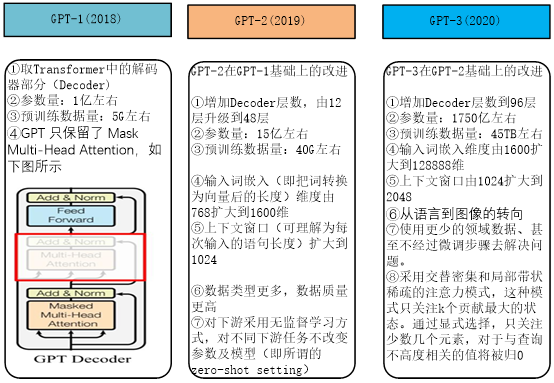
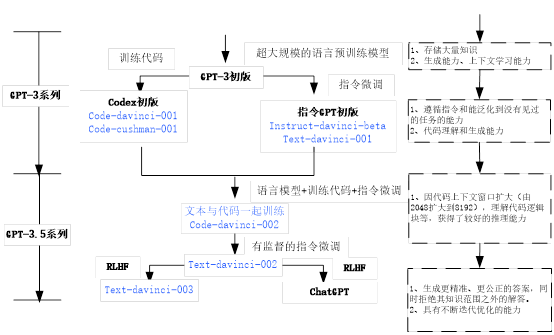
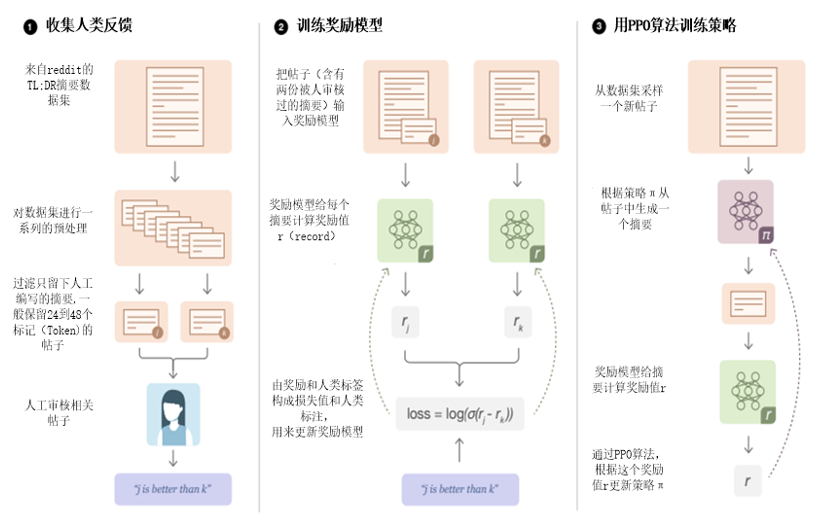
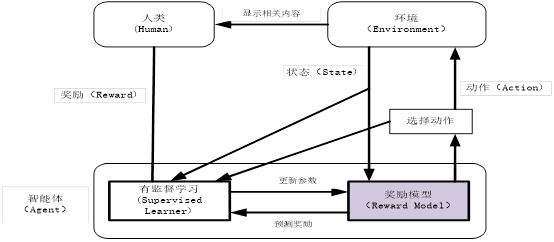
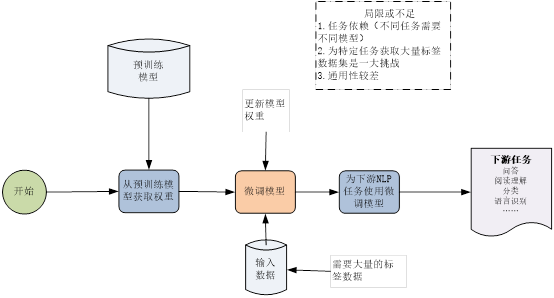
第1章 可视化GPT原理
BERT预训练模型采用了Transformer的Encoder部分,这节介绍的GPT(包括GPT-2、GPT-3)使用Transformer的Decoder部分。
1.1 GPT简介
GPT来自OpenAI的论文《Improving Language Understanding by Generative Pre-Training》,后来又在论文《Language Models are Unsupervised Multitask Learners》提出了 GPT-2 模型。GPT-2 与 GPT 的模型结构差别不大,但是采用了更大、更高质量的数据集进行实验。
GPT 是在 Google BERT算法之前几个月提出的,与 BERT 最大的区别在于,GPT和后来的一些模型,如TransformerXL和XLNet本质上是自回归(auto-regressive)模型,即使用单词的上文预测单词,而 BERT 不是,它采用使用MLM模型,同时利用单词左右来预测。因此,GPT 更擅长处理自然语言生成任务 (NLG),而 BERT更擅长处理自然语言理解任务 (NLU)。
