为便于大家了解Python生态及如何学习Python提供一些参考,这里附上几张Python知识图谱,供参考。
1、Python基础学习
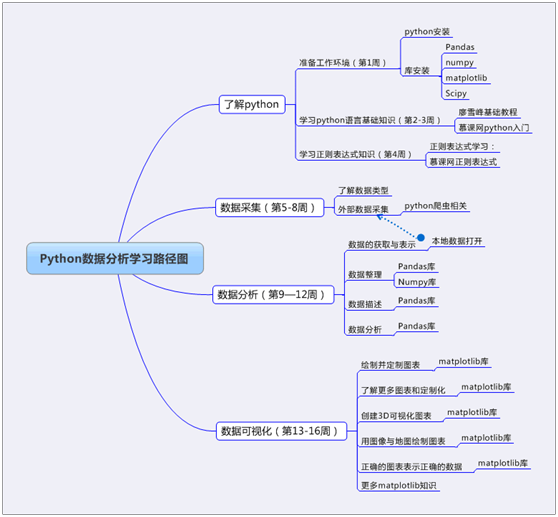
2、Python生态图谱

3、零基础学人工智能
这里引用莫烦的一个学习路线图,供大家参考。据他说,他学人工智能基本靠自学,莫烦(实名:周沫凡,湖南人,本科为桂林理工,土木工程系),下图从start开始。
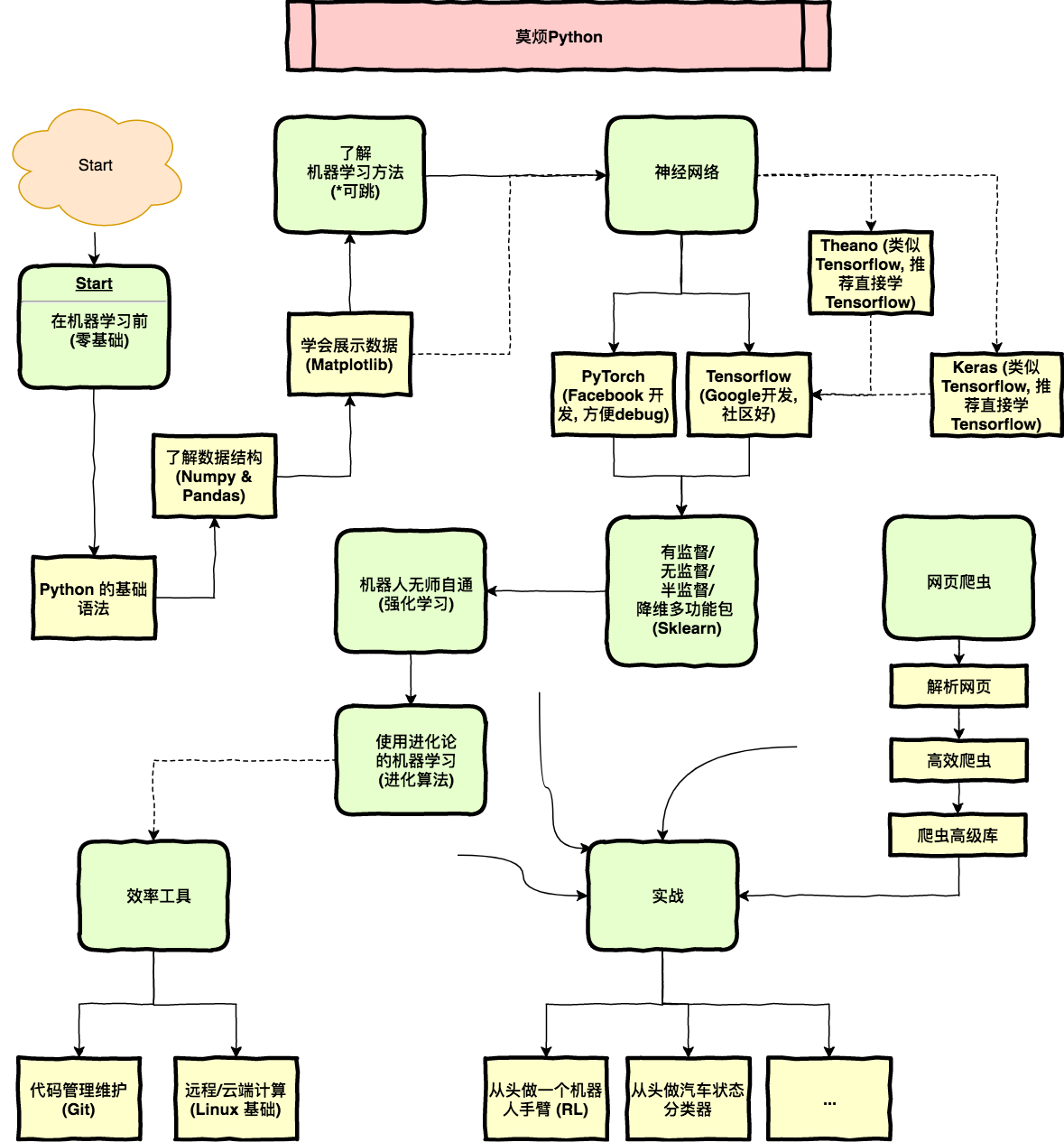
4、Python全栈技能
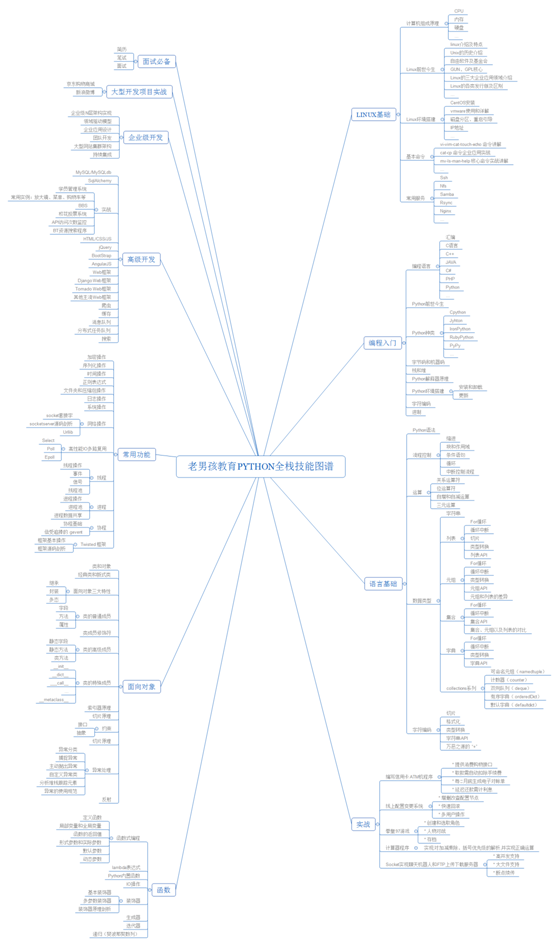
5、人工智能工程师---学习路线图

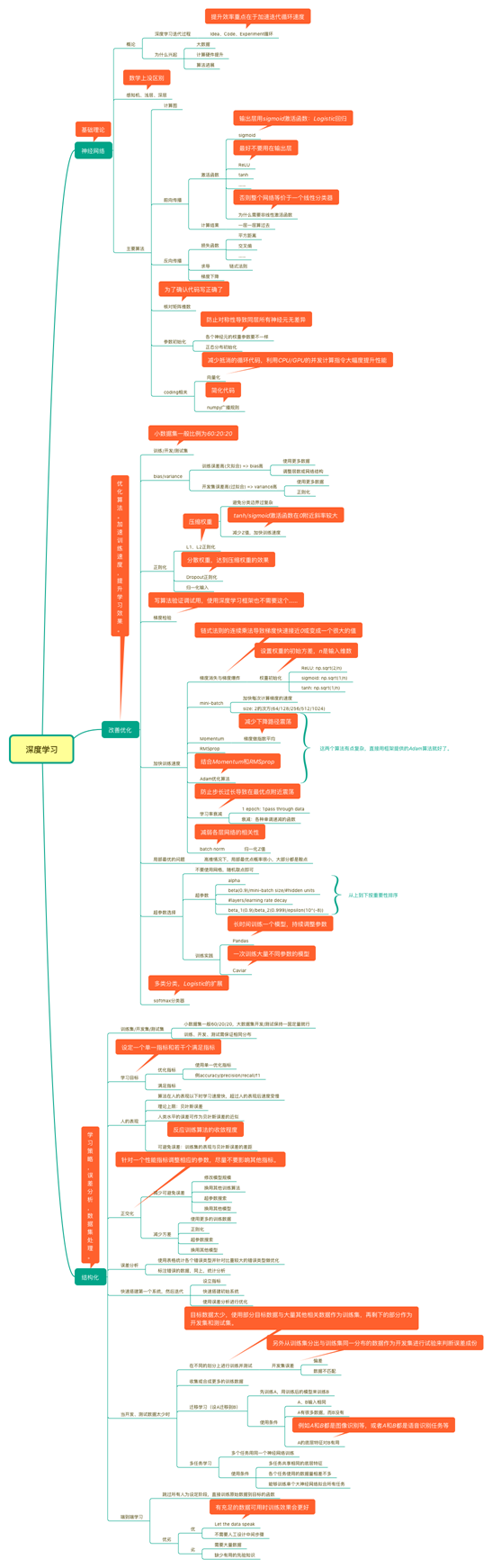
6、吴恩达深度学习课程精要
为便于大家了解Python生态及如何学习Python提供一些参考,这里附上几张Python知识图谱,供参考。
1、Python基础学习
2、Python生态图谱
3、零基础学人工智能
这里引用莫烦的一个学习路线图,供大家参考。据他说,他学人工智能基本靠自学,莫烦(实名:周沫凡,湖南人,本科为桂林理工,土木工程系),下图从start开始。
4、Python全栈技能
5、人工智能工程师---学习路线图
6、吴恩达深度学习课程精要
为什么要学习数据库?
这个问题我觉得还是从反面来回答比较好,数据库出故障了,会发生啥呢?
学数据库与我找工作或找到更好工作有关系吗?有,关系还很大哦。当然,如果你去应聘不用电脑的职业除外。否则,很可能产生“一丑遮百俊”。
学了数据库有哪些好处?
其他好处不好说,但如果你学了熟悉数据库,对学习其他技术有非常大得帮助,尤其对学习大数据相关技术如Hive、HBase、SparkSQL、SparkRDD等等更是如此,数据库很多都是相通或相似的,学好一个学其他的就轻松多了。
有哪些数据库?
数据库种类很多,从大得方面来说,可分为关系型数据库和非关系型数据库,如MySQL、SQL Server、Oracle、DB2、Sybase等属于关系型数据库,近些年比较火的HBase、MongoDB、Redis等属于非关系型数据库,从存储方式方面来说,可分为行存储数据库、列存储数据库、键值数据库、NoSQL数据库等,当然各类关系型数据库或非关系型数据库自身都各有一些特点。这里就不展开说了。
如何学习数据库?
这个问题有点仁者见仁智者见智,一百人可能有一百个答案,不过我个人认为,数据库作为一个基础性非常强、使用非常广泛的系统,多花些时间进行一些有系统的学习是非常必要,好的基础将大大提升你的竞争力、拓展你的职业发展空间。
为何选择MySQL? 它有哪些特点?
MySQL是由原MySQL AB公司自主研发的,现在已经被Sun公司收购,是目前IT行业最流行的开放源代码的数据库管理系统,同时它也是一个支持多线程高并发多用户的关系型数据库管理系统。支持Linux、Windows、MAC等多种操作系统,虽然功能上没有其他的大型数据库Oracle、DB2等那么齐全,但好用、易用、开源、可靠性等特点受到成千上万企业和用户的青睐重要原因。
向大家推荐几个学习MySQL的网站:
MySQL社区: http://www.mysqlpub.com/
MySQL菜鸟教程: http://www.runoob.com/mysql/mysql-tutorial.html
MySQL官网: http://www.mysql.com/
《深入浅出MySQL》唐汉名等著
数据库是一个长期存储在计算机内的、有组织、共享、统一的数据集合。作为关系型数据其关系可理解为数据库表,表是一系列二维数组的集合。
表定义:表(Table),在关系型数据库中,表是一系列二维数组的集合,由纵向的列和横向的行组成,列又称为字段,行又称为记录。
表样例:stud_info(学生基本信息表)
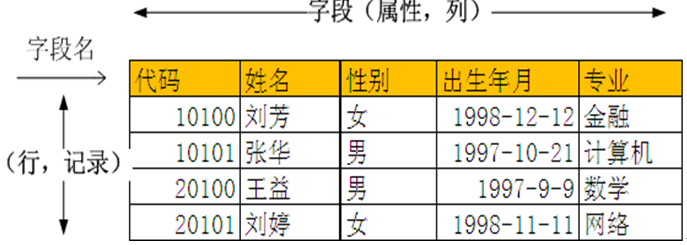
表要素有:
关系或表、列,字段行,记录
数据类型:
字符串数据类型、整数型、日期/时间类型、浮点数据型等
关键字,主键:
主键(Primary key),唯一标志表的每一条记录,可以定义表中一列或多列为主键, 主键列上不能有重复的值,也不能为空,如stud_info表中代码字段为该表的主键。
关系模式或表结构,格式为:表名称(属性1,属性2,…属性n)
我们一般通过数据库语言与数据库打交道,其中SQL是我们常用的,SQL的含义是结构化查询语言(Structured Query Language)。
SQL语言分类
数据定义语言(DDL)
如:DROP,CREATE,ALTER等
数据操作语言(DML)
如:INSERT,UPDATE,DELETE等
数据查询语言(DQL)
SELECT等
数据控制语言(DCL)
GRANT,REVOKE,COMMIT,ROLLBAK等。
为进一步理解SQL语句含义,下面以创建一张表的SQL语句为例,表名为t_student,具体SQL语句如下:
这是一个典型的数据定义语言(DDL),该表共有4个字段,分别为stud_id,stud_name,stud_sex,stud_birthday,其中stud_id为主键。
目前这个表是空表,只有结构没有数据,我们可以用数据操作语句(DML)往表插入记录或数据。
以上记录是否成功插入到表中呢?我们可以通过数据查询语言(DQL)来验证一下:
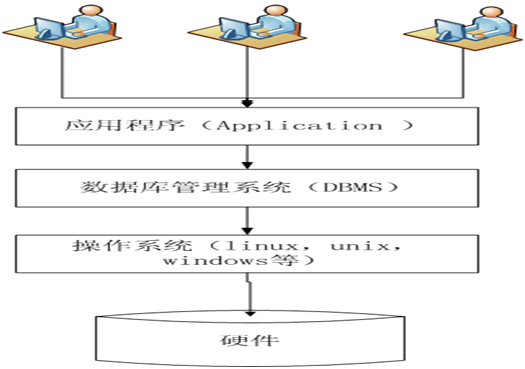
(图1-1 数据库系统架构)
MySQL支持多平台,如常见的windows,linux等,这里我们以Windows下安装为主,然后简单说明在Linux平台上的安装。
这里介绍一个针对初学者的Windows版的MySQL安装程序(mysqlSetup.exe,文件下载链接:http://pan.baidu.com/s/1kVHK3eZ),文件大小为35M左右,版本为V5.0,依赖较少,安装方便,但基础功能都有。
以下为详细的安装步骤:
第1步:点击“mysqlSetup.exe”文件,弹出如下界面
第2步:选择安装类型,选择typical(典型安装)。

第3步:是否注册,选择skip sign-up(不注册)
第4步:开始配置服务器
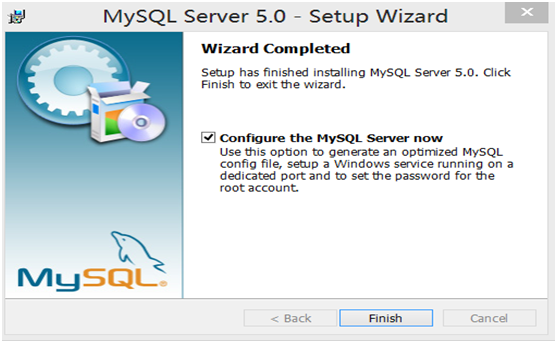
第5步:在配置类型界面中,选择Detailed configuration(详细配置)

第6步:在服务器类型中,作为初学者,可以选择Developer Machine(作为开发机),占用系统资源较少,但基本功能都有。
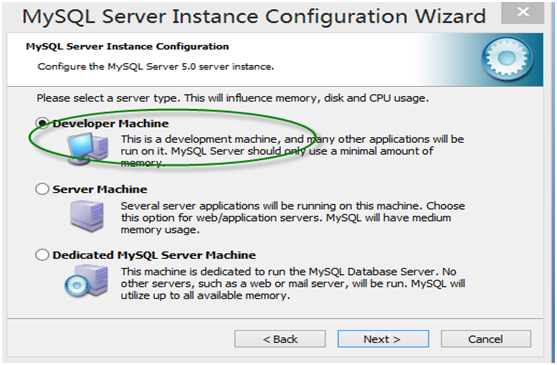
第7步:字符集选择界面,第一个为西文编码,第二个是多字节的通用utf8编码,都不是我们通用的编码,这里选择第三个,然后在Character Set那里选择或填入“gbk”,当然也可以用“gb2312”,区别就是gbk的字库容量大,包括了gb2312的所有汉字。
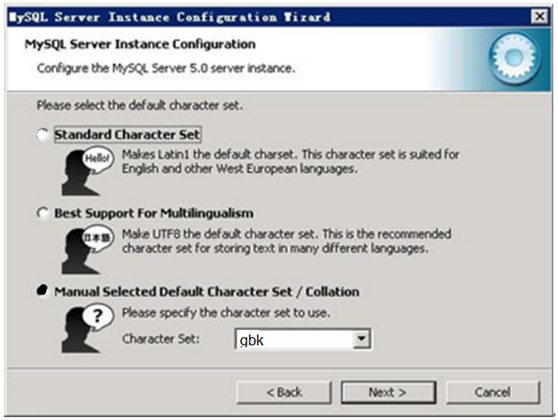
第8步:在数据库用途界面,选择Mutifunctional Database(多功能数据库)。
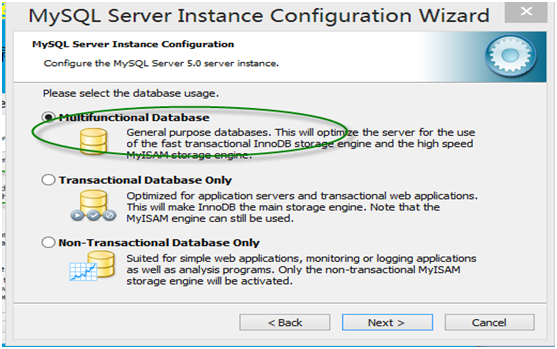
第9步:进入服务器最多并发连接数界面,作为初学者,不涉及很复杂的业务逻辑,而且并发数也需要很多,可选择第一项OLAP或OLTP,并发连接数(concurrent connection)缺省为15,当然你也可以根据需要进行修改。

