2.Pandas提高篇
2.1 如何提高数据的颜值?
很多时候面对各种数据,我们想要让不同DataFrame有不同的颜色或格式来显示(styling),这时可以使用pandas Styler底下的format函式来实现,如何实现?以下通过一个实例来说明。
(1)生成数据
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import numpy as np import pand as pd np.random.seed(100) boolean=[True,False] gender=["男","女"] color=["红色","白色","黑色","黄色",np.nan] data=pd.DataFrame({ "height":np.random.randint(150,190,100), "weight":np.random.randint(40,90,100), "smoker":[boolean[x] for x in np.random.randint(0,2,100)], "gender":[gender[x] for x in np.random.randint(0,2,100)], "age":np.random.randint(15,100,100), "color":[color[x] for x in np.random.randint(0,len(color),100) ] } ) |
(2)数据浏览
|
1 2 |
data10=data.head() data10 |
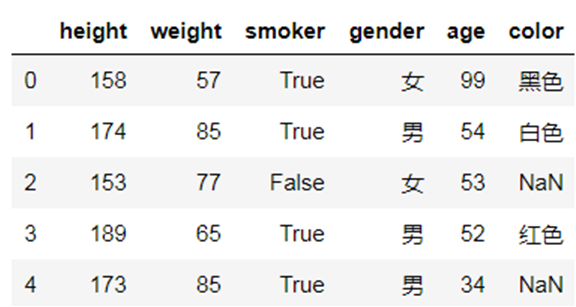
(3)对dataframe不同数据设置不同的显示风格
|
1 2 3 4 5 6 7 8 9 10 |
(data10.style #.format('{:.1f}', subset='BMI') .set_caption('★给数据集增添一点颜值☆') #添加一个标题说明 .hide_index() #隐藏索引 .bar('age', vmin=0) #将age字段依数值大小画条状图 .highlight_max('height') #将height最大的值高亮 .background_gradient('Greens', subset='weight') #将weight字段依数值画绿色的colormap .highlight_null() #将整个DataFrame中空值(nan)显示为红色 ) |
(4)显示结果

2.2如何使你的分析更专业?
通常的数据分析有:排序、分组汇总平均分析、同比、环比等等,如何使你的分析更专业?可以通过引入一些更具专业的KPI指标分析,如反应客户偏好的TGI分析、反应客户价值的RMF指标、投资回报比(ROI)等等,这里以TGI分析为例,这也是用户画像中的一个重要指标。
2.2.1 TGI指标解释
1.TGI(Target Group Index的简称)指标计算公式:

