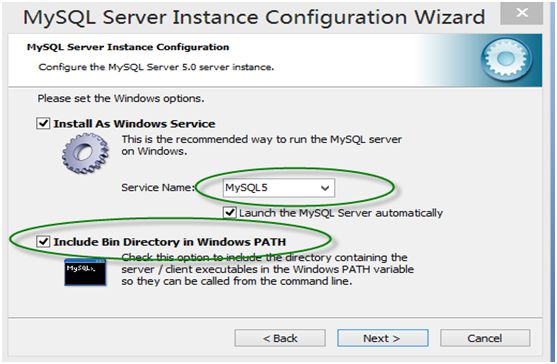
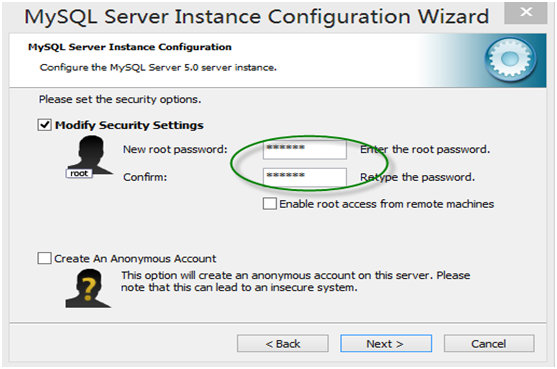
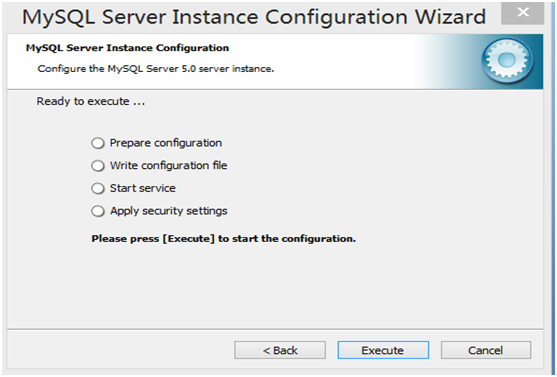
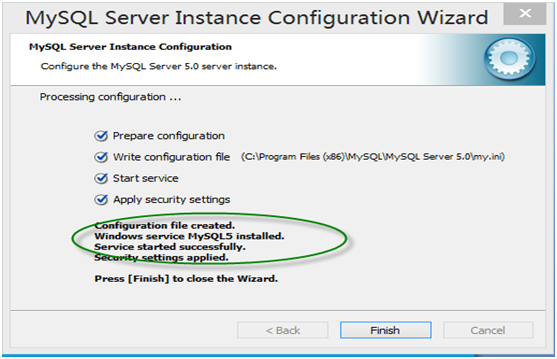
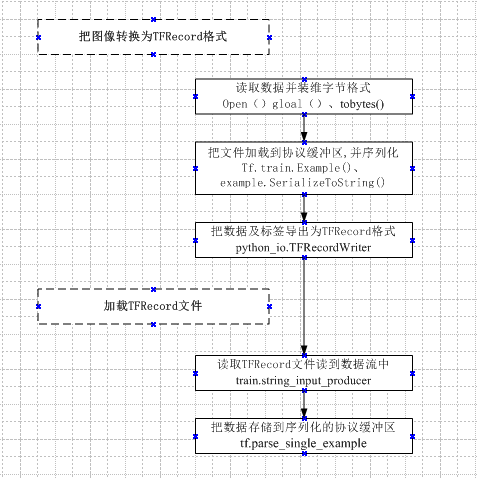
第3章 Python基础
3.1 Python简介
前面我们介绍了Linux操作系统、MySQL数据库。Linux作为大数据平台的基石,其重要性,在这里就不说了;MySQL数据库或推广为其他数据库(实际上其他数据库,如Oracle、DB2、SQL server等)作为存储和管理数据系统,在企业中已运行几十年(当然还将将继续使用下去,在事物处理方面尤其独特优势)积累大量各行各业的数据,这些数据是大数据重要来源。平台有了,数据有了,接下来要做的就是处理和分析这些数据,而Python恰恰是解决这类问题的高手之一,可以毫不夸张的说,Python将把你带进一个数据处理、数据分析的五彩缤纷世界!Python将助你达到一个新境界!
3.1.1 Python概述
Python是做啥用的? 为啥要学Python?在数据处理、数据分析、机器学习等方面除了Python还有其他一个工具,如R,MATLAB等,我们为啥选择Python?1、它开源,2,它易学,3,它强大,4,它与时俱进,它和大数据计算平台SPark的结合,可为强强联合,优势互补、相得益彰!Spark后面我们会重点介绍。
3.1.2 Python简介
Python是一种动态的高级解释性编程语言,简单易学,可读性高,功能强大,目前已广泛用于学校、企业、金融机构等。Python支持面向对象、模块和函数式编程,可以在windows、linux、Unix等操作系统上运行。它有如下主要特征:
开源:
由荷兰人Guido van Rossum在1989开发的,1991发行第一个正式版本,Python开发的里程碑:
1991年发行Python0.9.0;
1994年发行Python1.0;
2000年发行Python2.0;
2008年发行Python2.6;
2010年发行Python2.7;
2008年发行Python3.0;
2010年发行Python3.3;
2014年发行Python3.4.
从2008年开发有两版本在同时使用,而且这两个版本的代码不是100%兼容的,目前大部分实际使用的一般是Python2.6或Python2.7版本编写。
跨平台;
Python支持常用的操作系统,如Windows、Linux、Unix和Mac OS,既可在集群,也可运行在一些小设备上。
面向对象
Python支持面向对象、命令式、函数或过程式编程。
动态性
Python与JavaScript、PHP、Perl等语言类似,无需预先声明,直接赋值即可。
缩进感知
Python和大部分编程语言不同,它没有分号、begin、end等标记,使用缩进标记代码块、逻辑块,代替圆括号、方括号或分号等。
多用途
目前Python已广泛应用于web开发、数据库、图像处理、自然语言处理、网络、操作系统扩展等大型应用程序,也用于高级数据分析、图形处理等领域。
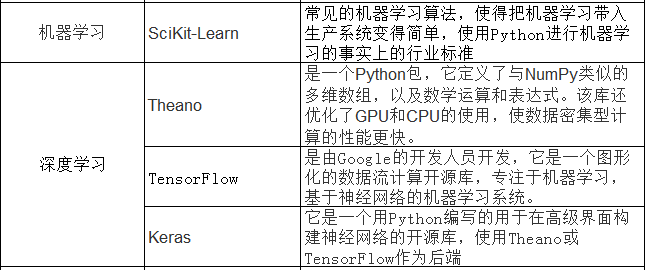
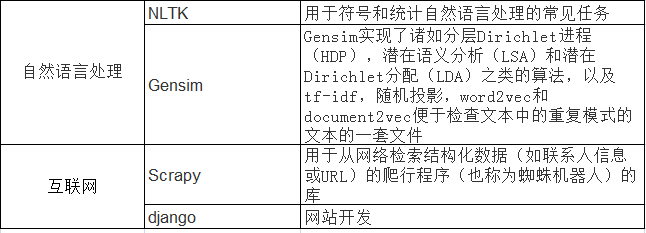
3.1.3 Python重要库

3.1.4 安装配置
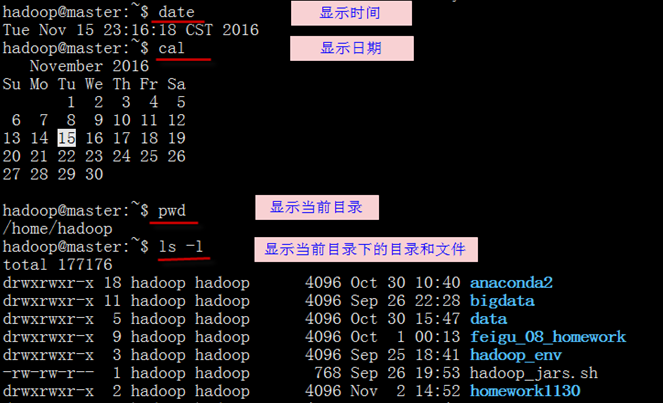
上一节介绍的这些库可以用python的安装管理包Anaconda轻松搞定,Anaconda有Linux、windows平台的,这里以2系列的包为例,其它版本安装类似。在Linux下安装,先下载管理包Anaconda2-4.0.0-Linux-x86_64.sh,这是2系列的安装包,3系列的包类似为Anaconda3-4.3.1-Linux-x86_64,然后在Linux命令行下运行:bash Anaconda2-4.0.0-Linux-x86_64.sh,然后按缺省步骤即可,如果要安装其他库,如scipy,只要运行conda install scipy即可。
Python安装完成后,在命令运行python后,启动交互式Python解释器:
其中>>>为提示符,说明已进入python环境,用户可在后面输入python命令、变量等。
Python解释器通过一次运行一条语句。
>>> 2+3
5
>>> print "hello world!"
hello world!