第10步:配置网络,使用缺省配置即可。

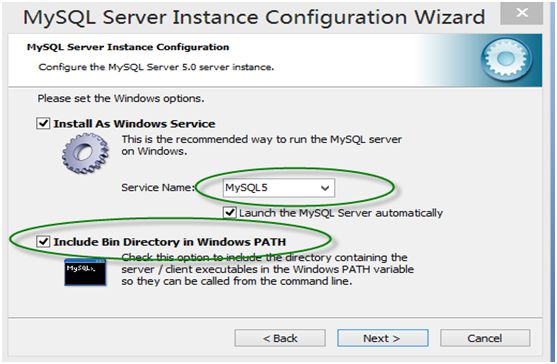
第11步:在Windows设置界面,记得在勾上“Inclode bin Directory in windows PATH”,这样自动把mysql命令所在目录放在Windows的环境变量Path中,接下来你便可在任何目录下启动mysql。
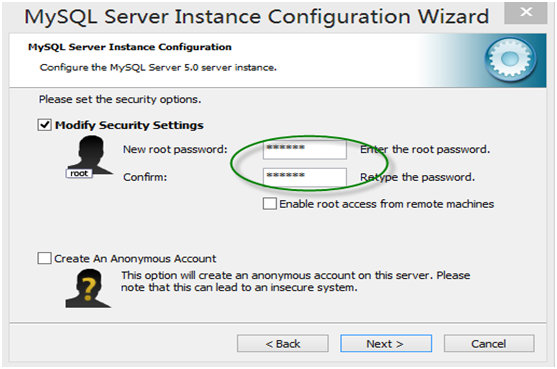
第12步,确认root用户密码
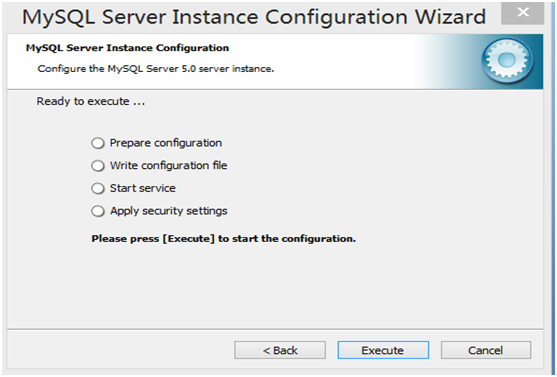
第13步,显示将执行的内容(无需选择),点击“Execute”
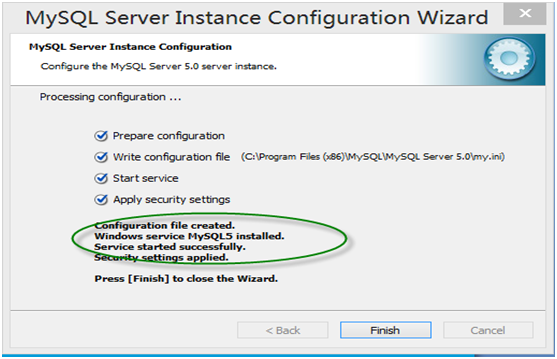
第14步 安装结束
第15步 登录MyQL系统。
通过Windows命令行登录
第1步,从开始菜单选择“运行”,打开运行对话框,输入‘cmd’
第2步,按确定,打开DOS窗口。
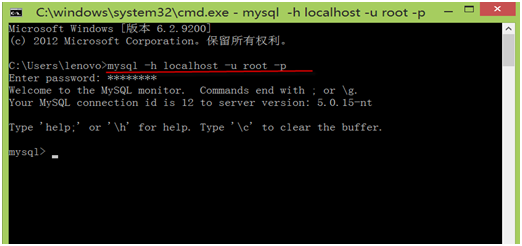
第3步,在DOS窗口中,可以通过输入命令登录MySQL系统,命令格式为:
mysql -h hostname -u username -p
其中mysql为登录命令,
-h 后的参数为服务器名称或IP地址,如果为本地服务器,可为localhost 或127.0.0.1, -u后的参数为用户名称,还没有创建其他用户时,只有root用户。
-p 后的参数为用户密码。
第4步,退出mysql系统,只要在mysql>后,输入quit 然后回车即可。
通过MySQL命令行登录
选择“开始”菜单,点击含“MySQL Command Line Client”字样的图标,进入登录界面,然后输入root用户密码即可登录。
这是在登录windows下MySQL系统的几种方式,下章我们将介绍如何登录远程服务器上的MySQL系统。
在第2章我们介绍了如何在Windows下安装和配置MySQL、通过“运行”或MySQL的命令行等界面登录Windows下的MySQL系统。
如果要连接Linux下的MySQL系统,该如何配置或操作呢?这个比较简单,首先,先通过Xshell或Putty等客户端连接Linux服务器,然后在Linux命令行输入连接MySQL的信息即可。如何连接Linux系统请参考第1章的1.6节。现在我们以用户feigu(密码也是feigu)连接MySQL。

登录MySQL系统后,我们可查看已创建的数据库,当然,我们也可自己创建数据。MySQL中命令一般以分号(;)或\g结束。
其中information_schema、mysql、performance_schema为系统自建数据库,用户不宜修改这些库。
创建数据库,其语法格式为:
CREATE DATABASE database_name;
创建一个数据库test_db,然后,验证创建是否成功。
创建了数据库,如果不用时,我们可以删除,当然测试关系不大,平时删除数据库要非常谨慎,如果有实际数据建议先备份,然后再删除,有备无患哦。
删除数据库的命令格式为:
MySQL有很多命令,各种命令的格式一般不同,忘记一些命令的使用方法是大概率事件,万一忘记了咋办?百度、google当然不失为方法之一,实际上MySQL自身就带有很强大的帮助功能,如查看MySQL一般可用help,如果要查询具体某个命令的使用方法,用help 命令名称,非常方便而且详细。
如何查看具体命令的使用方法?可用help 命令关键字,或? 命令关键字。如查看create database的具体使用方法。
MySQL有个独特、强大而灵活的功能,可以根据表的用途选择存储引擎。
它提供了很多种类型的存储引擎,我们可以根据对数据处理的需求,选择不同的存储引擎,从而最大限度的利用MySQL强大的功能。MySQL支持的存储引擎有:InnoDB、MyISAM、Memory、Merge、Archive等,可以使用SHOW ENGINES语句查看目前系统支持的存储引擎的类型:
以下我们列举几种常用存储引擎。
InnoDB
InnoDB是一个健壮的事务型存储引擎,这种存储引擎已经被很多互联网公司使用,为用户操作非常大的数据存储提供了一个强大的解决方案。作为默认的存储引擎,InnoDB还引入了行级锁定和外键约束,在以下场合下,使用InnoDB是最理想的选择:
1.更新密集的表。InnoDB存储引擎特别适合处理多重并发的更新请求。
2.事务。InnoDB存储引擎是支持事务的标准MySQL存储引擎。
3.自动灾难恢复。与其它存储引擎不同,InnoDB表能够自动从灾难中恢复。
4.外键约束。MySQL支持外键的存储引擎只有InnoDB。
5.支持自动增加列AUTO_INCREMENT属性。
一般来说,如果需要事务支持,并且有较高的并发读取频率,InnoDB是不错的选择。
MyISAM
MyISAM表是独立于操作系统的,这说明可以轻松地将其从Windows服务器移植到Linux服务器;每当我们建立一个MyISAM引擎的表时,就会在本地磁盘上建立三个文件,文件名就是表明。例如,我建立了一个MyISAM引擎的tb_Demo表,那么就会生成以下三个文件:
1.tb_demo.frm,存储表定义;
2.tb_demo.MYD,存储数据;
3.tb_demo.MYI,存储索引。
MyISAM表无法处理事务,这就意味着有事务处理需求的表,不能使用MyISAM存储引擎。MyISAM存储引擎特别适合在以下几种情况下使用:
1.查询密集型的表。MyISAM存储引擎在筛选大量数据时非常迅速,这是它最突出的优点。
2.插入密集型的表。MyISAM的并发插入特性允许同时选择和插入数据。例如:MyISAM存储引擎很适合管理邮件或Web服务器日志数据等。
MEMORY
使用MySQL Memory存储引擎的出发点是速度。为得到最快的响应时间,采用的逻辑存储介质是系统内存。虽然在内存中存储表数据确实会提供很高的性能,但当mysqld守护进程崩溃时,所有的Memory数据都会丢失。获得速度的同时也带来了一些缺陷。它要求存储在Memory数据表里的数据使用的是长度不变的格式,这意味着不能使用BLOB和TEXT这样的长度可变的数据类型,VARCHAR是一种长度可变的类型,但因为它在MySQL内部当做长度固定不变的CHAR类型,所以可以使用。
一般在以下几种情况下使用Memory存储引擎:
1.目标数据较小,而且被非常频繁地访问。在内存中存放数据,所以会造成内存的使用,可以通过参数max_heap_table_size控制Memory表的大小,设置此参数,就可以限制Memory表的最大大小。
2.如果数据是临时的,而且要求必须立即可用,那么就可以存放在内存表中。
3.存储在Memory表中的数据如果突然丢失,不会对应用服务产生实质的负面影响。
Memory同时支持散列索引和B树索引。B树索引的优于散列索引的是,可以使用部分查询和通配查询,也可以使用<、>和>=等操作符方便数据挖掘。散列索引进行“相等比较”非常快,但是对“范围比较”的速度就慢多了,因此散列索引值适合使用在=和<>的操作符中,不适合在<或>操作符中,也同样不适合用在order by子句中。
表存储引擎可以在创建表时利用USING子句指定。
在关系型数据库中,表是是数据库中最重要、最基本的操作对象,是数据存储的基本单位,数据是按行存储的(非关系型数据库有些是按列存储的),同时通过表中的主键、外键、索引、非空等约束来保证数据的一致性和完整性。这一章主要介绍数据表的基本操作:如何创建表、查看表的结构、修改数据表、删除数据表等。
创建表的方式,可以命令行的方式,也可以通过客户端(navicat for mysql)或通过该客户端的建模方式创建,然后,把模型同步到数据库即可。
创建表的过程就是确定数据列的属性、制定数据完整性、一致性等约束的过程。而这些约束主要通过主键、外键、是否可空、索引等约束来实现的。
创建表的语法形式:
CREATE TABLE 表名称
(
字段名称1 数据类型 [列级的约束] [默认值],
字段名称2 数据类型 [列级的约束] [默认值],
--------
[表级的约束]
);
注:
(1)、表的名称不区分大小写,不能以SQL中的一些关键字为表名,如CREATE、ALTER、INSERT等;
(2)、列名间用逗号隔开。
下面以创建一个学生的基本信息表为例,说明如何创建一张表。
表的定义或结构如下:
学生信息(t_stud_info)表结构
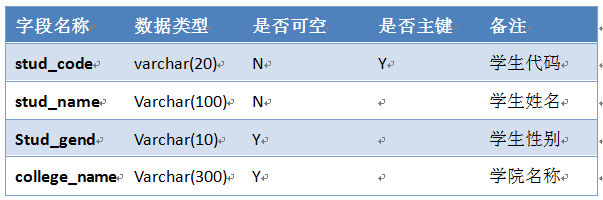
注:
(1)、stud_code这个字段为主键,作为主键(PRIMARY KEY)的字段不能为空,为空的字段不能为主键,主键可以建的一个字段上,也可建的两个或两个以上的字段上,称为组合主键;
(2)、非空字段,是指这些字段的值,不能为空(即为null)。
创建表的SQL语句:
创建表的SQL以写好,如何执行,如何查看表结构?通过实例来说明:
直接把创建表的SQL语句放在mysql命令行执行:
通过执行脚本创建表
如果一次要创建几十张表,把创建表的语句直接放在mysql命令行运行就不方便了,此时我们可以把创建这些表的SQL语句保存本地当前目录下,名为t_stud_info.sql的文件中,,具体内容请参看以下system cat t_stud_info.sql部分,然后用source命令在mysql命令下执行这个文件即可。这个source命令有点像shell命令。
除了以上两种方法外,还有其他方法,如通过客户端创建、通过模型来创建等等,这里就不展开来说了。
表创建好以后,有时间我们可能根据新的需求,需要修改字段类型、字段名称、添加字段、新建其它约束如索引、是否可空等。当表中无数据时做这些修改比较方便,如果表已有数据可能就需要慎重,否则可能导致修改失败,此时建议备份原表数据,然后清空数据,再做修改,修改后根据新的规则把数据导入新表中。但添加字段、放大自动长度等与是否有数据无关。
如果发现创建的表的某个字段长度太小,需要放大其长度,该如何修改呢?我们可以使用ALTER TABLE 语句来修改。
【注意】如果是正式环境的数据,记得先备份,后修改,有备无患。
修改表字段类型的语法格式:
ALTER TABLE <表名> MODIFY <字段名> <字符类型>;
我们创建一张表test01 (a1 varchar(20),a2 int,a3 date),然后,修改a1字段的数据类型,由varchar(20)改为varchar(60)。具体操作如下:
大家考虑一下,是否可以把INT修改为字符型,或把字符型修改整数型?如果要修改需要满足哪些条件?
除了可以修改字段类型,我们还可以修改表名称、字段名称、字段属性等。
修改字段名称的语句与修改字段类型的不一样,其语法格式为:
ALTER TABLE <表名> CHANGE <旧字段名> <新字段名> <数据类型>;
现在我们把test01表中a1字段名称改为name,数据类型不变。
表创建后,根据需要我们可以修改表名、修改表中字段名称、字段类型,当然也可添加字段,而且可以更加指定位置的添加,如果没有指定,缺省是添加到最后。添加字段的语法格式为:
ALTER TABLE <表名> ADD <新增字段名> <字段类型> [字段约束条件][FIRST|AFTER 已有字段名];
我们还是以test01表为例,在name字段后,添加一个名为code的字段,数据类型为varchar(20),并且不能为空或not null。
表的字符集或缺省字符集也能修改?能,这应该也是MySQL特色之一吧,一般数据库系统字符集与数据库绑定在一起,但MySQL把字符集粒度精确到了表甚至字段。虽然这个功能很强大,但也存在很大风险,特别是表中有数据时,可能导致字符类型不兼容问题,为降低风险,还是这句老话,先备份,后修改。
这里的修改一般指修改表的缺省字符集,常用的字符集有:UTF8、GBK、GB2312、latin1等,其中UTF-8用以解决国际上字符的一种多字节编码,它对英文使用8位(即一个字节),中文使用24为(三个字节)来编码。UTF-8包含全世界所有国家需要用到的字符,是国际编码,通用性强。GBK是国家标准GB2312基础上扩容后兼容GB2312的标准。GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示,为了区分中文,将其最高位都设定成1。GBK包含全部中文字符,是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBK大。
GBK、GB2312等与UTF8不兼容,需要通过Unicode编码才能相互转换:
GBK、GB2312--Unicode--UTF8
UTF8--Unicode--GBK、GB2312 。
字符集涉及面比较广,如服务器或数据库或表字符集、应用字符集(如连接字符集、文件字符集等)、客户端字符,一般这些环节的字符集需要一致或兼容,尤其对中文而言,否则可能导致乱码。如何解决乱码问题,后面我们也有介绍。
以下是修改表的字符集的一个简单实例:
修改方式或命令还有很多,大家可以借助其强大的help进一步获取其他命令的使用方法,如可以通过help ALTER TABLE 查询其他使用方法,这里就不在一一例举了。
往表中插入数据,有多种方法,如通过SQL语句、客户端、数据备份工具等。
1)、通过SQL命令:insert into table_name (列1,列2,..) Values(‘’,’’,’’,….);
用这种方法需要注意列与值的对应关系;如果不指定列名,则指所有列:
如insert into table_name values(‘’,’’,’’,…),values(),
2)、通过客户端导入;
3)、利用工具(load data file或mysqlimport等)借助数据文件来导入数据。
这里我们介绍第1种方法,其它2种后面讲数据备份时将介绍。
往表test01插入一条记录。
这是往插入1条记录,如果想一次往表插入多条记录如何实现呢?我们只要在后面添加个values即可,如同时往表中插入2条记录:
注意记录间用逗号。
具体操作请看下例
前面介绍创建表结构、往表中插入记录时,涉及数据类型,数据类型对数据质量、性能提升、甚至业务的拓展都有一定关系,在日常使用中经常看到中途修改字段类型的问题,这将带来很大风险,因此,设置合理的数据类型非常重要,我们需要理解各种数据类型及其取值范围,同时也要注意数据类型间的异同。
MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串类型。
数值类型
包括整数类型(TINYINT、SMALLINT、MEDIUMINT、INT(或INTEGER)、BIGINT),以及近似数值数据类型,浮点数据类型(FLOAT、DOUBLE)和定位数据类型(DECIMAL或DEC)。
日期时间类型
日期和时间类型有DATETIME、DATE、TIMESTAMP、TIME和YEAR。
字符串类型
字符串类型有CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT等。
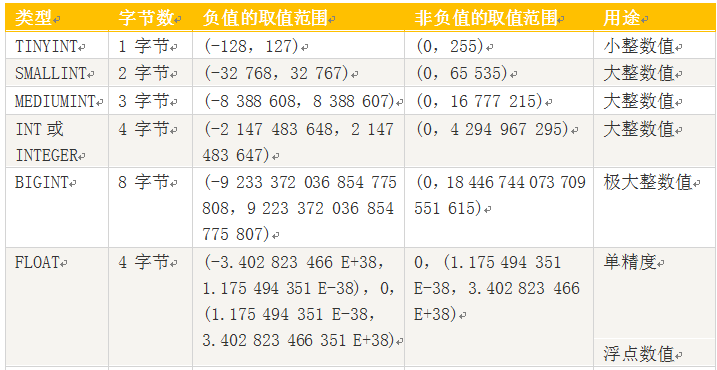
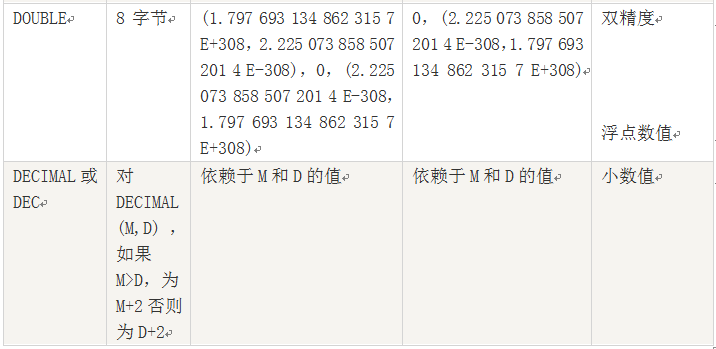
说明:
1、浮点数或定位数,如果实际值超出定义的精度范围,则采用四舍五入进行处理。处理时浮点数不提示,定位数会提示。
2、定位数据以字符串形式存储,如果对精度要求较高的科学计算、货币等,建议使用DECIMAL类型,浮点数进行比较时易出现问题。
3、FLOAT(M,D),其中M参数称为精度,是数据的总长度,即有效数字;D参数成为标度,是指小数点后的长度为D。如FLOAT(5,2)(如213.36)表示数据总长度为2,小数部分长度为2。
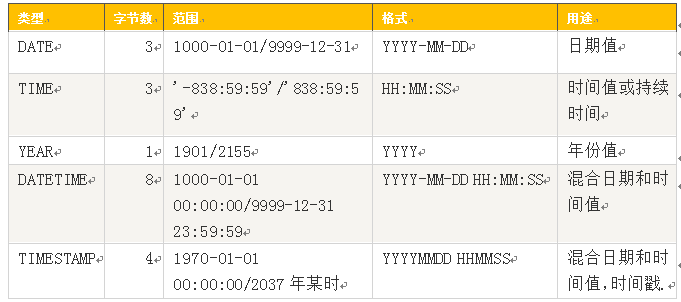
说明:
1、DATETIME和TIMESTAMP虽然都是19位,但前者范围比后者大,具体请看上表。
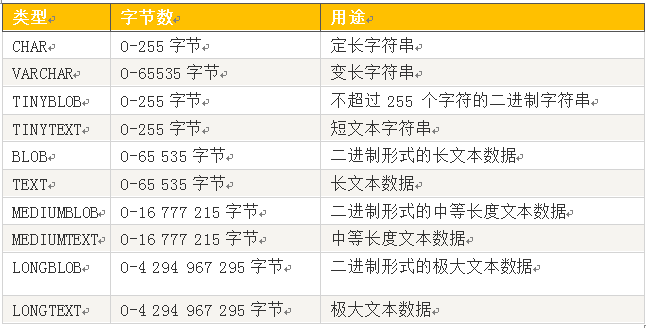
说明:
1、CHAR 把用户定义大小视为值的大小,不长度不足的情况下就用空格补足。而 VARCHAR 类型把它视为最大值并且只使用存储字符串实际需要的长度。
2、因为 VARCHAR 类型可以根据实际内容动态改变存储值的长度,所以在不能确定字段需要多少字符时使用 VARCHAR 类型可以大大地节约磁盘空间、提高存储效率。
运算符连接表达式中各个操作数,其作用是用来指明对操作数所进行的运算。常见的运算有数学计算、比较运算、位运算以及逻辑运算。运用运算符可以更加灵活地使用表中的数据,常用的运算符类型有:算术运算符,比较运算符,逻辑运算符等。
算术运算符
包括加(+)、减(-)、乘(*)、除(/)、求于(或称模运算,%)。
比较运算符
包括大于(>)、小于(<)、等于(=)、大于等于(>=)、小于等于(<=)、不等于(!=)、以及IN、 BETWEEN AND、IS NULL、GREATEST、LEAST、LIKE、REGEXP等。 LIKE运算符在进行匹配时,可以使用下面两种通配符: 1.‘%’,匹配任何数目的字符,甚至包括0字符。 2.. ‘_’,只能匹配一个字符。 REGEXP运算符在进行匹配时,常用的有下面几种通配符: 1.‘^’匹配以该字符后面的字符开头的字符串。 2.‘$’匹配以该字符后面的字符结尾的字符串。 3.‘.’匹配任何一个单字符。 4.‘[…]’匹配在方括号内的任何字符。例如,”[abc]”匹配”a”、”b”或”c”。 为了命名字符串的范围,使用一个’-‘。”[a-z]”匹配任何字母,而”[0-9]” 匹配任何数字。 5.‘*’匹配0个或多个在它前面的字符。 逻辑运算符 逻辑非(NOT或者!)、逻辑与(AND或者&&)、逻辑或(OR或者||)、逻辑异或(XOR)。 以下通过一些实例来加深理解:
 ,'spark'REGEXP '[abc]';
,'spark'REGEXP '[abc]';数据库主要功能是存储数据,但存储数据不是最终目的,存储数据最终目的是为了展示和分析,如何分析展示数据库中数据,数据查询就是重要手段。MySQL提供了功能强大、又非常灵活、非常方便的语句实现这些操作。这一章将介绍使用SELECT语句实现简单查询、子查询、连接查询、分组查询及利用正则表达式查询等。
最简单的是SELECT [列名]FROM [表名] WHERE [条件] 。然后你可以在后面加上像[LIMIT][ORDER BY][GROUP BY][HAVING]等。
[列名]: 可以多个字段(列间用逗号分隔),也可所以字段(一般用*表示所有字段)
[表名]: 可以是一个表名或视图名,也可以是多表或多视图(表间用逗号分隔)。
[条件]: 为可选项,如果选择该项,将限制行必须满足的查询条件。
[LIMIT]: 后跟[位置偏移量,] 行数 (第1行的位置偏移量为0,第2行为1,以此类推。)
[ORDER BY]: 后跟字段,可一个或多个,根据这些字段进行分组。
[GROUP BY]: 后跟可一个或多个字段,根据这些字段进行排序,升序(ASC)或降序(DESC)。
其后也可跟WITH ROLLUP,增加一条合计记录。
[HAVING]: 一般与GROUP BY一起使用,用来显示满足条件的分组记录。
单表查询就是从1张表中查询数据,后续将介绍多表查询。为查询表数据我们需要先做些准备工作。
准备工作包括:1)、定义表结构,创建表;2)、查看分析数据文件;3).把数据导入到表中。
1).首先我们创建一个存储学生各科成绩的表(stud_score),表的定义如下:
(表6-1 学生成绩表 stud_score)