2.TGI关键特征
TGI计算公式中,有三个关键点:总体,目标群体,某一特征。
总体:是我们研究的所有对象,比如一个学校里的所有人;
目标群体:是总体中我们感兴趣的一个分组,比如一个班;
某一特征:想要分析的某种行为或者状态,比如打篮球。
3、TGI计算示例
假设一个学校有1000人,有300个人喜欢打篮球,那么这个比例就是30%,即“总体中具有相同特征的群体所占比例” = 30%。
假设一个班有50个人,有20个人喜欢打篮球,那么这个比例就是40%,即“目标群体中具有某一特征的群体所占比例” = 40%。
TGI指数 = (40% / 30%) * 100 = 133
TGI指数大于100,代表着某类用户更具有相应的倾向或者偏好,数值越大则倾向和偏好越强;小于100,则说明该类用户相关倾向较弱(和平均相比);而等于100则表示在平均水平。
2.2.2 导入数据
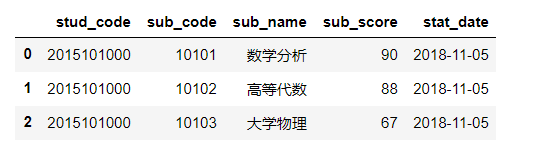
本数据为客户购买商品的订单信息,具体数据包括品牌名、买家姓名、付款时间、订单状态和地域等字段,一共28832条数据。
1、导入数据
|
1 2 3 |
import pandas as pd df = pd.read_excel('.\data\pandas_data\TGI-data.xlsx') df.head() |
2、数据浏览
|
1 |
df.info() |
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 28832 entries, 0 to 28831
Data columns (total 9 columns):
品牌名称 28832 non-null object
买家昵称 28832 non-null object
付款日期 28832 non-null datetime64[ns]
订单状态 28832 non-null object
实付金额 28832 non-null float64
邮费 28832 non-null int64
省份 28832 non-null object
城市 28832 non-null object
购买数量 28832 non-null int64
dtypes: datetime64[ns](1), float64(1), int64(2), object(5)
memory usage: 2.0+ MB
2.2.3 选择一个特征
这里我们以每个客户平均销售额50为界限,划分“高客单”或"低客单",接下来我们以“高客单”为特征进行TGI分析。
1、对dataframe进行分组汇总
|
1 |
df_users=df.groupby("买家昵称")["实付金额"].mean().reset_index() |
2、增加一个客单类别指标
|
1 |
df_users["客单类别"]=df_users["实付金额"].apply(lambda x: "高客单" if x>50 else "低客单") |
2.2.4 获取客户地域信息
df_users有单个用户的金额和客户类型,为便于各省市消费情况的比较,接下来就是添加每个用户的地域字段, 这个可以同pd.merge函数实现,具体与两表关联类型。由于源数据是未去重的,我们得先按昵称去重,不然匹配的结果会有许多重复的数据。
1、关联前对原df进行预处理
|
1 2 3 4 5 |
#对df基于“买家昵称”去重 df_dup = df.loc[df.duplicated(subset=['买家昵称'])==False,:] #根据"买家昵称"字段左关联两个数据集 df_ge = pd.merge(df_users,df_dup,left_on='买家昵称',right_on='买家昵称',how='left') df_ge.head() |

【说明】
DataFrame.duplicated函数格式为:
DataFrame.duplicated(subset=None, keep='first') 参数说明:
subset可选
keep{‘first’, ‘last’, False}, default ‘first’ df.loc函数功能:
通过标签或布尔数组访问一组行和列
2.2.5 计算高客单TGI指标
|
1 2 3 4 5 |
#选择需要的列 df_ge = df_ge[['买家昵称','客单类别','省份','城市']] #利用透视表函数 result = pd.pivot_table(df_ge,index=['省份','城市'],columns='客单类别',aggfunc='count') result.head(10) |

这样得到的结果包含了层次化索引,要索引得到“高客单”列,需要先索引“买家昵称”,再索引“高客单”。
|
1 |
result['买家昵称']['高客单'].reset_index().head() |
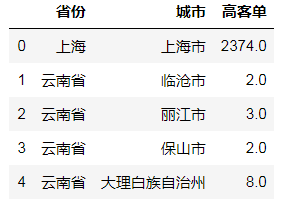
这样,拿到了每个省市的高客单人数,然后再拿到低客单的人数,进行横向合并:
|
1 2 3 4 5 6 7 |
tgi = pd.merge( result['买家昵称']['高客单'].reset_index(), result['买家昵称']['低客单'].reset_index(), left_on = ['省份', '城市'], right_on = ['省份', '城市'], how = 'inner' ) |
再看看每个城市总人数以及高客单人数占比,来完成“目标群体(如:高客单)中具有某一特征的群体所占比例”这个分子的计算:
|
1 2 3 4 |
tgi['总人数'] = tgi['高客单'] + tgi['低客单'] tgi['高客单占比'] = tgi['高客单'] / tgi['总人数'] tgi.head() |