>>> a=10
>>> a
10
退出Python解释器,在提示符下输入quit() 或 Ctrl-D即可。
当然我们也可用IPython,IPython是一种加强的交互式Python解释器,它更加方便、功能更强大、更神奇,它已经成为Python科学计算界的标准配置。启动Ipython,只要在命令行输入ipython。
在IPython我们可以进行计算、编程、运行脚本(用%run 脚本)、copy脚本(%paste)、测试脚本、可视化数据等,甚至可以运行shell命令,当然Tab补全功能、回看历史命令等它都有,方便快捷,功能强大,退出IPython解释器,在命令行输入quit或exit或Ctrl+D。后面我们以IPython为主。
3.2 常量与变量
3.2.1 语言特点
Python语言一个最大特点就是代码缩进与冒号,这是其他任何语言所没有的,这个约束既带来了Python程序的高可读性,也带来了一些其他声音。
Python通过空格或制表符来表示代码之间的层次关系或逻辑关系,而且通过空格缩进是其语法之一,必须严格遵守,否则可能报错或逻辑错误。它不像其它语言如Java、C++、SQL等,这些语句通过花括号或BEGIN...END等关键字来界定代码间的层次关系、开始结束等。
下面我们通过一个实例来进一步了解Python这个特点。
In [1]: a=10
In [2]: if a==10:
...: print("a is ",a) ###缩进4格(IPython在冒号后自动缩4个空格)
...: else:
...: print("a is ",a) ###缩进4格
...: a=a+10 ###缩进4格
...: print("a is ",a)
...:###以下为运行结果
('a is ', 10)
('a is ', 10)
########################################
a=10
a=input()
if a==10:
print("a is ",a) ###缩进4格(IPython在冒号后自动缩4个空格)
else:
print("a is ",a) ###缩进4格
a=a+10 ###缩进4格
print("a is ",a)
【几点说明】
1、冒号(:) 表示一段缩进代码的开始,其后的所有代码都必须缩进相同的量(否则将报错),直到代码块结束。
2、缩进量建议用4个空格,这也是IPython在冒号后自动缩进的空格数,不建议使用Tab制表符。
3、代码缩进量不同,可能结果也会不同。
4、通过冒号和缩进,也同时可少写很多关键字(如then,if,end if之类)。
如果我们把a=a+10语句放在与if语句同一级,运算结果将不同,具体请看下例:
In [8]: a=10
In [9]: if a==10:
...: print("a is ",a)
...: else:
...: print("a is ",a)
...: a=a+10 ###该句于if语句处于相一级,影响a的结果
...: print("a is ",a)
...: ###运行结果
('a is ', 10)
('a is ', 20)
以上代码我们也可以保存为py文件,然后在IPython直接执行运行该文件,非常方便。
In [11]: !cat mytest.py
a=10
if a==10:
print("a is ",a)
else:
print("a is ",a)
a=a+10
print("a is ",a)
In [12]: %run mytest.py ##运行该脚本或import mytest
('a is ', 10)
('a is ', 10)
为了使该脚本有更好的移植性,可在第一行加上一句#!/usr/bin/python
运行.py文件时,python自动创建相应的.pyc文件,如下图,.pyc文件包含目标代码(编译后的代码),它是一种python专用的语言,以计算机能够高效运行的方式表示python源代码。这种代码无法阅读,故我们可以不管这个文件。
python程序是使用名为虚拟机的特殊软件运行的。这个软件模拟计算机,是专为运行在python上而设计的,这让很多.pyc文件无需做任何修改就能在不同的计算机上系统上运行。
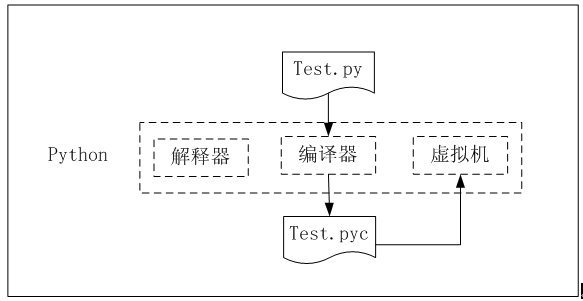
类似于shell脚本中的一行。然后,我们可以在命令行运行该该脚本,无需在显式使用Python或IPython解释器。如下例:
feigu@slave001:~$ cat mytest.py
#!/usr/bin/python
a=10
if a==10:
print("a is ",a)
else:
print("a is ",a)
a=a+10
print("a is ",a)
feigu@slave001:~$ python mytest.py ###在命令行运行下,通过python运行该脚本
('a is ', 10)
('a is ', 10)
3.2.2 注释
备注或注释,采用井号(#),注释多行,可以在每行前加#,或前后分别用三个单引号’’’,
如果注释中含中文,一般需要在python文件的最前面加上如下注释:
#-*- coding: utf-8 -*-
python3系列无需这句,因python3缺省字符集就是utf8。
说起这个注释符(#),我们应该不陌生了,shell中的注释也是#,SQL中也可使用。
#!/usr/bin/python
#-*- coding: utf-8 -*-
a=10
###if 判断语句
if a==10:
print("a is ",a)
else:
print("a is ",a)
a=a+10
print("a is ",a)
3.2.3模块导入
模块导入跟我们有啥关系?为什么要进行模块导入?学过Java的朋友,可能不会感到陌生,但对没有接触过Java,Python等新手来说,有这样的疑问,正常,能提出这样的疑问朋友,不错。
模块可用看成是一些对象或函数的集合。前面我们介绍了Python很强大,它确实很强大,他有成千上万的模块可用,不过绝大部分模块都处于“休眠状态”,如果我们要使用这些模块,需要通过import 模块或from 模块 from 函数等方式将它们"激活"。
用import 导入模块,引用模块中的函数时,还需要使用模块.函数的方式,如果你直接用其函数,不行带上模块这个“累赘”,可用采用from 模块 import 函数的方式,以下通过实例进一步说明如何使用以下两种导入方式的异同。
import 模块
from 模块 import 函数
In [1]: 1+2
Out[1]: 3
In [2]: max(1,2) ##这些常用函数启动python时就已“激活”
Out[2]: 2
In [3]: sqrt(4) ###使用这个平方根函数,报错,它所在模块没导入
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in ()
----> 1 sqrt(4)
NameError: name 'sqrt' is not defined
In [4]: import math ###平方根函数在math模块中,导入该模块
In [5]: math.sqrt(4) ###模块.函数,可用使用
Out[5]: 2.0
In [6]: sqrt(4) ###想直接用函数,报错
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in ()
----> 1 sqrt(4)
NameError: name 'sqrt' is not defined
In [7]: from math import * ###把模块及函数都导入
In [8]: sqrt(4) ###这下简单多了
Out[8]: 2.0
3.2.4变量与常量
在讲shell时,我们介绍了变量,shell中的变量拿来就可用,无需声明它是哪种数据类型,非常简单,Python也“继承”了这个优点,无需声明它是哪种数据类型,不像Java、c++等用一个变量还有先说明它哪种数据类型,否则还不让你用。好东西大家喜欢,scala也沿用了这一优点。
不声明数据类型,并不意味着Python就不需要数据类型,只是它更智能一点,它根据其值来推导。
变量的赋值可以一次一个变量、一次多个变量。
In [9]: a=2
In [10]: type(a)
Out[10]: int
In [11]: b="python"
In [12]: type(b)
Out[12]: str
In [13]: a+b
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in ()
----> 1 a+b
TypeError: unsupported operand type(s) for +: 'int' and 'str'
In [14]c=range(1,11)
In [15] d=xrange(1,11)
for i in d:
....:print i
###或[i for i in d]
【说明】
xrange 用法与 range 完全相同,所不同的是生成的不是一个list对象,而是一个生成器。要生成很大的数字序列的时候,用xrange会比range性能优很多,因为不需要一上来就开辟一块很大的内存空间。
python虽然无需声明变量类型,但它还是区分数据类型的,而且变量的引用无需像shell中变量一样要加上$,它可直接引用。
常量比较好理解,就是一些不变的量,如1,a等。
3.2.5变量如何赋值
变量赋值,通过赋值运算符=,把右边的值赋给左边的变量,具体如下:

应用变量时,需要初始化,否则将报错。
In [18]: v1=2+v0
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in ()
----> 1 v1=2+v0
NameError: name 'v0' is not defined
In [19]: v0=10 ###初始化
In [20]: v1=2+v0
In [21]: v1
Out[21]: 12
3.2.6多重赋值
python中,可以同时各多个变量赋值:
In [22]: x=10;y=20 ##一次给多个变量赋值
In [23]: a1,a2,a3=1,2,'python' ##一次给多个变量赋值
In [24]: a1,a2,a3
Out[24]: (1, 2, 'python')
3.3 控制语句
控制语句包括条件判断语句、循环语句,控制语句根据条件表达式控制程序的流转。
本章主要介绍
if条件判断语句
for循环语句
while循环语句
contnue及break语句
3.3.1if判断语句
if语句是一种最常用的条件判断语句,用于判断一个条件,如果成立,则执行紧跟其后的代码块,其语法格式为:
if (表达式):
代码块
if a>0:
print 'a 是正数'
if a>0 and b>0:
print 'a和b都是正数'
if语句也可以有多个分支,如if ...else,if ...elif ... else等
a=10
if a>0:
print "a 为整数"
elif a==0:
print "a 为零"
else:
print "a 为负数"
3.3.2 代码块和缩进
对于Python而言代码缩进是一种语法,Python没有像其他语言一样采用{}或者begin...end分隔代码块,而是采用代码缩进和冒号来区分代码之间的层次。缩进的空白数量是可变的,但是在一个模块中所有代码块语句必须包含相同的缩进空白数量,这个必须严格执行,否则将作为语法错误。

有时候代码采用合理的缩进但是缩进的情况不同,代码的执行结果也不同。有相同的缩进的代码表示这些代码属于同一代码块。例如:
# -*- coding: UTF-8 -*-
if 1>0:
print("Hello girl!")
else:
print("Hello boy!")
print("end")
print("=========华丽的分割线===========")
if True:
print("Hello girl!")
else:
print("Hello boy!")
print("end")
运行结果如下:
Hello girl!
end
=========华丽的分割线===========
Hello girl!