1.2 GPT的整体架构
GPT 预训练的方式和传统的语言模型一样,通过上文,预测下一个单词,GPT的整体架构如图1-11所示。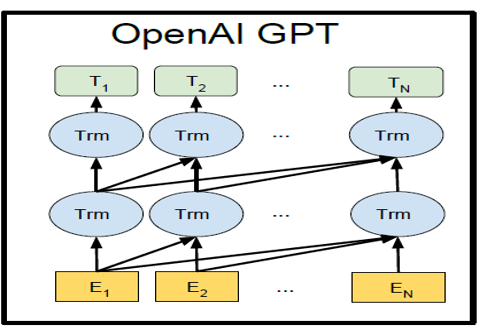
图1-11 GPT的整体架构图
其中Trm表示Decoder模块,在同一水平线上的Trm表示在同一个单元,E_i表示词嵌入,那些复杂的连线表示词与词之间的依赖关系,显然,GPT要预测的词只依赖前文。
GPT-2根据其规模大小的不同,大致有4个版本,如图1-12所示。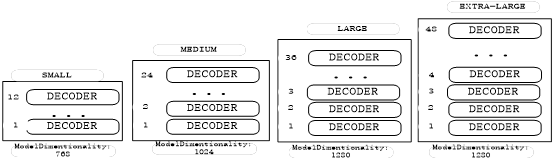
图1-12 GPT-2的4种模型
1.3 GPT模型结构
GPT、GPT-2使用 Transformer的Decoder 结构,但对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention,如图1-13所示。
图1-13 GPT的模型结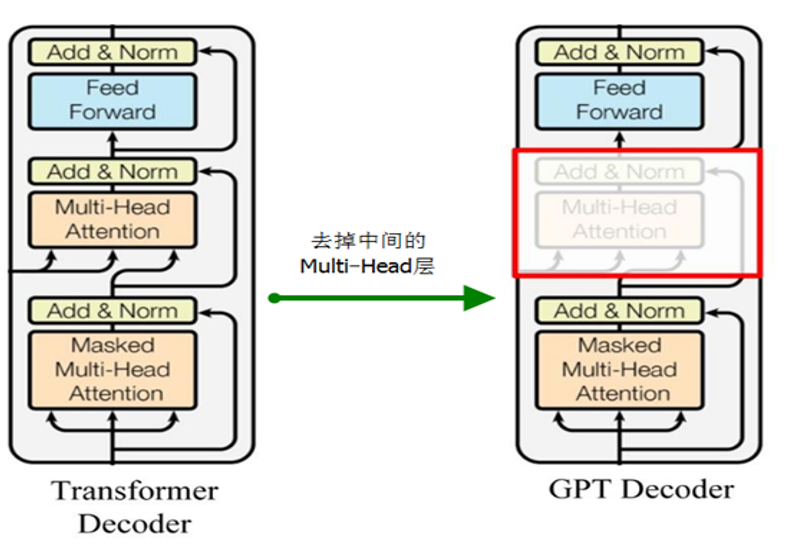 构
构
1.4 GPT-2的Mult-Head与BERT的Mult-Head区别
BERT使用Muti-Head Attention ,可以同时从某词的左右两边进行关注。而GPT-2采用Masked Muti-Head Attention,只能关注词的右边,如图1-14所示。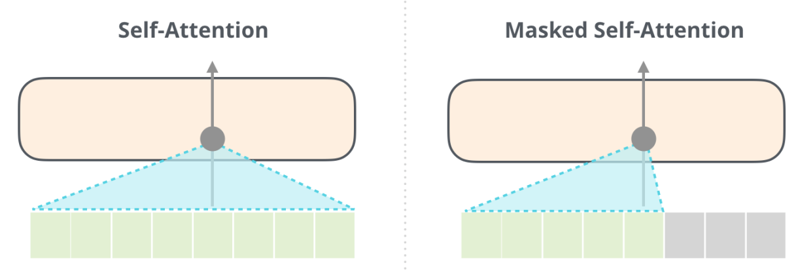
图1-14 BERT与GPT-2的Multi-Head的异同
1.5 GPT-2的输入