有些非常小众的城市,高客单或者低客单人数等于1甚至没有,而这些值尤其是空值会影响结果的计算,我们要提前检核数据:
|
1 2 3 4 5 |
#剔除掉存在空值的行 tgi = tgi.dropna() #接着统计总人数中,高客单人群的比例,来对标公式中的分母“总体中具有相同特征的群体所占比例 total_percentage = tgi['高客单'].sum() / tgi['总人数'].sum() print(total_percentage ) |
0.41528303343887557
最后一步,就是TGI指数的计算,顺便排个序
|
1 2 3 |
tgi['高客单TGI指数'] = tgi['高客单占比'] / total_percentage * 100 tgi = tgi.sort_values('高客单TGI指数', ascending=False) tgi.head() |
|
1 2 |
#对总人数进行筛选,用总人数的平均值作为阈值,只保留总人数大于平均值的城市 tgi.loc[tgi['总人数'] > tgi['总人数'].mean(), :].head(10) |
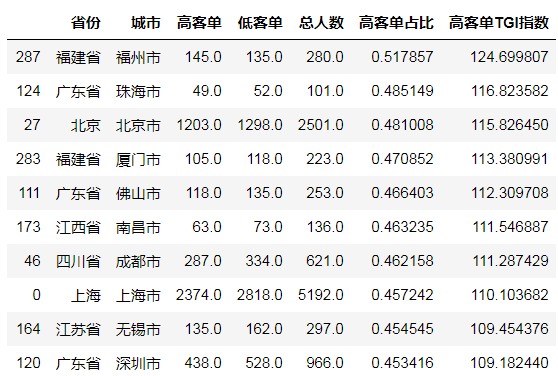
2.2.6 重要结论
基于各城市高客单TGI指数,我们发现福州、珠海、北京、厦门、佛山、南昌、成都、上海、无锡和深圳,是高客单偏好排名前10的城市!咱们要试销的高客单新产品,如果仅从客单角度,可以优先考虑他们!
2.3 如何使你的分析结果更具震撼效果?
为使分析结果更直观、更具震撼效果,可以采用pycharts工具,该工具提供了很多富有感染力的画图模块,除通常的图形外,Pycharts还提供热力图、日历图、迁徙图、地图等等,这里我们以地图为例。
1、导入需要的库
|
1 2 3 4 5 6 7 |
from pyecharts.charts import Pie, Bar, TreeMap, Map, Geo from wordcloud import WordCloud, ImageColorGenerator import pyecharts.options as opts import matplotlib.pyplot as plt from PIL import Image import pandas as pd import numpy as np |
2、对tgi增加一个字段
为便于使用中国地图,这里增加一个中国字段。
|
1 |
tgi["中国"]="中国" |
3、创建画图函数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
def create_province_map(df): # 筛选数据 df = df[df["中国"] == "中国"] df1 = df.copy() # 数据替换 df1["省份"] = df1["省份"].str.replace("省", "").str.replace("壮族自治区", "").str.replace("维吾尔自治区", "").str.replace("自治区", "") # 分组计数 df_num = df1.groupby("省份")["总人数"].agg(count="sum") df_province = df_num.index.values.tolist() df_count = df_num["count"].values.tolist() # 初始化配置 map = Map(init_opts=opts.InitOpts(width="800px", height="400px")) # 中国地图 map.add("", [list(z) for z in zip(df_province, df_count)], "china") # 设置全局配置项,标题、工具箱(下载图片)、颜色图例 map.set_global_opts(title_opts=opts.TitleOpts(title="GHI各省份分布图", pos_left="center", pos_top="0"), toolbox_opts=opts.ToolboxOpts(is_show=True, feature={"saveAsImage": {}}), # 设置数值范围0-2000,is_piecewise标签值连续 visualmap_opts=opts.VisualMapOpts(max_=2000, is_piecewise=False)) map.render("GHI各省份分布图.html") |
运行该函数
|
1 |
create_province_map(tgi) |
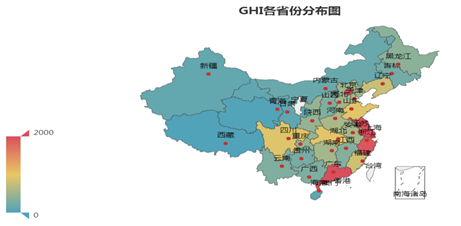
显示各省或直辖市,高客单的用户数。
另外,向大家提供一个有关如何提升数据分析能力的博客,供大家参考
月薪3000和30000的数据分析师差在哪?