【思考】
以上两个print("end")的区别。
3.3.3for循环语句
for循环语句可用于遍历一个集合(如列表、元组等)或迭代器,依次访问集合或迭代器中的每项或每个元素。其语法格式为:
for 变量 in 集合:
代码块
a=range(10) #a=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
a=range(10)
for i in a:
i+=1
print i ###输出结果为10
当然for 代码块中增加一些控制循环的关键字如continue或break。continue使for循环提前进入下一个循环或下一个迭代(跳过代码块的剩余部分,直接进入下一轮循环),而break是立即跳出for循环。下面通过实例来进一步说明它们的使用。
In [105]: b=[10,20,a,30,a]
In [106]: for i in b:
.....: if i is a:
.....: continue
.....: print i*2
.....:
20
40
60
如果我们把上面的continue关键字换成break,看一下结果:
In [108]: for i in b:
.....: if i is a: ###遍历到第一个a,立即结束for循环语句
.....: break
.....: print i*2
.....:
20
40
3.3.4 while循环语句
while循环定义了一个条件和代码块,只要条件满足,则代码块将一直被执行。其语法格式为:
while 条件:
代码块
下面通过实例来具体说明while的使用。
In [115]: x=10
In [116]: while x左数
Out[20]: 'n'
In [21]: "python"[-1]
Out[21]: 'n'
In [22]: "python"[-3] ##从右往左算第3个元素
Out[22]: 'h'
3.4 序列的基本操作
元组、字符串、列表统称为序列,它们除都有索引外,还有一些共性的操作,如索引、切片、相加、乘法、属员等操作,此外,还有计算序列的长度、最大与最小元素等。
3.4.1 索引
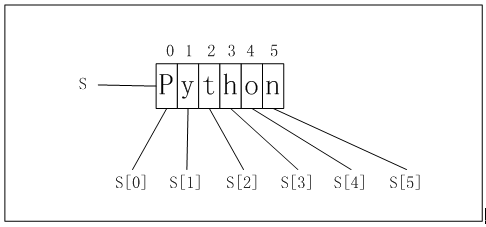
序列中的每个元素都分配一个序号,第一个元素的序号(或编号)为0,第二个元素的序号为1,以此类推,这些序号或编号就是索引。序列的元素可以通过其索引来访问。
In [16]: a="python"
In [17]: a[0]
Out[17]: 'p'
In [18]: a[1]
Out[18]: 'y'
In [19]: a[5]
Out[19]: 'n'
索引由左到右,索引由0开始,然后依次加1;索引也可以从右到左,索引从-1开始、依次减1。
In [20]: a[-1] ##负号表示从右->左数
Out[20]: 'n'
In [21]: "python"[-1]
Out[21]: 'n'
In [22]: "python"[-3] ##从右往左算第3个元素
Out[22]: 'h'
3.4.2 分片
可以通过索引来访问一个元素,是否可以通过索引一次访问多个元素呢?可以的,通过分片操作即可,分片三要素:
1、是索引运算符[]
2、分片的开始与结束位置,即start:stop,stop不在分片范围内。
3、开始与结束通过冒号(:)来分割,start索引所在元素包括在内,但stop索引所在元素不在分片范围内容。start或stop可以省略。具体请看以下实例
In [24]: b=[1,2,3,4,5]
In [25]: b[0:3] ##注意索引3对应元素不在分片范围内。
Out[25]: [1, 2, 3]
In [26]: b[2:] ##查看第3个开始及以后所有元素
Out[26]: [3, 4, 5]
In [27]: b[:] ##表示所有索引
Out[27]: [1, 2, 3, 4, 5]
In [28]: b[-1:]
Out[28]: [5]
In [29]: b[-3:]
Out[29]: [3, 4, 5]
如果只想选择偶数或奇数或选择其他步长,能否实现呢?如果能,又该如何实现呢?请看下例:
In [30]: b[::2] ###第二个冒号后的表示步长
Out[30]: [1, 3, 5]
In [31]: b[0:3:2] ###分片并取步长
Out[31]: [1, 3]
步长不能为零,但是否可以负,大家可尝试一下。
3.4.3 相加
我们知道数字可以相加,字符串也可相加,但数字和字符不能相加。序列是否可以相加呢?如果能相加,又有何限制呢?
可以相加,相加的条件和通常的数字或字符串相加一样,不同类型的不能相加。如元组不能和列表、字符串相加,列表不能和元组、字符串相加,尽管他们都是序列。只要两种相同类型的才能相加。
In [10]: b1=[6,7,8,9,10]
In [11]: b+b1
Out[11]: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
In [12]: b2=['a','b']
In [13]: b+b2
Out[13]: [1, 2, 3, 4, 5, 'a', 'b']
In [14]: a+b ##不同类型不能相加,a是字符串,b是列表。
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in ()
----> 1 a+b
TypeError: cannot concatenate 'str' and 'list' objects
3.4.4 乘法
这里的乘法指用一个数字n乘以一个序列生成一个新的序列,新的序列重复原来序列的n次。以下通过实例进一步说明。
In [19]: a*2
Out[19]: 'pythonpython'
In [20]: b*2
Out[20]: [1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
In [21]: c=(1,2,3)
In [22]: c*3
Out[22]: (1, 2, 3, 1, 2, 3, 1, 2, 3)
3.4.5 最大(小)值及长度
如果我们想知道一个序列的最大或最小值或这个序列的长度,这个长度指序列中元素的个数,尤其这个序列比较长或元素很多时,我们该如何求你?是否有现成的函数?我们知道MySQL里有现成或内置的函数。
Python提供了这方面的函数,如max、min、len等,这些函数是Python的内置函数。或Python自带的函数,我们直接使用即可。以下通过实例来进一步说明这些函数的使用。
In [23]: a
Out[23]: 'python'
In [24]: b
Out[24]: [1, 2, 3, 4, 5]
In [25]: max(b)
Out[25]: 5
In [26]: max(a)
Out[26]: 'y'
In [27]: len(a)
Out[27]: 6
In [28]: len(b)
Out[28]: 5
In [29]: e=[1,2,4,[3,4]] ##这里[3,4]是e的一个元素,故元素个数为4
In [30]: len(e)
Out[30]: 4
3.4.6 排序
对序列进行排序也是一件很平常的事,给序列排序可以sorted(序列)函数,缺省为升序,返回结果为新的有序列表。使用sorted函数不改变原序列的次序。
In [18]: sorted((1,4,5))
Out[18]: [1, 4, 5]
In [19]: sorted("spark")
Out[19]: ['a', 'k', 'p', 'r', 's']
In [20]: sorted((1,5,4,2))
Out[20]: [1, 2, 4, 5]
In [21]: sorted([4,7,2,5])
Out[21]: [2, 4, 5, 7]
In [23]: sorted([4,7,2,5],reverse=True) ##把reverse置为True将使用降序
Out[23]: [7, 5, 4, 2]
In [32]: p1=[7,4,9,6]
In [33]: sorted(p1) ##生成新的列表
Out[33]: [4, 6, 7, 9]
In [34]: p1 ###不会改变原序列的元素的次序
Out[34]: [7, 4, 9, 6]
sorted函数更详细使用可以通过help(sorted)来查询。
3.4.7 元组
上节介绍了序列一些共性方面的内容,如索引、分片等。元组(tuples)是Python中一种常见的数据结构,且不能修改或称为不可变序列,故除了序列常用操作外,没有太多其他操作。以下主要介绍元组的几种创建方法。
In [33]: t1=1,2,4,8 ##用逗号分割一些值,自动创建元组
In [34]: t1
Out[34]: (1, 2, 4, 8)
In [35]: t2="python","spark" ##用逗号分割一些值,自动创建元组
In [36]: t2
Out[36]: ('python', 'spark')
In [37]: t3=() ##元组可以没有值
In [38]: t3
Out[38]: ()
In [39]: t4=(1)
In [40]: t4 ##从结果来看,(1)不是元组,元组应该是使用圆括号
Out[40]: 1
In [41]: t5=(1,) ##如果元组只有一个元素,需要添加一个逗号
In [42]: t5
Out[42]: (1,)
In [43]: t6=tuple([1,2,3,4]) ###tuple函数(序列)生成元组
In [44]: t6
Out[44]: (1, 2, 3, 4)
In [45]: t7=tuple("SparkSQL")
In [46]: t7
Out[46]: ('S', 'p', 'a', 'r', 'k', 'S', 'Q', 'L')
In [47]: t8=tuple(2,3,4) ###tuple的参数要是序列,显然2,3,4没被认为是序列
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in ()
----> 1 t8=tuple(2,3,4)
TypeError: tuple() takes at most 1 argument (3 given)
In [48]: t9=tuple((2,3,4))
In [49]: t9
Out[49]: (2, 3, 4)
3.4.8 列表
列表为可修改序列,或称为可变序列,故列表上的操作相对比较丰富。这也是列表区别于元组、字符串的主要特点。以下对各种操作进行介绍。
3.4.8.1 列表的创建
列表通常用方括号"[]"或list(序列)函数进行定义,以下通过实例来说明。
In [7]: l1=[2,5,6,9]
In [8]: l1
Out[8]: [2, 5, 6, 9]
In [9]: l2=list("sparksql") ##
In [10]: l2
Out[10]: ['s', 'p', 'a', 'r', 'k', 's', 'q', 'l']
In [11]: l3=list((2,3,6,9))
In [12]: l3
Out[12]: [2, 3, 6, 9]
In [13]: l4=list([3,4,5])
In [14]: l4
Out[14]: [3, 4, 5]
3.4.8.2 添加或移除元素
既然列表是可变序列,这就意味着我们可以对其增删改,修改列表的方法比较多,甚至同一一种操作就有几种实现方法,各种实现方法的场景不同,效率也可能不同。
通过append方法,可以将元素添加到末尾,而用insert可以插入到指定位置,insert比较灵活但计算量比较大。
In [1]: lista=['python','R','hadoop','spark']
In [2]: lista.append('sparkml') ###在末尾添加一个元素
In [3]: lista
Out[3]: ['python', 'R', 'hadoop', 'spark', 'sparkml']
In [4]: lista.insert(3,'hdfs') ##在索引为3的位置上插入hdfs
In [5]: lista
Out[5]: ['python', 'R', 'hadoop', 'hdfs', 'spark', 'sparkml']
