第1章 Linux简介
1.1 Linux能做啥
Windows能做啥? 可能十个人十个都知道。具体能做啥,就不用我说了。Linux能做啥?为啥有了Windows,为啥还要Linux?
Windows与Linux的关系,打个不很恰当的比喻,如果把Windows和Linux都作为交通工具,Windows就想单车(自行车),Linux就像列车。前者方便易用,并几乎没有轨道的限制,但它只能单用户,能承载的重量有限;后者虽然不像前者方便易用,但它可以多用户,并且可以运送巨无霸的东西!如管理成千上万个节点的大数据集群。关键一点是安全,还免费,更有很庞大的志愿者和使用者,当然,它也有一个不足,必须使用命令方式操作,就像列车务必在铁轨上一样。当然这也是保证其安全所需要的。
1.2 如何学习Linux
学好Linux将大大提升你的竞争力,哪如何学好它呢?是否存在捷径?我觉得有但又没有。
作为初学者,个人建议可以像小孩学英语一样,先学会用,而且是学哪些最常用、最基础、最重要的部分。如果会用,理解起来就方便多了。否则,已开始就学一大堆的语法,效果往往事倍功半。此外,就像锻炼身体、学习英语等一样,贵在实践再实践,“纸上得来终觉浅,绝知此事要躬行”。
另,向大家推荐几个学习Linux的网站:
Linux中国:https://linux.cn
鸟哥的Linux私房菜: http://linux.vbird.org
Linux下载站: http://www.linuxdown.net
Linux公社: http://www.linuxidc.com
《鸟哥的Linux基础学习篇》鸟哥著
1.3 Linux的历史
Linux的前辈是Unix,但可能是由于历史原因,Unix派别林立而且主要用在大型服务器,如IBM的AIX,HP的HP-Unix,SUN公司(目前是Oracle的一部分)的SUN-Unix等等,更要命的一点是他们商业味道很浓。
1991年10月5日, 上午11时53分,有一个名为 Linus Torvalds 的年轻芬兰大学生在 comp.os.minix 这个新闻群组上发表了这样一个帖子,称他以bash,gcc等工具写了一个小小的内核程序,这个内核程序可以在Intel的386机器上运行,这引起很多人的兴趣,由此标志L inux的诞生。
当初还是个大学生的 Linus 大概完全没想到当初被他视为个人兴趣的程式,在几年以后会有超千万个使用者,由他自己带头开发的操作系统现在已经在世界各地受到普遍的欢迎。
1.4 Linux的优缺点
Linux继承了Unix 稳定有效率的特点。网路上安装 Linux 的主机连续运做一年以上而不曾宕机、不必关机是稀松平常的事,不过Linux却不像一般Unix要负担庞大的版权费用,也不需要在专属的昂贵硬体上才可以使用;Linux可以在一般的 i386 PC 上执行,效能又高,自然而然的接收了过去几十年来在Unix上累积的程式资源跟使用者,加上GPL的版权允许大家自由散发Linux的原始码,并针对自己的需求修改程式,使得Linux在目前已经成为非常受人欢迎的一个多用户、多任务、免费、稳定、效率高、可以在众多不同电脑系统平台上执行、拥有亿万粉丝的操作系统。当然,Linux也不是完美无缺的,它的一个最大缺点就是需要使用“命令行”来操作和管理,尤其是对初学者,不过在“安全第一”的今天,这个缺点或许又是保证其优点的重要方面。
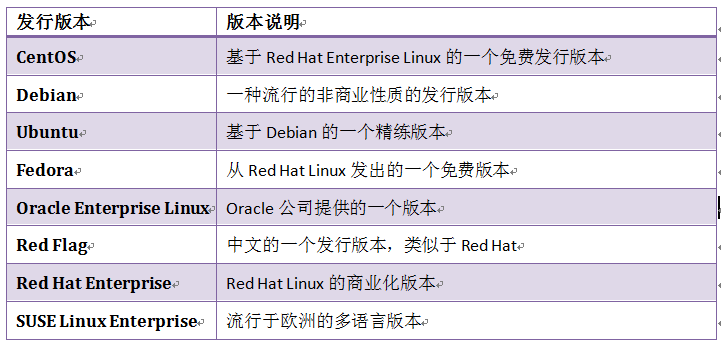
1.5 Linux的发行版本
Linux基于Debian、Red Hat和SUSE源的那些发行版本在生产环境中占据优势地位,以下为目前Linux比较流行的版本。
表1.1 Linux流行版本
对Linux而言,内核是其心脏,与硬件打交道,开机后留住在内存 ,而Shell为内核与应用程序间的桥梁,内核及shell构成Linux的主要内容,应用程序通过shell(或命令行)与服务器进行交互,shell调用内核(Kernel)来利用和管理服务器硬件资源,应用程序(如用户自己编写shell脚本等,office是windows操作系统的应用程序)保存在硬盘,需要时调入内存,它们之间的关系可用下图形表示:
(图1-1 Linux操作系统结构图)

1.6 登录系统
前面讲了Linux是个非常重要、功能强大、而且有意思的系统,而且还提到需要在命令行操作,不像使用windows一样,只需要按按鼠标即可,命令行操作确实不方便,尤其是对大多数用惯了windows的人来说。这确实有个‘痛苦’的过程,但是windows一般只能用来写写文档、上上网、打打游戏、看看电影之类,企业生产环境大都采用非windows环境,如Linux或Unix,因此对于大多数希望从事IT相关行业者,尤其进入大数据这个朝阳行业的人来说,是一道必需迈过的坎。
万事开头难,实际上你只要用过一段时间,将会慢慢喜欢上它,它有很多你想不到的优点,如tab补全功能。
如何登录Linux系统呢?如果Linux就在本地机器上,只需要启动Linux即可;如果Linu服务器不在本地,那也很简单,只要在你的客户端安装一个连接Linux的客户端(如Putty或Xshell等,这些在网上都可免费下载),然后做一个简单配置就可以了,下面我们以登录远程Linux服务为例(注:本例中Linux已安装好,并创建一个用户:conn_linux):
第一步:安装Xshell 5
从网上下载一个Xshell 5,安装基本按照缺省情况即可
第二步:打开Xshell 5,点击文件菜单,然后点击新建,进入下一个界面
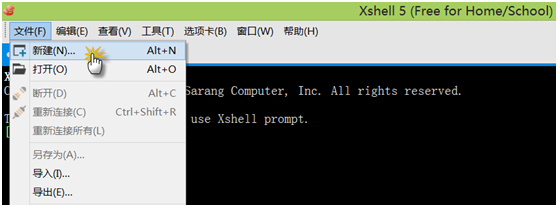
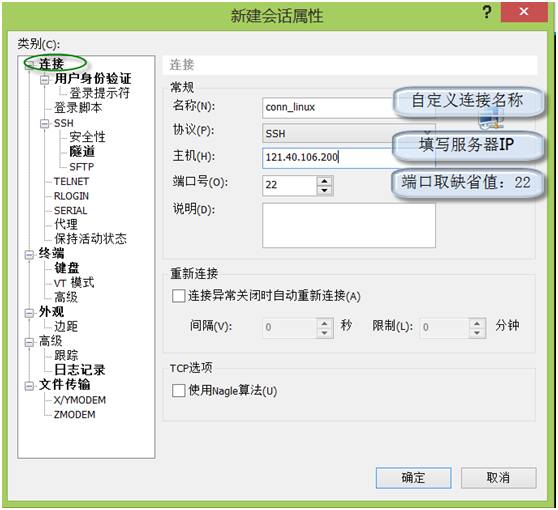
第三步:点击连接,配置服务器的IP,端口,如下图:
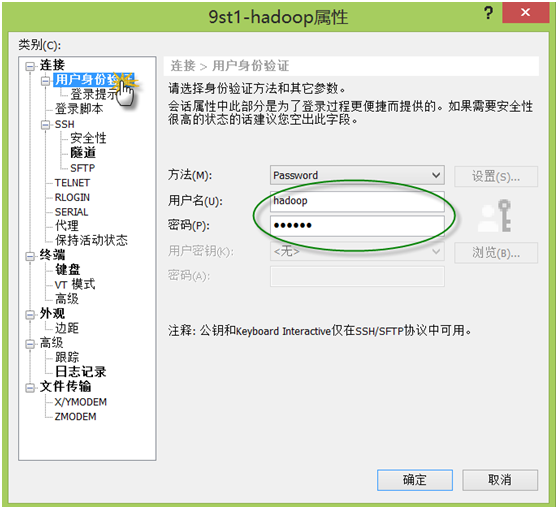
第四步:点击用户身份验证,配置用户及密码信息,如下图:
第五步:点击确认按键,所有配置完成,最后在会话界面将出现刚创建的连接,名为conn_linux,如下图。
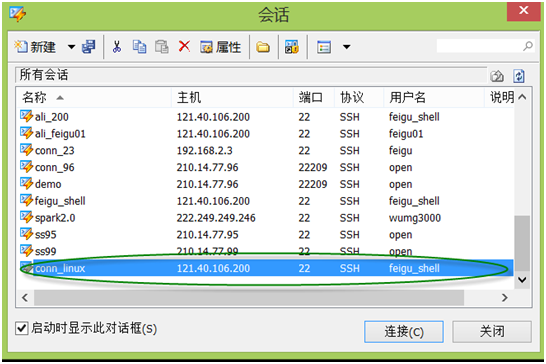
第六步:点击连接,如果IP,用户密码等都正确的话,进入Linux系统,如能看到如下类似界面,祝贺你,你已经迈入Linux大门了!
