1.背景说明
我们平时在网上、书上看到的有关深度学习的案例大多使用处理好、教规格的数据集,如MNIST, CIFAR10/100等数据集,这些数据集一般无需(或很少)做预处理,就看导入到模型中使用。但是很多情况下需要处理自己的数据集,这些数据集往往不规范,而且一般比较大。如何把自己的数据集转换成这些TensorFlow框架能够使用的数据形式至关重要,接下来将对TensorFlow2中官方推荐数据格式及预处理方法进行说明,小数据集处理方法很多,处理也比较方便,这里就不展开来说。这里主要介绍大中数据集,对大中数据集TensorFlow建议转换为TFRecord格式,使用TFRecord格式有哪些优势呢?
2.TFRecord的优势
正常情况下我们用于训练的文件夹内部往往会存着成千上万的图片或文本等文件,这些文件通常被散列存放。这种存储方式有一些缺点:
(1)占用磁盘空间;
(2)在一个个读取的时候会非常耗时;
(3)占用大量内存空间(有的大型数据不足以一次性加载)。
此时 TFRecord 格式的文件存储形式会很合理的帮我们存储数据。TFRecord 内部使用了 “Protocol Buffer” 二进制数据编码方案,它只占用一个内存块,只需要一次性加载一个二进制文件的方式即可,简单,快速,尤其对大型训练数据很友好。而且当我们的训练数据量比较大的时候,可以将数据分成多个 TFRecord 文件,来提高处理效率。
3.使用TFRecord的一般步骤
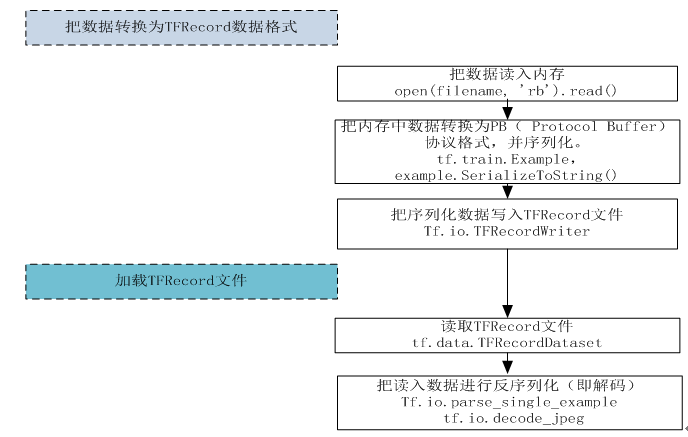
3.1 Exmple含义
freocrd的核心是其包含一系列的example,每个example可以认为是一条样本。example是tensorflow中的对象类型,用法是tf.train.example。
Example含义: 如下图,假设有样本 (example): (x,y) :输入x 和 输出y一起叫做样本。这里每个x是六维向量,每个y是一维向量。
(1)表征 (representation):x集合了代表个人的全部特征。
其中特征 (feature): x 中的某个维:如学历,年龄,职业。是某人的一个特点。
(2)标签 (label):y为输出。

对上表的数据的存储,通常我们把输入特征x与标签y分开进行保存。假设有100个样本,把所有输入存储在100x6的numpy矩阵中,把标签存储在100x1的向量中。
Example协议块格式:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
message Example { Features features = 1; }; message Features { map<string, Feature> feature = 1; }; message Feature { one of kind { BytesList bytes_list = 1; FloatList float_list = 2; Int64List int64_list = 3; } }; |
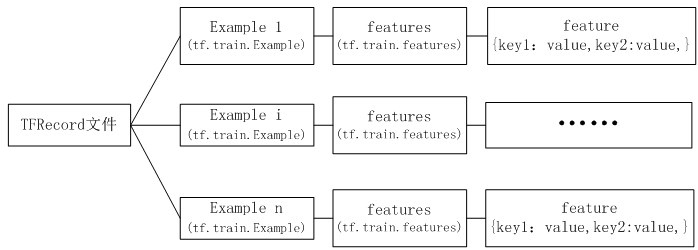
以TFRecord方式存储,输入和标签将以字典方式存放在一起,具体格式请参考下图。
3.2 TFRecord文件数据格式
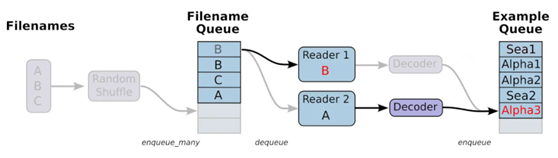
3.3 加载TFRecord文件流程
TFRecord做好了,可以通过tf.data来生成一个迭代器,每次调用都返回一个大小为batch_size的batch。读取TFRecord可以通过tensorflow两个个重要的函数实现如下图所示,分别是读取器(Reader): tf.data.TFRecordDataset和解码器(Decoder):tf.io.parse_single_example解析器。如下图:
4.代码实例
整个过程为:
(1)先把源数据(可以是文本、图像、音频、Embedding等,这里是小猫、小狗图片)导入内存(如NumPy)
(2)把内存数据转换为TFRecord格式数据
(3)读取TFRecord数据
(4)构建模型
(5)训练模型
4.1 导入数据
导入模块及数据,这里是windows环境,如果是linux环境,请修改路径格式。
数据集下载
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import tensorflow as tf import os data_dir = r"C:\Users\wumg\jupyter-ipynb\data\cat-dog" train_cat_dir = data_dir + '\\train\\cats\\' train_dog_dir = data_dir + "\\train\\dogs\\" train_tfrecord_file = data_dir + r"\train\train.tfrecords" test_cat_dir = data_dir + "\\test\\cats\\" test_dog_dir = data_dir + "\\test\\dogs\\" test_tfrecord_file = data_dir + r"\test\test.tfrecords" train_cat_filenames = [train_cat_dir + filename for filename in os.listdir(train_cat_dir)] train_dog_filenames = [train_dog_dir + filename for filename in os.listdir(train_dog_dir)] train_filenames = train_cat_filenames + train_dog_filenames train_labels = [0]*len(train_cat_filenames) + [1]*len(train_dog_filenames) test_cat_filenames = [test_cat_dir + filename for filename in os.listdir(test_cat_dir)] test_dog_filenames = [test_dog_dir + filename for filename in os.listdir(test_dog_dir)] test_filenames = test_cat_filenames + test_dog_filenames test_labels = [0]*len(test_cat_filenames) + [1]*len(test_dog_filenames) |