转换为建表的SQL语句为:
2)、创建这个表以后,我们需要把一个包含该表数据的文件(在slave02节点的/tmp目录下,名称为stud_score.csv)导入该表,另该文件第1行为字段名称,需过滤掉。我们先操作,具体语法等我们后续会介绍。
查看该数据文件信息
3)、把数据文件导入表中
利用LIKE 关键字可以进行模糊查询。下例查询学科代码以101开头的记录总数。
如果我们希望按学科来统计学生成绩、班级成绩该如何实现呢?这就涉及到分组统计问题,如果需要按学科统计,可以GROUP BY sub_code;然后取前3名学科,具体实现请看下例:
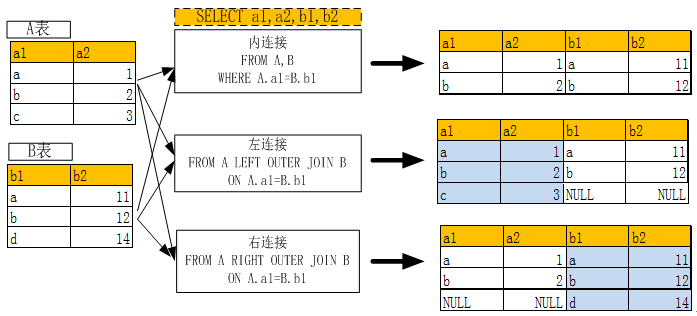
多表查询,需要连接2张或2张以上的表一起查询,连接有多种方式,如内连接(通常缺省连接)、外链接(又分为左连接,右连接)等。多表连接时,建议不宜一下连接很多表,尤其是数据比较大时,可以采用两两连接等方式。
要实现多表连接,还需创建一个存储学生基本信息的表(stud_info)并导入数据.
创建一个学生基本信息的表(表定义如下),并把数据(一个数据文件)导入到表中。
准备步骤,1).定义并创建表,2),查看分析数据文件,3). 导入数据,并验证导入结果。
1).定义并创建表

2).查看分析数据文件
3).导入数据并验证结果
两表内连接、左连接,右连接的含义及使用关键字请参看下图:
(图6-1 多表连接示意图)
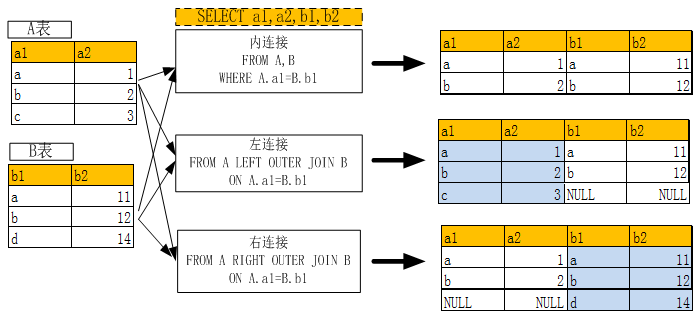
以下通过几个实例进一步说明多表连接的使用方法:
这里介绍以用IN关键字实现子链接,基本格式为:
SELECT * FROM 表名WHERE 字段 IN (SELECT 字段 FROM 表名 WHERE 条件);
使用子查询,比较灵活,且有利于把大表关联转换为小表关联。下例为表stud_info中
stud_code从表stud_score中成绩为大于或等于90分的子查询中获取。
上面的查询语句,有的比较简单,有的比较复杂,像对那些复杂的查询语句,包含了很多信息量,而且有可能还要经常使用,但命令行是无法保证这些语句的,如果下次还要使用是否又重新写一遍呢?大可不必,我们可以把这个查询语句以视图的形式保存到数据库中,然后直接查询这个视图即可。
如上面内连接的SQL语句:SELECT a.stud_name,b.sub_name,b.sub_score FROM stud_info a,stud_score b WHERE a.stud_code=b.stud_code LIMIT 3;
我们可以把它定义为一个视图V_STUD,然后查询视图即可,非常方便!而且视图会保存到数据库中,但视图本身不保存数据。具体实现请看下例:
存储数据时用来查询分析用的,所以查询分析数据是平时重要任务,但数据库中数据它不会自动生成,需要我们去维护,当然大部分是系统自动维护,不需要手工去操作,不过维护程序还是需要写的,这章我们介绍如何维护数据库数据。这里我们主要介绍如何新增数据、如何修改数据、如何删除数据等。
插入数据语句的语法:
INSERT INTO 表名[(列名1,……列名n)] values(值1,…..值n);
这个SQL语句一次往表中插入1条记录,如果一次要插入多条记录是否可以呢?可以,而且很方便,插入多条语句为:
INSERT INTO 表名[(列名1,……列名n)] VALUES(值1,…..值n), (值1,…..值n),..;
下面我们还是通过一些实例来进步说明如何操作。
修改数据也是很常见的,不过修改数据前,记得备份数据。如何备份数据后面将介绍。
修改数据的一般语法:
UPDATE 表名 SET 列名1=值1,….列名n=值n
[WHERE 条件];
以下以修改id为200对应的name为例,假设发现id为200对应的name输错了,不是刘婷,而是刘涛。
删除数据时,我们可以选择删除几条,或满足某些条件的记录,当然也可以删除所有记录。在日常工作中,删除数据需要非常谨慎,务必养成一个良好习惯,先备份,后删除。对生产环境数据、或正式环境的数据,不建议物理删除,最好采用逻辑删除的方式(即修改对应记录的状态或有效时间等)。数据都有价值。
用DELETE删除数据的一般语法:
DELETE FROM 表名 [WHERE 条件];
DELETE 加上条件,就可以有条件删除记录;如果没有条件,将删除所有数据。删除所有数据也可用TRUNCATE命令(这种方式删除数据比较快),其命令格式为:
TRUNCATE [table] 表名;
使用DELETE FROM 表名或TRUNCATE [table] 表名命令删除全部记录时,有一种情况需要注意,如果一个表中有自增字段,这个自增字段将起始值恢复成1.如果你不想这样做的话,可以在DELETE语句中加上永真的WHERE,如WHERE 1或WHERE true。
【1】在person表中,插入一条新记录,列的顺序与表一致,SQL语句如下:
INSERT INTO person (id ,name, age , info) VALUES (1,'Green', 21, 'Lawyer');
【2】在person表中,插入一条新记录,列顺序与表不一致,SQL语句如下:
INSERT INTO person (age ,name, id , info)
VALUES (22, 'Suse', 2, 'dancer');
【3】在person表中,插入一条新记录,不写列名,SQL语句如下:
INSERT INTO person VALUES (3,'Mary', 24, 'Musician');
【4】在person表中,插入一条新记录,不写自增字段,SQL语句如下:
INSERT INTO person (name, age,info) VALUES('Willam', 20, 'sports man');
【5】在person表中,插入一条新记录,不写id、age,SQL语句如下:
INSERT INTO person (name, info ) VALUES ('Laura', 'teacher');
【6】在person表中,在name、age和info字段指定插入值,同时插入3条新记录,SQL语句如下:
【7】在person表中,不指定插入列表,同时插入2条新记录,SQL语句如下:
INSERT INTO person
VALUES (9,'Harry',21, 'magician'),
(NULL,'Harriet',19, 'pianist');
【8】在person表中,delete 全表然后看自增字段的值,SQL语句如下
show table status like 'person';
delete from person;
truncate table person;
show table status like 'person';
修改自动增长字段起始值
alter table person auto_increment = 100 ;
INSERT INTO person (name, age,info) VALUES('Willam', 20, 'sports man');
select * from person;
在mysql中不同存储引擎对锁的粒度不同,InnoDB可到行级,MyISAM和MEMORY可到表级,BDB可到页级,下面以InnoDB引擎为例,说明MySQL的锁及事务控制。
给表加锁
session1 session2
给表加锁
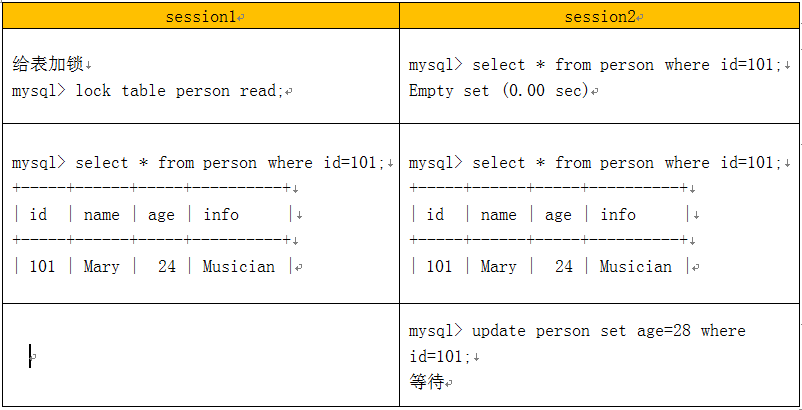

事务控制实例:


事务控制及回滚





MySQL数据库自身带有很多函数,合理使用这些函数能有效提高我们的编程效率和编程质量,可以直接使用数据库自带函数(或称为内置函数),当然我们也可以根据自己需要自定义函数。自定义函数(UDF)后面将介绍。
MySQL提供了大量函数,具体可为:数学函数、字符串函数、日期及时间函数、聚合函数、条件判断函数、系统信息函数等等。这些函数极大丰富和增强了对数据的处理和分析能力。下面我们就一些常用的函数进行说明,大家也可通过help或网络查看MySQL函数的一些使用方法。
ABS(x)
返回x的绝对值
MOD(x,y)
返回x/y的模(余数)
RAND()
返回0到1内的随机值,可以通过提供一个参数(种子),如RAND(N)使RAND() 随机数生成器生成一个指定的值。
SQRT(x)
返回一个数的平方根。
ROUND(X)
返回参数X的四舍五入的一个整数。
CONCAT(str1,str2,...)
返回来自于参数连结的字符串。如果任何参数是NULL,返回NULL。可以 有超过2个的参数。一个数字参数被变换为等价的字符串形式。
LOWER(str)
返回将字符串str中所有字符改变为小写后的结果
LEFT(str,x)
返回字符串str中最左边的x个字符
LENGTH(s)
返回字符串str中的字符数
LTRIM(str)
从字符串str中切掉开头的空格
LOCATE(substr,str)
返回子串substr在字符串str中第一次出现的位置
REVERSE(str)
返回颠倒字符串str的结果
RIGHT(str,x)
返回字符串str中最右边的x个字符
RTRIM(str)
返回字符串str尾部的空格
STRCMP(s1,s2)
比较字符串s1和s2
TRIM(str)
去除字符串首部和尾部的所有空格
SBUSTR(str,pos)
就是从pos开始的位置,一直截取到最后。
SUBSTR(str,pos,len)
就是从pos开始的位置,截取len个字符(空白也算字符)
UPPER(str)
返回将字符串str中所有字符转变为大写后的结果
CURRENT_DATE()
返回当前的日期
CURRENT_TIME()
返回当前的时间
NOW()
返回当前的日期和时间
DATE_ADD(date,INTERVAL int keyword)
返回日期date加上间隔时间int的结果(int必须按 照关键字进行格式化), 如:SELECTDATE_ADD(CURRENT_DATE,INTERVAL 6 MONTH);
DATE_FORMAT(date,fmt)
依照指定的fmt格式格式化日期date值
什么叫聚合计算?举个简单例子大家就明白了,假如要统计一个班男女同学各多少,这个问题就是聚合计算,聚合统计实际上就是分组计算或分组统计。以下通过图形来说明根据课程来分组聚合计算课程成绩的详细过程:
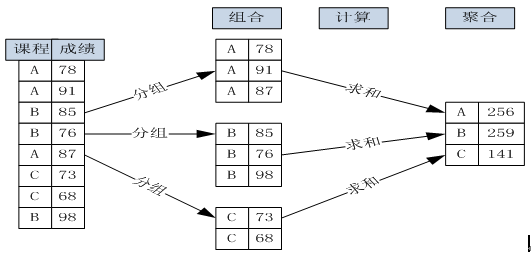
(图 8-1 按课程分组与聚合成绩的计算过程)
数据库如何进行聚合计算?非常方便,MySQL提供了现成的语句,即GROUP BY,具体格式为:
SELECT 聚合函数(如COUNT、SUM等) FROM 表名称 GROUP BY 分组字段(可以1个或多个)。
常用于GROUP BY从句的SELECT查询中。
AVG(col) 返回指定列的平均值
COUNT(col) 返回指定列中非NULL值的个数
MIN(col) 返回指定列的最小值
MAX(col) 返回指定列的最大值
SUM(col) 返回指定列的所有值之和
IFNULL(expr1,expr2)
如果expr1不是NULL,IFNULL()返回expr1,否则它返回expr2。
IF(expr1,expr2,expr3)
如果expr1是TRUE(expr1<>0且expr1<>NULL),那么返回expr2,否则它 返回expr3。
CASE value WHEN [compare-value] THEN result [WHEN [compare-value] THEN result ...] [ELSE result] END
CASE WHEN [condition] THEN result [WHEN [condition] THEN result ...] [ELSE result] END
如果第一个条件为真,返回result。如果没有匹配的result值,那么结 果在ELSE后的result被返回。如果没有ELSE部分,那么NULL被返回。
DATABASE() 返回当前数据库名
CONNECTION_ID() 返回当前客户的连接ID
FOUND_ROWS() 返回最后一个SELECT查询进行检索的总行数
USER() 返回当前登陆用户名
VERSION() 返回MySQL服务器的版本
存储过程或函数,有啥作用?如果我们平时只是使用一些简单SQL,可能不需要用到它们,如果那天你需要编写一个多功能、比较复杂的SQL,它们的作用就不可小看了。特别是一些功能需要提交到生产环境,那就更离不开它们了。这个有点像shell中命令与脚本一样。脚本可以把很多命令写到一个文件中,而且这个脚本可以放到其他服务器,可以定时执行等等,非常方便。
实际上MySQL的存储过程或函数还有些特殊有点。我们常用的操作数据库语言SQL语句在执行的时候需要要先编译,然后执行,而存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它。而且执行都在数据库中,可减少数据在数据库与应用服务间的传输,既可节省网络资源,又可提高运行效率。
存储过程与函数的区别可从以下几个方面来比较:
返回值:存储过程没有,但函数必须有。
参数: 存储过程有IN,OUT,INOUT类型,函数只有IN类型。
调用: CALL 存储过程名(参数),SELECT 函数名(参数)
创建或修改存储过程或函数的语法如下:
CREATE PROCEDURE 过程名 ([过程参数[,...]])
[特性 ...] 过程体
CREATE FUNCTION 函数名称([参数列表[,..]])
RETURNS 返回值类型
以下存储过程输入学生代码,统计该学生所选课程总数,并输出。
上面这个存储过程的功能,如何用函数来实现呢?
查看存储过程和函数的状态的语法格式:
SHOW [PROCEDURE][FUNCTION]STATUS [LIKE'pattern' ];
查看存储过程和函数的定义的语法格式:
SHOW CREATE [PROCEDURE][FUNCTION] sp_name;
备份数据是一项非常重要的事情,是保证数据安全、降低系统损坏、断电、失误操作等等所带来的危害的有力措施。任何的侥幸心理,都可能带来严重后果。
MySQL数据库备份的方法很多,这里我们介绍几种常用的方法:
1)、mysqldump工具
使用mysqldump备份单个数据库中的所有表,其语法格式为:
mysqldump -u user -h host -p dbname>filename.sql
使用mysqldump备份数据库中的部分表,其语法格式为:
mysqldump -u user -h host -p dbname [tablename[,tablename,,,]]>filename.sql
导出的结果包括表结构、数据等信息
2)、使用SELECT ... INTO OUTFILE导出到文件,其命令格式为:
SELECT ... INTO OUTFILE 'path/filename' [参数]
这样导出方式,比较简单,导入也简单,但只导出数据,不包含表结构等信息。
下面通过一个实例来进步说明如何操作,实例的目的是把表stud_info的数据导出到/tmp目录下。
验证导出结果:
恢复数据或还原数据也有多种方法,如通过MySQL命令、工具等。如果备份的文件是以SQL语句的格式保存的可采用执行该文件即可,如source filename.sql,利用工具mysqldump备份出的文件就是sql文件,恢复时就可采用执行文件的方式,其语法格式为:
mysql -u user -h host -p dbname DELETE FROM stud_info; ##全删表数据
Query OK, 22 rows affected (0.08 sec)
mysql> SELECT COUNT(*) FROM stud_info;
+----------+
| COUNT(*) |
+----------+
| 0 |
+----------+
mysql> LOAD DATA INFILE '/tmp/stud_info_20161102.txt' INTO TABLE stud_info
-> fields terminated by "," enclosed by '"' ;
Query OK, 22 rows affected (0.02 sec)
Records: 22 Deleted: 0 Skipped: 0 Warnings: 0
mysql> SELECT COUNT(*) FROM stud_info;
+----------+
| COUNT(*) |
+----------+
| 22 |
+----------+
mysql> SELECT * FROM stud_info LIMIT 2\G
*************************** 1. row ***************************
stud_code: 2015101000
stud_name: 王进
stud_sex: M
birthday: 1997-08-01
log_date: 2014-09-01
orig_addr: 苏州
lev_date: 0000-00-00
college_code: 10
college_name: 理学院
state: 1
*************************** 2. row ***************************
stud_code: 2015101001
stud_name: 刘海
stud_sex: M
birthday: 1997-09-29
log_date: 2014-09-01
orig_addr: 上海
lev_date: 0000-00-00
college_code: 10
college_name: 理学院
state: 1
2 rows in set (0.00 sec)
[/cceN_python]
优化数据库是数据库管理人员和开发人员需要具备的一项重要技能,在实际项目中,往往遇到运行一个查询或一个存储过程或显示1张报表耗时十几分钟或几个小时,甚至更多,但经优化后,原来需要几个小时的只要不到一分钟,由此,优化对开发和管理的意义就不言自明了。
数据库的优化,方法很多,但总的原则就是减少系统资源(包括I/O,内存、CPU等)的占有、增强系统的健壮性。
优化的一般步骤:先找到性能瓶颈,然后,根据资源使用情况,找到引起瓶颈的语句或应用,调整结构或设计或参数、优化的过程往往迭代式。
优化的方法主要有设计优化、查询优化、参数的优化等。
查询是我们用得最多的操作,提高查询速度是一个我们经常遇到的问题。
如果能及时查询使用资源的情况,将有助于我们发现问题所在,幸好,MySQL提供了一个分析语句:EXPLAIN或DES CRIBE,通过这个分析语句我们可以很方便地看到查询语句查询的行数、是否利用了索引等重要信息。
EXPLAIN语句的基本语法如下:
EXPLAIN 查询语句;