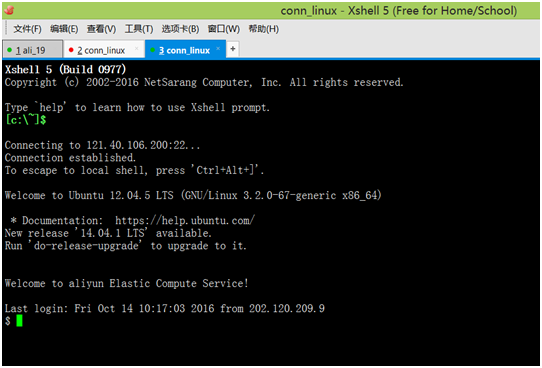
Xshell 5是连接Linux服务器的工具之一,还可以通过Putty等工具,配置和使用也很方便,此外大家还可以利用Xftp 5工具来上传或下载Linux服务器上的文件,它的安装和配置比较简单,网上有很多这方面的文档,这里就不再展开来说了。
1.7 登录后,试试身手
登录Linux后,可以用一些简单命令,试一试Linux这个听起来有点神秘的操作系统。
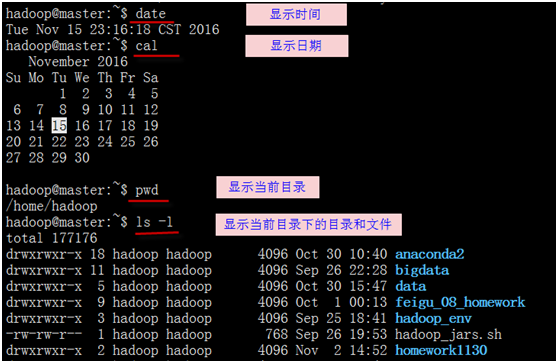 注意,linux是区分大小写的或称为大小写敏感,所以pwd和PWD是不同的。
注意,linux是区分大小写的或称为大小写敏感,所以pwd和PWD是不同的。
Linux系统要经常输入命令,而且有些命令或文件还比较长,如果要一个一个输入,不但麻烦,还容易出错。Linux是否有更有效的方法呢?答案是肯定的,那就是利用Tab键!它具有命令补全或文件补全的功能,这也是Linux很有趣的地方之一。当然,Linux为尽量减少你敲键盘次数,还有更强大的地方,如编写shell脚本,这个后面我们会详细介绍。
先看几个使用Tab键来偷点懒。
假如我们想进入homework1130这个目录,是否要cd homework1130?如采用Tab补全功能,在大大减少输入量的同时,还可大大提高你的准确率。具体实现方法为:输入目录名称的前几个字符即可,然后按Tab,系统自动补全该目录名称,具体操作如下图:

按Tab键后得如下界面

类似的神奇,Linux还有很多,如通过上下方向键(↑↓),可以调出前面输过的命令,输过了的命令可以不用重新输入了,这个功能也不错,顺便提一下,这些功能在MySQL数据库也有,讲MySQL时我们会介绍,看来好东西,大家都喜欢。
1.8 shell种类
shell是Linux内核与应用程序间的桥梁,起着非常重要的作用,shell由多种,如bsh(或sh),csh,ksh,bash等,这些shell基本内核对差不多,但还是有不少不一样的地方,所以我们在编写shell程序时,首先需要说明使用哪种shell来解释你程序,具体做法就是在shell程序第一行说明,如#!/bin/bash,这些内容大家先了解一下,后面我们会详细介绍,它们间关系大致如下:
(图1-2shell种类及关系图)
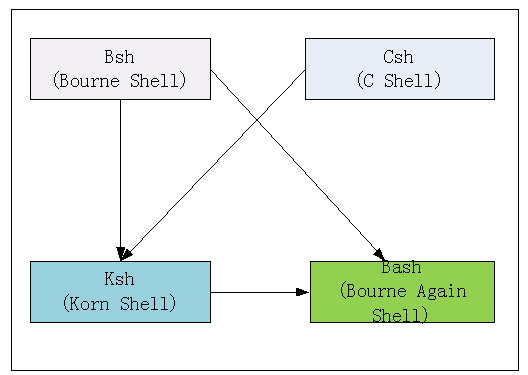
shell有多种,每个连接用户系统一般会先给个缺省shell(当然缺省shell可以修改),哪里可以看到你的缺省shell呢?查看文件/etc/passwd,或echo $SHELL 可以看到用户使用的缺省shell,cat /etc/shells可以看到目前已安装的shells。如何查看这些文件,后面将介绍。
第2章 文件与目录
2.1 文件与目录简介
说到文件和目录,我们从大家熟悉的windows开始,打开windows有关界面,我们通常能看到如下类似界面:
(图2-1 windows的目录及文件)
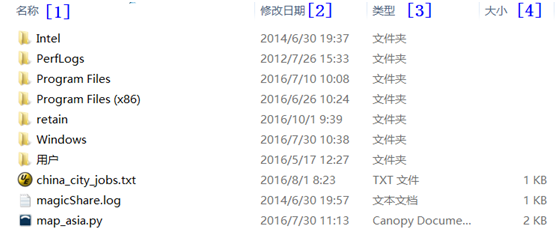
第[1]列为文件及目录名称:是文件还是目录,从图标很容易看出,其中有些为系统目录有 些是用户创建目录或文件。
第[2]列为修改时间;文件或目录的修改或创建时间。
第[3]列为类型:显式说了是文件夹还是文件,甚至为那种类型的文件。
第[4]列为文件大小,如果是文件,会显示其大小,单位为KB。
那Linux系统的目录及文件,又是如何排兵布阵的呢?windows进行下级目录,或上级目录只需要点击相关目录或到上级目录的方向图标,在Linux系统中如何进入下级目录或上级目录,如何打开文件?实际上在Linux系统虽然需要使用命令,但使用起来也很方便,而且在安全性、易用性方面更有独到的地方,目录的切换使用cd命令,查看当前目录或文件可以使用ls命令,详细操作我们如下实例。
(图2-2 Linux下的目录、文件及权限等)
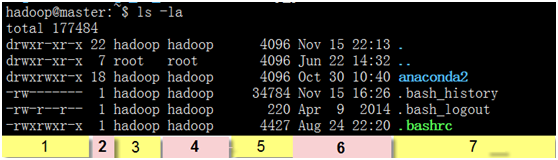
用ls -la(,注意ls 与-la间有一个空格,l(list)及a(all)为两个参数)可以查看当前目录下的文件或目录的详细信息,包括列出隐含文件(文件名前为.,如上面的.bashrc文件)。
与windows的内容基本相同,windows的第[1]、[2]、[3]、[4]列分别对应Linux的第[7]、[6]、[1]、[5],虽然没有windows这么直观,但包含更丰富的信息。理解这些信息非常重要,以后经常提到这些相关内容,下面我们对上面7列代表的含义逐一进行说明。
第[1]列:表示文件类型及权限,如果你仔细观察一下,会发现这列共有10个字符,
这10个字符的位置及含义,我们把它放大一下,如下图:
(图2-3文件及目录权限说明图)
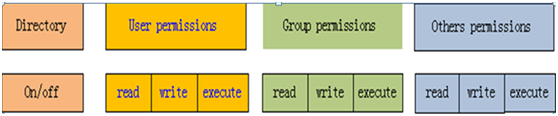
第1字符为d或-,d表示对应是目录,-对应是文件;
第2,3,4字符,如[rw-]、[rwx],表示用户或文件所有者的权限,r(read)表示有读的权限,w(write)表示有写的权限,x(execute)表示有执行权限,-表示没有对应权限。[rw-]
表示文件所有者有读、写权限,但没有执行权限。
第5、6、7字符,表示文件所属的用户组的权限。
第8、9、10字符,表示其他用户(有点像windows中guest用户)的权限。
第[2]列:表示文件或目录的连接数,如果目录至少为2,因任何一个目录至少包括.及..
两个目录,.表示当前目录,..表示上级目录,故如何我们需要切换到上级目录,可以cd ..
即可。
第[3]列:表示文件或目录的所有者账号
第[4]列:表示文件或目录所属用户组,如上面列出feigu feigu,说明所属用户为feigu,所属用户组也是feigu(这里两者同名,当然两者可以不同名)。
第[5]列:表示文件大小,缺省单位为B(非KB)。
第[6]列:表示文件文件或目录的创建或修改时间。
第[7]列:表示文件或目录名称,如果文件前多一个点的表示隐含文件,隐含文件只有加上a这个参数才会显示出来,否则不会显示出来。
以上这些权限或属性当然不是一成不变的,可以通过命令修改,如何修改2.3节将介绍。
ls命令的使用方法还有很多,我这里介绍几种常用方法:
ls -lt ####结果按时间排序,降序。
ls -l ####结果按名称排序
ls -lS ####按文件大小排序,注意S为大写
ls -ltr ####结果按时间排序,变为升序,增加参数r(reverse),表示与缺省排序方式相反。
看到这里,可能有很多朋友不耐烦了,这么多命都要一一去记吗?其实完全不必要去死记忆,Linux有一个类似windows中help工具,他就是man这个命令,这个man非常强大,不过其来源是manual,而非男人哦。使用起来很方便,其格式为:man [command] ,显示结果中有各参数的含义、示例等。
2.2 切换目录
Linux的存储都是以目录的方式存在的,所以了解其目录结构、主要目录的含义非常重要,在不同目录间切换是Linux人员做得最多的事情之一,既然是经常干的活,是否有些妙招呢?有但又没有,关键还是要多练,“熟练才能生巧”。
我们先来看一看Linux的主要目录及用途:
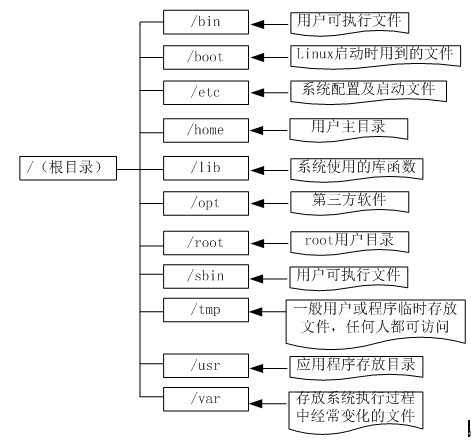
(图2-4 Linux主要目录结构图)
切换目录使用cd命令,如果要到根目录(Linux系统最高目录),可以cd / 即可;如果切换到上级目录,使用cd ..;如果要回到用户主目录,用cd ~ 。
查看当前你所在的目录,使用pwd命令;查看当前目录下的有哪些文件或目录,使用ls命令。
.表示当前目录,也可用./表示;..表示上级目录,也可用../表示。
由根目录(/)开始的路径成为绝对路径,如:/home/feigu/hadoop;相对于当前路径的称为相对路径,如:./hadoop 、~/spark等。
2.3 改变文件或目录属性和权限
”安全第一“,这句话用在操作系统方法同样适合。我们知道windows也有权限设计,它主要通过用户或角色的设置,没有细到文件和目录的,比较粗放,因毕竟它是PC机,自个用的没必要搞得那么复杂。Linux系统一开始基于互联网的,所以其安全设计方面做得好。
在第2.1小节,通过ls -la命令我们可以看到其权限的大致情况,可精准到目录和文件,对使用者分为所有者、用户组、其他人;权限又有r、w、x等。权限这部分迷惑了不少初学者,时常被“Permission denied”搞得头大,实际上问题就出在权限设置方面,这是一个坎,但过了这个坎,你就前进一大步了!