4.2 把数据转换为TFRecord格式
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
def encoder(filenames, labels, tfrecord_file): with tf.io.TFRecordWriter(tfrecord_file) as writer: for filename, label in zip(filenames, labels): image = open(filename, 'rb').read() # 建立feature字典,这里特征image,label都以向量方式存储 feature = { 'image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image])), 'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[label])) } # 通过字典创建example,example对象对label和image数据进行封装 example = tf.train.Example(features=tf.train.Features(feature=feature)) # 将example序列化并写入字典 writer.write(example.SerializeToString()) encoder(train_filenames, train_labels, train_tfrecord_file) encoder(test_filenames, test_labels, test_tfrecord_file) |
构建example的时候,这个tf.train.Feature()函数可以接收三种数据:
• bytes_list: 可以存储string 和byte两种数据类型。
• float_list: 可以存储float(float32)与double(float64) 两种数据类型。
• int64_list: 可以存储:bool, enum, int32, uint32, int64, uint64。
对于只有一个值(比如label)可以用float_list或int64_list,而像图片、视频、embedding这种列表型的数据,通常转化为bytes格式储存
4.3 从TFRecord读取数据
这里使用 tf.data.TFRecordDataset 类来读取 TFRecord 文件
使用 TFRecordDataset 对于标准化输入数据和优化性能十分有用。可以使用tf.io.parse_single_example函数对每个样本进行解析(tf.io.parse_example对批量样本进行解析)。 请注意,这里的 feature_description 是必需的,因为数据集使用计算图执行,并且需要这些描述来构建它们的形状和类型签名。
使用 tf.data.Dataset.map 方法可将函数应用于 Dataset 的每个元素。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
def decoder(tfrecord_file, is_train_dataset=None): #构建dataset dataset = tf.data.TFRecordDataset(tfrecord_file) #说明特征的描述属性,为解吗每个example使用 feature_discription = { 'image': tf.io.FixedLenFeature([], tf.string), 'label': tf.io.FixedLenFeature([], tf.int64) } def _parse_example(example_string): # 解码每一个example #将文件读入到队列中 feature_dic = tf.io.parse_single_example(example_string, feature_discription) feature_dic['image'] = tf.io.decode_jpeg(feature_dic['image']) #对图片进行resize feature_dic['image'] = tf.image.resize(feature_dic['image'], [256, 256])/255.0 #tf.image.random_flip_up_down(image).shape return feature_dic['image'], feature_dic['label'] batch_size = 4 if is_train_dataset is not None: #tf.data.experimental.AUTOTUNE#根据计算机性能进行运算速度的调整 dataset = dataset.map(_parse_example).shuffle(buffer_size=2000).batch(batch_size).prefetch(tf.data.experimental.AUTOTUNE) else: dataset = dataset.map(_parse_example) dataset = dataset.batch(batch_size) return dataset train_data = decoder(train_tfrecord_file, 1) test_data = decoder(test_tfrecord_file) |
显示图片