insert的逆运算为pop,它可以在指定位置移除元素,remove是按值删除数据,它仅删除第一个匹配的元素。
In [6]: listb=[2,3,1,2,7,5]
In [7]: listb.pop(2) ###这个2是指索引
Out[7]: 1
In [8]: listb
Out[8]: [2, 3, 2, 7, 5]
In [9]: listb.remove(2) ##这个2不是索引,是指元素2,只删除第一个2
In [10]: listb
Out[10]: [3, 2, 7, 5]
判断一个元素是否在列表中,可以用in这个关键字或运算符。
In [11]: 'hdfs'in lista
Out[11]: True
In [12]: 'sparkR'in lista
Out[12]: False
按索引查询比按值查询快很多,在列表中如此,但在后续我们将介绍的字典中,按值查询效率将比列表高很多,字典后面将介绍。
3.4.8.4 排序
对列表进行排序可以sort方法或sorted方法,sort实现就地排序,即改变原列表元素的次序,不生成新的列表;使用sorted排序,原列表元素次序不变,而是生成新的列表。此外sorted可用于可迭代序列,可迭代序列这个概念后面将介绍。
In [19]: listd=[3,5,2,1]
In [20]: listd.sort()
In [21]: listd ##列表的次序发生改变
Out[21]: [1, 2, 3, 5]
In [24]: liste=['red','blue','yellow','gree']
In [25]: listf=sorted(liste)
In [26]: listf
Out[26]: ['blue', 'gree', 'red', 'yellow']
In [27]: liste ##原列表次序未变
Out[27]: ['red', 'blue', 'yellow', 'gree']
数据库排序时通常指明用哪个字段或降序还是升序,在列表中是否可以呢?如果能,如何实现?当然可以,这就是接下来介绍的内容。sort或sorted两个重要参数key和reverse,key就就相当于指定排序的字段,这里key参数是函数,这个函数作用于列表中每个元素,reverse参数为False或True,False为默认的升序,True为降序。以下为具体使用实例。
In [1]: liste=['red','blue','yellow','gree']
In [2]: liste.sort(key=len,reverse=True) ##根据元素长度进行排序
In [3]: liste
Out[3]: ['yellow', 'blue', 'gree', 'red']
In [5]: sorted(liste,key=len) ##排序方式缺省为升序
Out[5]: ['red', 'blue', 'gree', 'yellow']
3.4.9 字符串
字符串是除数字外最重要的数据类型,字符串无处不在。字符串是一种聚合数据结构,我们可以使用索引和切片的方法。
3.4.9.1 字符串索引
字符串索引从0开始(这和我们使用尺子刻度从0开始一样),依次为1,2,,,到len(str)-1等等,当然也可以从右到左,此时,索引从-1开始,-2,-3,,,到-len(str)。如下图:
字符串负索引:

n [23]: s="Python"
In [24]: s[0]
Out[24]: 'P'
In [25]: s[5]
Out[25]: 'n'
In [26]: s[-1]
Out[26]: 'n'
In [27]: s[:2] ##字符串切片
Out[27]: 'Py'
In [28]: s[2:5] ##字符串切片
Out[28]: 'tho'
3.4.9.2 字符串函数
字符串的方法比较多,这里介绍几种常用方法,此外,简单介绍字符串格式化问题。
lower、upper实现字符大小写的转换;replace替换字符;strip去除两侧空格;split将字符串分割成列;字符串的正则表达式(re)。以下通过实例具体说明这些方法或函数的使用。
In [6]: 'Python'.lower
Out[6]:
In [7]: 'Python'.lower()
Out[7]: 'python'
In [8]: 'Python'.upper()
Out[8]: 'PYTHON'
In [9]: 'Python|MySQL|Hadoop|Spark'.split('|')
Out[9]: ['Python', 'MySQL', 'Hadoop', 'Spark']
In [10]: ' Scala '.strip()
Out[10]: 'Scala'
In [11]: 'Python'.replace('P','IP')
Out[11]: 'IPython'
3.4.10 字典
我们知道汉语字典、新华字典、英汉字典等,用这些字典可以根据一个字来查找有关这个字的使用方法,如读音、词语、成语、详细含义等等。这个可通过目录或索引来查找内容有点不同。
这里介绍的Python字典,本质上有点像上面讲的一些字典,就是通过关键字来查询其对应值,相当于Java中的HashMap。
字典(dict)是由多个键(key)和对应的值(value)构成的键-值对组成(键-值对又称为项),每个键和它对应的值之间用冒号(:)隔开,项之间用逗号(,)隔开,而整个字典放在在一个大括号{}里,键是唯一的,但值可以不唯一。字典格式,如:d={'liuhai':26 ,'gaofeng':30}
3.4.10.1 创建字典
字典的创建有多种方法,以下介绍几种常用方法:
1、使用大括号并用冒号分隔键和值,键-值对用逗号分隔。
2、使用dict()函数
3、使用已有的序列。
以下通过一些实例来说明如何创建字典:
In [1]: d1={'a':10 ,'b':20,'c':10}
In [2]: d1
Out[2]: {'a': 10, 'b': 20, 'c': 10}
In [3]: d2={} ##创建空字典
In [4]: d2
Out[4]: {}
In [5]: item=[('zhang',20),('liu',30)]
In [6]: d3=dict(item) ###使用dict函数创建字典
In [7]: d3
Out[7]: {'liu': 30, 'zhang': 20}
In [8]: item1=['red','blue','yellow']
In [9]: item2=[100,200,300]
In [10]: d4=dict(zip(item1,item2))
In [11]: d4
Out[11]: {'blue': 200, 'red': 100, 'yellow': 300}
3.4.10.2 字典的基本操作
len(d) 返回字典d中键-值对或项的个数;
d[k] 返回键k对应的值v;
d.get(k,default_value) 返回字典d中键k对应的值v,没有对应的键k,将返回缺省值(缺省值可自定义);
k in d 判断k是否在字典d中
以下通过一些具体实例来说明;
In [13]: d4
Out[13]: {'blue': 200, 'red': 100, 'yellow': 300}
In [14]: len(d4)
Out[14]: 3
In [15]: d4['red']
Out[15]: 100
In [16]: d4['gree'] ##如果没有对应的键,则报错
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
in ()
----> 1 d4['gree']
KeyError: 'gree'
In [17]: d4.get('red')
Out[17]: 100
In [18]: d4.get('gree',0) ##如果没有对应的键,则不报错,返回缺省值
Out[18]: 0
In [34]: 'red'in d4 ##键red是否在字典d4中,在则返回True
Out[34]: True
In [35]: 'gree' not in d4
Out[35]: True
d[k]=v 把键k对应的值修改为v
del d[k] 删除键为k所在的项;
d.pop(k) 删除键为k所在的项;
d.keys() 返回字典d所有的键;
d.values() 返回字典d所有的值。
以下通过一些具体实例来说明;
In [19]: d4['yellow']=200 ##把键为yellow的值修改为200
In [20]: d4
Out[20]: {'blue': 200, 'red': 100, 'yellow': 200}
In [21]: del d4['yellow'] ##删除键为yellow的项或一个键-值对
In [22]: d4
Out[22]: {'blue': 200, 'red': 100}
In [23]: d4.pop('blue')
Out[23]: 200
In [24]: d4
Out[24]: {'red': 100}
In [26]: d5
Out[26]: {'blue': 200, 'red': 100, 'yellow': 200}
In [27]: d5.keys()
Out[27]: ['blue', 'yellow', 'red']
In [28]: d5.values()
Out[28]: [200, 200, 100]
3.4.11 集合
集合(set)是由唯一元素组成的无序集,集合的创建方式常用的有两种,set函数或用大括号。
In [30]: set([2,3,8,2,6,1]) ##set有去重的功能
Out[30]: {1, 2, 3, 6, 8}
In [31]: {3,3,3,8,6,6}
Out[31]: {3, 6, 8}
集合的基本操作
a&b a与b的交集
a|b a与b的并集
a-b a与b的差
a.issubset(b) 判断a是否为b的子集
a.issuperset(b) 判断a是否为b的超集
以下为具体实例
In [36]: a={1,2,3,4}
In [37]: b={3,4,5,6,7,9}
In [38]: a&b
Out[38]: {3, 4}
In [39]: a|b
Out[39]: {1, 2, 3, 4, 5, 6, 7, 9}
In [40]: a-b
Out[40]: {1, 2}
In [41]: c=a|b
In [42]: c
Out[42]: {1, 2, 3, 4, 5, 6, 7, 9}
In [43]: a.issubset(c)
Out[43]: True
In [44]: c.issuperset(a)
Out[44]: True
3.5 pandas简介
3.5.1 pandas简介
“Pandas经过几个版本的更新,目前已经成为数据清洗、处理和分析的不二选择。”
前面我们介绍了NumPy,它提供了数据处理功能,但需要写很多命令,是否有更加便捷、直观、有效的方法?Pandas就是为此而诞生的。Pandas提供了众多更高级、更直观的数据处理功能,尤其是它的DataFrame数据结构,将给你全新的体验,可以用处理数据库表或电子表格的方式来处理分析数据。
Pandas基于NumPy构建的,它提供的结构或工具,让以NumPy为中心的数据处理、数据分析变得更加简单和高效。
Pandas中两个最常用的对象是Series和DataFrame。使用pandas前,需导入以下内容:
In [1]: import numpy as np
In [2]: from pandas import Series,DataFrame
In [3]: import pandas as pd
3.5.2 pandas数据结构
Pandas主要采用Series和DataFrame两种数据结构。Series是一种类似一维数据的数据结构,由数据(values)及索引(indexs)组成,而DataFrame是一个表格型的数据结构,它有一组有序列,每列的数据可以为不同类型(NumPy数据组中数据要求为相同类型),它既有行索引,也有列索引。
3.5.3 Series
上章节我们介绍了多维数组(ndarray),当然,它也包括一维数组,Series类似一维数组,为啥还要介绍Series呢?或Series有哪些特点?