GPT-2的输入涉及两个权重矩阵,一个是记录所有单词或标识符(Token)的嵌入矩阵(Token Embeddings),该矩阵形状为mode_vocabulary_size xEmbedding_size,另一个为表示单词在上下文位置的编码矩阵(Positional Encodings),该矩阵形状为:context_sizexEmbedding_size,其中Embedding_size根据GPT-2模型大小而定,SMALL模型为768,MEDIUM为1024,以此类推。输入GPT-2模型前,需要把标识嵌入加上对应的位置编码,如图1-15所示。
图1-15 GPT-2 的输入数据
在图1-15中,每个标识的位置编码在各层DECODER是不变的,它不是一个学习向量。
1.6 GPT-2 计算Masked Self-Attention的详细过程
假设输入语句为:"robot must obey orders",接下来must这个query对其它单词的关注度(即分数),主要步骤:
(1)对各输入向量,生成矩阵Q、K、V;
(2)计算每个query对其它各词的分数;
(3)对所得的应用Mask(实际上就是乘以一个下三角矩阵)
详细步骤如下:
1.创建矩阵Q、K 、V
对每个输入单词,分别与权重矩阵 相乘,得到一个查询向量(query vector)、关键字向量(key vector)、数值向量(value vector),如图1-16所示。
相乘,得到一个查询向量(query vector)、关键字向量(key vector)、数值向量(value vector),如图1-16所示。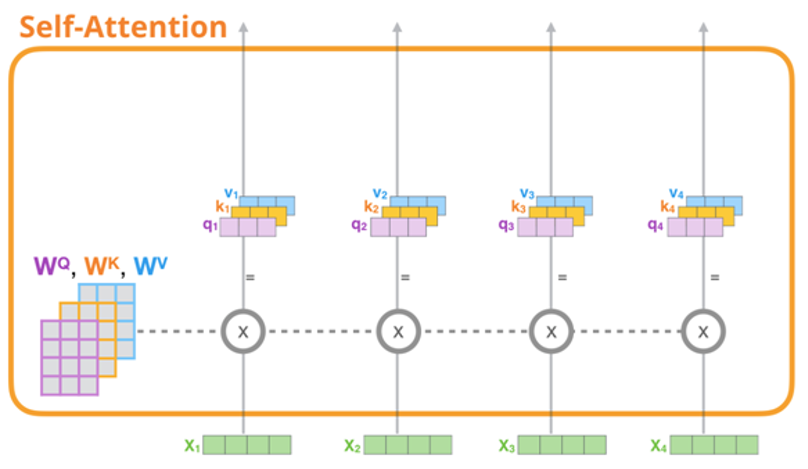