下面对查询结果的各项含义进行说明:
(1)id
Select语句的序列号
(2)select_type
表示查询类型,它主要有如下几种情况:
SIMPLE----表示简单查询,其中不包括连接查询、子查询等;
PRIMARY---表示主查询;
UNION-----表示涉及连接查询
(3)table
表示查询的表
(4)type
表示表的连接类型,各种连接类型从优到差大致有如下几种。
system:该表为仅有一行的系统表
const:数据表最多只有一个匹配行,它查询时开始读取,在后续查询中将优化为常量。const表查询很快,因只需读一次。它一般使用常量值比较主键或唯一索引的所有部分。
如下查询属于这类型:
SELECT * FROM TABLE_NAME WHERE PK_KEY1=a;
eq_ref:从关联表中读取一行,常用于主键或唯一索引字段的等式匹配。
ref: 从关联表中匹配所有行,常用于非主键或唯一索引字段的等式或不等式的匹配。
ref_or_null:。类型如同ref,但多了含null的查询条件;
index_merge:说明连接类型使用了索引合并优化方法;
uique_subquery:使用了索引的子查询
index_subquery:使用了非唯一性索引的子查询
range:搜索指定范围的行
index:只扫描索引
ALL: 进行总表扫描
(5)possible_keys
说明能用哪个索引,如果为null,没有使用索引,可考虑使用或创建相关索引来提高查询效率。
(6)key
茶香中使用到的索引,如果为null,说明没有使用索引。
(7)key_len
指选择索引字段的字节长度,如果为null,则长度为null,通过该值可知道实际使用了组合索引的几个字段。
(8)ref
说明使用了哪列或常数与索引一起查询;
(9)rows
说明查询时查询的行数;
(10)Extra
查询附加信息,如是否用了where等。
通过分析我们知道,该查询是单表查询,是全表扫描,共扫描了118行。
以下介绍通过不同字段查询相同记录的性能分析,看索引对查询的影响。
有一张表存储学生信息的表stud_info,分别通过学院代码字段(建立了一个索引)、学院名称字段(没有索引)查询。
索引对提高查询速度或数据库性能关系非常密切,其效果往往是立竿见影的,如果索引设计合理,能大幅提升的查询效率。下面我们以一个简单实例来说明,比较一个字段在没有索引和有索引的查询效能如何改变。
还是以表stud_info为例,对其字段college_code先没索引到创建索引,然后比较查询性能分析结果。
如果有个组合索引,是否创建了索引,然后使用其中一个为查询条件,是否一定走索引呢?我们通过一个实例来看一下,假设我们在stud_score表的stud_code,sub_code两个字段上创建一个联合索引或联合主键。
以上例子中虽然我们查询时用到了一个索引字段,但查询时却没有走索引,这是为什么呢?这里违背索引的一条重要原则,即最左原则。该原则是:如果使用的字段不含组合索引中的第一个字段(即最左边那个字段),查询时不走索引。以下我们还是通过实例来验证这个原则。
优化工作,除了在查询时需要考虑,实际上在数据库设计或建模时,更应考虑,而且意义更大、影响更广,这是把优化工作前移。一个差的设计方案,不但影响后续优化,甚至影响系统的性能、可靠性、可维护性。
在设计层面考虑优化时,一般主要以下原则:
1、表中字段不宜过多,否则,应考虑大表拆分成几个小表;
2、为减少多表关联,可以考虑适当添加一些冗余字段,或中间表;
3、需要经常出现在where条件的字段,需要考虑建立索引。
4、表分区设计
表分区的定义:
通俗地讲表分区是将一大表,根据条件分割成若干个小表。mysql5.1开始支持数据表分区了。 如:某商品的库存表的记录超过了400万条,那么就可以根据入库日期将表分区,也可以根据所在地将表分区。当然也可根据其他的条件分区。
查看目前MySQL版本是否支持表分区。
表分区的意义:
与单个磁盘或文件系统分区相比,可以存储更多的数据。
一些查询可以得到极大的优化,这主要是借助于满足一个给定WHERE语句的数据可以只保存在一个或多个分区内,无需查询所有分区。涉及到例如SUM()和COUNT()这样聚合函数的查询,可以很容易地进行并行处理。
通过跨多个磁盘来分散数据查询,来获得更大的查询吞吐量。
表分区类型:

表分区示例:
数据库系统方面的优化,主要涉及系统资源的优化、架构的优化及一些系统参数的优化。
系统资源方面的优化主要有以下方法:
1、配上较大的内存、或使用集群方式,共享内存,可大大增加内存总量;
2、配置高速磁盘系统,或采用集群方式,便于把数据分布到不同节点上。
3、采用多线程的处理器,或采用集群方式,提升并发处理能力。
在系统参数方面,需要关注以下参数:
1、max_connections:表示数据库的最大连接数。
2、query_cache_size:表示查询缓存大小。
3、sort_buffer_size:用来排序的缓冲大小。
4、key_buffer_size:表示索引缓存大小。
(注:参数涉及配置文件my.cnf)
一、连接数据库丢失SOCK
在MySQL服务器上连接数据库时,有时报can't connect to /tmp/mysql.sock类似错误。
这是因为连接中指定的localhost作为一个主机名,而mysqladmin默认使用Unix套接字文件(一命名为mysql.SOCK),而不是TCP/IP。为此,解决此类问题,
1、显式说明指明连接协议,如mysql --protocol=TCP -u user -p -h localhost
2、可以把localhost改为127.0.0.1
3、在连接信息中添加文件mysql.sock所在位置,这个参数(如unix_socket="/var/run/mysqld/mysqld.sock"),
4、修改相关配置参数my.cnf中socket。修改配置文件需要停启服务。
二、中文乱码问题
中文乱码一般是数据库(或表)字符集与客户端字符集、应用字符集不兼容导致的,三者间如果其中两个不兼容就有可能导致乱码。
查看表的字符集:mysql>SHOW CREATE TALE tablename;
查看文件的字符集:vim或vi 文件名,然后输入:set fileencoding 可以查看文件字符集
查看服务、数据库、客户端等字符集:
mysql>show variables like '%char%';
修改客户端字符集:mysql>SET character_set_results=字符集(utf8,gbk等);
三、mysql导入csv报错ERROR 29 (HY000): File not found (Errcode: 13)
解决方法;
1、在mysqld中添加存放数据路径的读写权限
假设存放数据路径为/tmp
#vi /etc/apparmor.d/usr.sbin.mysqld
在最后添加以下两行
/tmp/ r,
/tmp/* rw,
2、然后重新加载这个文件
#/etc/init.d/apparmor reload
一、在windows下安装配置MySQL,并尝试在cmd启动并连接mysql。
二、在testdb库上创建表,表结构如下:
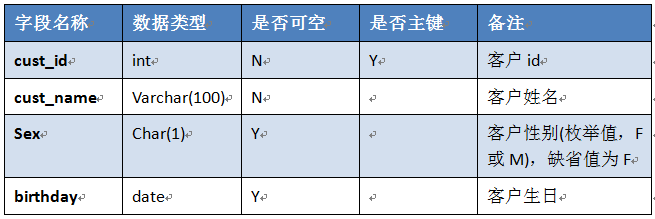
写一个sql文件,功能包括:
1、创建以上表结构,表名为:test_学号;
2、往表test_序号插入至少3条数据;
3、在表最后位置添加一个字段,字段要求如下:

三、创建表并把数据导入表中,然后查询相关数据,把这些操作放到一个SQL文件中,具体要求如下:
1、创建两表,表名分别为,stud_score_学号:stud_info_学号,表结构请参考第6.2.1节和6.3.1节
2、导入数据,把/tmp目录下stud_info.csv,stud_score.csv分别导入到表stud_info_学号,stud_score_学号中
3、查询数据,查询表stud_info_学号中,把姓刘的同学过滤出来。
四、多表查询,在一个SQL语句实现以下功能
1、内连接,实现stud_score_学号:stud_info_学号的内连接,连接字段为stud_code
2、左连接, 实现stud_score_学号:stud_info_学号的左连接,连接字段为stud_code
五、聚合查询
1、把选了大于5门课的同学的名称及各科总成绩打印出来。
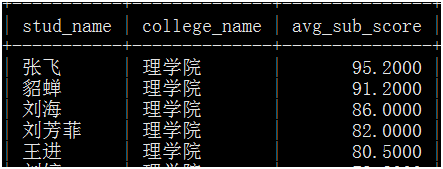
六、写一个存储过程,实现功能,输入学院代码,输出,学生名称、学院名称、各科平均成绩,如下图:
七、备份数据
1、导出表stud_socre_学号的数据,并验证导出数据的总条数、是否有乱码等。
八、性能优化
1、谈谈你对数据库优化方法,可包括数据库设计、SQL编写等方面内容。
此外大家还可参考网站其他数据库经典博客或文章 或My SQL 基础入门 或MySQL入门200句
第14章 由浅入深--轻松学会--用Python实现神经网络
我们知道现在神经网络很火,功能很强大、运用范围也很广泛,所以很多人都想在神经网络这方面有所突破和进展。但有不少读者,苦于基础不够,进展一致不尽人意。我们这一章或许能提高您的学习效率,使您能更快了解神经网络的架构和原理,并逐渐自己写神经网络算法。
本章我们将由浅入深介绍用Python实现神经网络,首先介绍感知器的实现方法,然后,介绍一种激活函数为恒等式的自适应神经网络算法,最后,介绍含隐含层的多层神经网络算法。学好这些算法将为学习深度学习打下扎实基础。
这里我们使用弗兰克•罗森布拉特(Frank Rossenblatt)提出的一个感知器,这类感知器有一个自学习算法,该算法可以自动通过优化得到权重系数,此权重系统与输入值的乘积决定神经元是否被激活。其权重更新无需损失函数,当然更无需求导,所以非常简单。

这里净输入函数为输入样本x与权重值w的相乘后的累加,假设:

分段函数ϕ(z)用图形可表示为:



这里使用的数据为鸢尾花数据集,定义感知器类(perceptron),在这个类中定义一个从数据中进行学习的fit方法,使用predict方法进行预测。对非初始化定义的变量,为区别起见我们将假设一个下划线,如self.w_。
1)定义感知器类
定义一个感知器类,在这个类中,先定义两个参数:学习速率eta,迭代步数n_iter;然后定义了两个属性:每次训练样本时记录权重的1维向量w_,用于记录每次迭代时发生错误的样本数errors_;在这个基础上定义了用来训练数据集的函数fit,计算净输入函数net_input,用于预测的函数predict。
2)导入鸢尾花数据集
该数据集前4列为特征,最后1列为类别。

3)可视化数据集
为便于可视化及使用二分类(实际也可以使用多分类),这里我们只取前100个类标,其中前50个为山鸢尾类标,后50个为变色鸢尾类标,类标赋给向量y。提取这100个样本中第1、3个特征,并赋值给矩阵X。

4)利用鸢尾花数据集训练感知器,并同时绘制每次迭代的错误分类数量。
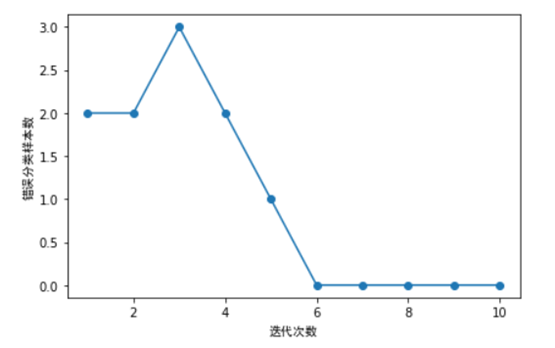
如上图所示,我们的分类器在第6次迭代后,错误数就为0,说明已收敛了。
第1节我们介绍使用Python实现一个单层的感知器神经网络,其激活函数为一个分段函数,这里我们介绍的自适应(Adaline)线性神经网络,其激活函数为一个恒等式。这个可以认为是对前一章神经网络的改进。其权重更新采用了一个连续的线性激活函数(一个恒等函数)来完成,而不是基于分段函数。Adaline算法中作用于净输入的激活函数ϕ(z)是个简单的线性恒等式,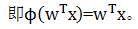 。
。
线性激活函数在更新权重的同时,我们使用量化器对类标进行预测,量化器与上节的单位分段函数类似,自适应线性神经网络的结构如下图所示:
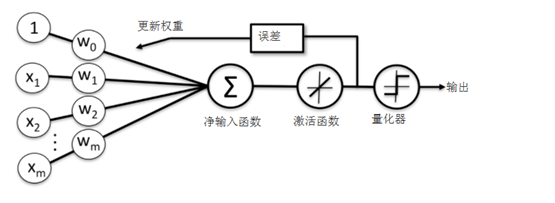
在机器学习中一个最核心的内容就是如何定义一个损失函数及优化损失函数,在自适应算法中,我们可以把模型输出值与实际类标之间的误差平方和(SSE),具体公式如下:
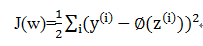
与单位阶跃函数相比,这种连续型激活函数有几个有点:
1)损失函数可导
2)损失函数是一个凸函数,可以通过梯度下降法更新权重,并获取全局最小值。
当然也有一些缺点,线性激活函数无法对非线性数据集进行划分,这点后续我们会介绍。
这里采用梯度下降法(如下图)来最小化损失函数J(w), 首先来看看梯度下降的一个直观的解释。比如我们在一座大山上的某处位置,由于我们不知道怎么下山,于是决定走一步算一步,先确定一个初始位置,然后求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。
从上面的解释可以看出,梯度下降不一定能够找到全局的最优解,有可能是一个局部最优解。当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。所以我们这里的选择凸函数作为我们的损失函数,这是重要考量之一。
通过梯度下降,我们可以基于损失函数J(w)沿着梯度∆J(w)方向做一次权重更新:

为求损失函数的梯度,我们需要计算损失函数对于每个权重w_j的偏导:



从以上图形可以看出,Adaline算法收敛效果不错,迭代到15次后,损失函数逐渐收敛。
【延伸思考】
1)、大家可以调整学习速率这个参数,分几种情况,如大于0.01或小于0.01的情况,然后看一下收敛情况。
2)、这里学习速率是固定不变,我们是否可以在迭代过程中动态调整这个参数?如何调整?
3)这里我们是一次训练整个数据集,如果数据集不大,还可以。如果数据量很大,这种方法就可能带来性能问题。对于大数据集对此,是否可以采用分批训练?如何实现,不妨动手尝试一下。
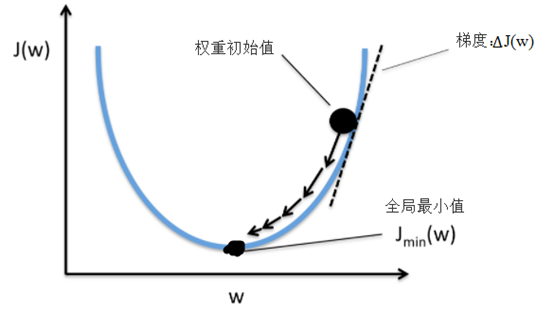
14.3 用Python实现多层神经网络
前面两节,我们分别介绍了感知器神经网络(Rossenblatt提出的)、自适应线性神经网络(Adaline),这两种虽然有激活函数,但只有输入层和输出层,没有隐含层,所以一般称为单层神经网络,这节我们将介绍一种含隐含层的神经网络,这样就有三层,分别为输入层、隐含层、输出层,隐含层的所有单元连接到输入层上,输出层的所有单元也全连接到隐含层中,如下图所示:如下图:
图 三层神经网络
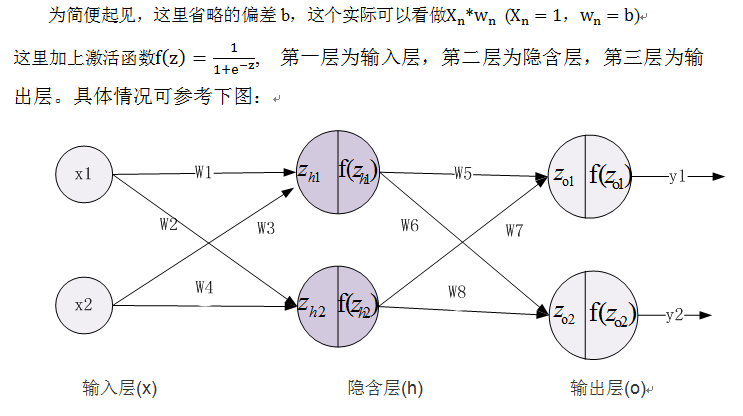
下图为典型的三层神经网络的基本构成,由输入层、隐含层、输出层构成,激活函数取sigmoid函数:

的图形为S型曲线,其输出介于[0,1]之间,如下图:

sigmoid函数的导数比较有特色,下面我们简单演示一下其求导过程:

为便于后续标识统一起见,我们使用Numpy中的向量化的代码,不使用一般的循环方法,所以基本从矩阵或向量的角度考虑各个节点的数据,具体设置如下:

这些矩阵或向量的具体位置,可参考下图:

有了上面这些设置后,我们就可方便设计出这个神经网络的前向传导算法的步骤:

反向传播算法(BP算法)与前向传导算法的方向正好相反,前向传导是从左到右,反向传播算法是从右到左。前向传导把激活值往后传导,反向传播则往前传播梯度,并更新权重参数。
传播的梯度将使损失函数最小化,这里的损失函数我们采用交叉熵函数:

