文章目录
1.强化学习难入门的主要原因
目前强化学习运用非常广泛,如在大语言模型,自动化,游戏等领域都有广泛的应用,但想要入门,却不简单,不少人看了不少视频或博客或书,但如果要总结一下强化学习的核心内容,还是感到一头雾水。这好像是一个普通现象,个人觉得主要是因为:
(1)强化学习涉及很多新知识、新概念。
(2)强化学习涉及面较广
(3)强化学习中数学成分较多
2.如何破解强化学习难入门问题
这里提供个人的一点,供大家参考。
(1)找准着力点(或入口),这里基本算法(可参考Leecode网址)我觉得是一个较好着力点。
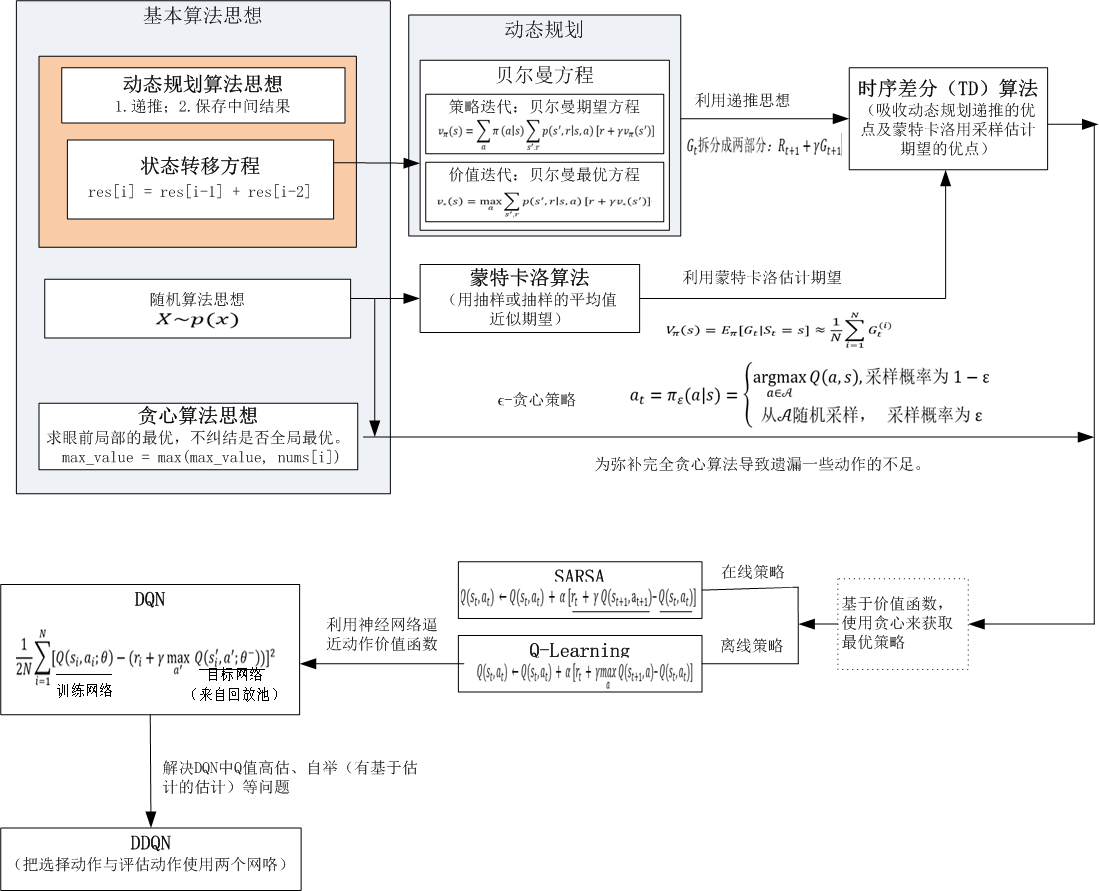
(2)从着力点开始,找到新旧知识的联系,从宏观上把握强化学习算法,这里我提供几个图,供大家参考。
(3)把握各算法之间的递进关系
(4)循序渐进,由宏观把握,再进入细节,甚至代码实现,强化学习的多种应用(如在在游戏方法,在GPT方法等到),然后再深入浅出。
3.强化学习几个重要概念的简单解释
(1)马尔科夫链
简单来说:随机过程+马尔科夫性=马尔科夫过程
马尔可夫过程(Markov Process)指具有马尔可夫性质的随机过程,也被称为马尔可夫链(Markov chain),【其中马尔可夫性类似于两两相扣的铁链,虽然是两两相扣,却能构成一个长长的铁链,把历史和现在连接在一起。】
(2)马尔可夫奖励过程
简单来说:马尔科夫过程+奖励=马尔科夫奖励过程
(3)回报
简单来说:回报就是所有奖励的折扣之和
(4)马尔科夫决策过程
简单来说:马尔科夫决策过程=马尔科夫过程+动作(由决策产生)
(5)策略
策略就是选择动作的概率。
(6)状态价值函数
状态价值函数就是策略获得的回报期望。
(7)同步策略与异步策略
我们称采样数据的策略为行为策略(behavior policy),称用这些数据来更新的策略为目标策略(target policy)。在同步策略(on-policy)(又称为在线策略)算法表示行为策略和目标策略是同一个策略,像SARSA、A2C等算法属于使用同步策略的算法。
而异步策略(off-policy)(又称为离线策略)算法表示行为策略和目标策略不是同一个策略。许多异步策略算法使用重放缓冲区来存储经验,并从重放缓冲区中采样数据以训练模型,Q-Learning、DQL等属于异步策略算法.