其实这个问题,说难也不难,掌握如此细腻的东西,耐心是最好的武器。下面我们来逐一分解。
由于Linux是多用户、多任务的系统,有时可能出现几十、几百个人同时连到一台服务器,甚至还有考虑一些不速之客,所以对如此多用户就需要进行划分了,自己应该就是所有者,其他人可以分成几个组,如开发组、测试组、业务组(你可以是组员之一、也可以不在这些组),在这些组之外,再设置一个others(其他人)。root拥有Linux系统最高权限,就像windows中administor,我们日常使用时,出于安全考虑最好选用其他用户。
使用文件或目录者分为三种身份(所有者、用户组、其他人)),权限分为r、w、x,这些权限对文件和目录的作用是否相同呢?下面我们来仔细分析分析一下:
权限对文件的影响
r-- 可以读取文件内容
w--可以修改、新增文件内容,但不能删除文件或创建文件;
x--可以执行文件,如shell脚本等其他程序。
r、w、x一般是针对文件内容的
权限对目录的影响
r-- 可以查询该目录下的文件或目录,如可以使用ls等命令。
w--可以新建或删除目录和该目录下文件、可以重命该目录及其下的文件等。
x--可以把当前目录作为工作目录,如可用cd命令进入该目录。
上面对用户身份及对应权限做了一些介绍,下面我们来回到这节的主题,如何修改文件或目录的属性和权限呢?比较简单,主要用到以下三个命令:
chgrp: change group的简称,修改目录或文件所属用户组。
chown:change owner的简称, 修改目录或文件所属所有者
chmod:change mode的简称,修改目录或文件权限。
chgrp的命令格式:chgrp [-R] 用户组 文件或目录
其中参数-R,表示可递归修改该目录及其所有子目录下的文件、 目录,使用该命令一般需要root权限,变更时涉及/etc/group 系统文件。
chown的命令格式:chown [-R] 所有者 文件或目录
或chown [-R] 所有者:用户组 文件或目录。变更时涉及 /etc/passwd系统文件。
执行该命令一般需要root权限,以下为一个示例:
# ls -l
total 16
-rw-rw-r-- 1 feigu feigu 154 Oct 16 11:11 conn_mysql.sh
-rw-rw-r-- 1 feigu feigu 31 Oct 16 11:12 install.log
-rw-rw-r-- 1 feigu feigu 1146 Oct 16 11:11 select.sh
dr-xr--r-- 2 feigu feigu 4096 Oct 17 14:32 shell_script
root@slave001:/home/feigu/linux_test# chown -R hadoop:hadoop shell_script/
root@slave001:/home/feigu/linux_test# ls -l
total 16
-rw-rw-r-- 1 feigu feigu 154 Oct 16 11:11 conn_mysql.sh
-rw-rw-r-- 1 feigu feigu 31 Oct 16 11:12 install.log
-rw-rw-r-- 1 feigu feigu 1146 Oct 16 11:11 select.sh
dr-xr--r-- 2 hadoop hadoop 4096 Oct 17 14:32 shell_script
chmod的命令格式:chmod [-R] xyz目录或文件,其中权限xyz有两种表达方式,一种是字符,r、w、x;还有一种是数据4、2、1,字符和数据间有个对应关系
(表2-1 权限两种表达方式)
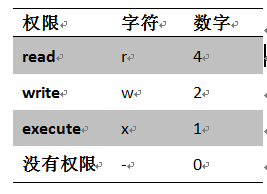
所有者名称与简称的对应关系:u代表user(owner),g代表group,o代表others,此外对权限的操作方式有:+表示加入权限,-表示除去权限。
在2.1节提到了文件或目录的权限,涉及权限部分共有9个字符,如[rwxr--r-x],每三个字符为一组,
第一组对于所有者权限[rwx],
第二组用户组权限[r--],
第三组为其他用户权限[r-x],
用字符来赋权限,上面这个我们可以写成:chmod u=rwx,g=r,o=rx test.sh
这种表示方法有个好处是直观,但有时比较麻烦。
如果用数字该如何表示呢?用三位数来表示,
第一位表示所有者权限,如上面的[rwx]对应数字为[4+2+1]=7,
第二位表示用户组权限,如上面的[r--]对应数字为[4+0+0]=4
第三位表示其他用户权限,如上面的[r-x]对应数字为[4+0+1]=5
所以[rwxr--r-x]用数字表示就是745
赋权语句就是:chmod 745 test.sh,以下是该示例
$ ls -l
total 12
-rw-rw-r-- 1 feigu feigu 154 Oct 16 11:11 conn_mysql.sh
dr-xr--r-- 2 hadoop hadoop 4096 Oct 17 14:32 shell_script
-rw-rw-r-- 1 feigu feigu 62 Oct 17 22:59 test.sh ####修改前
feigu@slave001:~/linux_test$ chmod 745 test.sh ####修改权限
feigu@slave001:~/linux_test$ ls -l
total 12
-rw-rw-r-- 1 feigu feigu 154 Oct 16 11:11 conn_mysql.sh
dr-xr--r-- 2 hadoop hadoop 4096 Oct 17 14:32 shell_script
-rwxr--r-x 1 feigu feigu 62 Oct 17 22:59 test.sh #####修改后
2.4 文件或目录管理
前面我们介绍了Linux的目录结构、如何查看目录、如何修改文件或目录的属性和权限等内容,当然我们学Linux肯定不是来看看的,我们还想做一些实际事情,如创建文件或目录,拷贝文件,删除文件或目录等,这些任务在windows里相信大家都比较熟了,在Linux中该如何做呢?操作方便吗?不但方便还非常有趣,下面我们就来谈谈这方面的问题:
切换目录上面我们讲到了,利用cd命令即可,我们这里再小结一下:
cd /home/feigu/hadoop ####切换到指定目录
cd ~ ####切换到用户主目录,即用户一开始登录进入的目录
cd .. ####切换到上级目录
cd / ####切换到根目录
cd - ####切换到上一次使用的目录
查看目录可以用pwd,ls等命令。下面我们谈谈如何创建目录,用mkdir命令即可,其功能比windows前很多哦。其命令格式为:
mkdir [-p] 新建目录
-p ####可以递归创建目录,如果上级没有的系统将自动创建。示例如下:
不用参数,创建单个目录
$ ls -l
total 12
-rw-rw-r-- 1 feigu feigu 154 Oct 16 11:11 conn_mysql.sh
dr-xr--r-- 2 feigu feigu 4096 Oct 17 14:32 shell_script
-rwxr--r-x 1 feigu feigu 62 Oct 17 22:59 test.sh
$ mkdir mydirect ###创建新目录mydirect
$ ls -l
total 16
-rw-rw-r-- 1 feigu feigu 154 Oct 16 11:11 conn_mysql.sh
drwxrwxr-x 2 feigu feigu 4096 Oct 18 11:35 mydirect ###创建成功
dr-xr--r-- 2 feigu feigu 4096 Oct 17 14:32 shell_script
-rwxr--r-x 1 feigu feigu 62 Oct 17 22:59 test.sh
使用-p参数,同时创建多级目录
$ ls -l
total 12
-rw-rw-r-- 1 feigu feigu 154 Oct 16 11:11 conn_mysql.sh
dr-xr--r-- 2 feigu feigu 4096 Oct 17 14:32 shell_script
-rwxr--r-x 1 feigu feigu 62 Oct 17 22:59 test.sh
$ mkdir -p test1/test2 #同时创建两级目录
$ cd test1 #一级
feigu@slave001:~/linux_test/test1$ ls -l
total 4
drwxrwxr-x 2 feigu feigu 4096 Oct 18 11:26 test2 ###test1的子目录
删除目录的命令及其格式为:rmdir 目录名称
注意用rmdir命令删除目录时,需要该目录为空目录(即该目录下没有文件或子目录),否则,会报错。如果该目录下有很多文件和目录,岂不要逐一删除?是否有更强的命令?
有的,接下来这个命令就可。
rm [-fir] 文件或目录
-f ###f就是force之意,不提示,对不存的目录或文件也不报错或警告
-i ###i 就是interactive之意,删除前会询问是否删除
-r ###r就是recursive之意,即递归删除,这个非常强大,但也需非常谨慎使用。
$ ls -l
total 20
-rw-rw-r-- 1 feigu feigu 154 Oct 16 11:11 conn_mysql.sh
drwxrwxr-x 2 feigu feigu 4096 Oct 18 11:35 mydirect
dr-xr--r-- 2 feigu feigu 4096 Oct 17 14:32 shell_script
drwxrwxr-x 3 feigu feigu 4096 Oct 18 14:00 test1
-rwxr--r-x 1 feigu feigu 62 Oct 17 22:59 test.sh
$ rm -rf test1 ###删除test1及其子目录test2
$ ls -l
total 16
-rw-rw-r-- 1 feigu feigu 154 Oct 16 11:11 conn_mysql.sh
drwxrwxr-x 2 feigu feigu 4096 Oct 18 11:35 mydirect
dr-xr--r-- 2 feigu feigu 4096 Oct 17 14:32 shell_script
-rwxr--r-x 1 feigu feigu 62 Oct 17 22:59 test.sh
与windows一样,对一些不满意的目录或文件,或根据实际情况,我们可重命名目录或文件名称,具体可使用mv命令,其格式为:
mv [-fiu] 原目录或文件 目标目录或文件.
其实该命令也常用来移动目录或文件,就像windows中移动文件或目录一样。
目录或文件除了可以移动,当然可以复制,windows中有的,Linux也有。cp命令可以很方便用来复制文件或目录,其命令格式为:
cp [-fipr] 原文件或目录 目标文件或目录
-f ###强制执行
-i ###如目标文件已存在,则会提示是否覆盖,覆盖按y,否则,按n
-p ###同时把文件或目录权限一起复制过去,而不仅仅默认权限或属性
-r ###递归复制,这个参数很给力
以上是一些常用参数,其实cp参数还有很多,大家可以通过man去了解更多参数的使用。
创建目录可以用mkdir,哪创建文件呢?创建文件比较简单,可用touch 文件名。当然也可用vi或vim等方法,vi或vim后续我们会讲到。
$ ls -l
total 0
###用touch命令,创建一个名为myfile.txt的空文件
$ touch myfile.txt
$ ls -l
total 0
-rw-rw-r-- 1 feigu feigu 0 Oct 24 17:31 myfile.txt
【延伸思考】
如果要在两台服务器间复制文件,该如何操作呢?有兴趣可以考虑一下,没有兴趣的可跳过]
2.5 查看文件内容
前面我们谈了如何查看当前目录(pwd命令)、用ls命令查看当前目录下有哪些文件或目录,如何查看文件内容呢?在windows中我们要看一个文件需要打开才能看到,在Linux中,查看文件灵活的多,而且有趣的多。如可以不open也可查看,而且还可以顺着看,也可倒着看,等等,下面我们就来讲讲如何查看文件内容。
查看文件内容,我们可用的命令很多,常用的有:
cat ###从第一行开始查看,一次打开,如果文件较大时,建议采用其方法。
tac ###从最后一行开始看,tac啥意思?其实它没意思,就是cat的倒写。
more ###逐页地看,按回车,继续查看,按q退出。
less ###与more类似,但可以往前翻(按PgDn)。
###/ 字符串,可向下查询字符串
###?字符串, 可向上查看字符串
###n、N可继续查看以上字符串
###q退出。
head ###查看前几行
tail ###查看后几行
最后2个命令可指定查看头几行或最后几行,命令格式为:
head -n 数字 文件名称 ####没有参数,缺省查看前10行
tail -n 数字 文件名称 ####不带参数,缺省查看最后10行
以下为示例:
$ head -n 5 stud_score_bak.csv ###查看前5行
stud_code,sub_code,sub_nmae,sub_tech,sub_score,stat_date
2015101000,10101,数学分析,,90,
2015101000,10102,高等代数,,88,
2015101000,10103,大学物理,,67,
2015101000,10104,计算机原理,,78,
