2.1 Adam算法的优点
Adam算法一直是优化算法中优等生,它有很多优点,如下图所示:
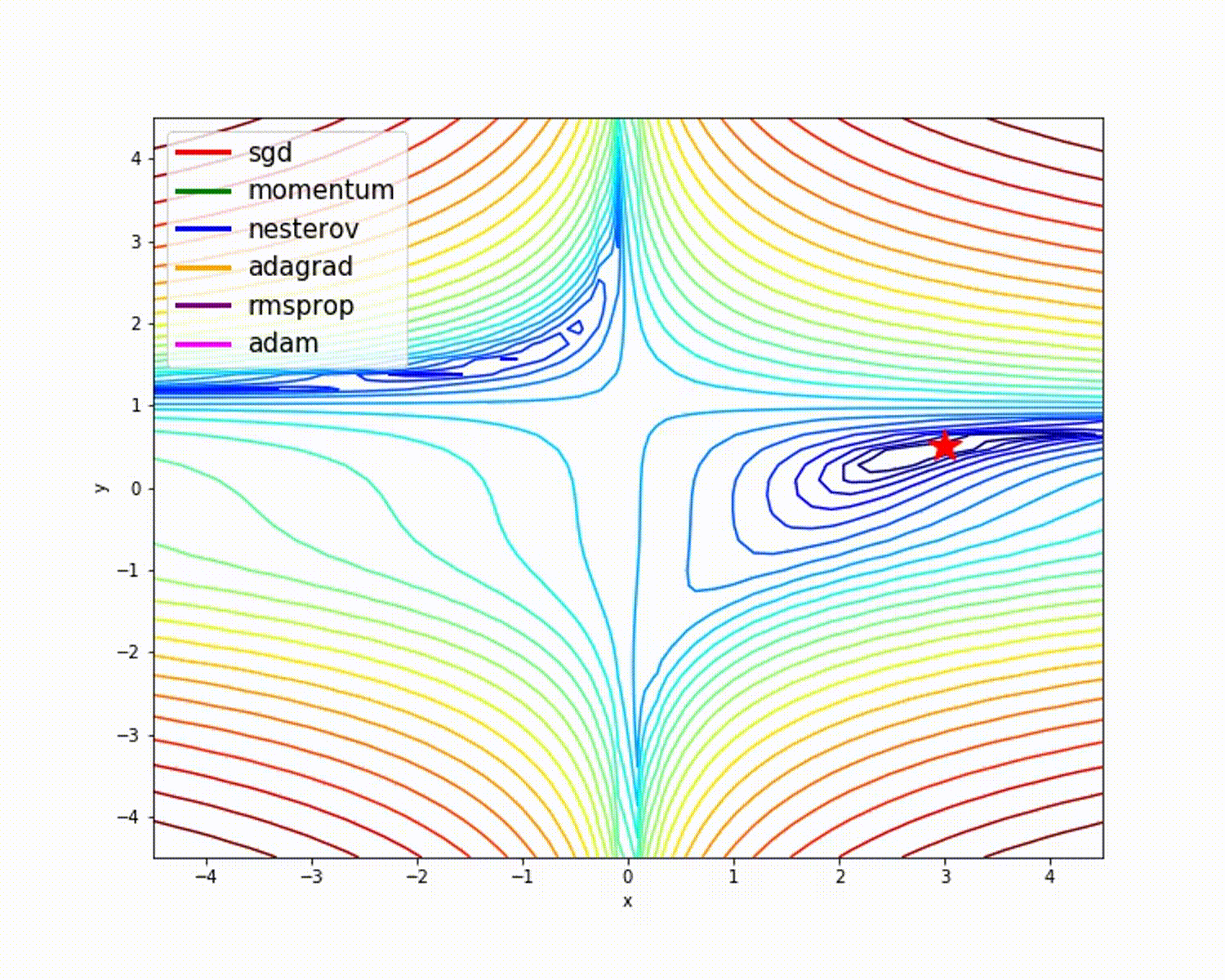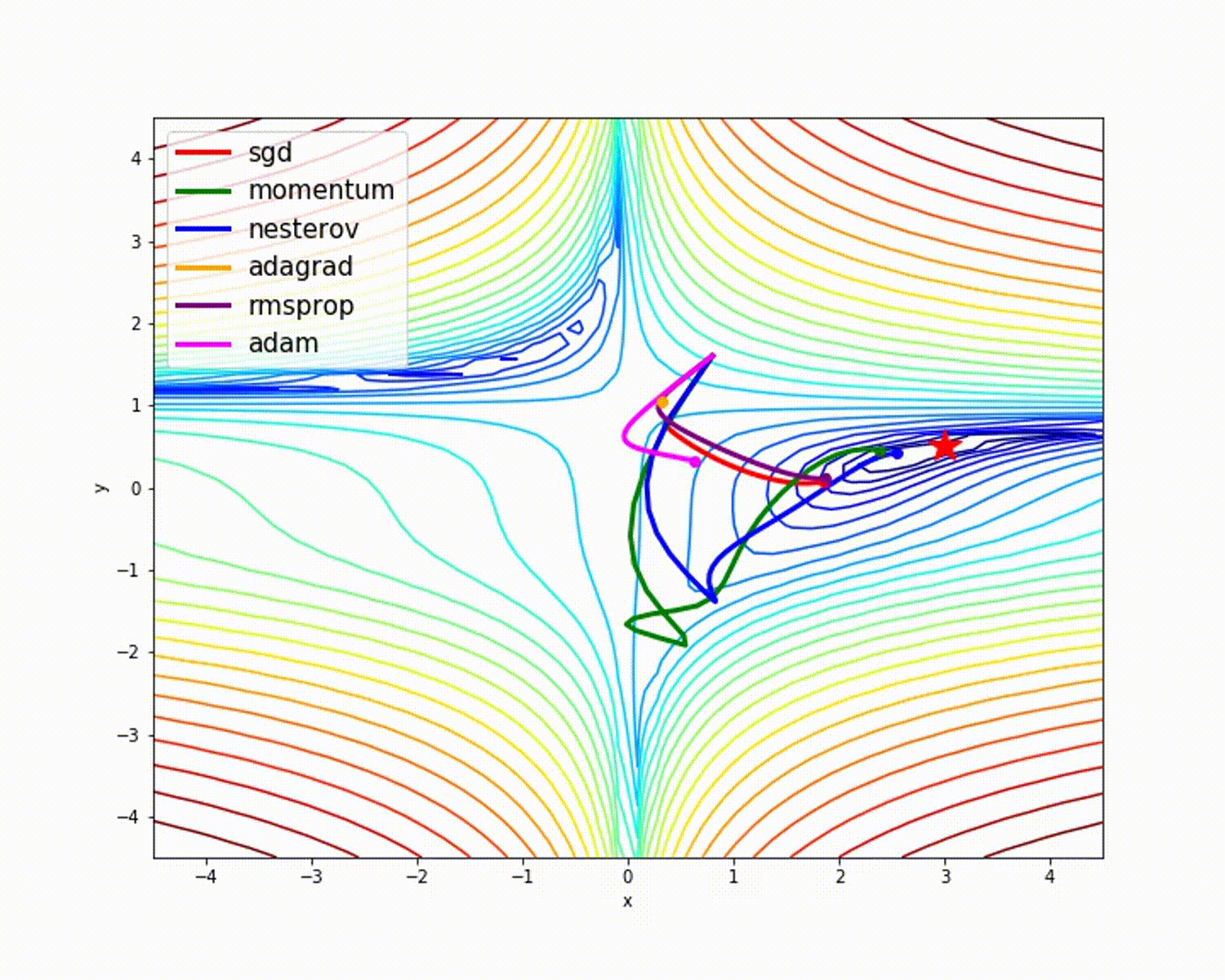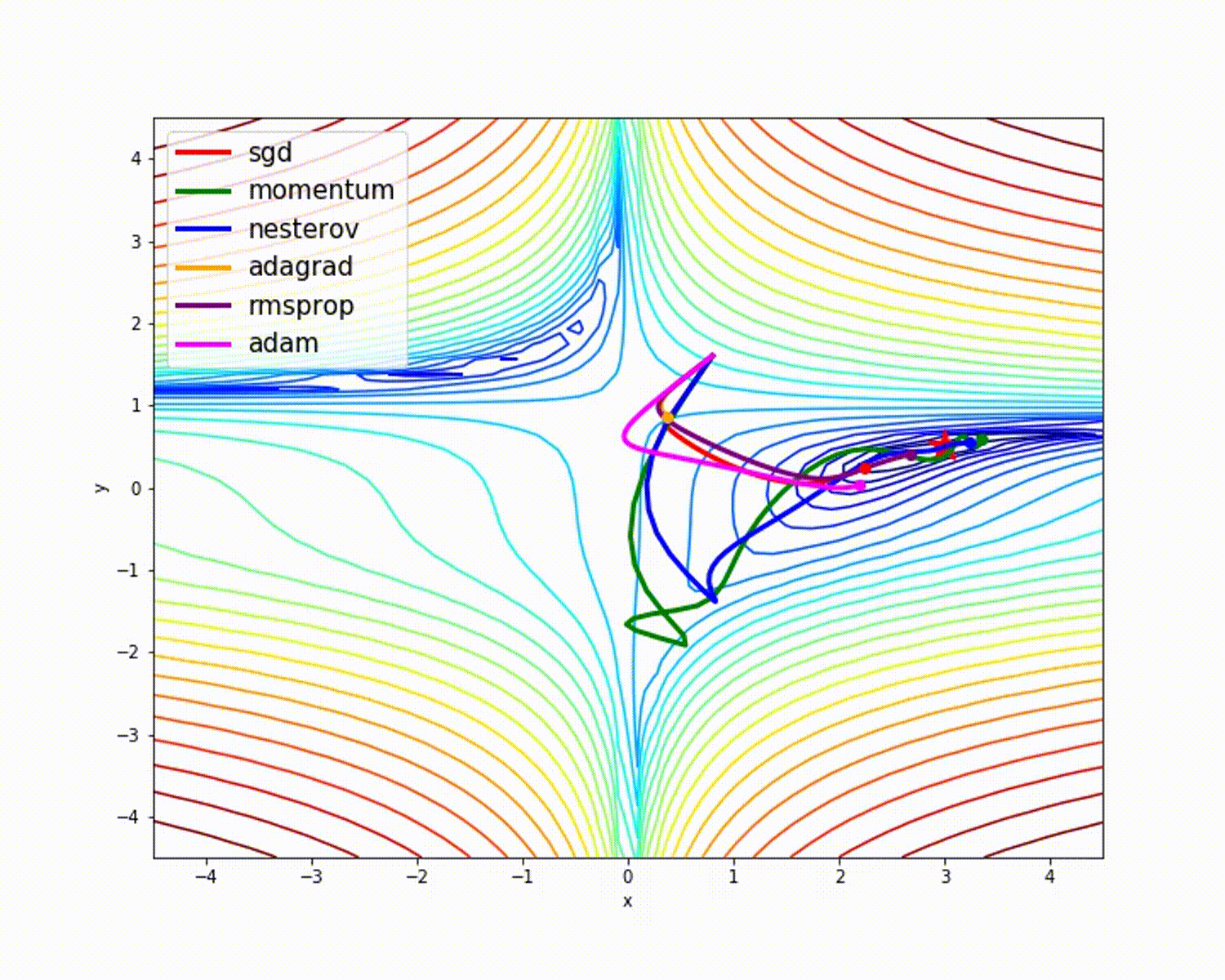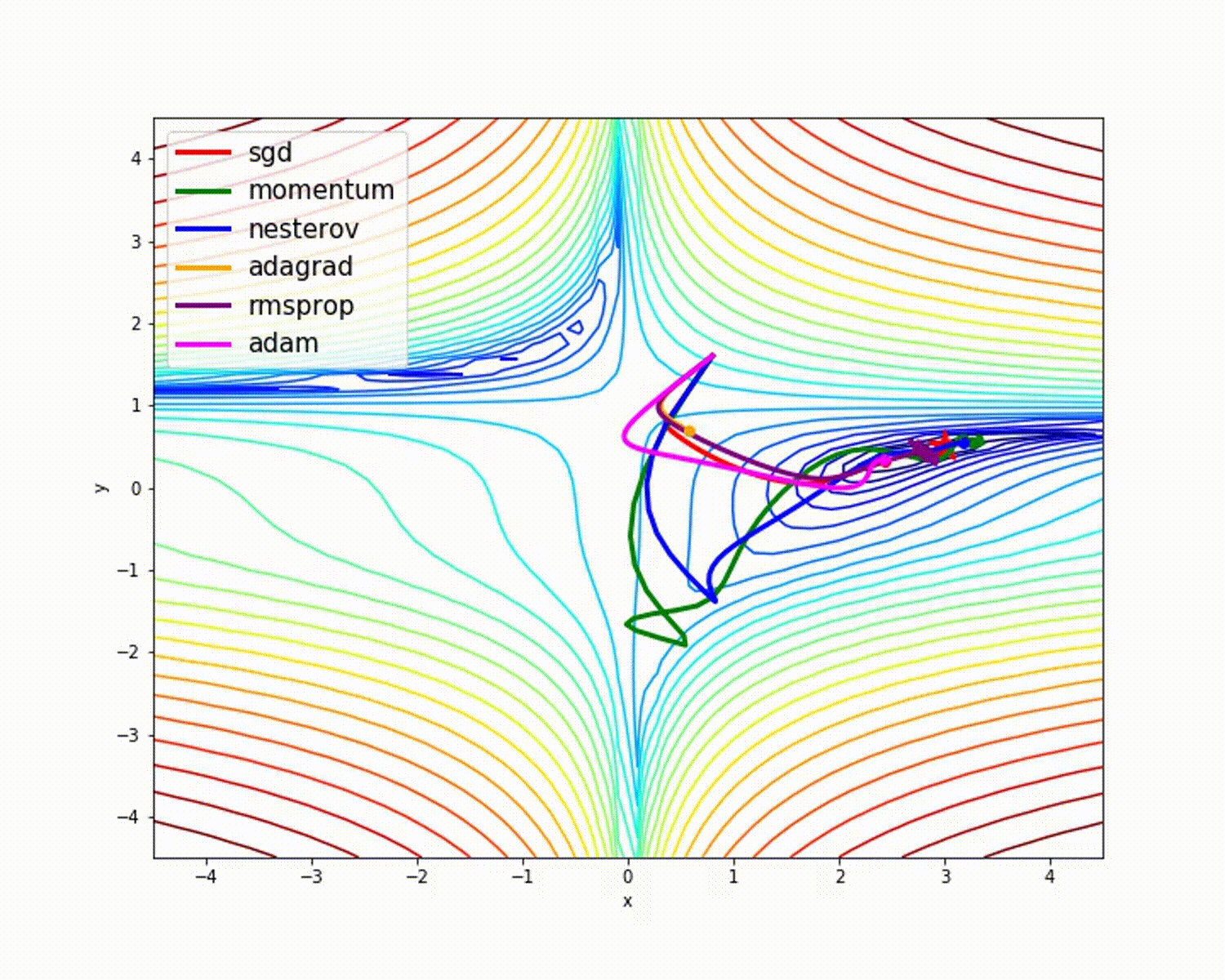
以Adam为代表的优化算法,能够避开鞍点最快抵达目标。传统SGD(不带动量)算法方法
容易受到外界干扰,其行走路线比较曲折。
2.2 Adam算法的表现不尽如人意
