5.1极大似然估计
5.1.1概率与似然
在统计中,似然与概率是不同的概念。概率是已知参数,对结果可能性的预测。似然是已知结果,对参数是某个值的可能性预测。
对函数 ,其中x表示某一个具体的数据;
,其中x表示某一个具体的数据; 表示模型的参数。针对的情况,可分为两种如下两种情况:
表示模型的参数。针对的情况,可分为两种如下两种情况:
(1)已知确定的,x是变量,这个函数叫做概率函数(probability function),它描述对于不同的样本点x,其出现概率是多少。
(2)x是已知确定的,是变量,这个函数叫做似然函数(likelihood function), 它描述对于不同的模型参数,出现x这个样本点的概率是多少。
5.1.2极大似然估计核心思想
我们通常使用贝叶斯完成分类任务,不过为了求后验概率,如P(B|A),其前提条件比较苛刻,既要只要先经验概率,如P(A)、P(B),又要知道条件概率P(A|B),即似然函数。但在实际生活中要获取条件概率P(A|B)包含一个随机变量的全部信息,样本数据可能不多等原因,获取这个概率密度函数难度比较大。
为解决这一问题,人们又另辟蹊径。把估计完全未知的概率密度转化为假设概率密度或分布已知,仅参数需估计。这里就将概率密度估计问题转化为参数估计问题,为此,极大似然估计就诞生了,它是一种参数估计方法。当然了,概率密度函数的选取很重要,模型正确,在样本区域无穷时,我们会得到较准确的估计值,如果模型错了,估计出来的参数意义也不大。
极大似然估计的核心思想是什么呢?我们可用图5-1来说明: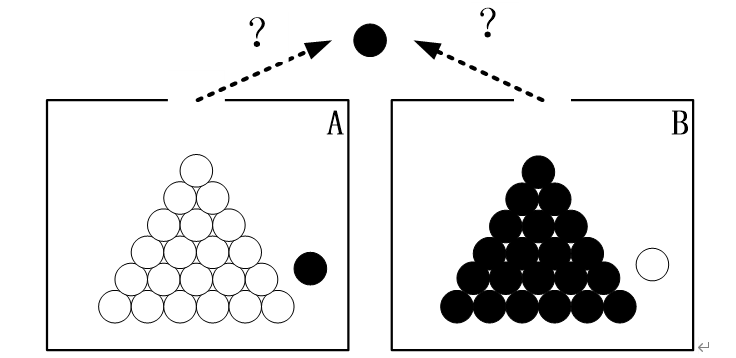
图5-1 极大似然的示意图
假设有两个外观完全相同的箱子A、B,其中A箱有99个白球,1个黑球;B箱有99个黑球,1个白球。一次实验需取出一球,结果取出的是黑球。
问:黑球从哪个箱子取出?
大多数人都会说,“黑球最有可能是从B箱取出。”,这个推断符合人们的经验。而“最有可能”就是“极大似然”之意,这种朴素的想法就称为“极大似然原理”。
极大似然估计的目的就是:利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
实际上,极大似然估计可以把它看作是一个反推。多数情况下我们是根据已知条件来推算结果,而极大似然估计是已经知道了结果(如已知样本数据),然后寻求使该结果出现的可能性最大的条件(如概率参数),以此作为估计值。
从上面这个简单实例,不难看出极大似然估计的是建立在极大似然原理的基础上的一个统计方法,是概率论在统计学中的应用。极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
以上文字的含义,如何用数学式子表示呢?
假设有一个样本集 ,其中n表示样本数,各样本
,其中n表示样本数,各样本 满足独立同分布。
满足独立同分布。
那么该分布的联合概率可表示为: ,它又称为相对于样本集
,它又称为相对于样本集 的参数θ的似然函数(linkehood function),参数可以是一个标量或向量。
的参数θ的似然函数(linkehood function),参数可以是一个标量或向量。

假设 为使出现该组样本的概率最大的参数值,即样本集的极大似然估计,则有:
为使出现该组样本的概率最大的参数值,即样本集的极大似然估计,则有:

为便于计算,一般采用两边取对数log来处理,用L(θ)表示似然函数,即

由此可得:

 为凸函数,如果同时可导,那么θ ̂就是下列方程的解:
为凸函数,如果同时可导,那么θ ̂就是下列方程的解:

极大似然估计的求解一般通过梯度下降法求解。
5.1.3 求极大似然估计实例
下面通过实例来说明求极大似然估计的具体方法。
例1:假设n个样本,它们属于伯努利分布B(p),其中取值为1的样本有m个,取值为0的样本有n-m个,样本集的极大似然函数为:

两边取对数log得:
logL(p)=mlogp+(n-m)log(1-p)
对logL(p)求导并设为0:

解得:

例2:假设n个样本 ,它们属于正态分布
,它们属于正态分布 ,,该样本集的极大似然函数为:
,,该样本集的极大似然函数为:
求极大似然函数估计值的一般步骤:
(1)写出似然函数;
(2)对似然函数取对数,并整理;
(3)求导数,令导数为0,得到似然方程;
(4)解似然方程,得到的参数即为所求。
5.1.4 极大似然估计的应用
极大似然估计与分类任务损失函数-交叉熵一致
设逻辑回归的预测函数为:

其中向量w,b为参数,x为输入向量。把参数及输入向量做如下扩充
[w,b]→w,[x,1]→x
式(5.3)可简化为:

对二分类任务来说,上式为样本为正的概率,样本属于负的概率为1-g(x)。
假设给定样本为 。为n维向量(即每个样本有n个特征),
。为n维向量(即每个样本有n个特征), 为类标签,取值为0或1。根据伯努利分布的概率函数,每个样本的概率可写成下式:
为类标签,取值为0或1。根据伯努利分布的概率函数,每个样本的概率可写成下式: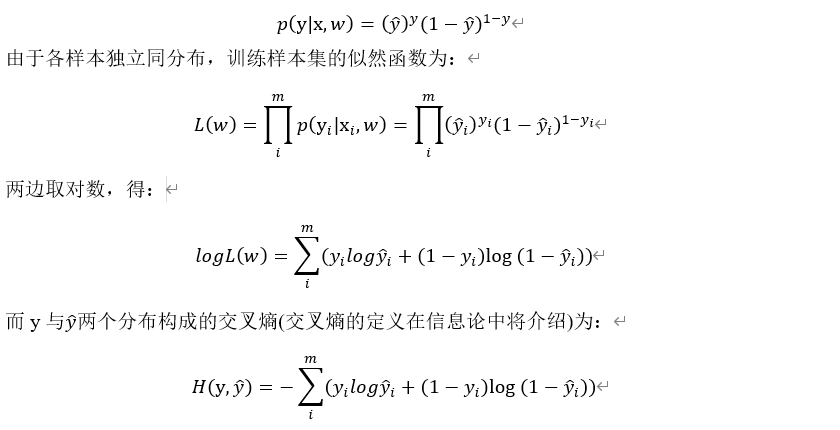
交叉熵一般作为分类任务的损失函数,由此可得,对数似然函数logL(w)与交叉熵只相差一个负号,即对极大似然估计等价于最小化损失函数(交叉熵)实际上效果是一致的!
极大似然估计与回归任务中的平方根误差一致
线性回归问题一般构建预测函数:

然后利用最小二乘法求导相关参数。另外,线性回归还可以从建模条件概率𝑝(𝑦|𝒙)的角度来进行参数估计,两种可谓殊途同归。
假设预测值y为一随机变量,该值下式为

其中 为服从标准正态分布,即均值为0,方差为
为服从标准正态分布,即均值为0,方差为 ,根据随机变量函数的分布相关性质可知,y服从均值为
,根据随机变量函数的分布相关性质可知,y服从均值为 ,方差为正太分布,即有:
,方差为正太分布,即有:
J(w)是线性回归的均方差损失函数,H(w)为似然函数。可见这里最小化J(w)与极大似然估计是等价的。







![var[X_i]](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_906df125f7e0113fdff936eecd63404f.gif)
![var[X_i ]<C,i=1,2,\cdots,n](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_269fdba5080bcb3ff9409f675cf1e65d.gif)

![\lim_{n\to\infty}p\left(\left|\bar{X}-\frac{1}{n}\sum_{i=1}^n E[X_i]\right|<\varepsilon\right)=1](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_d0b7b549589b79d1338223d53a2ddce9.gif)
![E[\bar{X}]=\frac{1}{n}\sum_{i=1}^n E[X_i]](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_998a8c7a39c4d2e3138c760e89a7d1de.gif)
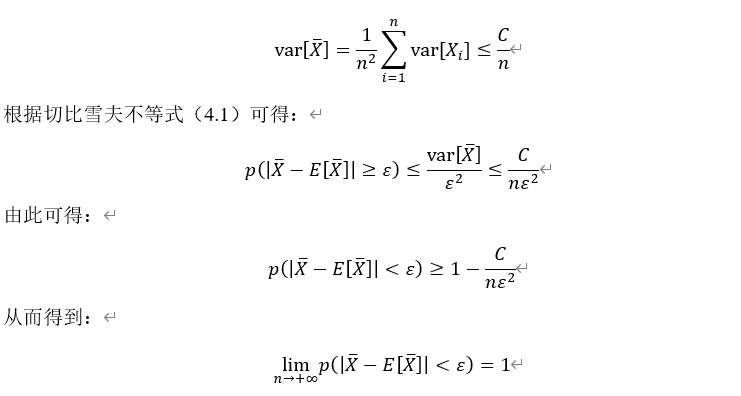



![E[\bar{X}]=\mu](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_05729ba1eef0965eba4dc587e3110862.gif)
![var[\bar{X}]=\frac{\sigma^2}{n}](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_8100ce4a8bad5a7941e32ca34075ad7f.gif)