feigu@slave001:~$ tail -n 3 stud_score_bak.csv ###查看最后3行
2015201010,20104,概率统计,,96,
2015201010,20105,汇编语言,,91,
2015201010,20106,数据结构,,87,
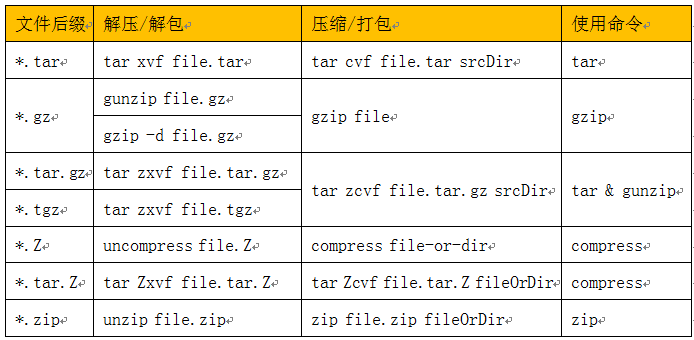
2.7 文件压缩与打包
以下列出Linux一些常用的压缩解压、打包解包的常用命令,供大家参考:
第3章 Shell脚本
3.1 vim编辑器
vim编辑器是啥东西?它有哪些功能?为何要用vim?在windows中我们要编辑一个文件,可以用word、文本编辑器、excel等,如果要说这些编辑器哪个更像vim,那就是文本编辑器了,它们都不支持图片,但vim比文本编辑器功能上强很多,如支持语法高量、远程编辑、崩溃后文件恢复、与vi(vim是vi的加强版,vi也是很多Linux自带的编辑器)兼容等等,所以vim通常作为程序编辑器来使用。
刚开始用vi或vim来编辑文件或脚本时,大多数人都不习惯,这很正常,就像我们穿一双新鞋一样,大都有个磨合期。对于用惯word的朋友,在word中大部分动作基本用鼠标就可搞定,但在vi或vim中鼠标好像不起作用,Linux靠命令驱动,vi或vim也不例外,不过它有很多优点,时间久了你就可慢慢体会到。
好闲话少说,下面我们开始介绍vi或vim的使用方法,用vi或vim来编辑文件,操作上几乎一样,而且两者相互兼容,下面以vim为例来进行说明。
vim的使用分为三种模式,即普通模式、编辑模式、低行模式,了解这三种模式非常重要,实现这三种模式的转换很简单,就是按Esc键。
普通模式
用vim打开文件时就进入了普通模式,在这种模式中,可使用方向键移动光标,也 可以删除、复制、粘贴字符
编辑模式
顾名思义,在这种模式中,可以对插入、删除字符,在普通模式下,按下i或o或a之后,马上就进入到编辑模式,注意前提是在普通模式下。如果保证当前模式为普通模式,有个诀窍,多按几次Esc键。
低行模式
在普通模式下,按“:或/或?”,就进入低行模式,为何叫低行模式?因此时光标会自动跳到低行,在低行模式下,可以进行保存、退出、查询等操作,这里同样要注意其前提,如何保证当前为普通模式,多按几次Esc键。
以下是vim三种模式的转换关系
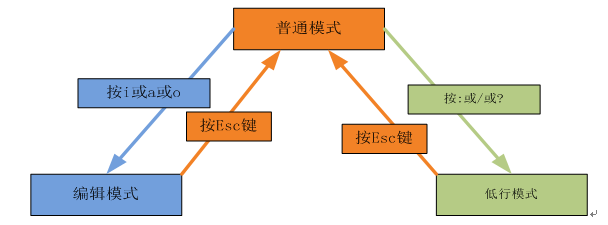
(图3-1 vim三种模式间的转换图)
以下通过几个实例来说明:
(1)普通模式,利用vim或vi打开一个文件,处于普通模式

(2)在普通模式基础上,按i或a、o键,将进入编辑模式,在编辑模式下,用户可对文件进行增删改等操作。
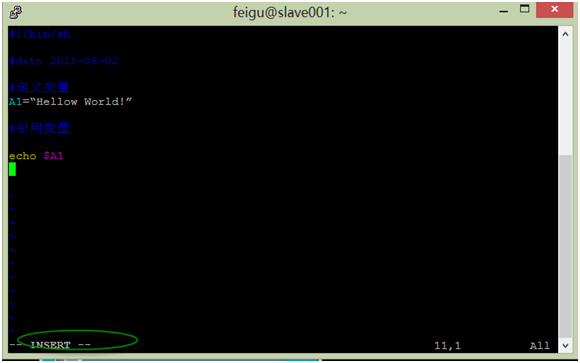
(3)在编辑模式时按“Esc”键,将返回到普通模式,在普通模式时,按冒号(:),斜杠(/)或问号(?)将进入低行模式,低行模式可对文件进行保存退出、查询等操作。:wq!表示保存并强制退出, :q! 不保存强制退出。
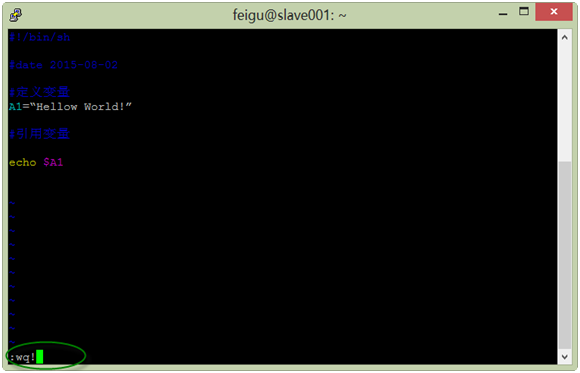
以上这些命令是最常用、最基础的,不过还有很多命令,而且还很多功能不错也很有趣的命令,大家可以从man或网上找到。
[注意:如果不正常退出或编辑时正好断网断线等异常情况,vim将在当前目录下创建一个扩展名为swp的暂时文件,利用这个文件可以用来恢复文件,恢复后可以删除该文件,否则下次再编辑该文件时,vim还会提示你是否要恢复或只读进入方式打开文件等。]
3.2 shell变量
说到变量相信大家都不陌生,像X,Y,Z都可以称为变量,与变量相对的就是常量,如a,b,c,2,3等等。shell的变量有不少特殊的地方,首先shell变量无需声明类型(顺便提一下:这点与Java、C、C++等不同,但与python 相似),下面具体讲讲shell变量的特点:
变量的赋值:
格式为,变量名=变量值,
如,V1="abc"
字符串可以使用双引号"",和单引号'',但两者间有些区别,用双引号可以保留字符含 义,单引号将视特殊字符为一般字符,具体下面举例说明。
变量的使用
需要在变量前加上$,如$v1 或${v1}。
变量的显示:
echo $v1,下面通过一个示例说明双引号与单引号的区别:
$ v1="numpy"
$ v2="import $v1" ###双引号中含特殊字符$
$ echo $v2
import numpy ###双引号保留了$的特殊含义
$ v3='import $v2'
$ echo $v3
import $v2 ###单引号内的$被作为一般字符
环境变量
在windows有环境变量,如何设置windows环境变量?Linux的环境变量如何设置?环境变量有何作用?
这部分我们来介绍Linux环境变量问题,首先我们看一看windows环境如何设置环境变量问题,在windows的我的电脑=〉属性=〉高级属性设置=〉高级系统属性中有一个“环境变量”设置菜单,点击这个菜单就看到类似如下界面:
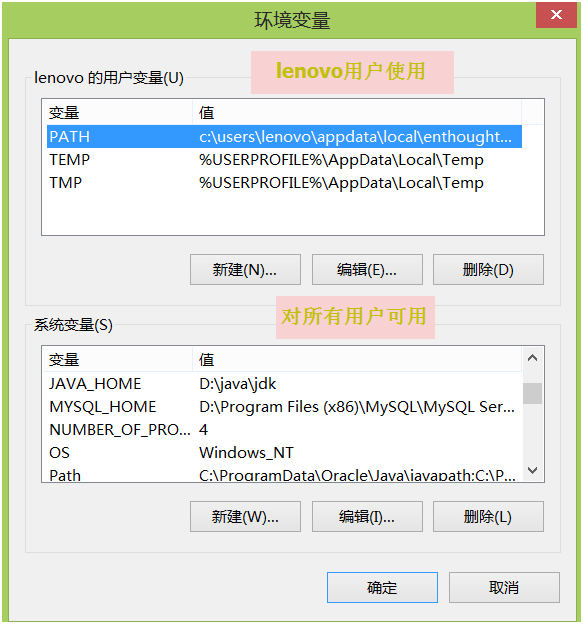
(图3-2 windows环境变量设置界面)
里面就是windows环境变量,如PATH、JAVA_HOME、MYSQL_HOME等等,这些环境变量有何作用呢?它的作用不小,给我们提供很多方便,具体作用还是举一个例子来说吧,如果我们想在cmd下运行命令mysql,而该命令所在路径不在环境变量PATH中,我们只有在mysql所在目录运行,否则将报错;如果在环境变量中添加了执行程序mysql所在路径,如:C:\MySQL\MySQL Server 5.5\bin,,那么在cmd下运行mysql命令时,系统将自动在这些目录中查找是否存在该命令,因在path或PATH中添加了,故你可以在任何目录运行该命令。环境变量系统有些时安装时自动生成的,有些需要手工添加。
理解了windows的环境变量,实际也基本了解了Linux的环境变量及其作用,只是设置存储环境变量的方式不同而已。那么如何在Linux系统查看环境变量?如何设置?下面就这些类似问题进行说明。
查看环境变量
用env(environmnet的缩写)命令查看当前用户可用的环境变量
常用的环境变量
PATH、HOME、LANG、SHELL等等,如果我们运行的一些命令不在PATH环境变量,运行该命令是,有可能报找不到该命令。
设置环境变量的几个文件及作用范围
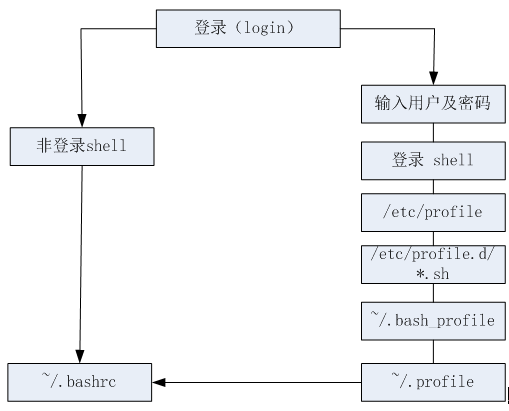
(图3-3 Linux环境变量设置文件及其关系)
[注:/etc下配置文件为所有用户,~下配置文件只作用于当前登录用户,如果要使修改后的配置文件立即生效,记得用”source 配置文件“命令运行该文件]
环境变量与export
环境变量在某些场合又成为全局变量,我们自定义的变量一般是局部变量,如何使局面变量成为全局变量(如:父进程、子进程都有效)?在局面变量前加上关键字export,下面通过一个实例来说明export的作用。
我们这里有两个简单shell脚本:test1.sh和test11.sh,test1.sh调用test11.sh
详细脚本如下:
$ cat test1.sh
#!/bin/bash
##test export
v1="Linux shell"
v2="spark RDD"
echo "显示变量V1的值: "$v1
sh test10.sh ###调用test10.sh这个脚本,希望获取v2变量的值
#####################################
$ cat test10.sh
#!/bin/bash
#test export
echo "获取test1.sh中变量v2的值: "$v2
运行test1.sh脚本,看能否获取到变量v2的值?
$ sh test1.sh
显示变量V1的值: Linux shell
获取test1.sh中变量v2的值: ####没有获取到变量v2的值
下面我们对test1.sh做一个小小的改动,即在变量v2前,加上export 关键字,其他不变,
$ cat test1.sh
#!/bin/bash
##test export
v1="Linux shell"
export v2="spark RDD" ###添加export关键字
echo "显示变量V1的值: "$v1
sh test10.sh ###调用test10.sh这个脚本,希望获取v2变量的值
再运行test1.sh,看test10.sh是否能获取v2变量的值?
$ sh test1.sh
显示变量V1的值: Linux shell
获取test1.sh中变量v2的值: spark RDD ###这次获取到了v2变量的值!
通过以上实例说明了,在局部变量或自定义变量前加上export,就马上变成全局变量,或子程序(或子进程)也可获取父脚本(或父进程)中的变量!所以,在变量设置中记得添加export。它将使你的程序更强大!
几个特殊又常用的变量
(表3-1 特殊变量)

这些变量的使用或作用我们后面将讲到,大家先有个了解。
3.3 数据流重定向
数据流重定向,这个概念好像有点陌生,但相关的事我们可能天天都在做,如在windows系统中编辑word文档,首先我们敲击键盘,把键盘上的字符输入到电脑,然后电脑把结果(或称为数据)输出到屏幕,为了以后可以重用、或给其他人,我们通常会把屏幕结果保存为文件或输出到打印机,实际上,这时我们完成了一个数据流重定向任务(即把输出到屏幕上的文字改为输出到文件或打印机等)。
数据流重定向,在Linux系统大同小异,如我们把键盘上的ls字符(或称为数据),输入到Linux系统,回车执行该命令,然后系统把结果数据输出到屏幕(缺省),如果有错误等信息也输出到屏幕,因正确和错误信息都输出到屏幕,有时造成一定的混乱,是否有方法把两者分开输出呢?有的,这里就涉及到数据流重定向过程。我们可把正确信息输出到一个文件,把错误信息输出到另一个文件,这是一个典型的数据流重定向问题。
Linux数据流重定向整个流程可图形化为:
(图3-3 数据流重定向图形)
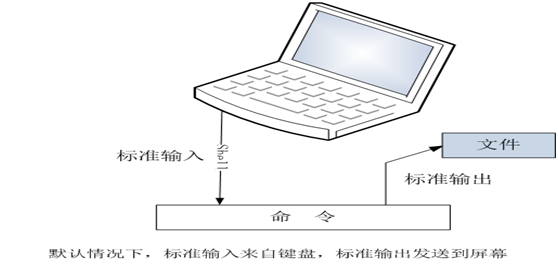
了解了数据流重定向的概念,理解它的意义就不难了。下图为数据流重定向的一般流程。
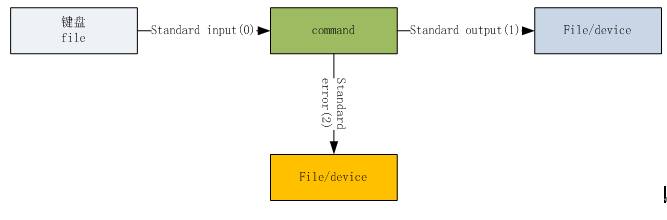
(图3-4命令执行的数据流向图)
其中标准输入(Standard input)可能比较好理解,说白了就是键盘或文件,命令(command)也不难理解,就是shell中一些命令,如ls、pwd、mkdir等等,标准输出(Standard ouput)可理解为执行命令后的正确信息,而标准错误(Standard error)输出就是命令执行失败的信息。
标准输入输出操作符的一些约定:
1. 标准输入(stdin):代码为 0 ,操作符有: < 或 << 2. 标准输出(stdout):代码为 1 ,操作符有: > 或 >>
3. 标准错误输出(stderr):代码为 2 ,操作符有: > 或 >>
shell遇到“>” 操作符,会判断右边文件是否存在,如果存在就先删除,并且创建新文件。不存在直接创建。 无论左边命令执行是否成功。右边文件都会变为空。
shell “>>”操作符,判断右边文件,如果不存在,先创建;如果存在,则追加。
shell “<”或“<<”操作符,与上面含有基本相同,只是操作其左边的文件。 下面举例说明数据流重定向及相关代码的应用:
$ ls -l >lstest.txt ###把ls -l结果保存到文件
###find为查找命令,即在目录/home/feigu/linux_test下查找文件lstest.txt
$ find /home/feigu/linux_test/ -name lstest.txt
/home/feigu/linux_test/lstest.txt
###把查找到的正确结果(代码为1)添加(操作符为>)到文件findstdout.txt
$ find /home/feigu/linux_test/ -name lstest.txt 1>findstdout.txt
$ cat findstdout.txt
/home/feigu/linux_test/lstest.txt
$ find /home/feigu/linux_test11/ -name lstest.txt 1>findstdout.txt
find: <code>/home/feigu/linux_test11/': No such file or directory
###把正确结果(代号为2)添加(>)到文件findstderr.txt
$ find /home/feigu/linux_test11/ -name lstest.txt 2>findstderr.txt
feigu@slave001:~/linux_test$ cat findstderr.txt
find: </code>/home/feigu/linux_test11/': No such file or directory
###把正确和错误信息同时((代码表示为:2>&1)追加(操作符为>>)到findstderr.txt
$ find /home/feigu/linux_test11/ -name lstest.txt >>findstderr.txt 2>&1
###把正确和错误信息存放到一个垃圾桶黑洞(/dev/null)里
$ find /home/feigu/linux_test11/ -name lstest.txt >/dev/null 2>&1
【延伸思考】
1、>或>>缺省会输出标准错误信息吗?即,不指明输出是1或2,或2>&1。
2、>或>>输出到文件后,屏幕上就看不到了;是否有方法能同时输出到文件和屏幕?