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import matplotlib.pyplot as plt %matplotlib inline #查看dataset中样本的具体信息 i=1 for image,lable in train_data: plt.subplot(1,2,i) plt.imshow(image[0].numpy()) i+=1 if i==3: break plt.show() |

4.4 构建模型
模型由两层卷积和两层全连接层构成。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
class CNNModel(tf.keras.models.Model): def __init__(self): super(CNNModel, self).__init__() self.conv1 = tf.keras.layers.Conv2D(12, 3, activation='relu') self.maxpool1 = tf.keras.layers.MaxPooling2D() self.conv2 = tf.keras.layers.Conv2D(12, 5, activation='relu') self.maxpool2 = tf.keras.layers.MaxPooling2D() self.flatten = tf.keras.layers.Flatten() self.d1 = tf.keras.layers.Dense(64, activation='relu') self.d2 = tf.keras.layers.Dense(2, activation='softmax') def call(self, inputs): x = self.conv1(inputs) x = self.maxpool1(x) x = self.conv2(x) x = self.maxpool2(x) x = self.flatten(x) x = self.d1(x) x = self.d2(x) return x |
4.5 训练模型
训练模型使用@tf.function装饰器将普通Python函数转换成对应的TensorFlow计算图构建代码。使用tf.GradientTape实现自动求导,使用TensorFlow2 autograph机制,该机制可以把动态图转换成静态图加速。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
def train_CNNModel(): model = CNNModel() loss_obj = tf.keras.losses.SparseCategoricalCrossentropy() optimizer = tf.keras.optimizers.Adam(0.001) train_acc = tf.keras.metrics.SparseCategoricalAccuracy(name='train_acc') test_acc = tf.keras.metrics.SparseCategoricalAccuracy(name='test_acc') @tf.function def train_step(images, labels): with tf.GradientTape() as tape: logits = model(images) loss = loss_obj(labels, logits) grads = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(grads, model.trainable_variables)) train_acc(labels, logits) @tf.function def test_step(images, labels): logits = model(images) test_acc(labels, logits) Epochs =10 for epoch in range(Epochs): train_acc.reset_states() test_acc.reset_states() for images, labels in train_data: train_step(images, labels) for images, labels in test_data: test_step(images, labels) tmp = 'Epoch {}, Acc {}, Test Acc {}' print(tmp.format(epoch + 1, train_acc.result() * 100, test_acc.result() * 100)) train_CNNModel() |
运行结果:
Epoch 1, Acc 50.98039627075195, Test Acc 57.5
Epoch 2, Acc 68.13725280761719, Test Acc 52.499996185302734
Epoch 3, Acc 80.39215850830078, Test Acc 47.5
Epoch 4, Acc 91.66667175292969, Test Acc 57.5
Epoch 5, Acc 93.13725280761719, Test Acc 57.5
Epoch 6, Acc 97.54901885986328, Test Acc 52.499996185302734
Epoch 7, Acc 100.0, Test Acc 52.499996185302734
Epoch 8, Acc 100.0, Test Acc 50.0
Epoch 9, Acc 100.0, Test Acc 50.0
Epoch 10, Acc 100.0, Test Acc 52.499996185302734
有兴趣的读者可以从以下几方面提升性能
5.利用数据增强方法提升性能
6.利用现代经典网络提升性能
7.利用数据迁移方法提升性能
8.结合Transformer技术提升性能