Series一个最大特点就是可以使用标签索引,序列及ndarray也有索引,但都是位置索引或整数索引,这种索引有很多局限性,如根据某个有意义标签找对应值?切片时采用类似[2:3]的方法,只能取索引为2这个元素等等,无法精确定位。
Series的标签索引(它位置索引自然保留)使用起来就方便多了,而且定位也更精确,不会产生歧义。举例说明。
In [1]: import numpy as np
In [2]: from pandas import Series,DataFrame
In [3]: import pandas as pd
In [4]: s1=Series([1,3,6,-1,2,8])
In [5]: s1
Out[5]:
0 1
1 3
2 6
3 -1
4 2
5 8
dtype: int64
In [6]: s1.values
Out[6]: array([ 1, 3, 6, -1, 2, 8])
In [7]: s1.index
Out[7]: RangeIndex(start=0, stop=6, step=1)
###创建Series时,自定义索引或称为标签索引
In [8]: s2=Series([1,3,6,-1,2,8],index=['a','c','d','e','b','g'])
In [9]: s2
Out[9]:
a 1
c 3
d 6
e -1
b 2
g 8
dtype: int64
In [10]: s2['a'] ###根据标签索引找对应值
Out[10]: 1
In [11]: s2[['a','e']] ###根据标签索引找对应值
Out[11]:
a 1
e -1
dtype: int64
当然,Series除了标签索引外,还有其它很多优点,如运算的简洁:
In [15]: s2[s2>1]
Out[15]:
c 3
d 6
b 2
g 8
dtype: int64
In [16]: s2*10
Out[16]:
a 10
c 30
d 60
e -10
b 20
g 80
dtype: int64
3.5.4 DataFrame
DataFrame除了索引有位置索引也有标签索引,而且其数据组织方式与MySQL的表极为相似,除了形式相似,很多操作也类似,这就给我们操作DataFrame带来极大方便。这些是DataFrame特色的一小部分,它还有比数据库表更强大的功能,如强大统计、可视化等等。
DataFrame几要素:index、columns、values等,columns就像数据库表的列表,index是索引,当然values就是值了。
In [18]:
####自动生成一个3行4列的DataFrame,并定义其索引(如果不指定,缺省为整数索引)####及列名
d1=DataFrame(np.arange(12).reshape((3,4)),index=['a','b','c'],columns=['a1','a2','a3','a4'])
In [19]: d1
Out[19]:
a1 a2 a3 a4
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
In [20]: d1.index ##显示索引
Out[20]: Index([u'a', u'b', u'c'], dtype='object')
In [21]: d1.columns ##显示列名
Out[21]: Index([u'a1', u'a2', u'a3', u'a4'], dtype='object')
In [22]: d1.values ##显示值
Out[22]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
3.5.4.1 生成DataFrame
生成DataFrame有很多,比较常用的有导入等长列表、字典、numpy数组、数据文件等。
In [33]: data={'name':['zhanghua','liuting','gaofei','hedong'],'age':[40,45,50,46],'addr':['jianxi','pudong','beijing','xian']}
In [34]: d2=DataFrame(data)
In [35]: d2
Out[35]:
addr age name
0 jianxi 40 zhanghua
1 pudong 45 liuting
2 beijing 50 gaofei
3 xian 46 hedong
In [36]: d3=DataFrame(data,columns=['name','age','addr'],index=['a','b','c','d'])
In [37]: d3
Out[37]:
name age addr
a zhanghua 40 jianxi
b liuting 45 pudong
c gaofei 50 beijing
d hedong 46 xian
3.5.4.2 获取数据
获取DataFrame结构中数据可以采用obj[]操作、查询、obj.ix[]等命令。
In [8]: data={'name':['zhanghua','liuting','gaofei','hedong'],'age':[40,45,50,46],'addr':['jianxi','pudong','beijing','xian']}
###把字典数据转换为DataFrame,并指定索引
In [9]: d3=DataFrame(data,columns=['name','age','addr'],index=['a','b','c','d'])
In [10]: d3
Out[10]:
name age addr
a zhanghua 40 jianxi
b liuting 45 pudong
c gaofei 50 beijing
d hedong 46 xian
In [11]: d3[['name','age']] ##选择列
Out[11]:
name age
a zhanghua 40
b liuting 45
c gaofei 50
d hedong 46
In [12]: d3['a':'c'] ##选择行
Out[12]:
name age addr
a zhanghua 40 jianxi
b liuting 45 pudong
c gaofei 50 beijing
In [13]: d3[1:3] ##选择行(利用位置索引)
Out[13]:
name age addr
b liuting 45 pudong
c gaofei 50 beijing
In [14]: d3[d3['age']>40] ###使用过滤条件
Out[14]:
name age addr
b liuting 45 pudong
c gaofei 50 beijing
d hedong 46 xian
obj.ix[indexs,[columns]]可以根据列或索引同时进行过滤,具体请看下例:
In [16]: d3.ix[['a','c'],['name','age']]
Out[16]:
name age
a zhanghua 40
c gaofei 50
In [17]: d3.ix['a':'c',['name','age']]
Out[17]:
name age
a zhanghua 40
b liuting 45
c gaofei 50
In [18]: d3.ix[0:3,['name','age']]
Out[18]:
name age
a zhanghua 40
b liuting 45
c gaofei 50
pandas除了可通过ix确定行列位置外,还可以通loc、iloc来定位或查找需要的数据,这三者主要区别可参考如下示例
import pandas as pd
data = [[1,2,3],[4,5,6]]
index = [0,1]
columns=['a','b','c']
df = pd.DataFrame(data=data, index=index, columns=columns)
#1. loc——通过行标签索引行数据
df.loc[1]
'''''''
a 4
b 5
c 6
'''
#1.2 loc[‘d’]表示索引的是第’d’行(index 是字符)
import pandas as pd
data = [[1,2,3],[4,5,6]]
index = ['d','e']
columns=['a','b','c']
df = pd.DataFrame(data=data, index=index, columns=columns)
df.loc['d']
'''''''
a 1
b 2
c 3
'''
#1.3 如果想索引列数据,像这样做会报错
print df.loc['a']
'''''''
KeyError: 'the label [a] is not in the [index]'
'''
#1.4 loc可以获取多行数据
print df.loc['d':]
'''''''
a b c
d 1 2 3
e 4 5 6
'''
#1.5 loc扩展——索引某行某列
print df.loc['d',['b','c']]
'''''''
b 2
c 3
'''
#1.6 loc扩展——索引某列
print df.loc[:,['c']]
'''''''
c
d 3
e 6
'''
##当然获取某列数据最直接的方式是df.[列标签],但是当列标签未知时可以通过这种方式##获取列数据。
#需要注意的是,dataframe的索引[1:3]是包含1,2,3的,与平时的不同。
#2. iloc——通过行号获取行数据
#2.1 想要获取哪一行就输入该行数字
df.iloc[1]
'''''''
a 4
b 5
c 6
'''
#2.2 通过行标签索引会报错
print df.iloc['a']
'''''''
TypeError: cannot do label indexing on <class 'pandas.core.index.Index'> with these indexers [a] of <type 'str'>
'''
#2.3 同样通过行号可以索引多行
df.iloc[0:]
'''''''
a b c
d 1 2 3
e 4 5 6
'''
#2.4 iloc索引列数据
df.iloc[:,[1]]
'''''''
b
d 2
e 5
'''
#3. ix——结合前两种的混合索引
#3.1 通过行号索引
df.ix[1]
'''''''
a 4
b 5
c 6
'''
#3.2 通过行标签索引
df.ix['e']
'''''''
a 4
b 5
c 6
'''
3.5.4.3 修改数据
我们可以像操作数据库表一样操作DataFrame,删除数据,插入数据、修改字段名、索引名、修改数据等,以下通过一些实例来说明。
In [9]: data={'name':['zhanghua','liuting','gaofei','hedong'],'age':[40,45,50,46],'addr':['jianxi','pudong','beijing','xian']}
In [10]: d3=DataFrame(data,columns=['name','age','addr'],index=['a','b','c','d'])
In [11]: d3
Out[11]:
name age addr
a zhanghua 40 jianxi
b liuting 45 pudong
c gaofei 50 beijing
d hedong 46 xian
In [12]: d3.drop('d',axis=0) ###删除行,如果欲删除列,使axis=1即可
Out[12]:
name age addr
a zhanghua 40 jianxi
b liuting 45 pudong
c gaofei 50 beijing
In [13]: d3 ###从副本中删除,原数据没有被删除
Out[13]:
name age addr
a zhanghua 40 jianxi
b liuting 45 pudong
c gaofei 50 beijing
d hedong 46 xian
###添加一行,注意需要ignore_index=True,否则会报错
In [14]: d3.append({'name':'wangkuan','age':38,'addr':'henan'},ignore_index=True)
Out[14]:
name age addr
0 zhanghua 40 jianxi
1 liuting 45 pudong
2 gaofei 50 beijing
3 hedong 46 xian
4 wangkuan 38 henan
In [15]: d3 ###原数据未变
Out[15]:
name age addr
a zhanghua 40 jianxi
b liuting 45 pudong
c gaofei 50 beijing
d hedong 46 xian
###添加一行,并创建一个新DataFrame
In [16]: d4=d3.append({'name':'wangkuan','age':38,'addr':'henan'},ignore_index=True)
In [17]: d4
Out[17]:
name age addr
0 zhanghua 40 jianxi
1 liuting 45 pudong
2 gaofei 50 beijing
3 hedong 46 xian
4 wangkuan 38 henan
In [18]: d4.index=['a','b','c','d','e'] ###修改d4的索引
In [19]: d4
Out[19]:
name age addr
a zhanghua 40 jianxi
b liuting 45 pudong
c gaofei 50 beijing
d hedong 46 xian
e wangkuan 38 henan
In [20]: d4.ix['e','age']=39 ###修改索引为e列名为age的值
In [21]: d4
Out[21]:
name age addr
a zhanghua 40 jianxi
b liuting 45 pudong
c gaofei 50 beijing
d hedong 46 xian