3.4 管道与过滤
过滤我们都不陌生,Linux也有管道?它长得啥样?有啥作用?不过我们日常生活中不少管道,如排水管道,把管道接前后连接,给我们带来很多便利和1+1>2的功效。我们知道管道的一个基本事实就是,前个管道的流出也就是后一个管道的流入。Linux中我们可以把一个命令看成一个管道,如果把两个的命令前后连在一起,那么前一个命令的输出就是后一个命令的输入,从这一点看,确实非常像管道,如下图:
图3-5 管道示意图
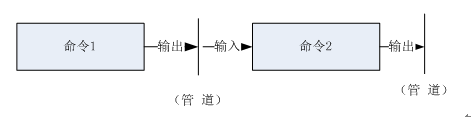
在Linux中管道用竖线(|)表示,其作用如何,我们还是让实例说话吧。
$ ls -l
total 28
-rw-rw-r-- 1 feigu feigu 154 Oct 16 11:11 conn_mysql.sh
drwxrwxr-x 2 feigu feigu 4096 Oct 18 11:35 mydirect
drwxrwxr-x 2 feigu feigu 4096 Oct 18 14:27 shell_script
-rw-rw-r-- 1 feigu feigu 3 Oct 18 14:28 te1.txt
-rw-rw-r-- 1 feigu feigu 3 Oct 19 08:31 tel.py
-rwxr--r-x 1 feigu feigu 82 Oct 18 23:45 test_bak.sh
-rwxr--r-x 1 feigu feigu 62 Oct 17 22:59 test.sh
$ ls -l|grep "drw" ###过滤出ls -l中的目录
drwxrwxr-x 2 feigu feigu 4096 Oct 18 11:35 mydirect
drwxrwxr-x 2 feigu feigu 4096 Oct 18 14:27 shell_script
这个结果其实不用管道也可实现,如:
第一步把ls -l的结果导入到文件中
第二步查找这个文件
但用管道,一步就搞定,而且逻辑非常清晰和直观!
其中grep为一个很有用的过滤命令,下面我们会重点介绍。
Linux中常用的过滤或查找命令有:
grep命令
grep 是一个强大的文本搜索工具,可以使用正则表达式(下节讲到),并返回匹配的行, 语法为:
grep [-cinv] '匹配字符串' filename
如果不指定file参数,grep命令将读取标准输入,如上例中的ls -l显示结果。“grep”源 于 ed(Linux的一个行文本编辑器)的 g/re/p 命令,g/re/p 是“globally search for a regular expression and print all lines containing it”的缩写,意思是使用正则表 达式进 行全局检索,并把匹配的行打印出来。
grep 命令有很多选项,比较常用的有:
-c ###输出匹配的总行数。
-i ###不区分大小写进行匹配。
-n ###输出匹配的行以及行号。
-v ###反转查询,输出不匹配的行。例如,grep -v "test" demo.txt 将输出不包含"test" 的行。
举例说明:
$ ls -l
total 20
-rw-rw-r-- 1 feigu feigu 154 Oct 16 11:11 conn_mysql.sh
drwxrwxr-x 2 feigu feigu 4096 Oct 18 11:35 mydirect
drwxrwxr-x 2 feigu feigu 4096 Oct 18 14:27 shell_script
-rwxr--r-x 1 feigu feigu 62 Oct 17 22:59 test.sh
-rw-rw-r-- 1 feigu feigu 38 Oct 21 15:00 Test.txt ###这个文件有个大写的T
feigu@slave001:~/linux_test$ ls -l|grep 'test' ####区分大小写
-rwxr--r-x 1 feigu feigu 62 Oct 17 22:59 test.sh
feigu@slave001:~/linux_test$ ls -l|grep -i 'test' ###带参数i,表示不区分大小写
-rwxr--r-x 1 feigu feigu 62 Oct 17 22:59 test.sh
-rw-rw-r-- 1 feigu feigu 38 Oct 21 15:00 Test.txt
feigu@slave001:~/linux_test$ ls -l|grep -in 'test' ###同时输出行号
5:-rwxr--r-x 1 feigu feigu 62 Oct 17 22:59 test.sh
6:-rw-rw-r-- 1 feigu feigu 38 Oct 21 15:00 Test.txt
cut命令
cut是一个选取命令,以行为单位,用指定分隔符将行切分为若干字段,选取所需 要的字段。命令格式为:
cut -d '分隔符' -f 字段 filename
cut -c 字符范围 file
如果不指定file参数,cut 命令将读取标准输入。
使用实例:
$ cat Test.txt ###该文件是以冒号为列分隔符
hadoop:hbase:hive
Spark:RDD:DataFrame
$ cat Test.txt |cut -d ":" -f 2 ###取第2列
hbase
RDD
$ cat Test.txt |cut -d ":" -f 2,3 ###取第2,3列
hbase:hive
RDD:DataFrame
$ cut -c 3 Test.txt ###取第3个字符
d
a
$ cut -c 3- Test.txt ###取第3个及以后的所有字符
doop:hbase:hive
ark:RDD:DataFrame
$ cut -c 3-10 Test.txt ###取第3至10个字符
doop:hba
ark:RDD:
熟悉数据库的朋友或许会联想到,grep命令有点像是查询表中某些行,而cut是取表中一些列。为方便理解我们也不妨把grep理解为横切,cut为纵切。
3.5 正则表达式
表达式这三个字相信我们都比较熟悉,加上正则两字好像有点怪怪的,正则表达式(Regular Express,RE)实际上就是一种匹配模式,利用这种模式有利于我们更精准、更灵活地定位。
正则表达式运用非常广泛,不但Linux有,Python、Java、c、C++、scala,数据库等等都有,学好了可以大大提高你的工作效率,尤其在涉及查找、过滤等方面。正则表达式可进一步细分为基础正则表达式和扩展正则表达式,其中基础正则表达式比较常用。
grep、sed、awk、vi或vim等命令支持正则表达式,查询或匹配某字符或字符串时,往往需要使用正则表达,正则表达式的具体规则请参考下表。
(表3-2 正则表达式)
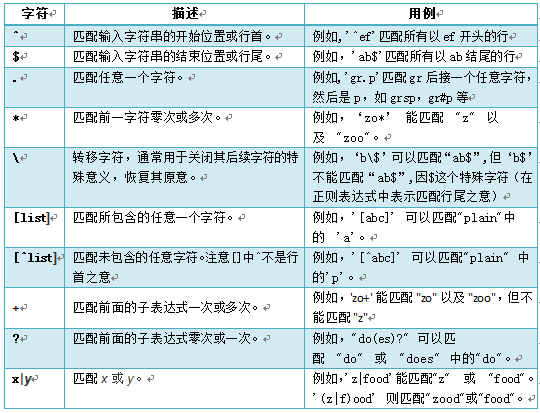
注:
1、最后4个为扩张正则表达式,需使用egrep命令
2、ls 、find、cp等命令不支持正则表达式,需采用bash通配符,如*(任意多个字符),?(任意一个字段)等。
3.6 数据处理常用工具
数据处理时一项非常重要的工作,据那些搞大数据的大师说,数据挖掘、机器学习等数据处理要占整个工作量的80%,而且这块的工作好坏直接影响数据的质量,没有好的质量,挖出的结果也很难保在上面进行证质量。
其实数据处理也是我们平常经常遇到的问题,如修改一些数据、删除一些数据、新增一些数据等等。在windows中我们要修改数据,通常使用word、txt、execel、UltraEdit、NotePad等编辑工具,用这些工具处理数据一般都要先打开,如果遇到一个有几百万行的文件,能open就不错了,更不用说open处理了!
在Linux中难道可以不打开就修改文件?完全可以,而且只要编写一些简单命令就可处理很多复杂问题、还可以一次修改几十份文件、几百份文件!它有何神器呢?
前几节我们讲了如何在文件中精准查询、精准定位等问题,所需字符或行找到了,再使用一些可增删改的工具,如sed、awk等,问题就好解决了。下面我们介绍Linux中有关命令。
wc [-lwm]
这个命令可以用来查看文件的记录数、字节数等。
-l ###打印出行数
-w ###打印出单词数(英文)
-m ###打印出字符数
$ ls -l
total 20
-rw-rw-r-- 1 feigu feigu 154 Oct 16 11:11 conn_mysql.sh
drwxrwxr-x 2 feigu feigu 4096 Oct 18 11:35 mydirect
drwxrwxr-x 2 feigu feigu 4096 Oct 18 14:27 shell_script
-rwxr--r-x 1 feigu feigu 62 Oct 17 22:59 test.sh
-rw-rw-r-- 1 feigu feigu 38 Oct 21 15:00 Test.txt
$ ls -l|wc
6 47 277
[行数] [单词数] [字符数] ###这里的单词以空格分隔
$ ls -l|wc -l
6
$ ls -l|wc -w
47
$ ls -l|wc -m
277
sed
sed 编辑器逐行处理,处理时,把当前处理的行存储在临时缓冲区中,接着用sed命令处理缓冲区中的内容,处理完成后,
把缓冲区的内容送往屏幕。文件本身并没有改变,如果你要保存修改,可以重定向到另一个文件。不过如果使用-i 参数,将直接修改原文件! 其命令格式为:
sed [-参数] '动作' 文件(或标准输入)
下面我们通过一些实例,来说明sed的使用:
删除行,使用参数d
sed '3d' file ###删除第三行的内容
sed '3,$d' file ###删除从第3行到最后一行的内容。
sed '$d' file ###删除最后一行的内容
替换字符(串),使用参数s
sed 's/abc/def/g' file ###把行内的所有abc替换成def,如果没有g,则 ###只替换行内的第一个abc
sed -n 's/abc/def/p' file ###只打印发生替换的那些行
追加行,使用参数a
sed '/spark/a\python pandas' file ###在包含spark的行后新起一行,写入 ###python pandas
sed '/spark/a\python pandas' file>file01 ###把结果存放到另一个文件
结合管道及正则表达式
$ ls -l
total 24
-rw-rw-r-- 1 feigu feigu 154 Oct 16 11:11 conn_mysql.sh
drwxrwxr-x 2 feigu feigu 4096 Oct 18 11:35 mydirect
drwxrwxr-x 2 feigu feigu 4096 Oct 18 14:27 shell_script
-rw-rw-r-- 1 feigu feigu 36 Oct 22 15:34 test11.txt
feigu@slave001:~/linux_test$ ls -l|grep '^d' ###选择目录
drwxrwxr-x 2 feigu feigu 4096 Oct 18 11:35 mydirect
drwxrwxr-x 2 feigu feigu 4096 Oct 18 14:27 shell_script
feigu@slave001:~/linux_test$ ls -l|grep '^d'|sed 's/.*script$//g' ##置空第2行
drwxrwxr-x 2 feigu feigu 4096 Oct 18 11:35 mydirect
feigu@slave001:~/linux_test$ ls -l|grep '^d'|sed 's/.*script$//g'|sed '/^$/d'
drwxrwxr-x 2 feigu feigu 4096 Oct 18 11:35 mydirect ##删除空行结果
awk
sed命令用来定位到行,如果我们想定位到‘列’或‘字段’,有相关命令吗?awk就是。这个命令很强大,而且比较好用,和sed一样,awk也是逐行处理的,通常用来处理一些小数据,其命令格式为:
awk '条件1{动作1}条件2{动作2}...'