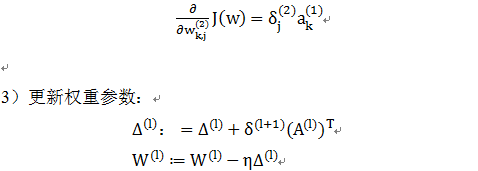
这里以MNIST为数据集,MNIST是一个手写数字0-9的数据集,它有60000个训练样本集和10000个测试样本集它是NIST数据库的一个子集。
MNIST数据库官方网址为:http://yann.lecun.com/exdb/mnist/ ,也可以在windows下直接下载,train-images-idx3-ubyte.gz、train-labels-idx1-ubyte.gz等。下载四个文件,可用
gzip *ubyte.gz -d 解压缩。解压缩后发现这些文件并不是标准的图像格式。这些图像数据都保存在二进制文件中。每个样本图像的宽高为28*28。
【备注】程序具体实现时,做了一些优化,如正则化,自适应学习速率等。
训练模型

【延伸思考】
本章先从最简单的单层感知器入手,然后介绍了Adaline神经元的实现,这两个都是属于单层神经网络,之后,我们介绍了含隐含层的多层神经网络,并重点说明了前向传导、反向传播的原理。这些原理及实现方法应该是神经网络的关键技术之一,是进一步学习深度学习的重要基础。随着层数的不断增多,深度学习遇到各种挑战,如过拟合问题、梯度消失、梯度爆炸问题、性能问题等等,这些问题都是深度学习时必须解决的问题。如何有效解决这些问题,后续介绍深度学习时将会详细说明。
神经网络是一门重要的机器学习技术。它是目前最火热的研究方向--深度学习的基础。学习神经网络不仅可以让你掌握一门强大的机器学习方法,同时也可以更好地帮助你理解深度学习技术。
目前,深度学习(Deep Learning,简称DL)在人工智能领域可谓是大红大紫,现在不只是互联网、人工智能,在教育、医疗、智慧城市、出行、司法、安全、金融等众多领域,都能反映出深度学习引起巨大变化。要学习深度学习,首先要熟悉深度学习的源头--神经网络(Neural Networks,简称NN)。又称为人工神经网络(Artificial Neural Networks,简称ANN)。
神经网络最早是人工智能领域的一种算法或者说是模型,目前神经网络已经发展成为一类多学科交叉的学科领域,它也随着深度学习取得的进展重新受到重视和推崇。
其实,神经网络最为一种算法模型很早就已经开始研究了,最早可以回溯到1946年,到现在近70年了。一路走来,经历了很多波折,其中比较代表性的是其三次大起大落:
1)20世纪40年代到60年代,期间人们陆续发明了第一款的感知神经网络软件和聊天软件,证明了数学定理。不过,很快到了70年代后期,人们发现过去的理论和模型,只能解决一些非常简单的问题,很快人工智能进入了第一次的冬天。
2)20世纪80年代到90年代,随着1982年Hopfield神经网络和BT训练算法的提出,大家发现人工智能的春天又来了。80年代又兴起一拨人工智能的热潮,包括语音识别、语音翻译计划,以及日本提出的第五代计算机。不过,到了90年代后期,人们发现这种东西离我们的实际生活还很遥远。大家都有印象IBM在90年代的时候提出了一款语音听写的软件叫IBM Viavoice,在演示当中效果不错,但是真正用的时候却很难使用。因此,在2000年左右第二次人工智能的浪潮又破灭了。
3)直到2006年,随着2006年Hinton提出的深度学习的技术,以及在图像、语音识别以及其他领域内取得的一些成功,大家认为经过了两次起伏,神经网络、深度学习开始进入了真正爆发的前夜。
我们可以通过一个图来总结这三次浪潮:
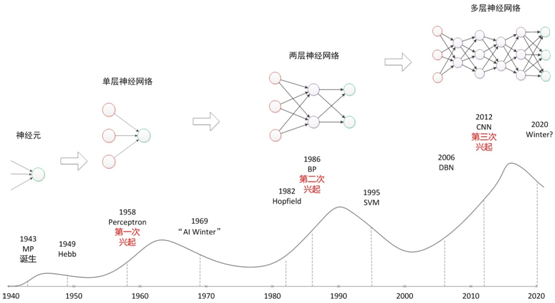
本图片选自:http://www.cnblogs.com/subconscious/p/5058741.html
图中的起伏线,我觉得表达人们对神经网络情感的起落,但从技术上角度来说,应该是条递增曲线。
本章以神经网络为主,着重介绍一些相关的基础知识,然后在此基础上引出深度学习的基本概念。
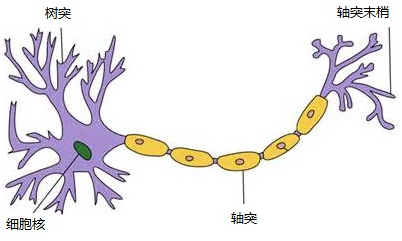
1943年,心理学家McCulloch和数学家Pitts参考了生物神经元的结构(请看下图),发表了抽象的神经元模型MP。
一个神经元模型包含输入,输出与计算功能的模型。下图是一个典型的神经元模型:包含有3个输入,1个输出,以及2个计算功能(一个求和,一个函数f)。

其间的箭头线称为“连接”。每个连接上有一个“权值”,如上图〖的w〗_i,权重是最重要的东西。一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好。
我们使用x来表示输入,用w来表示权值。一个表示连接的有向箭头可以这样理解:在初端,传递的信号大小仍然是x,端中间有加权参数w,经过这个加权后的信号会变成x*w,因此在连接的末端,信号的大小就变成了x*w。
输出y是在输入和权值的线性加权和叠加了一个函数f的值。在MP模型里,函数f又称为激活函数。
从机器学习的角度,我们习惯把已知的属性称之为特征,未知的属性称之为目标。假设特征与目标之间确实是线性关系,并且我们已经得到表示这个关系的权值w1,w2,w3。那么,我们就可以通过神经元模型预测新样本的目标。
1958年,计算科学家Rosenblatt提出了由两层神经元组成的神经网络。他取名为“感知器”(Perceptron)感知器是当时首个可以学习的人工神经网络。Rosenblatt现场演示了其学习识别简单图像的过程,在当时的社会引起了轰动。
人们认为已经发现了智能的奥秘,许多学者和科研机构纷纷投入到神经网络的研究中。美国军方大力资助了神经网络的研究,并认为神经网络比“原子弹工程”更重要。这段时间直到1969年才结束,这个时期可以看作神经网络的第一次高潮。
单层神经网络在原来MP模型的“输入”位置添加神经元节点,标志其为“输入单元”。其余不变,于是我们就有了下图:
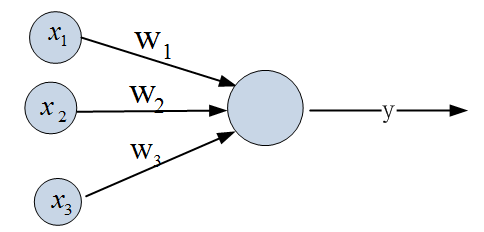
在“感知器”中,有两个层次。分别是输入层和输出层。输入层里的“输入单元”只负责传输数据,不做计算。输出层里的“输出单元”则需要对前面一层的输入进行计算。
假如我们要预测的目标不再是一个值,而是一个向量,例如[0,1]。那么可以在输出层再增加一个“输出单元”。
下图显示了带有两个输出单元的单层神经网络,其中输出单元f1的计算公式如下图。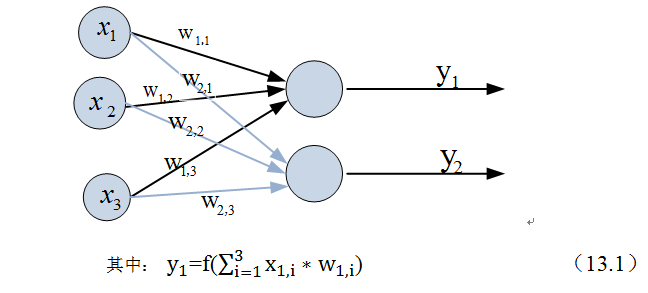

f(W * X) = Y;
这个公式就是神经网络中从前一层计算后一层的矩阵运算。其中f是激活函数,激活函数一般特点是:
1)非线性:为提高模型的学习能力,如果是线性,那么再多层都相当于只有两层效果。
2)可微性:基于梯度的模型最优化方法。
3)单调性:保证模型简单
与神经元模型不同,感知器中的权值是通过训练得到的,它类似一个逻辑回归模型,可以做线性分类任务,但感知器只能做简单的线性分类任务。不过,当时的人们并没有认识到这一点,感知器刚出来一段时间,人们热情高涨,以为找到了打开人工智能的钥匙,当人工智能领域的巨擘Minsky指出其局限性时,事态就发生了变化。
Minsky在1969年出版了一本叫《Perceptron》的书,里面用详细的数学证明了感知器的弱点,尤其是感知器对XOR(异或)这样的简单分类任务都无法解决。如果将计算层增加到两层,计算量则过大,而且没有有效的学习算法。所以,他认为研究更深层的网络是没有价值的。或许由于Minsky的巨大影响力以及书中呈现的悲观态度,让很多学者和实验室纷纷放弃了神经网络的研究,神经网络的研究陷入了第一次低谷。
Minsky说过单层神经网络无法解决异或问题。但是当增加一个计算层以后,两层神经网络不仅可以解决异或问题,而且具有非常好的非线性分类效果。不过两层神经网络的计算是一个问题,没有一个较好的解法。
1986年,Hinton和Rumelhar等人提出了反向传播(Backpropagation,BP)算法,解决了两层神经网络所需要的复杂计算量问题,从而带动了业界使用两层神经网络研究的热潮。目前,大量的教授神经网络的教材,都是重点介绍两层(带一个隐藏层)神经网络的内容。

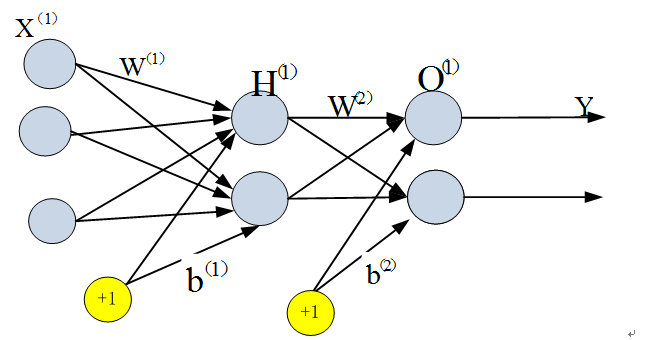
两层神经网络除了包含一个输入层,一个输出层以外,还增加了一个中间层。此时,中间层(又称为隐含层)和输出层都是计算层,如下图:

现在,我们的权值矩阵增加到了两个,我们用上标来区分不同层次之间的变量。

由此可见,使用矩阵运算来表达是很简洁的,而且也不会受到节点数增多的影响(无论有多少节点参与运算,乘法两端都只有一个变量)。因此神经网络的教程中大量使用矩阵运算来描述。
不知大家是否注意到,到目前为止,我们对神经网络的结构图的讨论中都没有提到偏置节点。事实上,这些节点一般默认存在的。它本质上是一个只含有存储功能,且存储值永远为1的单元。在神经网络的每个层次中,除了输出层以外,都会含有这样一个偏置单元。正如线性回归模型与逻辑回归模型中的一样。
偏置单元与后一层的所有节点都有连接,我们设这些参数值为向量b,称之为偏置。如下图:
可以看出,偏置节点很好认,因为其没有输入(前一层中没有箭头指向它)。有些神经网络的结构图中会把偏置节点明显画出来,有些不会。一般情况下,我们都不会明确画出偏置节点。
在考虑了偏置以后的一个神经网络的矩阵运算如下:

事实上,神经网络的本质就是通过参数与激活函数来拟合特征与目标之间的真实函数关系。
前面我们讲了,单层网络只能做线性分类任务,无法对非线性数据集分类。两层神经网络能对非线性数据集分类吗?可以的。
与单层神经网络不同。理论证明,两层神经网络可以无限逼近任意连续函数。那它是如何做到的呢?
从公式(13.4)、(13.5)我们可以看出,从输入层到隐藏层时,为矩阵和向量相乘,本质上就是对向量的坐标空间进行一个变换,使其可以被线性分类,然后输出层的决策分界划出了一个线性分类分界线,对其进行分类。
这里需要强调一下,如果只引入隐含层无法保证可以处理非线性数据。除了增加隐含层,还一个关键要素是隐含层神经元引入激活函数,而且这些激活函数必须非线性。如果这些激活函数是线性,那么可以证明(具体证明大家可参考黄安埠编写的《深入浅出深度学习》),即使增加了隐含层,那么多层神经网络,其效果与单层神经网络没有区别,即,不管增加多少层隐含层,也只能处理线性数据,无法处理非线性数据集。
在设计一个神经网络时,输入层的节点数需要与特征的维度匹配,输出层的节点数要与目标的维度匹配。而中间层的节点数,却是由设计者指定的。节点数设置是否合理,会影响到整个模型的效果。
我们该如何决定隐含层的节点数呢?目前业界没有完善的理论来指导这个决策。一般是根据经验来设置。较好的方法就是预先设定几个可选值,通过切换这几个值来看整个模型的预测效果,最后选择效果较好的那个。
以下我们通过一个实例来具体说明神经网络的前向传播与反向传播的实现方法,理解神经网络的信息传播(包括误差传播)对理解深度学习中很多技术非常有帮助。如深度学习中梯度消失、梯度爆炸等原因将一目了然。
13.5.1 前向传播
在神经网络中,前向传播是利用当前的权重参数和输入数据,从下到上(即从输入层到输出层),求取预测结果,并利用预测结果与真实值求解损失函数的值。如下图:

具体步骤如下:
1、有输入层到隐含层

2、有隐含层到输出层

13.5.2 反向传播
在神经网络中,反向传播是利用前向传播求解的损失函数,从上到下(即从输出层到输入层),求解网络的参数梯度或新的参数值,经过前向和反向两个操作后,完成了一次迭代过程,如下图:
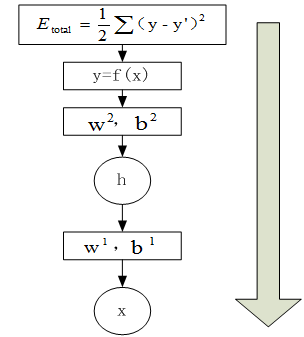
具体步骤如下:
1、计算总误差

2、由输出层到隐含层,假设我们需要分析权重参数w5对整个误差的影响,可以用整体误差对w5求偏导求出:这里利用微分中的链式法则,涉及过程包括:f(Z_O1)--->Z_O1----->W5
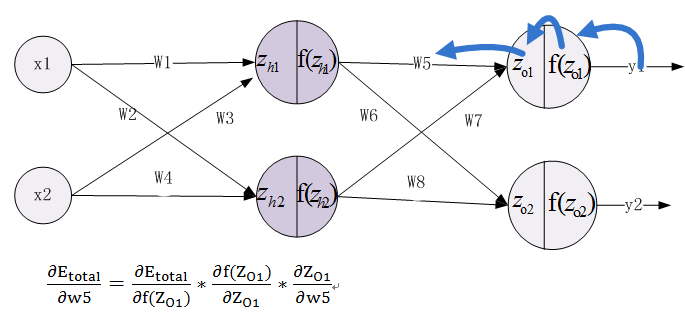
根据公式11.10--11.16,不难求出各部分的偏导数。
最后,调整后的权重为w5’,具体计算公式如下:
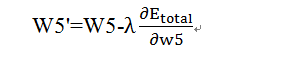
3、由隐含层到输入层,假设我们需要分析权重参数w1对整个误差的影响,可以用整体误差对w1求偏导求出,涉及过程包括:f(Z_h1)--->Z_h1----->W1,不过而f(Z_h1)会接受E_O1和E_O2两个地方传来的误差,所以这个地方两个都要计算。
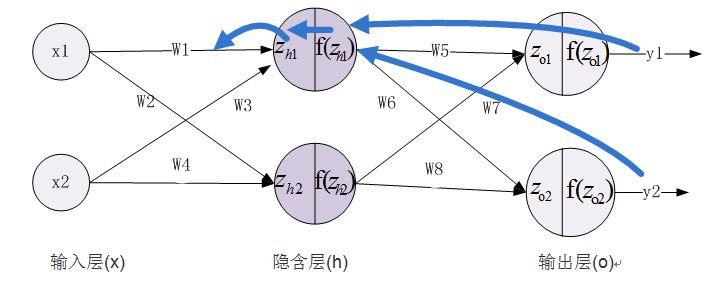

13.6 两层神经网络的优势与局限
两层神经网络在多个地方的应用说明了其效用与价值。10年前困扰神经网络界的异或问题被轻松解决。神经网络在这个时候,已经可以发力于语音识别,图像识别,自动驾驶等多个领域。
历史总是惊人的相似,神经网络的学者们再次登上了《纽约时报》的专访。人们认为神经网络可以解决许多问题。就连娱乐界都开始受到了影响,当年的《终结者》电影中的阿诺都赶时髦地说一句:我的CPU是一个神经网络处理器,一个会学习的计算机。
但是神经网络仍然存在若干的问题:尽管使用了BP算法,一次神经网络的训练仍然耗时太久,而且困扰训练优化的一个问题就是局部最优解问题,这使得神经网络的优化较为困难。同时,隐藏层的节点数需要调参,这使得使用不太方便,工程和研究人员对此多有抱怨。
90年代中期,由Vapnik等人发明的SVM(Support Vector Machines,支持向量机)算法诞生,很快就在若干个方面体现出了对比神经网络的优势:无需调参;高效;全局最优解。基于以上种种理由,SVM迅速打败了神经网络算法成为主流。神经网络的研究再次陷入低谷。
 Vladimir Vapnik
Vladimir Vapnik
我们延续两层神经网络的方式来设计一个多层神经网络。
在两层神经网络的输出层后面,继续添加层次。原来的输出层变成中间层,新加的层次成为新的输出层。所以可以得到下图:
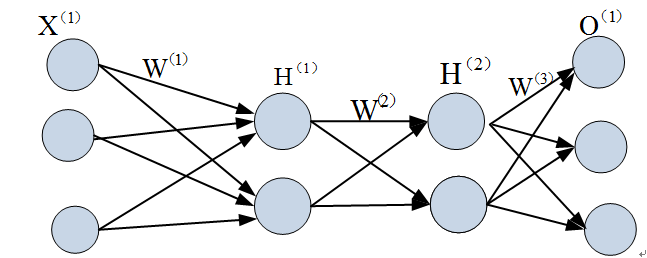
当然,我们也可在这个基础继续添加新层、最终得到一个几十、几百、甚至上千层的神经网络。随着层数的不断增多,也出现很多新问题,如维度爆炸、过拟合、梯度消失、梯度爆炸等等,对这些新出现的问题,该如何解决?这里就展开来说,后面我们介绍深度学习时,会涉及到。
2006年,Hinton在《Science》和相关期刊上发表了论文,首次提出了“深度信念网络”的概念。与传统的训练方式不同,“深度信念网络”有一个“预训练”(pre-training)的过程,这可以方便的让神经网络中的权值找到一个接近最优解的值,之后再使用“微调”(fine-tuning)技术来对整个网络进行优化训练。这两个技术的运用大幅度减少了训练多层神经网络的时间。他给多层神经网络相关的学习方法赋予了一个新名词--“深度学习”。
很快,深度学习在语音识别领域暂露头角。接着,2012年,深度学习技术又在图像识别领域大展拳脚。Hinton与他的学生在ImageNet竞赛中,用多层的卷积神经网络成功地对包含一千类别的一百万张图片进行了训练,取得了分类错误率15%的好成绩,这个成绩比第二名高了近11个百分点,充分证明了多层神经网络识别效果的优越性。