虽然Adam很多的优点(带有动量,学习率的自适应性),但在深度学习的很多数据集上的最好效果还是用SGD with Momentum细调出来的。可见Adam的泛化性并不如带有动量(Momentum)的SGD。【https://arxiV.org/pdf/1711.05101.pdf 】中提出其中一个重要原因就是Adam中L2正则化项并不像在SGD中那么有效。
2.3 Adam算法表现不佳的原因是什么?
Adam算法表现不佳的原因就是其梯度更新与权重衰减耦合在一起,如下图所示:
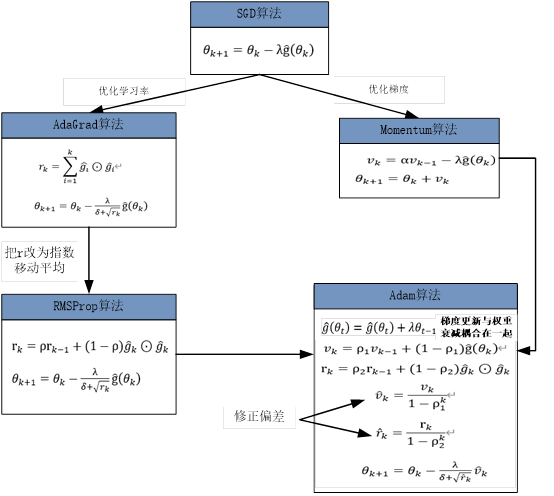
2.4 如何解决这个问题?
这是PyTorch平台给出的解决方案

2.5 AdamW算法的优点