注意:awk条件和动作需要放在单引号内,动作放在{}内。
$ ls -l
total 12
-rw-rw-r-- 1 feigu feigu 154 Oct 16 11:11 conn_mysql.sh
drwxrwxr-x 2 feigu feigu 4096 Oct 18 11:35 mydirect
drwxrwxr-x 2 feigu feigu 4096 Oct 18 14:27 shell_script
feigu@slave001:~/linux_test$ ls -l|awk '{print $0}' ###$0表示所有列
total 12
-rw-rw-r-- 1 feigu feigu 154 Oct 16 11:11 conn_mysql.sh
drwxrwxr-x 2 feigu feigu 4096 Oct 18 11:35 mydirect
drwxrwxr-x 2 feigu feigu 4096 Oct 18 14:27 shell_script
feigu@slave001:~/linux_test$ ls -l|awk '{print $1,$9}' ###$1表示第1列
total
-rw-rw-r-- conn_mysql.sh
drwxrwxr-x mydirect
drwxrwxr-x shell_script
feigu@slave001:~/linux_test$ ls -l|awk '{FS=" "}{print $1,$9}' ###列的分隔符为 ###空格
total
-rw-rw-r-- conn_mysql.sh
drwxrwxr-x mydirect
drwxrwxr-x shell_script
【延伸思考】
sed、grep、awk等可以很方便批量处理多个文数据文件,尤其对不一些不很庞大的数据。但如果需要处理几个G、几百上千个G、甚至更大更复杂的数据(如图像、视频等等),该咋办呢?目前是否已有好用又高效处理工具?答案是肯定的!稍大的一些文件可以使用python、pandas、Java等,大数据可使用Hadoop、Hive、HBase、Spark等技术,这些技术都基于Linux,这些技术或工具不但解决了大数据存储问题、大数据处理、大数据计算等问题,还有很好的可靠性,这些技术我们后面将一一介绍。
3.7 shell脚本
shell脚本(shell script)是啥样?为何要使用shell脚本?用了能带来啥好处?不用又会带来哪些不便?
shell脚本简单来说就是由shell命令写成一个程序,有点类似windows中dos下批处理文件(.bat),shell脚本无需编译就可直接运行。
假设哪天要你管理几十台甚至几百几千台Linux服务器,需要在每台服务器上创建很多相同目录、修改很多相同配置文件,你该如何处理呢?在每台服务器上都一个一个命令执行一下?恐怕几天都搞不完,即使完成了,也很难保证在每台服务器上做的都是一样。
如果我们把这些命令写成一个脚本,并在一台服务器上测试好,那么剩下的工作就是把这个脚本部署不同服务器上,运行一下即可(熟练的话,这些部署和运行都可一键搞定),如此不但快、而且质量也高。这就是shell脚本强大之一。
下面我们试着写一个简单的shell脚本,加深大家的理解。
$ cat myfirst.sh ####shell脚本名称,以sh为扩展名
#!/bin/bash ###说明使用哪种shell解释你的程序,这里使用bash
#在界面上显示字符串 ###这一行为注释,shell注释用井号(#)
echo "I like linux!" ###把字符串“I like linux!”输出到窗口
关于编辑shell脚本的几个良好习惯
1、第一行说明用哪种shell解释你的脚本
如:#!/bin/bash
2、说明该脚本的功能、变更历史等。
3、添加必要的注释,方便别人更好理解你的程序,尤其是团体开发时。
脚本写好了,该如何执行呢?很简单哟,shell脚本无需编译,可以直接运行,运行方式大致有:
1、利用sh或bash运行,直接运行,但脚本权限要求不高,有读的权限即可。
如:sh myfirst.sh
2、利用. ./myfirst.sh或source ./myfirst.sh的方式,可直接运行, 有读的权限即可。
注./myfirst.sh前有空格
3、如果脚本有执行权限(即x权限),可采用如下格式:
./myfirst.sh
3.8 控制语句
shell流程控制语句常用的有三种:条件判断语句、选择语句、循环语句。
条件判断语句
简单判断语句
if [ 条件判断式 ]; then ###[ 条件判断式 ]中条件判断式前后要有空格,否则会 ###报错!
条件判断成立时的执行语句
fi ###大家注意一个有趣的情况,if反过来写就是fi,shell中类型情况有不少。
复杂一点的判断语句
if [ 条件判断式 ]; then
条件判断成立时的执行语句
else
条件判断不成立时的执行语句
fi
更多条件的判断语句
if [ 条件判断式1 ]; then
条件判断1成立时的执行语句
elif [ 条件判断式2 ]; then
条件判断2成立时的执行语句
fi
$ vim myfirst01.sh
#!/bin/bash/
##功能:测试判断语句
##定义变量
a=10
b=20
##根据a、b值的大小,输出不同提示。
if [ $a == $b ];then
echo "a is equal to b"
elif [ $a -gt $b ];then
echo "a is greater to b"
else
echo "a is less to b"
fi
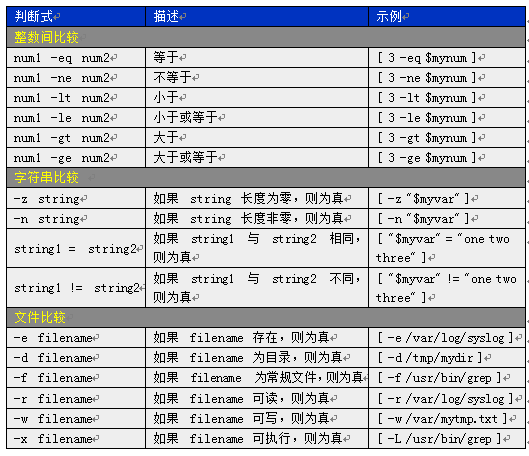
注意,shell中判断整数不是用,>,=,< 之类,而是gt ==,lt 。下表为shell常用判断式: (表3-3 shell常用判断式)
分支选择语句 如果一个变量有多种情况,可以用上面的if 语句,但如果用分支选择语句逻辑更清晰,分支选择语句的语法格式为: case $var in pattern1) ###模式后需要加上) act1 ;; ###;;表示每段任务执行结束 patern2) act2 ;; *) ###*代表其它情况 act3 ;; esac ####case反过来写就是esac
$ vim myfirst02.sh #!/bin/bash/ ##功能:测试选择语句 ##显示输入提示 read -p "请输入选择的数据:" var1 case $var1 in 1) echo "你选择第1项" ;; 2) echo "选择了第2项" ;; *) echo "你选择了其它项" ;; esac
for循环语句 for循环语句常用来已知要循环的次数或循环一个列表,具体语法格式为: for var in con1 con2 con3 ... do act done 或 for ((初始值 ; 条件;步长或运行语句)) do act done
$ vim myfirst03.sh #!/bin/bash/ ##功能:测试for循环语句 for i in $(seq 5) ###$(seq 5)产生一个序列:1 2 3 4 5 do echo "$i" done
while循环语句 其语法格式为: while [condition] do act done until 循环语句 until 循环语句格式为: until [condition] do act done 【延伸思考】 这里我们提到了判断语句、选择语句、循环语句,这些语句无疑在处理一些数据分支或序列方面的问题带来了很大的方便,但也存在一些不足,如果分支很多,如果我们要在循环中又实行判断等等,虽能实现,步骤就比较多了,步骤一多,程序逻辑的清晰度、可读性等就大大下降了。是否有更简洁的方法?如可以把循环与判断结合在一起、甚或不用循环语句?好消息是,有并且很多,如在Python、scala中就有很好的解决方案,这些方案或技术后续我们也会向大家介绍。
第4章 日常管理
4.1 搜索目录或文件
使用Linux时,有时忘记上次编辑的文件存放在哪里?但还记得部分文件名称或大致修改时间等线索,此时我们该如何做呢?这样的需求应该是很平常,就像我们平常百度一样。 Linux中有很多方法可以用来查找目录或文件,如前面提到的ls、pwd、grep命令等,除了这些命令之外,还有which、type、whereis、locate、find等,下面我们就来介绍这些命令的使用。
which命令
which命令一般用来查询执行文件,而且是从$PATH这个环境变量中查询。使用格式为:
which [-a] 执行文件 -a ###将所有在PATH中能找到的文件
feigu@slave001:~$ which python
/home/feigu/anaconda2/bin/python
feigu@slave001:~$ which -a python
/home/feigu/anaconda2/bin/python
/usr/bin/python
feigu@slave001:~$ which cd
feigu@slave001:~$ ###cd 因时shell内置命令,不在$PATH中
which命令无法查询内置命令,但我们可以用type命令来查找。
type命令 使用type可以查找shell的外部命令、内部命令等,语法格式为:
type [-a] 文件 -a ###显示所有可能的类型,如有些命令如cd是shell内置命令,也可以是外部命令。
feigu@slave001:~$ type -a cd
cd is a shell builtin
feigu@slave001:~$ type -a ls
ls is aliased to <code>ls --color=auto'
ls is /bin/ls
whereis 命令
whereis 、locate都是从linux的数据库文件中查询,不是从硬盘查询(如find命令),故查询效率比较高,其语法格式如下: whereis [-msu] 文件
-m ###显示在manual路径下的文件
-s ###显示source源文件
-u ###显示其他特殊文件
feigu@slave001:~$ whereis pwd
pwd: /bin/pwd /usr/include/pwd.h /usr/share/man/man1/pwd.1.gz
feigu@slave001:~$ whereis -u mysql
mysql: /usr/bin/mysql /etc/mysql /usr/lib/mysql /usr/bin/X11/mysql /usr/include/mysql /usr/share/mysql /usr/share/man/man1/mysql.1.gz
feigu@slave001:~$
locate命令
locate也是从Linux的数据库文件中读取,但比whereis更灵活,其参数可使用正则表达式,其语法格式为:
locate [-ir] 文件或目录
-i ###查询时忽略大小写
-r ###后可接正则表达式
feigu@slave001:~$ locate -n 5 -i ipython ###查看含ipython目录或文件的前5条
/home/feigu/.ipython
/home/feigu/.ipython/README
/home/feigu/.ipython/extensions
/home/feigu/.ipython/nbextensions
/home/feigu/.ipython/profile_default
feigu@slave001:~$ locate -n 5 -r ^/var/lib/dpkg/info ###查看以/var/lib开头的
/var/lib/dpkg/info
/var/lib/dpkg/info/accountsservice.conffiles
/var/lib/dpkg/info/accountsservice.list
/var/lib/dpkg/info/accountsservice.md5sums
/var/lib/dpkg/info/accountsservice.postinst
find命令
如果用whereis和locate无法查找到我们需要的文件时,可以使用find,但是find是在硬盘上遍历查找,因此将消耗较多资源,而且速度也比较慢,不过find可以根据指定路径或修改时间等进行查找,其语法格式为:
find [路径] [参数] [-print ] [-exec 或-ok command] {} \;
时间参数:
-mtime n ###列出n天之前的1天之内修改过的文件 (或距当前n*24 与(n+1)*24 ###小时)
-mtime +n ###列出n天之前(不含n天本身)修改过的文件
-mtime -n ###将列出n天之内(含n天本身)修改过的文件
名称参数:
-group name ###寻找群组名称为name的文件
-user name ###寻找用户者名称为name的文件
-name file ###寻找文件名为file的文件(可以使用通配符)
-print ###将查找到的文件输出到标准输出
-exec command {} \; ###将查到的文件执行command操作,{} 和 \;之间有空格
-ok ###和-exec相同,只不过在操作前要询用户
###列出1天内修改过的文件
feigu@slave001:~$ find /home/feigu/linux_test/ -mtime -1 ###列出/home/feigu/linux_test目录下文件以myfirst开头的文件
feigu@slave001:~$ find /home/feigu/linux_test/ -name myfirst* -print
4.2 查看资源使用情况
在日常管理中,我们经常需要了解目前系统的资源使用情况,如硬盘使用、内存使用等。查看硬盘使用可用df -m,内存使用情况可用free -m,此外了解系统整体使用情况还可用top等命令。
feigu@slave001:~$ df -m Filesystem 1M-blocks Used Available Use% Mounted on /dev/xvda1 20157 17218 1915 90% / udev 489 1 489 1% /dev tmpfs 100 1 99 1% /run none 5 0 5 0% /run/lock none 498 0 498 0% /run/shm none 1 0 1 0% /sys/fs/cgroup
feigu@slave001:~$ free -m total used free shared buffers cached Mem: 994 709 284 0 17 21 -/+ buffers/cache: 671 322 Swap: 1999 60 1939
4.3 进程管理功能 如何查看当前正在运行的进程?如何停止一些不必要的进程?如何把一些任务放在后台运行?(即使你断开客户端程序能继续运行)如何实现前后台进程的转换?下面我们来介绍这方面的问题的处理方法。
ps -ef ###查看当前所有进程
jobs -r ###列出在后台运行的进程
netstat ###查看当前网络及端口使用情况
pstree [-Ap] ###查看进程树
kill -9 PID ###强行停止进程号为PID的进程
Ctrl+c ###停止终端正在运行的任务,如一个正在运行的find命令
ctrl+d ###暂停终端正在运行的任务,如一个正在运行的find命令
第5章 实例详解
5.1 编写导航菜单
操作Linux一大麻烦就是输入命令,虽然Linux为了提高大家的输入效率,内部做了很多工作,如Tab键的补全功能、把相关shell命令行放在一个脚本文件中,利用脚本文件可以重复使用还可以移植到其他服务器上等等,确实大大减少了工作量、同时也极大的提高了正确率。有些人还想,是否有更简单、更直观的方法,如像windows中的菜单式的方法? 有的,本节我们就来做这方面的一个工作,即生成一个Linux的菜单式界面,然后像操作菜单一样来完成我们的任务。
这里的业务场景就是,通过菜单式的方法来安装大数据多种重要组件,主菜单界面如下:

实现以上界面及功能的代码:
$ vim install_hadoop_mainmenu.sh
#!/bin/bash
#****************************************************************************
#文件名称: hadoop_intall_mainmenu.sh
#功能概述: 通过菜单方式安装hadoop各组件.