图1-16 生成self-Attention中的K,Q,V
2.计算每个Q对Key的得分
对每个Q对Key的得分计算公式,如图1-17所示。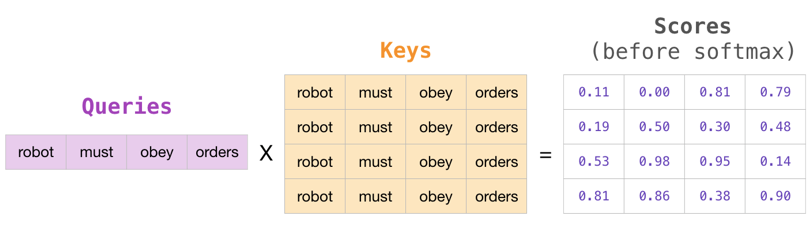
图1-17 Q对key得分的计算过程
3.对所得的分数应用Mask
对所得分再经过Attention Mask的映射,如图1-18所示。
图1-18 得分经过Mask示意图
4.Mask之后的分数通过softmax函数
经过Mask后的分数通过softmax后的结果如图1-19所示。
图1-19 得分通过softmax后
5.单词must(即q2)对各单词的得分为:
q2对各单词的得分,如图1-20所示。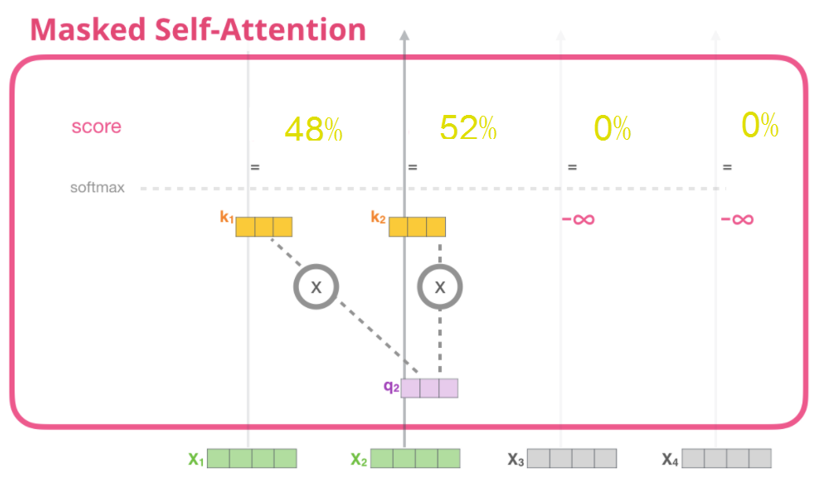
图1-20 q2对各词的得分
1.7 输出
在最后一层,对每个词的输出乘以Token Embedding矩阵(该矩阵的形状为mode_vocabulary_size xEmbedding_size,其中Embedding_size的值根据GPT-2的型号而定,如果是SMALL型,就是768,如果是MEDIUM型,就是1024等),最后经过softmax函数,得到模型字典中所有单词的得分,通过取top取值方法就可得到预测的单词,整个过程如图1-21所示。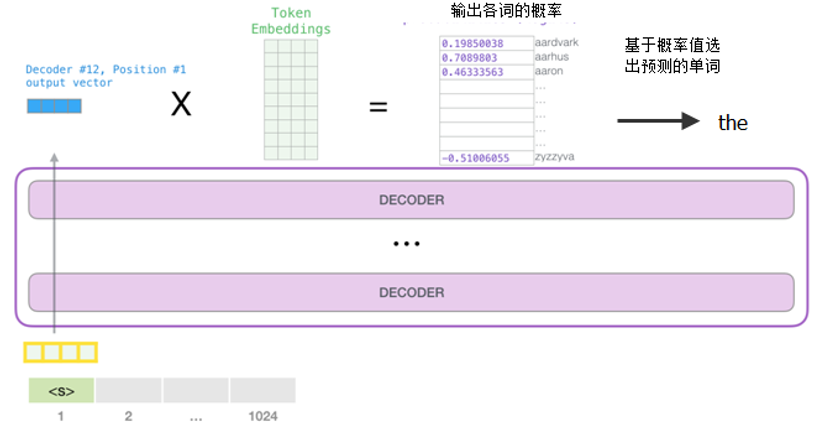
图1-21 GPT-2的输出
1.8 GPT与GPT-2的异同