e wangkuan 39 henan
3.5.4.4 汇总统计
Pandas有一组常用的统计方法,可以根据不同轴方向进行统计,当然也可按不同的列或行进行统计,非常方便。
常用的统计方法有:
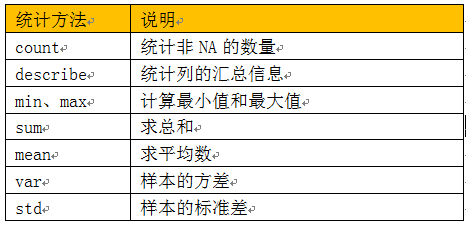
(表7-1 Pandas统计方法)
以下通过实例来说明这些方法的使用
from pandas import DataFrame
import numpy as np
import pandas as pd
inputfile = '/home/hadoop/data/stud_score.csv'
data = pd.read_csv(inputfile)
#其他参数,
###header=None 表示无标题,此时缺省列名为整数;如果设为0,表示第0行为标题
###names,encoding,skiprows等
#读取excel文件,可用read_excel
In [7]: df=DataFrame(data)
In [8]: df.head(3) ###显示前3行
Out[8]:
stud_code sub_code sub_nmae sub_tech sub_score stat_date
0 2.015101e+09 10101.0 数学分析 NaN 90.0 NaN
1 2.015101e+09 10102.0 高等代数 NaN 88.0 NaN
2 2.015101e+09 10103.0 大学物理 NaN 67.0 NaN
In [9]: df.count()
Out[9]:
stud_code 121
sub_code 121
sub_nmae 121
sub_tech 0
sub_score 121
stat_date 0
dtype: int64
In [10]: df['sub_score'].describe() ##汇总学生各科成绩
Out[10]:
count 121.000000
mean 78.561983
std 12.338215
min 48.000000
25% 69.000000
50% 80.000000
75% 89.000000
max 98.000000
Name: sub_score, dtype: float64
In [11]: df['sub_score'].std() ##求学生成绩的标准差
Out[11]: 12.338214729032906
注:DataFrame数据结构的函数或方法有很多,大家可以通过df.[Tab键]方式查看,具体命令的使用方法,如df.count(),可以在Ipython命令行下输入:?df.count() 查看具体使用,退出帮助界面,按q即可。
3.6 函数
3.6.1函数的定义
说到函数大家应该不陌生,函数从初中就开始了,函数的作用我们也大都有所了解,利用函数极大提高了我们工作的效率,一个个函数就像软件行业的一块块芯片,插上接口就可使用。所以函数很好的解决程序的移植性、重用性、复制性、易用性和可靠性等等。
Python的函数同样有这些特性,Python有很多内置函数,如max、min、abs等,甚至还有很多内置机器算法或模型、机器学习库等,如sklearn库中的支持向量机、keras中的神经网络等等,这里就不展开说了,这章主要介绍自定义函数的创建及使用。
Python函数定义的格式:
def 函数名(参数1,参数2,...):
函数体
return 表达式或变量
【说明】
1、参数可分为位置参数、关键参数或默认参数或可选参数;
2、返回值可以是表达式、变量,甚至没有return语句,此时返回None。
Python函数的调用:
函数名(参数1,参数2,....)
下面是定义、调用函数的一些实例
In [1]: def myfun(x,y): ###定义函数
...: return x+y
...:
In [2]: myfun(2,6) ###调用函数
Out[2]: 8
In [5]: def myfun01(x,y,z=1): ##定义一个含缺省参数(z)的函数
...: if z==1:
...: return x+y
...: else:
...: return (x+y)*z
...:
In [6]: myfun01(2,6) ###调用函数时,没有输入z参数,则取其缺省值
Out[6]: 8
In [7]: myfun01(2,6,10) ###调用函数时,输入z参数,则取其输入值
Out[7]: 80
3.6.2 函数的返回值
我们在介绍Shell的函数时,发现其局限很多,通过return只能返回[0,255]间的某个整数,如果要返回其它值,需要通过echo的方式,然后再通过运行该函数来获取返回值,大大限制了函数的表现力。Python的函数返回值,是否也是这样呢?
Python的函数强大多了,也方便多了!从输入参数可以看出它不同一般的很多优点,其返回值同样有很多不一样的地方。
不但可以返回多个值,还可有多种形式,举例如下:
In [8]: def myfun02():
...: a=1
...: b=3
...: c=8
...: return a,b,c
...: myfun02()
...:
Out[8]: (1, 3, 8) ###返回多个值,而且很方便
In [9]: x,y,z=myfun02()
In [10]: print x,y,z ###轻松返回多个值,而且轻松获取返回值
1 3 8
3.6.3 变量的作用域
前面我们提到模块及函数,一个模块中可能有很多函数和变量,当然在一个函数中也可能涉及很多变量或嵌套函数等等问题,如此,变量的活动范围(或作用范围)就是一个重要问题。改变变量作用范围的有def、class、lambda等定义函数或类的语句,循环语句不影响变量的作用域。
我们先看一个示例:
#testlocalvar.py
import math
def dist(x,y):
a,b=0,0
d2=(x-a)**2+(y-b)**2
d=math.sqrt(d2)
return d
dist(3,4) ###调用函数
#print(a) ###应用局部变量a将报错
局部变量只是在其所属的函数内部使用,在函数外,不能访问函数的局部变量,函数结束时,其局部变量将被自动删除。
在一个模块中除了函数内部的变量外,一般也有函数之外的变量,这部分变量可以被其他函数访问,但能否被被其他函数修改呢?我们来看一个示例:
#testglobalvar.py
name='python'
def select_tool():
print('select the tool is:'+name)
def select_other(a):
name=a
select_other('java')
def select_tool()
运行结果是:
select the tool is:python
而不是:
select the tool is:java
上例中之所以结果非我们期待的java,究其原因,就是函数select_other中name是一个局部变量,该局部变量,执行函数select_other()立即被删除,如要出现我们期望的结果,该如何设计?
方法之一,可以在select_other函数中声明name为全局变量,如下例:
#testglobalvar.py
name='python'
def select_tool():
print('select the tool is:'+name)
def select_other(a):
global name
name=a
select_other('java')
def select_tool()
运行结果是:
select the tool is:java
3.6.4 函数也是对象
在Python中,有一句话非常有代表性:“万物皆对象”,一个字符是对象,一个数字也是对象,更不用说数据结构、模块、函数了,何以见得?既然是对象,那应该就有属性或方法,难道一个字符也有属性和方法?下面看几个实例。
In [18]: a='b'
In [19]: a. ###a.然后按Tab键,就可以看到a具有的方法或属性
a.capitalize a.endswith a.isalnum a.istitle a.lstrip a.rjust a.splitlines a.translate
a.center a.expandtabs a.isalpha a.isupper a.partition a.rpartition a.startswith a.upper
a.count a.find a.isdigit a.join a.replace a.rsplit a.strip a.zfill
a.decode a.format a.islower a.ljust a.rfind a.rstrip a.swapcase
a.encode a.index a.isspace a.lower a.rindex a.split a.title
In [19]: b=2
In [20]: b. ###b.然后按Tab键,就可以看到b具有的方法或属性
b.bit_length b.conjugate b.denominator b.imag b.numerator b.real
这是Python非常神奇、非常强大的特点之一。后续大家将看到更多有趣的地方。
万物皆对象有啥好处?好处很多,第一,保证了python对象的一致性;第二,增强python的灵活性;第三,提供了使用的方便性(如通过.Tab就可方便查看对象的属性和方法等),等等。下面介绍一个实际应用,既然函数也是对象,当然就可以把它作为其它对象来对待,如字符或数字或参数之类。函数可以作为一个参数,传给另一个函数;函数也可作为函数的返回值。
In [11]: def sum1(x,y):
....: return x+y
....: def max1(a,f): ##f就是一个函数参数
....: return max(a,f) ##函数max作为返回值
....: max1(10,sum1(20,30))
....:
Out[11]: 50
它的好处,现在你可能感觉不到,不过scala已经在大面积使用这一方法。
3.7 数据可视化
无论是大数据、还是小数据、也不管通过统计还是挖掘或机器学习,人们最终想看到的数据,越直观越好,所以这个就涉及到一个数据的可视化问题,而python或pandas的数据可视化功能很强大,可画的种类多,也非常便捷,这是一般数据库软件和开发工具目前所欠缺的。以下我们通过两个实例来说明利用python的matplotlib或pandas实现数据的可视化。
下例利用matplotlib实现数据的可视化
In [1]: %paste
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] ###显示中文
plt.rcParams['axes.unicode_minus']=False ##防止坐标轴上的-号变为方块
x = np.linspace(0, 10, 100)
y = np.sin(x)
y1 = np.cos(x)
##绘制一个图,长为10,宽为6(默认值是每个单位80像素)
plt.figure(figsize=(10,6))
###在图列中自动显示$间内容
plt.plot(x,y,label="$sin(x)$",color="red",linewidth=2)
plt.plot(x,y1,"b--",label="$cos(x^2)$") ###b(blue),--线形
plt.xlabel(u"X值") ##X坐标名称,u表示unicode编码
plt.ylabel(u"Y值")
plt.title(u"三角函数图像") ##t图名称
plt.ylim(-1.2,1.2) ##y上的max、min值
plt.legend() ##显示图例
plt.savefig('fig01.png') ##保持到当前目录
plt.show()
以下是运行结果:
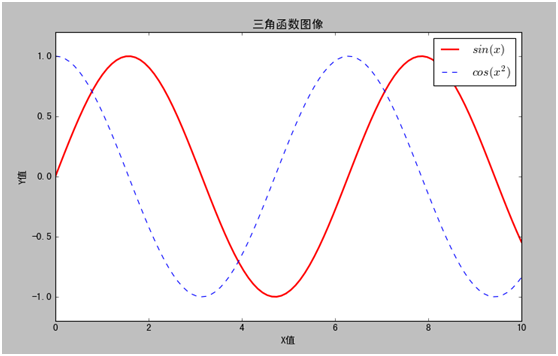
(图 9-2 matplotlib数据可视化)
3.8 数据地图显示
下例通过matplotlib及mpl_toolkits.basemap实现地图数据的可视化。
# -*- coding: utf-8 -*-
from mpl_toolkits.basemap import Basemap
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif']=['SimHei']
#============================================# read data
names = []
pops = []
lats = []
lons = []
countries = []
for line in file("/home/hadoop/data/bigdata_map/china_city_jobs_stat.csv"):
info = line.split(',')
names.append(info[0])
pops.append(float(info[1]))
lat = float(info[2][:-1])
if info[2][-1] == 'S': lat = -lat
lats.append(lat)
lon = float(info[3][:-1])
if info[3][-1] == 'W': lon = -lon + 360.0
lons.append(lon)
country = info[4]
countries.append(country)
#============================================
#lat0 = 35;lon0 = 120;change = 25;
lat0 = 30;lon0 = 120;change = 26;
lllat=lat0-change; urlat=lat0+change;
lllon=lon0-change; urlon=lon0+change;
map = Basemap(ax=None,projection='stere',lon_0=(urlon + lllon) / 2,lat_0=(urlat + lllat) / 2,llcrnrlat=lllat, urcrnrlat=urlat,llcrnrlon=lllon,urcrnrlon=urlon,resolution='f')