#作者姓名: 吴茂贵
#创建日期: 2016-10-20
#修改历史:
#****************************************************************************
##获取系统时间
V_SYSTIME=</code>date +%EY-%m-%d-%H:%M:%S<code>
##进入主界面菜单
##利用一个条件始终为真的while循环
while true
do
clear
echo -e "\n\n \t\t \033[40;32m ======飞谷安装Hadoop主界面======\033[1m \t\t " echo -e "\n"
echo -e "\t"1\)安装Hadoop
echo -e "\t"2\)安装Spark
echo -e "\t"0\)退出 echo -e "\n"
echo "请选择(可单选或多选,多选以逗号分隔,如1,2):"
read choice
#利用选择分支语句,根据不同选择,进行相关操作
case $choice in
0 ) break
cd .
;;
1 )
echo "正在安装Hadoop..."
read menu
continue;;
2 ) echo "正在安装Spark..."
read menu continue;;
1,2 ) echo "正在安装Hadoop和Spark..."
read menu continue;;
esac
done
获取Linux系统日期或时间及加减示例
###获取系统时间
V_SYSTIME=</code>date +%EY-%m-%d-%H:%M:%S<code>
hadoop@master:~$ v_sysdate=</code>date +%Y-%m-%d' '%H:%M:%S<code>
hadoop@master:~$ echo $v_sysdate 2016-12-12 15:42:55
hadoop@master:~$ v_sysdate1=$(date +%Y-%m-%d' '%H:%M:%S)
hadoop@master:~$ echo $v_sysdate1 2016-12-12 15:43:56
###获取系统日期
hadoop@master:~$ v_date=$(date +%Y-%m-%d)
hadoop@master:~$ echo $v_date 2016-12-12
###获取明天日期,可以+,- day,month,year等
hadoop@master:~$ v_date1=$(date +%Y-%m-%d --date="+1 day")
hadoop@master:~$ echo $v_date1 2016-12-13
5.2 Shell处理文件 处理文件或处理数据,是大数据开放、大数据分析、机器学习等一项非常基础、非常重要的任务,而且在整个数据分析生命周期中大约占比70%左右,如果数据比较复杂,可能还要超过这个比例。由此可见其作用和意义了。如何处理文件或数据?需要用哪些命令或工具?下面我们通过一些实例来说明。 业务场景是,有一个文件,共有5行,第5行为垃圾数据需要清理,列之间的分隔符是竖线(|),文件中还有乱字符(^M)需要清理,清理数据后,取出前2列,如果有空行,需要删除空行。
$ cat list.lst
linux|shell|function
python|ipython|pandas
hadoop|yarn|hdfs^M
spark|sparkSQL|sparkML^M
sfssf
$ sed 5d list.lst
linux|shell|function
python|ipython|pandas
hadoop|yarn|hdfs^M
spark|sparkSQL|sparkML^M
####^为特殊符号,需要把取消其特殊含义,故需要用转移字符""
$ sed 5d list.lst |sed 's/\^M//g'
linux|shell|function
python|ipython|pandas
hadoop|yarn|hdfs
spark|sparkSQL|sparkML
$ sed 5d list.lst |sed 's/\^M//g'|awk '{FS="|"}{print $1,$2}'
linux|shell|function
###第一行没有变化,因FS缺省为Tab分割,第一行$0,$1等
###需从第二行开始生效,为此,可加上BEGIN关键字,从第
###一行开始生效
python ipython
hadoop yarn
spark sparkSQL
$ sed 5d list.lst |sed 's/\^M//g'|awk 'BEGIN {FS="|"}{print $1,$2}'
linux shell
python ipython
hadoop yarn
spark sparkSQL
$ sed 5d list.lst |sed 's/\^M//g'|awk 'BEGIN {FS="|"}{print $1,$2}' \ > |sed '/^\s*$/d' ###去由Tab、空格组成的空行删除
linux shell
python ipython
hadoop yarn
spark sparkSQL
$ sed 5d list.lst |sed 's/\^M//g'|awk 'BEGIN {FS="|"}{print $1,$2}' |sed '/^\s*$/d'\ ###最后这个\,表示续行,\s匹配<空格>、 ##
> >clear_list.lst ####把结果重定向到文件中
$ cat clear_list.lst
linux shell
python ipython
hadoop yarn
spark sparkSQL
####从文件随机抽取2000条
shuf -n2000 kddcup.data >kddcup2000.data
【延伸思考】
通过shell命令sed、awk、cut等可以对一些文件进行增删改,这无疑带来很大方便,但这种方式也有很多不足,除操作不方便外、对并发处理、快速定位、保证多人修改数据一致性等等都存在严重不足。这些不足如果是离线或只有个人使用,体现不出来,但如果很多人需要同时使用这个问题,这些不足就非常严重、甚至是致命的。如何克服这些不足,数据库管理思想为我们提供了非常高效的解决之道,至于数据库管理系统是如何实现或解决这些不足的,大家可留意后续章节介绍的MySQL。
5.3 Shell函数
为什么要使用shell函数?不用shell函数是否可以?函数我们平常应该经常打交道,如excel中的求和函数、统计函数、三角函数等等,这些函数给我们带来很大方便,其实shell函数的作用一样,主要是为提高效率及增强程序的可读性和可靠性。是否使用函数,看情况而定,如果你的程序本身就很简单,不用也可以,但如果你的程序比较复杂,其中有些模块需要多次或多地使用,那么此时把这些模块用函数来表示、开发效率将显著提升。
shell函数的创建和调用其实很简单,下面我们来介绍函数的定义、函数调用、函数的返回值等。
函数的定义或语法:
[function]functionname[()]
{
action;
[return value;]
}
几点说明:
1、可以带function fun() 定义,也可以直接fun() 或fun定义,不带任何参数。
2、参数返回,可以显示加:return 返回,如果不加,将以最后一条命令运行结果,作为返回值,return后跟数值n(0-255),通过$?系统变量获取返回值;如果要返回大于255的数、浮点数和字符串值,最好用函数输出到变量。如在函数最后echo $v1 然后通过V2=funct1()方式捕获函数返回值。
3、函数的调用:
函数调用需放在函数定义后,因shell是由上向下逐步执行的
无参数情况:函数名
有函数情况:函数名 参数1 参数2 ... 参数间用空格分开
4、有关参数变量或位置变量
$# 表示参数总数
$0 代表函数名称
$1 表示第一个参数
$2 表示第二参数,以此类推。
以下我们通过一些实例来进一步说明函数的使用。
feigu@slave001:~$ vim testfun1.sh
#!/bin/bash
###在函数定义前,试图调用函数
fSum 3 2;
function fSum()
{
if [ $# -ne 2 ] ;then
echo "请检查函数$0 的参数 a,b"
#exit
fi
echo $1,$2
###求和,并返回其结果
return $(($1+$2))
}
###调用函数
fSum 10 8
###调用函数,并试图把函数返回值给变量total
total=$(fSum 3 2)
echo "total的值:"$total "\$?的值: "$?
###只传一个参数
#fSum 100
###传入的参数和超过255
total10=</code>fSum 100 160<code>
echo "total10的值:"$total10 "\$?的值: "$?
feigu@slave001:~$ sh testfun1.sh
testfun1.sh: line 4: fSum: command not found
10,8
total的值:3,2 $?的值: 5
total10的值:100,160 $?的值: 4
hadoop@master:~/wumg/linux$ cat f1.sh
#!/bin/bash
f1()
{
a=$1 #第一个参数值放到变量a里面
echo $a #打印变量a的值
return $a #把a的值作为函数的返回值
}
#f1 10
#echo $? #查看上一个命令的返回值
#c=</code>f1 200<code> #反单引号里面的语句将作为命令执行,把执行结果放入变量c里面
#d=$(f1 300) #$()中的内容会自动执行,把执行结果放入变量d中
f1 300
echo $?