深度学习有很多方法,如卷积神经网络(CNN),循环神经网络(RNN)等,这些神经网络涉及内容比较多,这里就不展开说了,后面在介绍深度学习内容时将详细介绍。这里我们只涉及全连接的深度学习。
增加更多的层次有什么好处?更深入的表示特征,以及更强的函数模拟能力。
更深入的表示特征可以这样理解,随着网络的层数增加,每一层对于前一层次的抽象表示更深入。在神经网络中,每一层神经元学习到的是前一层神经元值的更抽象的表示。例如第一个隐藏层学习到的是“边缘”的特征,第二个隐藏层学习到的是由“边缘”组成的“形状”的特征,第三个隐藏层学习到的是由“形状”组成的“图案”的特征,最后的隐藏层学习到的是由“图案”组成的“目标”的特征。通过抽取更抽象的特征来对事物进行区分,从而获得更好的区分与分类能力。
关于逐层特征学习的例子,可以参考下图:

这一个特征不断抽象的过程:像素==>边==>器官==>人脸
这种对特征逐层抽象的思想,在深度学习中非常普遍而且重要。以下是利用深度学习模型识别猫或狗的训练步骤:
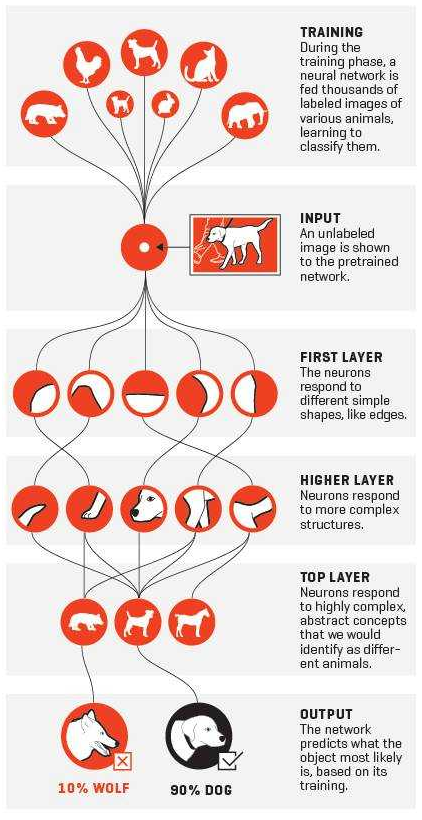
在单层神经网络时,我们使用的激活函数符号函数,如sgn函数。到了两层神经网络时,我们使用的最多的是sigmoid函数。而到了多层神经网络时,通过一系列的研究发现,ReLU函数在训练多层神经网络时,更容易收敛,并且预测性能更好。因此,目前在深度学习中,最流行的非线性函数是ReLU函数。ReLU函数不是传统的非线性函数,而是分段线性函数。其表达式非常简单,就是y=max(x,0)。简而言之,在x大于0,输出就是输入,而在x小于0时,输出就保持为0。这种函数的设计启发来自于生物神经元对于激励的线性响应,以及当低于某个阈值后就不再响应的模拟。
在多层神经网络中,训练的主题仍然是优化和泛化。当使用足够强的计算芯片(例如GPU图形加速卡)时,梯度下降算法以及反向传播算法在多层神经网络中的训练中仍然工作的很好。目前学术界主要的研究既在于开发新的算法,也在于对这两个算法进行不断的优化,例如,增加了一种带动量因子(momentum)的梯度下降算法。
在深度学习中,泛化技术变的比以往更加的重要。这主要是因为神经网络的层数增加了,参数也增加了,表示能力大幅度增强,很容易出现过拟合现象。因此正则化技术就显得十分重要。目前,Dropout技术,以及数据扩容(Data-Augmentation)技术是目前使用的最多的正则化技术。
目前,深度神经网络在人工智能界占据统治地位。但凡有关人工智能的产业报道,必然离不开深度学习。神经网络界当下的四位引领者除了前文所说的Ng,Hinton以外,还有CNN的发明人Yann Lecun,以及《Deep Learning》的作者Bengio。

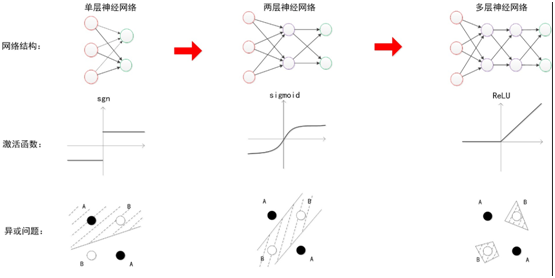
随着层数的不断增加,训练的方法也在不断变化,下图说明期间的一些主要变化:
神经网络其实是一个非常宽泛的称呼,它包括两类,一类是用计算机的方式去模拟人脑,这就是我们常说的ANN(人工神经网络),另一类是研究生物学上的神经网络,又叫生物神经网络。对于我们计算机人士而言,肯定是研究前者。神经网络大致分类,可参考下图:
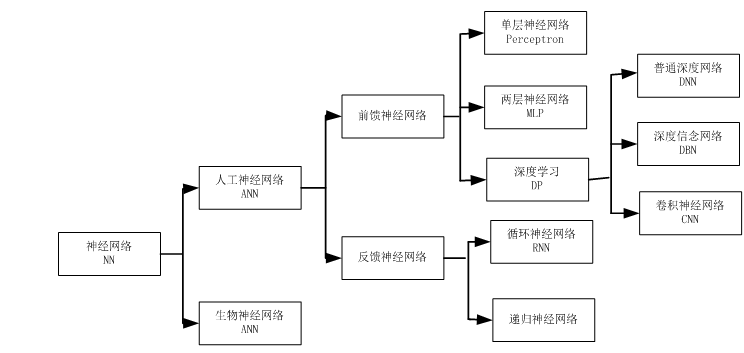
在人工神经网络之中,又分为前馈神经网络和反馈神经网络这两种。那么它们两者的区别是什么呢?这个其实在于它们的结构图。我们可以把结构图看作是一个有向图。其中神经元代表顶点,连接代表有向边。对于前馈神经网络中,这个有向图是没有回路的。你可以仔细观察本文中出现的所有神经网络的结构图,确认一下。而对于反馈神经网络中,结构图的有向图是有回路的。反馈神经网络也是一类重要的神经网络。其中Hopfield网络就是反馈神经网络。深度学习中的RNN也属于一种反馈神经网络。
具体到前馈神经网络中,就有了本文中所分别描述的三个网络:单层神经网络,双层神经网络,以及多层神经网络。深度学习中的CNN属于一种特殊的多层神经网络。另外,在一些Blog中和文献中看到的BP神经网络是什么?其实它们就是使用了反向传播BP算法的两层前馈神经网络。也是最普遍的一种两层神经网络。
参考:http://www.cnblogs.com/subconscious/p/5058741.html
本文将使用Python来可视化股票数据,比如绘制K线图,并且探究各项指标的含义和关系,最后使用移动平均线方法初探投资策略。
这里将股票数据存储在stockData.txt文本文件中(下载数据),我们使用pandas.read_table()函数将文件数据读入成DataFrame格式。
其中参数usecols=range(15)限制只读取前15列数据,parse_dates=[0]表示将第一列数据解析成时间格式,index_col=0则将第一列数据指定为索引。
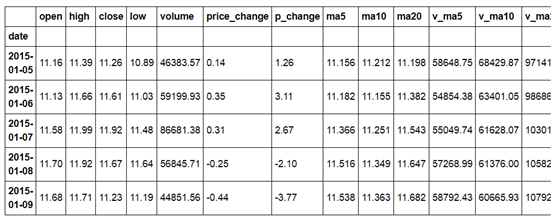
以上显示了前5行数据,要得到数据的更多信息,可以使用.info()方法。它告诉我们该数据一共有20行,索引是时间格式,日期从2015年1月5日到2015年1月30日。总共有14列,并列出了每一列的名称和数据格式,并且没有缺失值。
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 20 entries, 2015-01-05 to 2015-01-30
Data columns (total 14 columns):
open 20 non-null float64
high 20 non-null float64
close 20 non-null float64
low 20 non-null float64
volume 20 non-null float64
price_change 20 non-null float64
p_change 20 non-null float64
ma5 20 non-null float64
ma10 20 non-null float64
ma20 20 non-null float64
v_ma5 20 non-null float64
v_ma10 20 non-null float64
v_ma20 20 non-null float64
turnover 20 non-null float64
dtypes: float64(14)
memory usage: 2.3 KB
在观察每一列的名称时,我们发现'open'的列名前面似乎与其它列名不太一样,为了更清楚地查看,使用.columns得到该数据所有的列名如下:
Index([' open', 'high', 'close', 'low', 'volume', 'price_change','p_change', 'ma5', 'ma10', 'ma20', 'v_ma5', 'v_ma10', 'v_ma20','turnover'], dtype='object')
于是发现'open'列名前存在多余的空格,我们使用如下方法修正列名。
至此,我们完成了股票数据的导入和清洗工作,接下来将使用可视化的方法来观察这些数据。
首先,我们观察数据的列名,其含义对应如下:

这些指标总体可分为两类:
• 价格相关指标
o 当日价格:开盘、收盘价,最高、最低价
o 价格变化:价格变动和涨跌幅
o 均价:5、10、20日均价
• 成交量相关指标
o 成交量
o 换手率:成交量/发行总股数×100%
o 成交量均量:5、10、20日均量
由于这些指标都是随时间变化的,所以让我们先来观察它们的时间序列图。
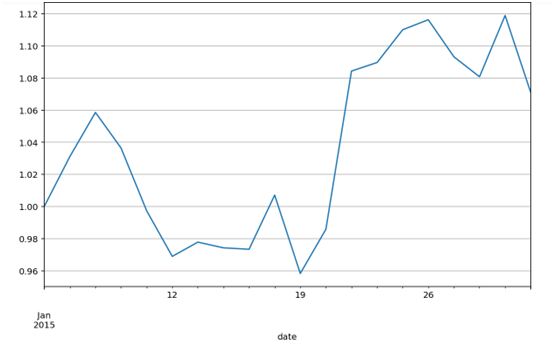
以时间为横坐标,每日的收盘价为纵坐标,做折线图,可以观察股价随时间的波动情况。这里直接使用DataFrame数据格式自带的做图工具,其优点是能够快速做图,并自动优化图形输出形式。
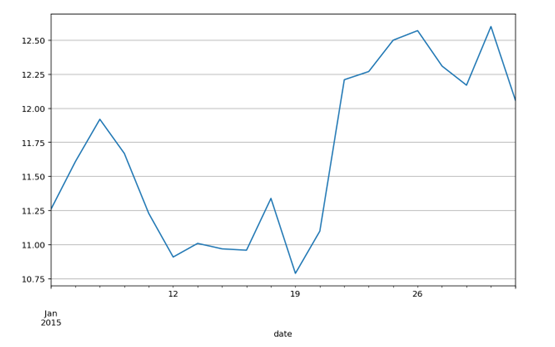
如果我们将每日的开盘、收盘价和最高、最低价以折线的形式绘制在一起,难免显得凌乱,也不便于分析。那么有什么好的方法能够在一张图中显示出这四个指标?答案下面揭晓。
相传K线图起源于日本德川幕府时代,当时的商人用此图来记录米市的行情和价格波动,后来K线图被引入到股票市场。每天的四项指标数据用如下蜡烛形状的图形来记录,不同的颜色代表涨跌情况。
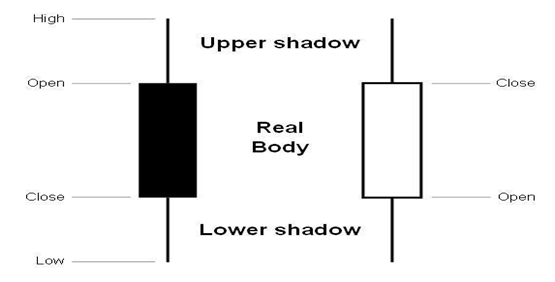
Matplotlib.finance模块提供了绘制K线图的函数candlestick_ohlc(),但如果要绘制比较美观的K线图还是要下点功夫的。下面定义了pandas_candlestick_ohlc()函数来绘制适用于本文数据的K线图,其中大部分代码都是在设置坐标轴的格式。
运行定义的函数
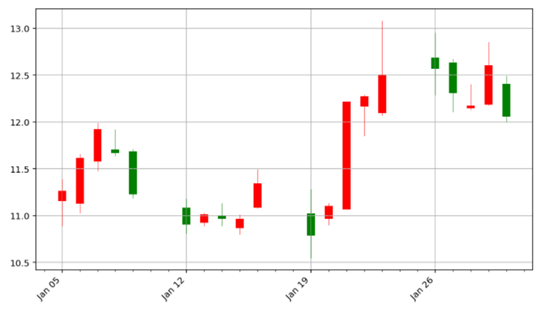
这里红色代表上涨,绿色代表下跌。
股票中关注的不是价格的绝对值,而是相对变化量。有多种方式可以衡量股价的相对值,最简单的方法就是将股价除以初始时的价格。

第二种方法是计算每天的涨跌幅,但计算方式有两种:
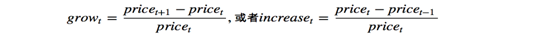
这两者可能导致不同的分析结果,样例数据中的涨跌幅使用的是第一个公式,并乘上了100%。
为了解决第二种方法中的两难选择,我们引入第三种方法,就是计算价格的对数之差,公式如下:


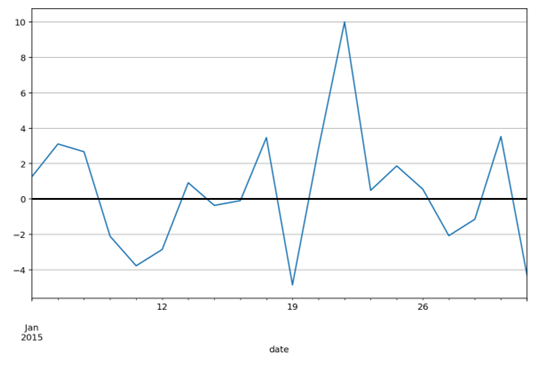
在观察了价格的走势之后,我们来看看各指标之间的关系。下面挑选了部分代表性的指标,并使用pandas.scatter_matrix()函数,将各项指标数据两两关联做散点图,对角线是每个指标数据的直方图。
图中可以明显发现成交量(volume)和换手率(turnover)有非常明显的线性关系,其实换手率的定义就是:成交量除以发行总股数,再乘以100%。所以下面的分析中我们将换手率指标去除,这里使用了相关性关系来实现数据降维。
上面的散点图看着有些眼花缭乱,我们可以使用numpy.corrcof()来直接计算各指标数据间的相关系数。
如果觉得看数字还是不够方便,我们继续将上述相关性矩阵转换成图形,如下图所示,其中用颜色来代表相关系数。我们发现位于(0,3)位置的相关系数非常大,查看数值达到0.91。这两个强烈正相关的指标是收盘价和成交量。

以上我们用矩阵图表的方式在多个指标中迅速找到了强相关的指标。接着做出收盘价和成交量的折线图,因为它们的数值差异很大,所以我们采用两套纵坐标体系来做图。
stock[['close','volume']].plot(secondary_y='volume', grid=True)
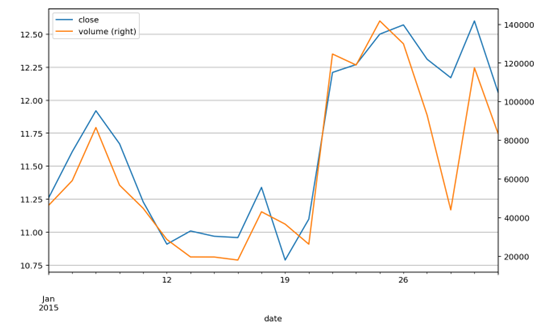
观察这两个指标的走势,在大部分时候股价上涨,成交量也上涨,反之亦然。但个别情况下则不成立,可能是成交量受到前期的惯性影响,或者还有其他因素。
吴军老师曾讲述他的投资经验,大意是说好的投资方式不是做预测,而是能在合适的时机做出合适的应对和决策。同样股市也没法预测,我们能做的是选择恰当的策略应对不同的情况。
好的指标是能驱动决策的。在上面的分析中我们一直没有使用的一类指标是5、10、20日均价,它们又称为移动平均值,下面我们就使用这项指标来演示一个简单的股票交易策略。(警告:这里仅仅是演示说明,并非投资建议。)
为了得到更多的数据来演示,我们使用pandas_datareader直接从雅虎中下载最近一段时间的谷歌股票数据。
【备注】:pandas_datareader 库如果不存在,可用pip 安装。

数据中只有每天的价格和成交量,所以我们需要自己算出5日均价和10日均价,并将均价的折线图(也称移动平均线)与K线图画在一起。

观察上图,我们发现5日均线与K线图较为接近,而20日均线则更平坦,可见移动平均线具有抹平短期波动的作用,更能反映长期的走势。比较5日均线和20日均线,特别是关注它们的交叉点,这些是交易的时机。移动平均线策略,最简单的方式就是:当5日均线从下方超越20日均线时,买入股票,当5日均线从上方越到20日均线之下时,卖出股票。
为了找出交易的时机,我们计算5日均价和20日均价的差值,并取其正负号,作于下图。当图中水平线出现跳跃的时候就是交易时机。
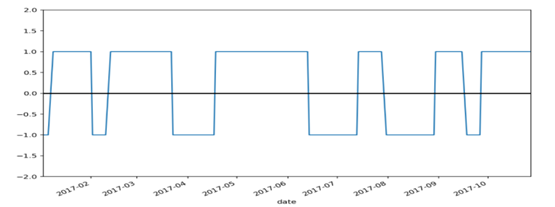
为了更方便观察,上述计算得到的均价差值,再取其相邻日期的差值,得到信号指标。当信号为1时,表示买入股票;当信号为-1时,表示卖出股票;当信号为0时,不进行任何操作。
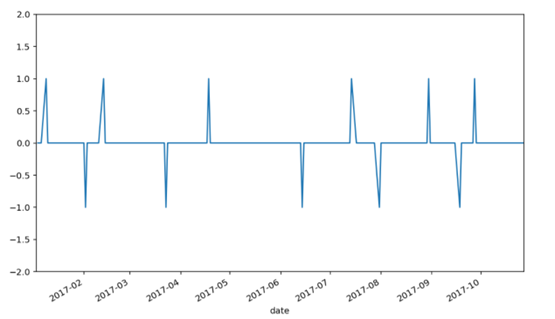
从上图中看出,从今年初到现在,一共有两轮买进和卖出的时机。到目前为止,似乎一切顺利,那么让我们看下这两轮交易的收益怎么样吧。
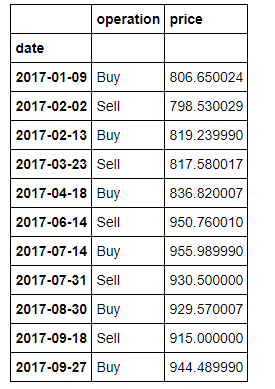
上述表格列出了交易日期、操作和当天的价格。但很遗憾地发现,这两轮交易的卖出价都小于买入价,实际上按上述方法交易我们亏本了!!!
你是否很愤怒呢?原来分析到现在,都是假的呀!我之前就警告过,这里的分析只是演示移动平均线策略的思想,而并非真正的投资建议。股票市场是何其的复杂多变,又如何是一个小小的策略所能战胜的呢?
那么这个策略就一无是处吗?非也!如果考虑更长的时间跨度,比如5年、10年,并考虑更长的均线,比如将20日均线和50日均线比较;虽然过程中也有亏损的时候,但赢的概率更大。也就是说,在更长的时间尺度上该策略也是可行的。但即使你赚了,又能跑赢大盘吗?这时候还需用到其他方法,比如合理配置投资比例等。
还是那句话,股市有风险,投资需谨慎。本文不是分析股票的文章,而是借用股票数据来说明数据分析的基本方法,以及演示什么样的指标是好的指标。
参考博客:http://www.jianshu.com/p/ce0e0773c6ec#
在介绍MySQL时,我们了解了其查询功能非常强大,既可单表查询、也可多表查询、还可以实现子查询等等,而且实现起来还非常方便,写几个SQL语句就可轻松搞定。假如某天你想参加大数据方面的竞赛,主办方给你的数据不是数据库的表,而是几个数据文件(这样的情况非常普遍),要求你基于这些数据文件(如文本文件、excel文件等)进行预测或分类等,此时你该如何处理呢?把这些文件导入数据库,然后用SQL进行处理?有时也是方法之一,但,假如主办方不提供数据库呢?实际也没关系!我们可以就数据文件进行处理、进行合并、聚合等操作,甚至可以比SQL做更多事情,如何处理呢?这就是本章将介绍的内容。
本章主要内容:
合并数据文件
旋转数据
新增指标
聚合数据
在MySQL的多表查询章节中,我们介绍了两表关联问题,具体请看如下图形;
(图3-1 多表关联)
如果现在把表换成数据文件或数据集,该如何实现呢?Python中有类似方法,把连接的关键字有JION改为MERGE一下就可,其它稍作修改,具体请看下表:
(表3-2 两个DataFrame数据集关联格式表)
关联方式 关联语句