# draw coastlines, country boundaries, fill continents.
map.drawcoastlines(linewidth=0.25)
map.drawcountries(linewidth=0.25)
# draw the edge of the map projection region (the projection limb)
map.drawmapboundary(fill_color='#689CD2')
# draw lat/lon grid lines every 30 degrees.
#map.drawmeridians(np.arange(0,360,30))
#map.drawparallels(np.arange(-90,90,30))
# Fill continent wit a different color
map.fillcontinents(color='green',lake_color='#689CD2',zorder=0)
# compute native map projection coordinates of lat/lon grid.
shapefilepath = '/home/hadoop/data/bigdata_map/map/map'
map.readshapefile(shapefilepath,'city') #添加街道数据
x, y = map(lons, lats)
max_pop = max(pops)
# Plot each city in a loop.
# Set some parameters
size_factor = 80.0
y_offset = 15.0
rotation = 30
for i,j,k,name in zip(x,y,pops,names):
size = size_factor*k/max_pop
cs = map.scatter(i,j,s=size,marker='o',color='yellow')
plt.text(i,j+y_offset,name,rotation=rotation,fontsize=1)
plt.title(u'中国大数据主要城市需求分布图(2017-03-17)')
plt.show()
运行结果如下图:
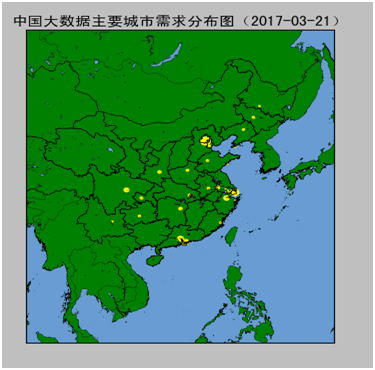
(图9-3 中国大数据需求分别图)
3.9 图像处理
3.9.1PIL常用操作
这节我们将介绍如何Python库PIL(Python Imaging Library,图像处理类库)提供的图像处理功能,以及大量有用的基本图像操作,比如图像缩放、裁剪、旋转、颜色转换等。
利用 PIL 中的函数,我们可以从大多数图像格式的文件中读取数据,然后写入最常见的图像格式文件中。PIL 中最重要的模块为 Image。要读取一幅图像,可以使用:
import PIL
from PIL importImage
im = Image.open('timg.png')
im.show() ###显示图片

【说明】如果ubuntu系统无法显示图像,看是否已安装imagemagick,如果没有,通过sudo apt-get install imagemagick来安装。
上述代码的返回值 im 是一个 PIL 图像对象
图像的颜色转换可以使用 convert() 方法来实现。要读取一幅图像,并将其转换成灰度图像,只需要加上 convert('L'),如下所示:
from PIL importImage
im1=Image.open('timg.png').convert('L')
im1.show()

使用 PIL 可以很方便地创建图像的缩略图。thumbnail() 方法接受一个元组参数(该参数指定生成缩略图的大小),然后将图像转换成符合元组参数指定大小的缩略图。例如,创建最长边为 128 像素的缩略图,可以使用下列命令:
im.format, im.size, im.mode ##查看图像信息
('JPEG', (128, 128), 'RGB')
im.thumbnail((128,128)) ###设置目前大小
im.save("tenna_bak.gif","GIF") ###保存图片,并转换格式
如何图片剪辑?我们可以通过crop方法,先设定剪辑范围,然后使用crop方法即可:
box=(100,100,130,130) ##设置图片剪辑区
region=im.crop(box) ### region是一个新的图像对象
如何选择图像?我们可以通过
box=(100,100,130,130) ##设置图片剪辑区
如何旋转一个图片?我们可以通过函数rotate
im3=im.rotate(45)
im3.show()

如何实现图像的模糊处理?可以使用ImageFilter方法,具体请看如下代码:
from PIL import ImageFilter
im4 = im.filter(ImageFilter.BLUR) ##模糊滤波,处理之后的图像会整体变得模糊
im4.show()

3.9.2随机生成验证码
PIL的ImageDraw提供了一系列绘图方法,以下利用该方法,随机生成字母验证码图
from PIL import Image,ImageDraw, ImageFont, ImageFilter
import random
# 随机字母:
def rndChar():
return chr(random.randint(65, 90))
# 随机颜色1:
def rndColor():
return (random.randint(64, 255), random.randint(64, 255), random.randint(64, 255))
# 随机颜色2:
def rndColor2():
return (random.randint(32, 127), random.randint(32, 127), random.randint(32, 127))
# 240 x 60:
width = 60 * 4
height = 60
image = Image.new('RGB', (width, height), (255, 255, 255))
# 创建Font对象:
font1= ImageFont.truetype('/home/hadoop/anaconda2/lib/python2.7/site-packages/matplotlib/mpl-data/fonts/ttf/Arial.ttf', 36)
# 创建Draw对象:
draw = ImageDraw.Draw(image)
# 填充每个像素:
for x in range(width):
for y in range(height):
draw.point((x, y), fill=rndColor())
# 输出文字:
for t in range(4):
draw.text((60 * t + 10, 10), rndChar(), font=font1, fill=rndColor2())
# 模糊:
image = image.filter(ImageFilter.BLUR)
#显示图形
image.show()

3.9.3图像数组表示
NumPy是非常有名的 Python 科学计算工具包,其中包含了大量有用的思想,比如数组对象(用来表示向量、矩阵、图像等)以及线性代数函数。NumPy 中的数组对象几乎贯穿用于本书的所有例子中 1 数组对象可以帮助你实现数组中重要的操作,比如矩阵乘积、转置、解方程系统、向量乘积和归一化,这为图像变形、对变化进行建模、图分类、图像聚类等提供了基础。PyLab 实际上包含 NumPy 的一些内容,如数组类型。
先前的例子中,当载入图像时,我们通过调用 array() 方法将图像转换成 NumPy 的数组对象,但当时并没有进行详细介绍。NumPy 中的数组对象是多维的,可以用来表示向量、矩阵和图像。一个数组对象很像一个列表(或者是列表的列表),但是数组中所有的元素必须具有相同的数据类型。除非创建数组对象时指定数据类型,否则数据类型会按照数据的类型自动确定。
对于图像数据,下面的例子阐述了这一点:
im = array(Image.open('empire.jpg'))
print im.shape, im.dtype
结果显示如下:
(220, 142, 3) uint8
im = array(Image.open('empire.jpg').convert('L'),'f')
print im.shape, im.dtype
结果显示如下:
(220, 142) float32
每行的第一个元组表示图像数组的大小(行、列、颜色通道),紧接着的字符串表示数组元素的数据类型。因为图像通常被编码成无符号八位整数(uint8),所以在第一种情况下,载入图像并将其转换到数组中,数组的数据类型为“uint8”。在第二种情况下,对图像进行灰度化处理,并且在创建数组时使用额外的参数“f”;该参数将数据类型转换为浮点型。关于更多数据类型选项,可以参考图书 [24]。注意,由于灰度图像没有颜色信息,所以在形状元组中,它只有两个数值。
数组中的元素可以使用下标访问。位于坐标 i、j,以及颜色通道 k 的像素值可以像下面这样访问:
value = im[i,j,k]
多个数组元素可以使用数组切片方式访问。切片方式返回的是以指定间隔下标访问该数组的元素值。下面是有关灰度图像的一些例子:
im[i,:] = im[j,:] # 将第 j 行的数值赋值给第 i 行
im[:,i] = 100 # 将第 i 列的所有数值设为100
im[:100,:50].sum() # 计算前100 行、前 50 列所有数值的和
im[50:100,50:100] # 50~100 行,50~100 列(不包括第 100 行和第 100 列)
im[i].mean() # 第 i 行所有数值的平均值
im[:,-1] # 最后一列
im[-2,:] (or im[-2]) # 倒数第二行
注意,示例仅仅使用一个下标访问数组。如果仅使用一个下标,则该下标为行下标。注意,在最后几个例子中,负数切片表示从最后一个元素逆向计数。我们将会频繁地使用切片技术访问像素值,这也是一个很重要的思想。
3.10 操作MySQL数据库
人工智能最重要的动力就是数据,没有充分数据的人工智能是毫无意义的,数据越大人工智能将越聪明,所以数据是非常重要的。因此整合各种数据的能力也是各种开发工具非常重视的,Python在这方面功能很强大。这一章我们将介绍如何利用Python存取数据库中的数据。
目前企业数据大都存储在数据库中,如MySQL、Oracle、DB2等关系型数据库,这些数据库目前使用非常广泛,由于其独特优势,未来还将大量使用;但随着数据量、数据种类的不断增长,目前非关系型数据库也越来越普及了,如MongoDB、Redis、HBase等等,这些数据库有时又称为NoSQL型数据库。所有这些数据是目前大数据的主要源头,因此,如何使用抽取、整合、处理及分析这些数据是非常重要。
这章主要内容:
操作MySQL
Python使用MySQL非常简单,先导入python有关mysql的驱动模块,然后建立与数据库的连接即可。
以下通过实例来说明。
In [2]: import numpy as np
In [3]: import pandas as pd
In [4]: from pandas import DataFrame
In [5]: import MySQLdb
In [6]: conn= MySQLdb.connect(host='slave02',port=3306,user='feigu', passwd='feigu', db='testdb',charset='utf8')
In [7]: data= pd.read_sql('select * from stud_score', conn)
In [8]: df=DataFrame(data)
In [9]: df.count()
3.11 初学者最易犯的一些错误
Python 以其简单易懂的语法格式与其它语言形成鲜明对比,初学者遇到最多的问题就是不按照 Python 的规则来写,即便是有编程经验的程序员,也容易按照固有的思维和语法格式来写 Python 代码,以下小结一下初学者最易犯的几个错误,供大家参考。
注:以上代码都是基于 Python3 的,在 Python2 中即使是同样的代码出现的错误也不尽一样。
1、忘记冒号:
在 if、elif、else、for、while、class、def 语句后面忘记添加 “:”
spam=26
if spam > 20
print('Hello!')