#echo $c
#echo $d
【延伸思考】
很多相同或相似的功能,我们可以用函数来模块化、封装化,定义一次,以后就可重复使用千万次,如上面我们定义的求两数的和这个函数。当然,这是一个非常简单的函数,而且输入也很严格,内部也没有做异常识别或处理。但这样业务的需求还是比比皆是,尤其涉及到一些稍大一些的项目,这种模块化的处理方式,不但能极大提高我们的开发效率、更重要的是大大提高整个程序的可靠性、可移植性等等。
沿着这个思路想下去,如果fsum能做到不受输入参数个数的限制,那它的通用性就更好了,如何实现这些方法?开发工具python、java、scala等等都有很好的解决方法。
如果类似的函数有很多,而且除了函数,还有很多变量值,缺省值或枚举值等等,那我们又该如何有效管理呢?我们前辈,也想到了很好的解决之道,那就是对象的引入,一个对象可以包括很多函数或方法,还可以包含很多变量或常量等,这是一个更高一级的模块化。
对象问题Linux没有涉及到,后续Python、java、scala中大家会学到。
5.4 Shell操作数据库
现在企业的数据大部分存储在数据库中,但无法直接对数据库中的数据进行分析、挖掘、机器学习等,因为数据库中没有这些算法,因此,如果要对这些数据进行分析,往往先把这些数据保存到文件中,然后与其他数据结合进行分析、挖掘。
如果要用shell操作数据库,首先必须连接数据库,然后操作数据库,如何连接数据库呢?这里我们以MySQL为例,MySQL数据库是开源免费的,而且通过多年的发展,不但好用,而且还很稳定,所以目前在很多中小企业中运用非常广泛。
如何连接?如何操作?我们还是通过实例来说明。环境是Linux服务器(服务器IP已知)上安装了MySQL数据库,数据库名称为testdb,还知道连接数据库的用户及密码等信息。
有了这些我们就可以着手工作了。
$ vim conn_mysql.sh
#!/bin/bash
#get mysql path
MYSQL=</code>which myql<code>
mysql -h slave02 -u feigu -p testdb <<EOF
show databases;
EOF
if [ $? -eq 0 ]; then
echo "连接数据库--成功!"
else
echo "连接数据库--失败!"
fi
$ sh conn_mysql.sh
Enter password:
Database ###显示目前存在的数据库
information_schema
mysql
performance_schema
testdb
连接数据库--成功!
连接数据后,如果我们想操作一下数据库,如创建表,往表中插入记录,然后验证结果是否与期望的一致等,这些任务用shell如何实现呢?请看下例:
#!/bin/bash
#get mysql path
MYSQL=</code>which myql<code>
mysql -h slave02 -u feigu -p testdb <<EOF
DROP TABLE IF EXISTS test10;
create table test10 (name varchar(10),age int);
insert into test10 values('zhangfei',88);
insert into test10 values('liuting',26);
select * from test10 \G;
EOF
feigu@slave001:~/linux_test$ sh insert_data.sh
Enter password:
*************************** 1. row ***************************
name: zhangfei
age: 88
*************************** 2. row ***************************
name: liuting
age: 26
5.5 定时调度
场景:如果有个任务要求在凌晨1点运行、或从9点到16点每隔1分钟运行一次,我们该如何处理呢?守到凌晨1点运行这个程序?当然大可不必,借助Linux的调度器(crontab),你可轻松搞定这些任务。同时通过定时任务的执行加深对环境变量、登录配置参数等的理解。
crontab 是Linux、Unix等系统下的定时任务触发器,在crontab中定义好要调度的时间、频率及要执行的文件等信息,Linux服务器将按照的要求进行调度和执行。windows是否有呢?当然有,windows在计算机管理=>系统工具=>任务计划程序。
(图5-1 windows定义定时调度任务)
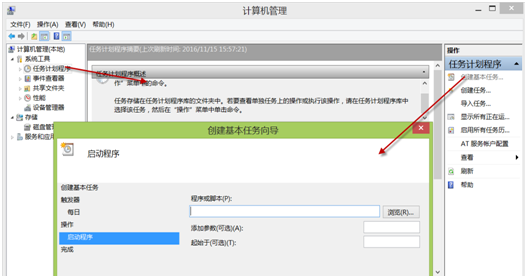
其中,触发器定义调度时间及频率(不过最小单位天,不像Linux下的crontab可以精确到分。);操作部分定义执行程序或发邮件等;应用程序一般指写好批处理bat文件等。
Linux下的定时定义类似,但内容更丰富、功能更强大。调度时间及频率格式如下:
* * * * * 共六段,前五段为时间,第六段是命令或脚本,段之间用空格隔开。
段 含义 取值范围
第一段 代表分钟 0-59
第二段 代表小时 0-23
第三段 代表日期 1-31
第四段 代表月份 1-12
第五段 代表星期几 0-6(0-星期日)
几个示例:
0 * * * 0,6 /usr/lib/sa/sa1 (每星期六、日)
0 8-17 * * 1-5 /usr/lib/sa/sa1 1200 3
15 4 1 * * /usr/lib/acct/monacct > /dev/null 2>&1
0 6-12/2 * * * /usr/lib/acct/monacct > /dev/null 2>&1(6点到12点每隔2小时执行一次命令)
0,30 * * * * /usr/lib/acct/monacct > /dev/null 2>&1(每隔半小时运行一次)
如何查看或修改当前用户的定时调度任务?可用如下命令:
crontab -l(查看当前用户所有crontab任务)
crontab -e (编辑当前用户crontab任务)
以下通过实例来说明如何创建crontab及使用crontab可能出现的问题和解决方法。
先用通过crontab执行一个简单语句,把crontab的环境变量导出到一个文件。
注:第一次使用crontab -e 打开时,可能会提示你选择编辑器,建议选择vim
如果不提示,但出现的为不是vim或vi编辑器,可用命令:export EDITOR=vim把当前进程的编辑器指定为vim。
hadoop@master:~$ crontab -e
在打开的crontab后,在最后一行添加如下语句:
0-59/1 * * * * echo </code>env<code>>env_log.txt
以下是env_log.txt文件内容
hadoop@master:~$ cat env_log.txt
LANGUAGE=en_US:en HOME=/home/hadoop LOGNAME=hadoop PATH=/usr/bin:/bin LANG=en_US.UTF-8 SHELL=/bin/sh PWD=/home/hadoop
为了便于测试,我们使它每隔1分钟执行1次。大家把env_log.txt的结果
与在命令行直接运行env这个命令的结果比较一下,看是否一样,如果不一样,为什么?
在3.2节,我们介绍了登录shell与非登录shell的区别,最大的区别就是读取配置文件的不同,从而导致它们的环境变量不一样,环境变量不一样会导致什么结果呢?我们来看一个实例。
这是执行的一个shell脚本,主要功能是连接MySQL数据库,然后创建一个表并往表中插入2条记录。
$ cat insert_sql.sh
#!/bin/bash
#get mysql path
MYSQL=</code>which myql`
mysql -h slave02 -u feigu -p testdb <<EOF
DROP TABLE IF EXISTS test10;
create table test10 (name varchar(10),age int);
insert into test10 values('zhanghua',22);
insert into test10 values('liuting',26);
EOF
if [ $? -eq 0 ]; then
echo "操作数据库成功"
else
echo "操作数据库失败"
fi
我们直接在命令行执行这个脚本
hadoop@master:~/wumg/linux/cron$ ls -l
total 4
-rw-rw-r-- 1 hadoop hadoop 352 Nov 15 17:25 insert_mysql.sh
hadoop@master:~/wumg/linux/cron$ sh insert_mysql.sh
操作数据库成功 ###执行成功
接下来,我们通过crontab来调度该脚本,为此,在crontab中添加如下一条语句:
0-59/1 * * * * sh insert_mysql.sh >log.txt 2>&1
我们查看log.txt是
hadoop@master:~$ cat log.txt
sh: 0: Can't open insert_mysql.sh
从以上运行日志可以看出,运行失败,失败的原因是什么呢?请大家看一下env_log.txt日志内容,这说明crontab执行的无登录的shell脚本,环境变量PATH中没有脚本insert_mysql.sh所在的路径,故系统找不到或无法open该脚本,那该如何解决呢?
我们可以在crontab执行命令中添加该脚本的绝对路径,就可以。把执行语句改为:
0-59/1 * * * * sh /home/hadoop/wumg/linux/cron/insert_mysql.sh >log01.txt 2>&1
过一会儿,我们查看日志文件log01.txt
hadoop@master:~$ cat log01.txt
操作数据库成功
说明这次执行成功了!
【延伸思考】
环境变量问题,除了添加绝对路径外,想一想还有其他方法吗?
5.6 服务器间的ssh无密码传输
【这节为了解内容,后续《hadoop课程》将有更详细介绍。】
场景:假如你正在管理1000台Linux服务器、甚至更多,你需要把一些文件或数据发布或传输到其他服务器上,如果不做处理,每次都要输入密码,当然更不方便写一个代码自动分发。能否写一个代码自动分发传输时无需输入密码?
这就涉及到ssh无密码传输问题,这节就是介绍ssh无密码传输含义及设置方式,配置好以后,使用ssh或scp到另外一台服务器,就无需输入密码了。
环境:A、B两台Linux服务器,实现从A到B的无密码传输。
5.6.1 SSH简介
(1)SSH定义
SSH 为 Secure Shell 的缩写,由 IETF 的网络工作小组(Network Working Group) 所制定,是建立在应用层和传输层基础上的安全协议。
SSH是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用SSH 协议可以有效防止远程管理过程中的信息泄露问题。
(2)SSH提供两种安全级别的安全论证
基于密码
基于密钥
5.6.2 SSH无密码传输
由master到slave01节点,可以通过以下命令:
登录master节点后,在命令行输入:ssh slave01 即可无密码进入slave01节点。
退回master节点,可在salve01节点,输入exit即可,具体请看以下示例。
hadoop@master:~$ ssh salve01
ssh: Could not resolve hostname salve01: Name or service not known
hadoop@master:~$ ssh slave01
Welcome to Ubuntu 14.04.2 LTS (GNU/Linux 3.13.0-61-generic x86_64)
* Documentation: https://help.ubuntu.com/
System information as of Tue Nov 15 10:54:00 CST 2016
System load: 0.0 Processes: 83
Usage of /: 4.6% of 97.66GB Users logged in: 0
Memory usage: 18% IP address for eth0: 192.168.1.132
Swap usage: 0%
Graph this data and manage this system at:
https://landscape.canonical.com/
148 packages can be updated.
73 updates are security updates.
*** System restart required ***
Last login: Tue Nov 15 10:54:03 2016 from master
hadoop@slave01:~$ ###说明已登录到slave01节点
hadoop@slave01:~$ exit
logout
Connection to slave01 closed.
hadoop@master:~$ ###退回到master节点
由master节点向其它节点传输文件可以采用scp命令,scp命令格式如下:
scp [-r]源文件 username@hostname:目标路径
以下示例的功能为:把hadoop用户当前目录下文件test.txt 传输到slave01节点,登录slave01节点的用户为hadoop,目标路径为/home/hadoop/data(因/home/hadoop是hadoop用户的主目录,故可用波浪号(~)表示)。
hadoop@master:~$ scp test.txt hadoop@slave01:~/data/
test.txt 100% 12 0.0KB/s 00:00
hadoop@master:~$
【课后练习】
一、在目录homework1130/20161130**(这个表示各人学号,每个人的学号不一样)
1、创建2个子目录
一级子目录名称(课程):linux
二级子目录名称(第几次练习):01
最后通过pwd命令应该看到如下格式:
~/homework1130/20161130**/linux/01
2、修改linux目前权限,是其它人只有读(r)的权限,自己和所属组有读写执行权限。
二、在linux目录下,新建一个shell脚本,脚本功能为:
1、定义两个变量,其中一个为你的姓名全拼,并在屏幕上显示;另一个变量传给一个 子shell脚本
2、调用一个shell,并在屏幕上显示该变量,同时把执行子shell的错误日志输出到另一 个文件。
三、编写一个脚本,实现安装linux、mysql、python的导航菜单,菜单可以单选或多选。
四、编写一个shell脚本,脚本中第一个函数,往该函数传入2个整数,输出它们的最大值。
五、查找服务器上含mysql字符串的目录及文件前10条导入到一个文件中,错误信息除外。
六、编写一个脚本,用ls命令及管道技术,把用户主目录下的所有文件(目录不需要)名称导入一个文件中,然后删除导出文件的前2行记录后导入到另一个文件中。
七、操作数据库,编写一个shell脚本,连接数据库testdb,然后创建一个表t_你的姓名全拼,该表至少包含3个字段,如id 为整数,name为varchar类型,birthday 为日期型,然后插入几条记录,最后捕获操作数据库的状态,如果成功,则在屏幕上打印成功字样;否则,打印失败字样。
八、编写一个脚本,然后通过crontab每天23点20分钟启动,并把运行脚本的错误日志输出到一个日志文件中。