在优化算法中,AdamW相对于Adam的改进主要表现在权重衰减的处理方式上。具体来说,AdamW在应用权重衰减时,将其与梯度更新解耦,避免了两者之间的耦合问题。这种改进的背后原因主要有以下几点:
(1)更稳定的优化过程:原始的Adam算法在权重衰减与梯度更新的耦合方式可能会导致优化过程中的不稳定。当权重衰减较大时,这种耦合可能导致梯度更新变得非常小,从而使得学习率变得非常慢。解耦后,梯度更新和权重衰减可以独立调整,从而使得优化过程更加稳定。
(2)避免不一致性:权重衰减与梯度更新的耦合可能导致算法的不一致性。当权重衰减变化时,它可能会影响到梯度的计算,这可能导致算法在优化过程中行为不一致。解耦后,权重衰减只作为一个单独的项来处理,避免了这种不一致性。
(3)更好的泛化性能:权重衰减作为一种正则化技术,有助于防止模型过拟合。通过解耦,AdamW可以更好地利用权重衰减的正则化效果,从而提高模型的泛化性能。
(4)更广泛的适用性:由于AdamW在权重衰减方面的改进,它可能更适合于一些需要较强正则化的场景。通过独立调整权重衰减和梯度更新,AdamW可以更好地适应不同的任务和数据集,从而提高算法的适用性。
(5)灵活的超参数调整:解耦后,可以更加灵活地调整超参数。例如,可以独立调整权重衰减和学习率,而不会相互影响。这为超参数调整提供了更大的灵活性,有助于找到最优的超参数配置。
总之,AdamW通过改进权重衰减的处理方式,提高了优化算法的稳定性、一致性和泛化性能,使其在各种机器学习任务中更具竞争力,能用Adam的地方可以都用AdamW来代替。