报错:SyntaxError: invalid syntax
订正:
spam=26
if spam > 20:
print('Hello!')
2、误用 “=” 做等值比较
“=” 是赋值操作,而判断两个值是否相等是 “==”
if spam = 42:
print('Hello!')
报错:SyntaxError: invalid syntax
3、使用错误的缩进
Python用缩进区分代码块,常见的错误用法:
print('Hello!')
print('Happy new year!')
报错:IndentationError: unexpected indent
说明:同一个代码块中的每行代码都必须保持一致的缩进量
if spam == 42:
print('Hello!')
print('Howdy!')
报错:IndentationError: expected an indented block
说明:“:” 后面要使用缩进
4、变量没有定义
if age == 42:
print('Hello!')
报错:NameError: name 'age' is not defined
5、获取列表元素索引位置忘记调用 len 方法
通过索引位置获取元素的时候,忘记使用 len 函数获取列表的长度。
spam = ['cat', 'dog', 'mouse']
for i in range(spam):
print(spam[i])
报错:TypeError: 'list' object cannot be interpreted as an integer
订正:
spam = ['cat', 'dog', 'mouse']
for i in range(len(spam)):
print(spam[i])
cat
dog
mouse
可用更符合python风格的写法是用 enumerate
spam = ['cat', 'dog', 'mouse']
for i, item in enumerate(spam):
print(i, item)
0 cat
1 dog
2 mouse
6、修改字符串
字符串一个序列对象,支持用索引获取元素,但它和列表对象不同,字符串是不可变对象,不支持修改。
spam = 'I have a pet cat.'
spam[5] = 'r'
print(spam)
报错: in ()
1 spam = 'I have a pet cat.'
----> 2 spam[5] = 'r'
3 print(spam)
TypeError: 'str' object does not support item assignment
订正:
spam = 'I have a pet cat.'
spam = spam[:13] + 'r' + spam[14:]
print(spam)
I have a pet rat.
7、字符串与非字符串连接
num_eggs = 12
print('I have ' + num_eggs + ' eggs.')
报错:TypeError: must be str, not int
说明:字符串与非字符串连接时,必须把非字符串对象强制转换为字符串类型。
num_eggs = 12
print('I have ' + str(num_eggs) + ' eggs.')
I have 12 eggs.
或者使用字符串的格式化形式
num_eggs = 12
print('I have %s eggs.' % (num_eggs))
I have 12 eggs.
8、使用错误的索引位置
spam = ['cat', 'dog', 'mouse']
print(spam[3])
报错:
使用错误的索引位置1 spam = ['cat', 'dog', 'mouse']
----> 2 print(spam[3])
IndexError: list index out of range
说明:列表对象的索引是从0开始的,第3个元素应该是使用 spam[2] 访问。
9、字典中使用不存在的键
spam = {'cat': 'Zophie', 'dog': 'Basil', 'mouse': 'Whiskers'}
print('The name of my pet zebra is ' + spam['zebra'])
报错:KeyError: 'zebra'
说明:在字典对象中访问 key 可以使用 [],但是如果该 key 不存在,就会报错。
订正:正确的方式应该使用 get 方法,如果key 不存在,get 默认返回 None。
spam = {'cat': 'Zophie', 'dog': 'Basil', 'mouse': 'Whiskers'}
spam.get('zebra')
10、用关键字做变量名
报错:SyntaxError: invalid syntax
说明:在 Python 中不允许使用关键字作为变量名。Python3 一共有33个关键字。关键字有:
import keyword
print(keyword.kwlist)
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
11、函数中局部变量赋值前被使用
someVar = 42
def myFunction():
print(someVar)
someVar = 100
myFunction()
报错:UnboundLocalError: local variable 'someVar' referenced before assignment
说明:当函数中有一个与全局作用域中同名的变量时,它会按照 LEGB 的顺序查找该变量,如果在函数内部的局部作用域中也定义了一个同名的变量,那么就不再到外部作用域查找了。因此,在 myFunction 函数中 someVar 被定义了,所以 print(someVar) 就不再外面查找了,但是 print 的时候该变量还没赋值,所以出现了 UnboundLocalError
12、使用自增 “++” 自减 “--”
报错:SyntaxError: invalid syntax
说明:Python 中没有自增自减操作符,如果你是从C、Java转过来的话,你可要注意了。你可以使用 “+=” 来替代 “++”
spam = 0
spam += 1
print(spam)
1
13、错误地调用类中的方法
class Foo:
def method1():
print('m1')
def method2(self):
print("m2")
a = Foo()
a.method1()
报错:TypeError: method1() takes 0 positional arguments but 1 was given
说明:method1 是 Foo 类的一个成员方法,该方法不接受任何参数,调用 a.method1() 相当于调用 Foo.method1(a),但 method1 不接受任何参数,所以报错了。正确的调用方式应该是 Foo.method1()。
3.12 Python2.x与Python3.x版本的区别
3.12.1简介
Python3发布于2008年底,是一次重大的Python升级。Python3的有些改进不向Python2兼容,因此,Python2始终与Python3并行向前发展,不过,据Python官方说明,Python2.x将在2020年后停止维护,以后将以Python3.x为主。
3.12.2具体说明
print函数
在Python3中,print是函数式,而在Python2中,print是个语言结构,与if和for一样。以下几种情况,在Python2.7中是等价的。
print "ok"
print ("ok") #注意print后面有个空格
print("ok") #print()不能带有任何其它参数
对Python2.x中print函数,可以通过导入print_function ,即from __future__ import print_function,可以使Python2中print兼容Python3,如下例,在Python2中可运行如下语句:
from __future__ import print_function
print("fish", "panda", sep=',')
Unicode
Python 2 有 ASCII str() 类型,unicode() 是单独的,不是 byte 类型。
现在, 在 Python 3,我们最终有了 Unicode (utf-8) 字符串,以及一个字节类:byte 和 bytearrays。
由于 Python3.X 源码文件默认使用utf-8编码,这就使得以下代码是合法的。
在Python2.x中,需要添加u
a1="我喜欢Python"
a1
'\xe6\x88\x91\xe5\x96\x9c\xe6\xac\xa2Python'
a2=u"我喜欢Python"
a2
u'\u6211\u559c\u6b22Python'
在Python3.x
a1="我喜欢Python"
a1
'我喜欢Python'
除法运算
Python中的除法较其它语言显得非常高端,有套很复杂的规则。Python中的除法有两个运算符,/和//
首先来说/除法:
在python 2.x中/除法就跟我们熟悉的大多数语言,比如Java啊C啊差不多,整数相除的结果是一个整数,把小数部分完全忽略掉,浮点数除法会保留小数点的部分得到一个浮点数的结果。
在python 3.x中/除法不再这么做了,对于整数之间的相除,结果也会是浮点数。
在Python2.x中
1/2
结果为
0
1.0/2.0
结果为:
0.5
xrange
在 Python 2 中 xrange() 创建迭代对象的用法是非常流行的。比如: for 循环或者是列表/集合/字典推导式。
这个表现十分像生成器(比如。"惰性求值")。但是这个 xrange-iterable 是无穷的,意味着你可以无限遍历。
由于它的惰性求值,如果你不得仅仅不遍历它一次,xrange() 函数 比 range() 更快(比如 for 循环)。尽管如此,对比迭代一次,不建议你重复迭代多次,因为生成器每次都从头开始。
在 Python 3 中,range() 是像 xrange() 那样实现以至于一个专门的 xrange() 函数都不再存在(在 Python 3 中 xrange() 会抛出命名异常)。
不等运算符
Python 2.x中不等于有两种写法 != 和 <>
Python 3.x中去掉了<>, 只有!=一种写法,还好,我从来没有使用<>的习惯。
数据类型
1)Py3.X去除了long类型,现在只有一种整型——int,但它的行为就像2.X版本的long
2)新增了bytes类型,对应于2.X版本的八位串,定义一个bytes字面量的方法如下:
str对象和unicode对象可以使用.encode() (str -> unicode) or .decode() (unicode -> str)方法相互转化。
3.13 练习
一、编写程序计算1+2+3+....+100的结果。
二、对字符串'12345678',将逆序输出。
三、创建一个10*10的随机数组并查找最大最小值