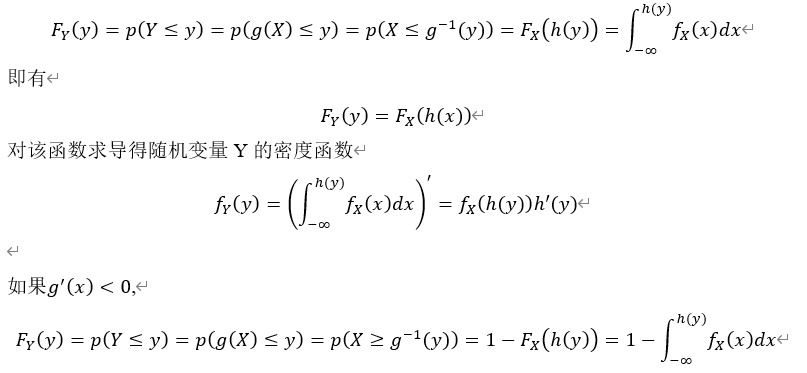





















![var(X)=E[X^2]-E^2 X](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_978edb4a8f65724c6fd8befe7f3a02c0.gif)



























































![E[X]=\sum_i^m x_i a_i](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_600f912ca047b7300d3f89f66b692ab2.gif)
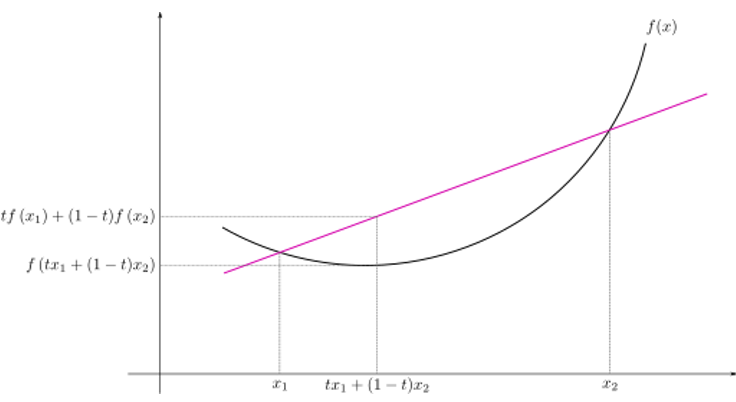
![f(E[X])\le E[f(X)]](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_70ad9eecd8ae1ed2e371b7fd07962dc8.gif)






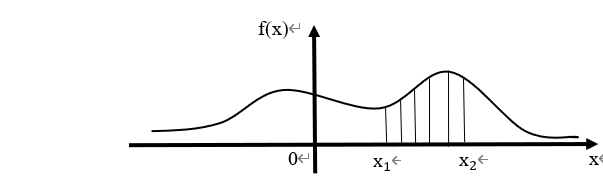
![[x_1,x_2]](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_e2928e128099d8ebc393e5079c62ab4c.gif)





















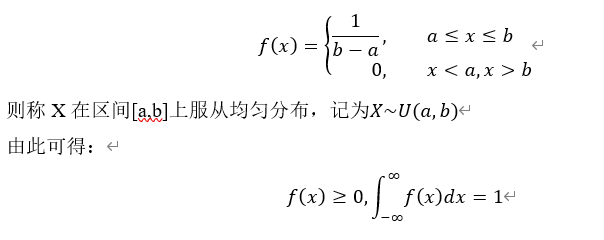










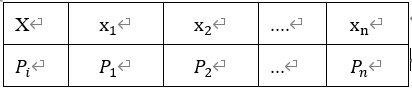









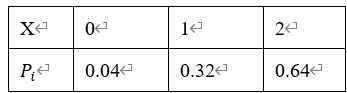







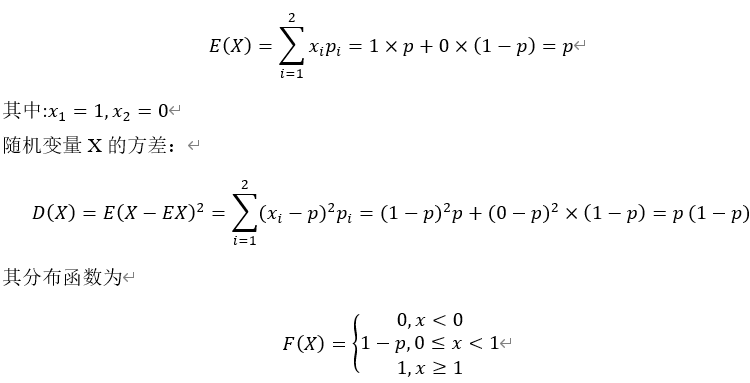




![[1,0,0,\cdots,0],X=2,](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_03c5f484dd0681c3f5deb663acbf8bdd.gif)
![[0,1,0,0,\cdots,0]](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_d3dbda39c04813c72bdd58877d226db0.gif)
![[y_1,y_2,\cdots,y_k]](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_494bfb791bf3f49062e568e7e20f286e.gif)