下面同时示例来说明以上命令的具体使用。
两个集合连接以后,有些值可能为空或为NaN,NaN值有时计算不方便,我们可以把NaN修改为其它值,如为0值等,如果要修改或补充为0值,该如何操作呢?非常方便,利用DataFrame的fillna函数即可。其使用方法如下:
上节我们介绍了有时便于数据分析,需要把两个或多个数据集合并在一起,这在大数据的分析或竞赛中是经常干的事。不过有时为便于分析,需要把一些连续性数据离散化或进行拆分,这也是数据分析常用方法,如对年龄字段,可能需转换成年龄段,这样可能更好地对数据的进行分类或预测,这种处理方式往往能提升分类或预测性能,这种方法又称为离散化或新增衍生指标等。这方面的实例在Spark中将介绍。
如何离散化连续性数据?在一般开发语言中,可以通过控制语句来实现,但如果分类较多时,这种方法不但繁琐,效率也比较低。在Pandas中是否有更好方法?如果有,又该如何实现呢?
pandas有现成方法,如cut或qcut等,不需要编写代码,至于如何使用还是通过实例来说明。
对连续性字段进行离散化是机器学习常用方法,此外,对一些类型字段,如上例中type字段,含有1,2两种类型,实际上1,2两种类型是平等,它们只是代表不同类型,并无大小区别,如果在回归分析中如果用1、2代入算法中,则与业务含义就不相符了,对这种情况,我们该如何处理呢?
在机器学习中通常把这些分类变量或字段转换为“指标矩阵”或“哑变量矩阵”,具体做法就是,假设该字段或变量有k种取值(上例中type只有2中取值),则可派生出一个k列矩阵,矩阵值为0或1,0表示无对应分类,1表示有对应分类。我们可以编写程序实现,也可用Pandas中get_dummies函数来实现,具体实现请看以下示例。
【说明】
这种方法,在SparkML中有专门的算法--独热编码(OneHotEncoder),独热编码将标签指标映射为二值向量,其中最多一个单值。这种编码被用于将种类特征使用到需要连续特征的算法,如逻辑回归等。
我们平常看到的数据格式大多像数据库中的表,如购买图书的基本信息:
(表3-1 客户购买图书信息)
书名 书代码 购买客户 购买数量
这样的数据比较规范,比较适合于一般的统计分析。但如果我们欲依据这些数据来对客户进行推荐或计算客户的相似度,就需要把以上数据转换为如下格式:
(表3-2 客户购买图书的对应关系)
我们观察一下不难发现,把表3-1中书代码列旋转为行就得到表3-2数据。如何实现行列的互换呢?编码能实现,但比较麻烦,还好,pandas提供了现成的方法或函数,如stack、unstack、pivot_table函数等。以下以pivot_table为例说明具体实现。
MySQL中我们介绍了分组聚合计算,具体通过函数Group by对数据进行分组统计,参与分组的字段可以一个或多个,分组后可以进行分组汇总、求平均值等计算。在Pandas的DataFrame格式的数据该如何进行分组及聚合呢?与MySQL非常类似,我们可以像操作数据库中表一样操作DataFrame格式数据。这或许得益于DataFrame结构类似于数据库中表。
具体如何实现,我们还是通过示例来说明。
人工智能最重要的动力就是数据,没有充分数据的人工智能是毫无意义的,数据越大人工智能将越聪明,所以数据是非常重要的。因此整合各种数据的能力也是各种开发工具非常重视的,Python在这方面功能很强大。这一章我们将介绍如何利用Python存取数据库中的数据。
目前企业数据大都存储在数据库中,如MySQL、Oracle、DB2等关系型数据库,这些数据库目前使用非常广泛,由于其独特优势,未来还将大量使用;但随着数据量、数据种类的不断增长,目前非关系型数据库也越来越普及了,如MongoDB、Redis、HBase等等,这些数据库有时又称为NoSQL型数据库。所有这些数据是目前大数据的主要源头,因此,如何使用抽取、整合、处理及分析这些数据是非常重要。
这章主要内容:
操作MySQL
操作MongoDB
Python使用MySQL非常简单,先导入python有关mysql的驱动模块,然后建立与数据库的连接即可。
以下通过实例来说明。
MongoDB 是一个基于分布式文件存储的数据库。由C++语言编写。它是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。 它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo可以有多个数据库,每个数据库中数据或文档被分组存储在数据集合(Collection)中。每个集合在数据库中都有一个唯一的标识名,并且可以包含无限数目的文档。集合的概念类似关系型数据库(RDBMS)里的表(table),不同的是它不需要定义任何模式(schema)。
以下通过一个实例来说明,如何连接mongodb,然后创建集合,并往集合中插入记录,并查询该条记录或文档。
当然也可同时往集合插入多条记录:
关系型数据可以使用DataFrame函数转换为DataFrame格式,Mongodb格式的数据能否转换?如果能,该如何转换呢?可以的,而且方式与关系型数据库类型,请看以下示例:
正则化在机器学习、深度学习中运用非常广泛,机器学习中在回归、降维时经常使用,在目前很火的深度学习中为避免过拟合也常使用。为何它作用如此之大,它的大致原理和作用是啥?接下来我们来做个简单介绍。
在机器学习中,很多被显式地设计用来减少测试误差的策略,统称为正则化。正则化旨在减少泛化误差而不是训练误差。目前有许多正则化策略。有些策略向机器学习模型添加限制参数值的额外约束,如L1、L2等;有些策略向目标函数增加额外项对参数值进行软约束,如作为约束的范数惩罚等。这些惩罚和约束通常用来使模型更简单,以便提高模型的泛化能力,当然也有些正则化,如集成方法,是为了结合多个假说来更好解释训练数据。
正则化是机器学习领域的中心问题之一,其重要性只有优化问题才能与之匹敌。
正则化的作用、原理,我们还是先从几张图来说明吧,图形直观明了,易说明问题。

(图1 测试误差与训练误差)
(图2 根据房屋面积预测房价几个回归模型)
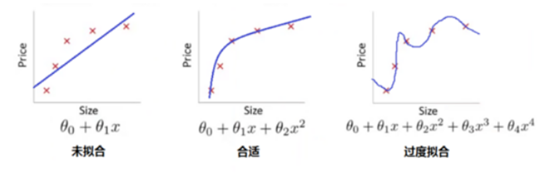
这两个图说明了:
(1)、图1说明了,模型不是越复杂越好,训练精度随复杂度逐渐变小;测试误差刚开始随着模型复杂度而变小,但当复杂度超过某点之后,测试误差不但不会变小,反而会越来越大;
(2)、图2是对图1的一个示例说明。
上面我们讲了正则化的主要目的就是提高模型的泛化能力,或降低模型的测试误差。在实际模型中,它是如何实现的呢?
我们以图2中最右边这个图来说,其模型是一个4次多项式,因它把一些噪音数据也包括进来了,所以导致模型很复杂,实际上房价与房屋面积应该是2次多项式函数,如图2中间这个图。

当然这里我们取10000只是用来代表一个"大值",现在,如果我们要最小化这个函数,那么为了最小化这个新的代价函数,我们要让 θ3 和 θ4 尽可能小。因为,如果你在原有代价函数的基础上加上 10000 乘以 θ3 这一项 ,那么这个新的代价函数将变得很大,所以,当我们最小化这个新的代价函数时, 我们将使 θ3 的值接近于 0,同样 θ4 的值也接近于 0,就像我们忽略了这两个值一样。如果我们做到这一点( θ3 和 θ4 接近 0 ),那么我们将得到一个近似的二次函数。如下图:
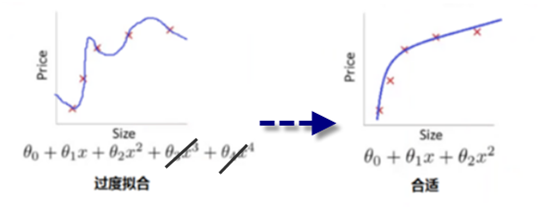
图3 利用正则化提升模型泛化能力
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1-norm和ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数。
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。下式是Python中Lasso回归的损失函数,式中加号后面一项α||w||1即为L1正则化项。
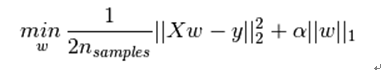
下式是Python中Ridge回归的损失函数,式中加号后面一项α||w||22即为L2正则化项。
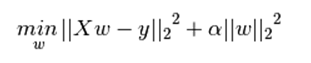
一般回归分析中回归w表示特征的系数,从上式可以看到正则化项是对系数做了处理(限制)。L1正则化和L2正则化的说明如下:
L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为〖||w||〗_1
L2正则化是指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为〖||w||〗_2
一般都会在正则化项之前添加一个系数,Python中用α表示,一些文章也用λ表示。这个系数需要用户指定。
L1正则化和L2正则化的作用:
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
1)L1正则化和特征选择
假设有如下带L1正则化的损失函数:
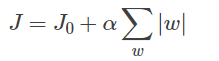

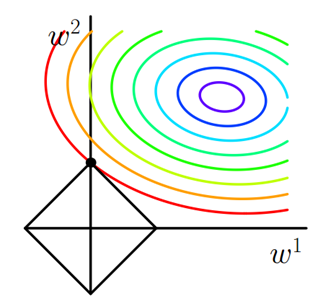
图4 L1正则化

同样可以画出他们在二维平面上的图形,如下:
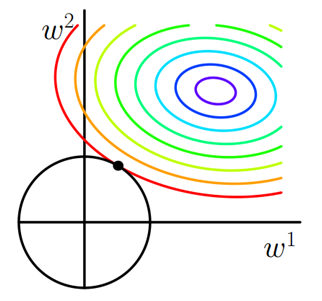
图5 L2正则化

2)L2正则化和过拟合
拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,提高模型的鲁棒性。
那为什么L2正则化可以获得值很小的参数?
以线性回归中的梯度下降法为例。假设要求的参数为θ,h_θ (x)是我们的假设函数,那么线性回归的代价函数如下:

其中λ就是正则化参数。从上式可以看到,与未添加L2正则化的迭代公式相比,每一次迭代,θj都要先乘以一个小于1的因子(如1-αλ/m),从而使得θj不断减小,因此总得来看,θ是不断减小的。
L1正则化一定程度上也可以防止过拟合。L1可以是权重系数逼近于0或等于0,这样可以简化模型,提高模型的泛化能力,从而达到与L2正则化类似的效果。
这里我们以逻辑回归实例来具体说明,在算法中如何利用正则化策略惩罚参数值的。

因此,减少正则化参数倒数C的值就相当于增强正则化的强度,以下我们通过绘制对四个权重系数进行L2正则化的图像予以展示。
1)导入数据
2)把数据集划分为训练集和测试集,划分比例为7:3
3)对逻辑回归加入正则化项,并对C的不同取值,对权重的影响图形化。
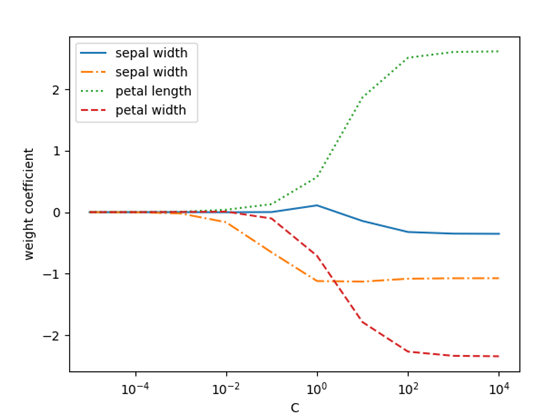
图6 利用正则化控制逻辑回归权重参数值
从上图我们不难看出,如果我们减小参数C的值,即增强正则化项的强度,可以使权重系统逐渐收缩。
Dropout是Srivastava等人在2014年的一篇论文中提出的一种针对神经网络模型的正则化方法 Dropout: A Simple Way to Prevent Neural Networks from Overfitting。
Dropout的做法是在训练过程中按一定比例(比例参数可设置)随机地忽略一些神经元。这些神经元被随机地“抛弃”了。也就是说它们在正向传播过程中对于下游神经元的贡献效果暂时消失了,反向传播时该神经元也不会有任何权重的更新。
随着神经网络模型不断地学习,神经元的权值会与整个网络的上下文相匹配。神经元的权重针对某些特征进行调优,具有一些特殊化。周围的神经元则会依赖于这种特殊化,如果过于特殊化,模型会因为对训练数据过拟合而变得脆弱不堪。神经元在训练过程中的这种依赖于上下文的现象被称为复杂的协同适应(complex co-adaptations)。
这么做的效果就是,网络模型对神经元特定的权重不那么敏感。这反过来又提升了模型的泛化能力,不容易对训练数据过拟合。
Dropout训练的集成包括所有从基本的基础网络除去非输出单元形成 子网络,如在图7所示。
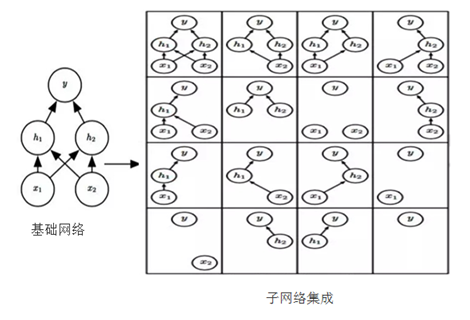
图 7 基础网络Dropout为多个子网络
Dropout训练由所有子网络组成的集成,其中子网络通过从基本网络中删除非输出单元构 建。我们从具有两个可见单元和两个隐藏单元的基本网络开始。这四个单元有十六个可能的子集。 右图展示了从原始网络中丢弃不同的单元子集而形成的所有十六个子网络。在这个小例子中,所 得到的大部分网络没有输入单元或没有从输入连接到输出的路径。当层较宽时,丢弃所有从输入 到输出的可能路径的概率变小,所以这个问题对于层较宽的网络不是很重要。
较先进的神经网络基于一系列仿射变换和非线性变换,我 们可以将一些单元的输出乘零就能有效地删除一个单元。这个过程需要对模型一些 修改,如径向基函数网络,单元的状态和参考值之间存在一定区别。为了简单起见, 我们在这里提出乘零的简单Dropout算法,但是它被简单地修改后,可以与从网络中 移除单元的其他操作一起工作。
回想一下使用Bagging学习,我们定义 k 个不同的模型,从训练集有替换采样 构造 k 个不同的数据集,然后在训练集 i 上训练模型 i。Dropout的目标是在指数 级数量的神经网络上近似这个过程。具体来说,训练中使用Dropout,我们使用基 于minibatch的学习算法和小的步长,如梯度下降等。我们每次在minibatch加载一个 样本,然后随机抽样应用于网络中所有输入和隐藏单元的不同二值掩码。对于每个 单元,掩码是独立采样的。掩码值为 1 的采样概率(导致包含一个单元)是训练开 始前固定一个超参数。它不是模型当前参数值或输入样本的函数。通常一个输入单 元包括的概率为 0.8,一个隐藏单元包括的概率为 0.5。然后,我们运行之前一样的 前向传播、反向传播以及学习更新。图8说明了在Dropout下的前向传播。
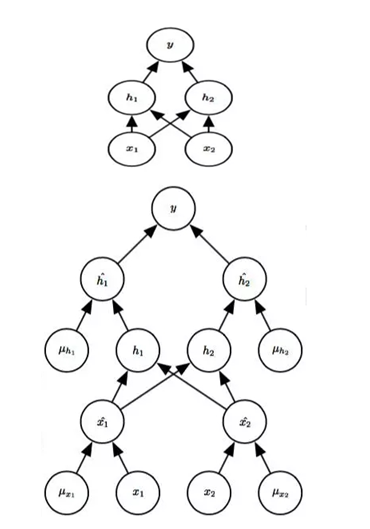
图 8
在使用Dropout的前馈网络中前向传播的示例。(顶部) 在此示例中,我们使用具有两个输入 单元,具有两个隐藏单元的隐藏层以及一个输出单元的前馈网络。(底部) 为了执行具有Dropout的 前向传播,我们随机地对向量 μ 进行采样,其中网络中的每个输入或隐藏单元对应一项。μ 中的 每项都是二值的且独立于其他项采样。每项为 1 的概率是超参数,对于隐藏层通常为 0.5,对于输 入通常为 0.8。网络中的每个单元乘以相应的掩码,然后正常地继续通过网络的其余部分前向传 播。这相当于从图7中随机选择一个子网络并通过它前向传播。
1)通常丢弃率控制在20%~50%比较好,可以从20%开始尝试。如果比例太低则起不到效果,比例太高则会导致模型的欠学习。
2)在大的网络模型上应用。当dropout用在较大的网络模型时更有可能得到效果的提升,模型有更多的机会学习到多种独立的表征。
3)在输入层(可见层)和隐藏层都使用dropout。在每层都应用dropout被证明会取得好的效果。
4)增加学习率和冲量。把学习率扩大10~100倍,冲量值调高到0.9~0.99.
5)限制网络模型的权重。大的学习率往往导致大的权重值。对网络的权重值做最大范数正则化等方法被证明会提升效果。
L1、L2是我们常见正则化方式,正则化在机器学习中运用非常广泛,而且功能很强大,经常用来提升模型的泛化能力,此外,正则化策略还包括dropout、数据集增强等,甚至提前终止、集成方法、参数绑定与共享等都与正则化有千丝万缕的关系。其中有些正则化策略这里不展开来说了,后续在深度学习中我们会介绍。
本章参考以下博客或书:
http://www.cnblogs.com/jianxinzhou/p/4083921.html
http://blog.csdn.net/jinping_shi/article/details/52433975
《Python机器学习》塞巴斯蒂安.拉施卡 著
支持向量机(SupportVector Machines),在处理线性数据集、非线性数据集都有较好效果,在机器学习或者模式识别领域可是无人不知,无人不晓。八九十年代的时候,和神经网络一决雌雄,独领风骚几十年,甚至有人把神经网络八九年代的再度沉寂归功于它。
它的强大或神奇与它采用的相关技术不无关系,如最大类间隔、松弛变量、核函数等等(这些技术本章都会介绍),使用这些技术使其在众多机器学习方法中脱颖而出。虽然几十年过去了,但风采依旧,究其原因:与其高效、简洁、易用的特点分不开,其中一些处理思想与当今深度学习技术有很大关系,如其用核方法解决非线性数据集分类问题,很像带隐含层的神经网络,可以说两者有同工异曲之妙。
分类的方法有很多,如线性回归、逻辑回归、决策树、贝叶斯等等,分类的目的是学会一个分类函数或分类模型(或者叫做分类器),该模型能把数据集中的数据项映射到给定类别中的某一个,对新数据通过这个映射,预测其类别。
支持向量机进行分类,目的也是一样:得到一个分类器或分类模型,不过它的分类器一个超平面(如果数据集是二维,这个超平面就是直线,三维数据集,就是平面,以此类推),这个超平面把样本一分为二,当然,这种划分不是简单划分,需要使正例和反例之间的间隔最大。间隔最大,其泛化能力就最强。如何得到这样一个超平面?下级我们通过用一个二维空间例子来说明。
何为超平面?哪种超平面是我们需要?,我们首先看下图的几个超平面或直线。