(8)自举
自举就是用估计进行估计。
4.由基本算法到强化学习算法
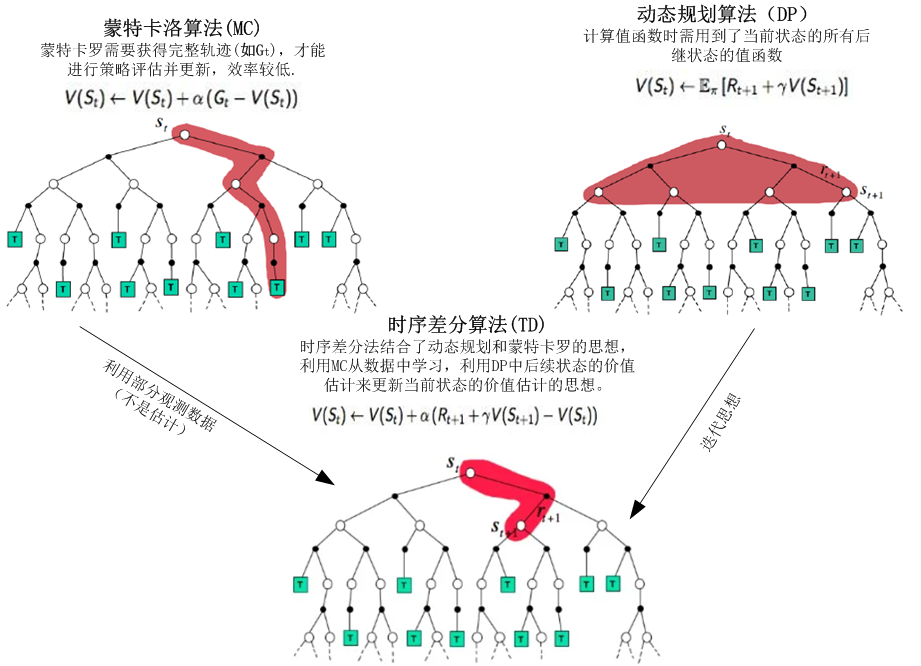
5.蒙特卡洛算法、动态规划算法、时序差分算法之间的异同
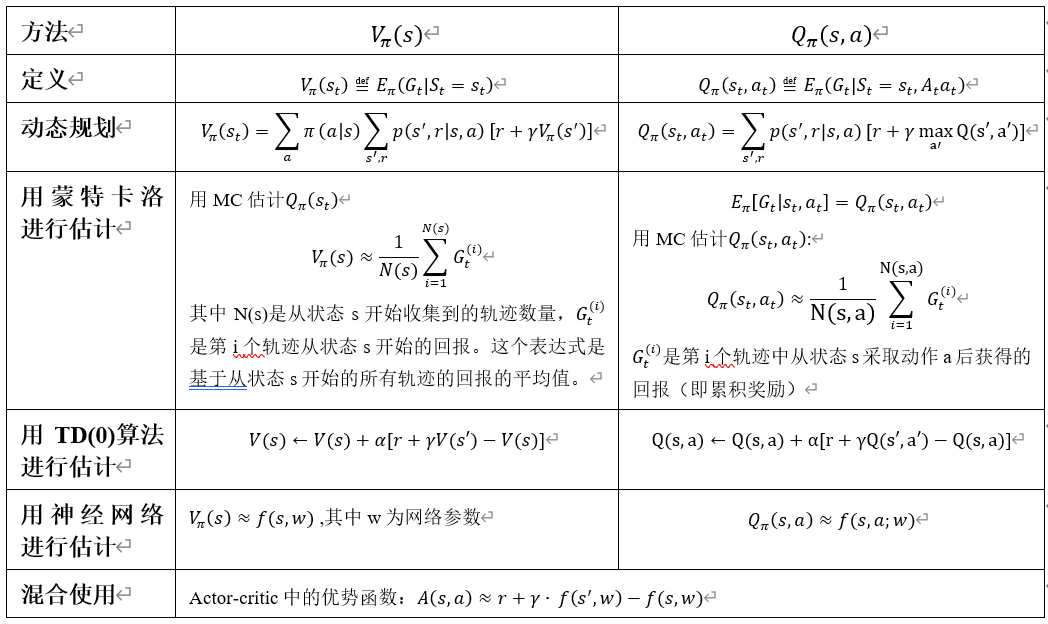
6.蒙特卡洛算法、动态规划算法、时序差分算法等算法的使用示例
7.由基于价值函数到基于策略的过渡

提供两个强化学习入门较优化的网址:
动手学强化学习
王树森老师讲解强化学习