如何获取最大化分类间隔?分类算法优化目标通常是最小化分类误差,但对SVM而言,我们的优化的目标是最大化分类间隔。所谓间隔是指两个分离的超平面间的距离,其中最靠近超平面的训练样本又称为支持向量(support vector)。以下我们通过一个二维空间的简单实例来进一步说明。
假设在一个二维空间,分布下例这些点(有些是圆点,有些是方块)。



所以我们的问题就变成:

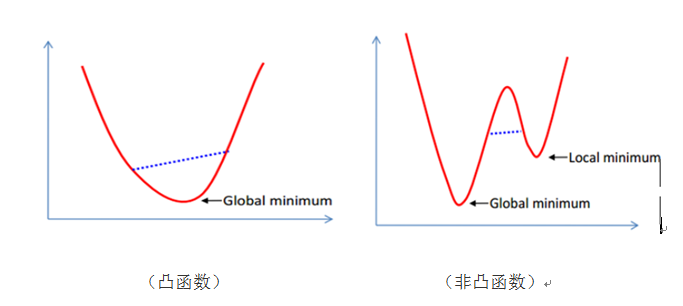
这是个凸二次规划问题。什么叫凸?凸集是指这样一些点的集合,其中任取两个点连一条直线,这条线上的点仍然在这个集合内部,因此说“凸”。例如下图,对于凸函数(在数学表示上,满足约束条件是仿射函数,也就是线性的Ax+b的形式)来说,局部最优就是全局最优,但对非凸函数来说就不是了。二次表示目标函数是自变量的二次函数。
既然是凸二次规划问题,就可以通过一些现成的 QP (Quadratic Programming) 的优化工具来得到最优解。所以,我们的问题到此为止就算全部解决了。虽然这个问题确实是一个标准的 QP 问题,但是它也有它的特殊结构,通过 Lagrange Duality 变换到对偶变量 (dual variable) 的优化问题之后,可以找到一种更加有效的方法来进行求解,而且通常情况下这种方法比直接使用通用的 QP 优化包进行优化要高效得多。也就说,除了用解决QP问题的常规方法之外,还可以应用拉格朗日对偶性,通过求解对偶问题得到最优解,这就是线性可分条件下支持向量机的对偶算法,这样做的优点在于:一是对偶问题往往更容易求解;二者可以自然的引入核函数,进而推广到非线性分类问题。至于对偶问题及其优化这里就不展开来说了,有兴趣的读者可以参考有关资料。
实际数据集往往很难找到一条直线或一个超平面就可一分为二,或者这些数据集是线性可分的。如果出现非线性数据集,我们该如何处理呢?这里我们介绍一种所谓软间隔的分类方法,这种方法由Vladimir Vapnik在1995年引入,其基本思想是引入一个松弛系数ξ,放松线性约束的条件,以便在适当的罚项成本下,对错误分类的情况优化时也能收敛。
为了处理这种情况,我们允许数据点在一定程度上偏离超平面。也就是允许一些点跑到H1和H2之间,也就是他们到分类面的间隔会小于1。如下图:
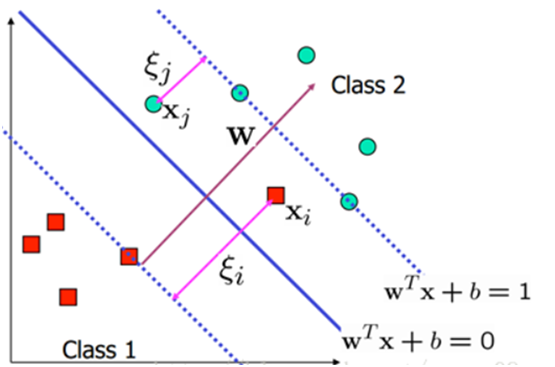

其中C是离群点的权重,引入非负参数ξi后(称为松弛变量),就允许某些样本点的函数间隔小于1,即在最大间隔区间里面,或者函数间隔是负数,即样本点在对方的区域中。而放松限制条件后,我们需要重新调整目标函数,以对离群点进行处罚,目标函数后面加上的第二项就表示离群点越多,目标函数值越大,而我们要求的是尽可能小的目标函数值。通过变量C我们可以控制对错误分类的惩罚程度。C越大表明离群点对目标函数影响越大,也就是越不希望看到离群点。这时候,间隔也会很小。我们看到,目标函数控制了离群点的数目和程度,使大部分样本点仍然遵守限制条件,如下图所示:

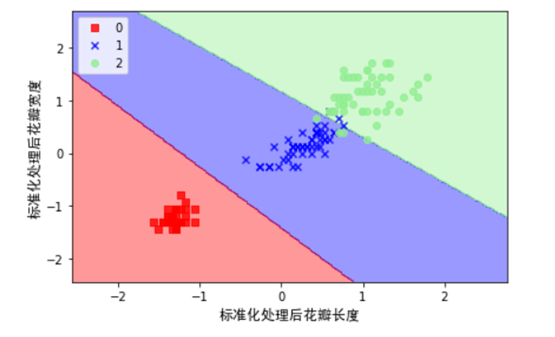
至此,我们已经了解了线性SVM的基本概念,主要原理,接下来我们通过一个实例来演示一个SVM模型对鸢尾花数据集中的样本进行分类。
接下来我们以鸢尾花卉数据集(lris)样本,使用SVM对其进行分类,lris是一类多重变量分析的数据集。通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
1)导入数据
使用sklearn中导入数据的库(datasets)进行数据的导入,为方便可视化起见,这里我们花瓣长度,花瓣宽度为两个特征,并由此构建一个特征矩阵X,同时将对应花的类标赋给向量Y,具体实现如下:
2)对数据进行标准化处理
4)为更好的显示划分后的效果,这里我们先定义几个函数,用来图形化数据。
5)利用SVM对对数据集进行分类,这里使用了松弛变量来处理非线性数据集。
上节我们介绍了使用松弛变量处理非线性数据集(含有一些离群点)问题,效果还不错。但有些数据集其分布就是非线性可分的,如比较典型的“异或”问题,遇到这种数据集,我们该如何处理呢?显然使用松弛变量难以达到满意效果,不过没有关系,此时,我们可以使用SVM的一种强大而神奇的核函数法。通过核函数我们可以把线性不可分数据集转换为线性可分(在更高维度空间中)。
接下来我们简单介绍一下核函数或核方法。
我们先通过一个图及一个简单实例,先来大致了解一下SVM的核威力。我们先一个图,给大家一点感性认识:
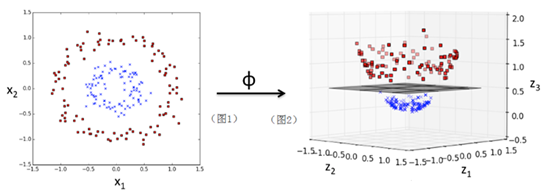
图1是一个二维空间上的一些散点分布图,通过一个核函数ϕ:
ϕ(x1,x2)=(z1,z2,z3)=(x1,x2,〖x1〗^2+〖x2〗^2)
把一个在二维空间线性不可分的数据集映射到三维空间(图2)后,就可以线性可分了(其中超平面可以把数据分成上下两部分)。
这是核方法的一个直观认识,下面我们使用scikit-learn包的SVM类,具体实现一个核方法。
1)在二维空间,生成一个类似‘异或’的数据集
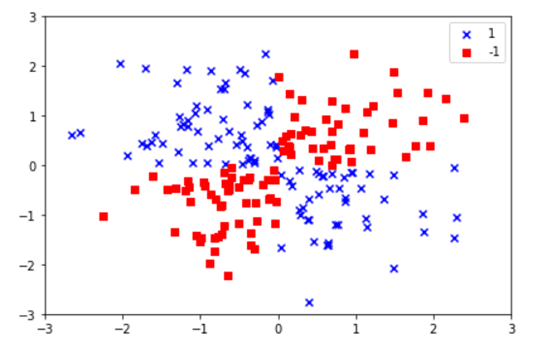
显然,对这个数据集是线性不可分的,即无法找到一条直线或超平面,把这个数据集划分为两类。
接下来我们采用SVM类中一个高斯核或径向基函数核(Radial Basis Function Kernel,RBF Kernel ),把数据映射到一个高维空间,然后利用SVM对其进行分类或划分。

从以上图可以看到,SVM比较完美的把不同类型的点划分成了两部分。
核函数我们可以把它理解为把低维数据集映射为高维数据集的映射或相似函数。接下来我们看一下核函数一般形式及特点、常用核函数。
设xi,xj∈X,X属于R(n)空间,非线性函数Φ实现输入空间X到特征空间F的映射,其中F属于R(m),n<<m。根据核函数技术有:
K(xi,xj) =<Φ(xi),Φ(xj) >
其中:<, >为内积,K(xi,xj)为核函数。从上式可以看出,核函数将m维高维空间的内积运算转化为n维低维输入空间的核函数计算,从而巧妙地解决了在高维特征空间中计算的“维数灾难”等问题,从而为在高维特征空间解决复杂的分类或回归问题奠定了理论基础。
特点编辑
核函数方法的广泛应用,与其特点是分不开的:
(1)核函数的引入避免了“维数灾难”,大大减小了计算量。而输入空间的维数n对核函数矩阵无影响,因此,核函数方法可以有效处理高维输入。
(2)无需知道非线性变换函数Φ的形式和参数.
(3)核函数的形式和参数的变化会隐式地改变从输入空间到特征空间的映射,进而对特征空间的性质产生影响,最终改变各种核函数方法的性能。
(4)核函数方法可以和不同的算法相结合,形成多种不同的基于核函数技术的方法,且这两部分的设计可以单独进行,并可以为不同的应用选择不同的核函数和算法。
常见分类编辑
核函数的确定并不困难,满足Mercer定理的函数都可以作为核函数。常用的核函数有:线性核函数,多项式核函数,径向基核函数,Sigmoid核函数等,这些核函数的表达式如下:

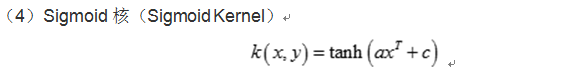
参考网站:http://blog.csdn.net/zouxy09/article/details/17291543
参考书:Python机器学习
机器学习中有两类的大问题,一个是分类,一个是聚类。
分类是根据一些给定的已知类别标识的样本,训练某种学习机器,使它能够对未知类别的样本进行分类。这属于监督学习。而聚类指事先并不知道任何样本的类别标识,希望通过某种算法来把一组未知类别的样本划分成若干类别,这在机器学习中被称作无监督学习。在本章,我们关注其中一个比较简单的聚类算法:k-means算法。
k-means算法是一种很常见的聚类算法,它的基本思想是:
(1)适当选择k个类的初始中心
(2)在第i次迭代中,对任意一个样本,求其到K个中心的距离,将该样本归到距离 最短的中心所在的类
(3)利用均值等方法更新该类的中心值
(4)对于所有的K个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变, 则迭代结束,否则继续迭代。
最后结果是同一类簇中的对象相似度极高,不同类簇中的数据相似度极低。
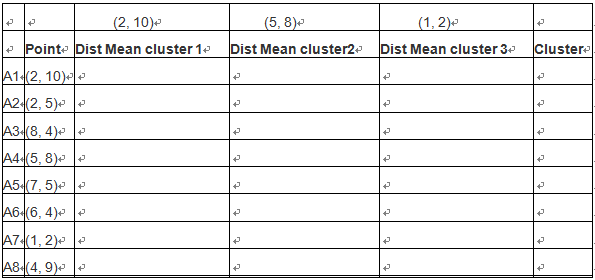
假定我们有如下9个点:
A1(2, 10) A2(2, 5) A3(8, 4) A4(5, 8) A5(7, 5) A6(6, 4) A7(1, 2) A8(4, 9)
现希望分成3个聚类(即k=3)
初始化选择 A1(2, 10), A4(5, 8) ,A7(1, 2)为聚类中心点,假设两点距离定义为ρ(a, b) = |x2 – x1| + |y2 – y1| . (当然也可以定义为其它格式,如欧氏距离)
第一步:选择3个聚类中,分别为A1,A4,A7
这些点的分布图如下:
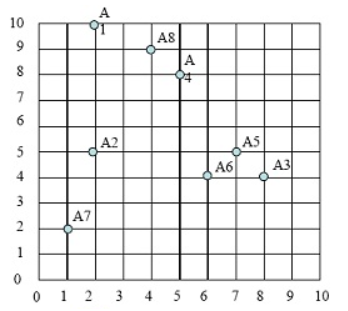
第二步:计算各点到3个类中心的距离,那个点里类中心最近,就把这个样本点
划归到这个类。选定3个类中心(即:A1,A4,A7),如下图:
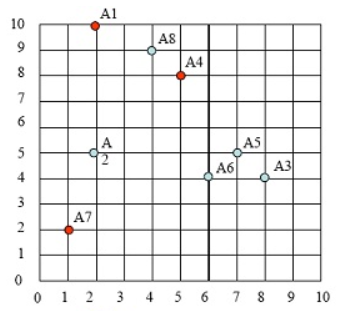
对A1点,计算其到每个cluster 的距离
A1->class1 = |2-2|+|10-10}=0
A1->class2 = |2-5|+|10-8|=5
A1->class3 = |2-1|+|10-2|=9
因此A1 属于cluster1,如下图:
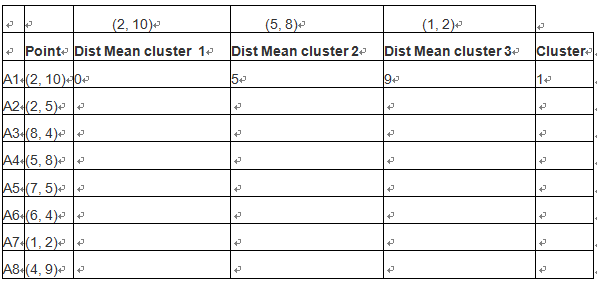
按照类似方法,算出各点到聚类中心的距离,然后按照最近原则,把样本点放在那个族中。如下表格:

根据距离最短原则,样本点的第一次样本划分,如下图:
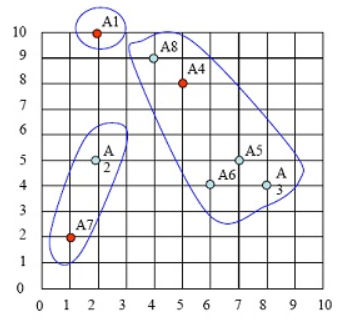
第三步:求出各类中样本点的均值,并以此为类的中心。
cluster1只有1个点,因此A1为中心点
cluster2的中心点为 ( (8+5+7+6+4)/5,(4+8+5+4+9)/5 )=(6,6)。注意:这个点并非样本点。
cluster3的中心点为( (2+1)/2, (5+2)/2 )= (1.5, 3.5),
新族的具体请看下图中x点:
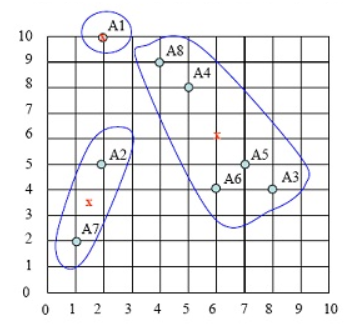
第四步:计算各样本点到各聚类中心的距离,重复以上第二、第三步,把样本划分到新聚类中,如下图:
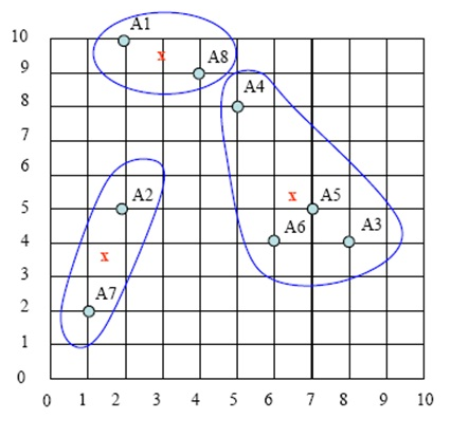 持续迭代,直到前后两次迭代不发生变化为止,如下:
持续迭代,直到前后两次迭代不发生变化为止,如下:
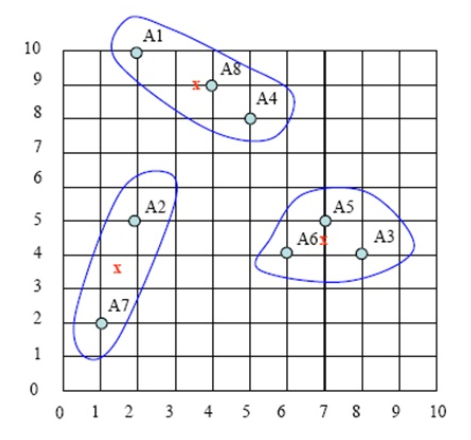
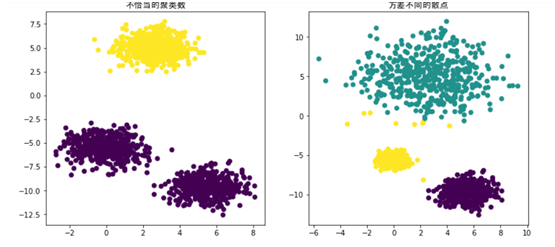
初始化聚类中心比较有讲究,上面这个实例我们是人工指定,A1、A4、A7为初始化的聚类中心;如果K值选择不当或聚类中心选择不当,则可能导致聚类效果不佳。因此,在实际项目中往往采用随机选择K个聚类中心,另外,K的选取也是很重要的,K的选取我们也有比较好的方法,如肘(elbow)方法、轮廓图(silhouette plot)方法等,这里就不展开来说,有兴趣的读者可以查阅相关资料。
对K-means算法,如果原数据很多,其计算量非常大,对于大数据是否有更好的方法呢?在计算梯度时,我们用整个数据集计算,如果数据量大的话,我们可以采用随机梯度的方法。同理,我们在处理聚类算法时,也有类似的方法,这就是scikit-learn提供的Mini Batch K-Means算法,其具体方法如下:
Mini Batch K-Means算法是K-Means算法的变种,采用小批量的数据子集减小计算时间,同时仍试图优化目标函数,这里所谓的小批量是指每次训练算法时所随机抽取的数据子集,采用这些随机产生的子集进行训练算法,大大减小了计算时间,与其他算法相比,减少了k-均值的收敛时间,小批量k-均值产生的结果,一般只略差于标准算法。
该算法的迭代步骤有两步:
1:从数据集中随机抽取一些数据形成小批量,把他们分配给最近的质心
2:更新质心
与K均值算法相比,数据的更新是在每一个小的样本集上。对于每一个小批量,通过计算平均值得到更新质心,并把小批量里的数据分配给该质心,随着迭代次数的增加,这些质心的变化是逐渐减小的,直到质心稳定或者达到指定的迭代次数,停止计算
Mini Batch K-Means比K-Means有更快的 收敛速度,但同时也降低了聚类的效果,但是在实际项目中却表现得不明显,这是一张k-means和mini batch k-means的实际效果对比图。
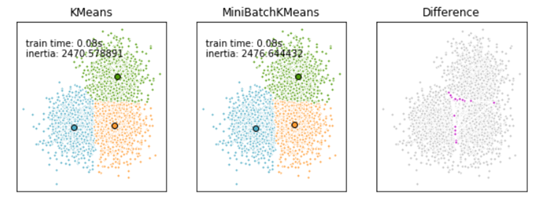
参考网站:http://blog.csdn.net/gamer_gyt/article/details/51244850