在GPT的基础上,后面又开发出GPT-2,两者架构上没有大的变化,只是对规模、数据量等有些不同,它们之间的异同如下:
1.结构基本相同,都采用LM模型,使用Transformer的DECODER。
2.不同点:
(1)GPT-2结构的规模更大,层数更大。
(2)GPT-2数据量更大、数据类型更多,这些有利于增强模型的通用性,并对数据做了更多质量过滤和控制。
(3)GPT对不同的下游任务,修改输入格式,并添加一个全连接层,采用有监督学习方式,如图1-22所示。而GPT-2对下游采用无监督学习方式,对不同下游任务不改变参数及模型(即所谓的zero-shot setting)。
图1-22(左)Transforer的架构和训练目标,(右)对不同任务进行微调时对输入的改造。
GPT如何改造下游任务?微调时,针对不同的下游任务,主要改动GPT的输入格式,先将不同任务通过数据组合,代入Transformer模型,然后在模型输出的数据后加全连接层(Linear)以适配标注数据的格式,具体情况大致如下:
1.分类问题,改动很少,只要加上一个起始和终结符号即可;
2.句子关系判断问题,比如Entailment,两个句子中间再加个分隔符即可;
3.文本相似性判断问题,把两个句子顺序颠倒下做出两个输入即可,这是为了告诉模型句子顺序不重要;
4.多项选择问题,则多路输入,每一路把文章和答案选项拼接作为一个输入即可。
从图1-22可看出,这种改造还是很方便的,不同任务只需要在输入部分改造即可,所以GPT-2、GPT-3 对不同下游任务基本不改过参数和模型方式。
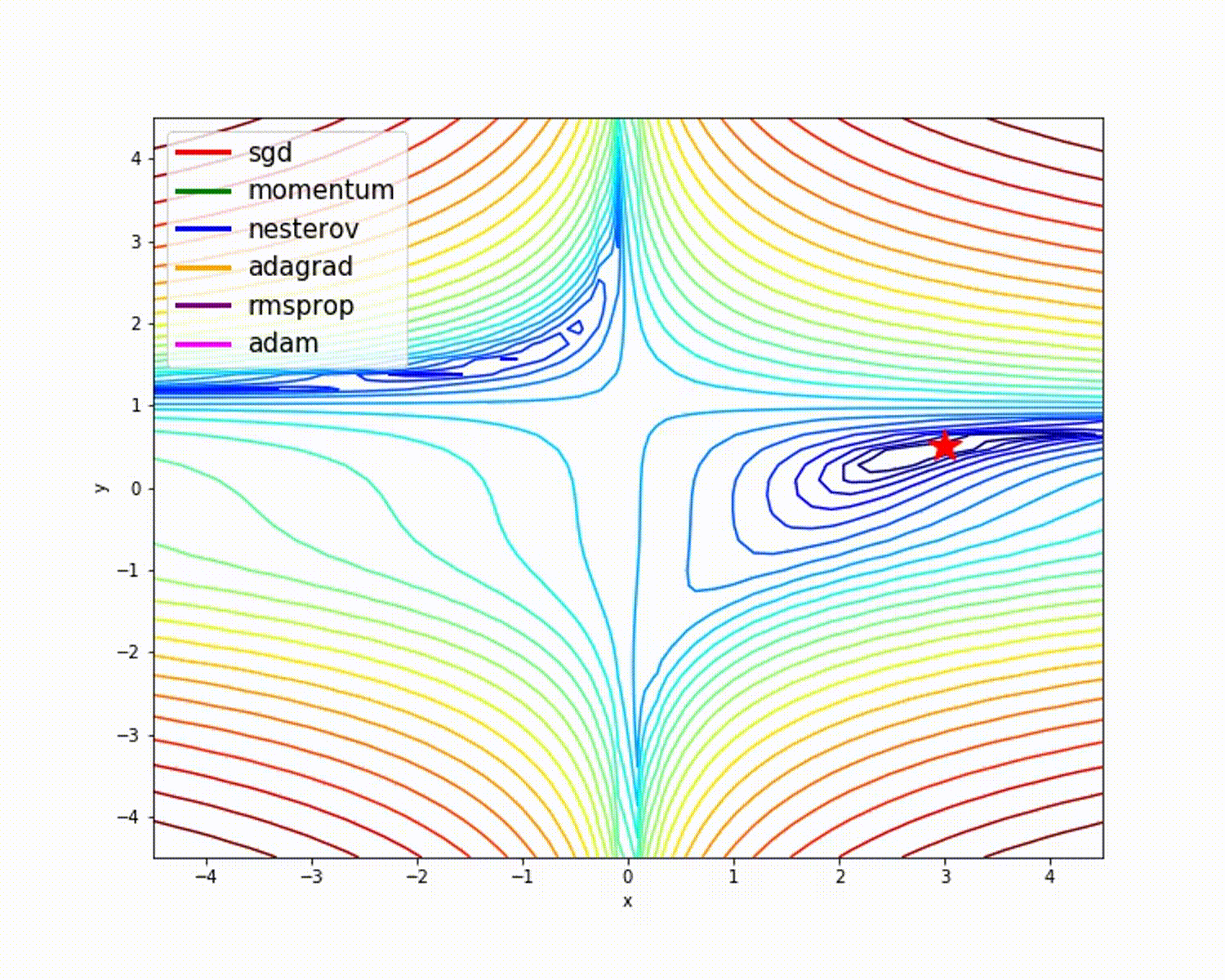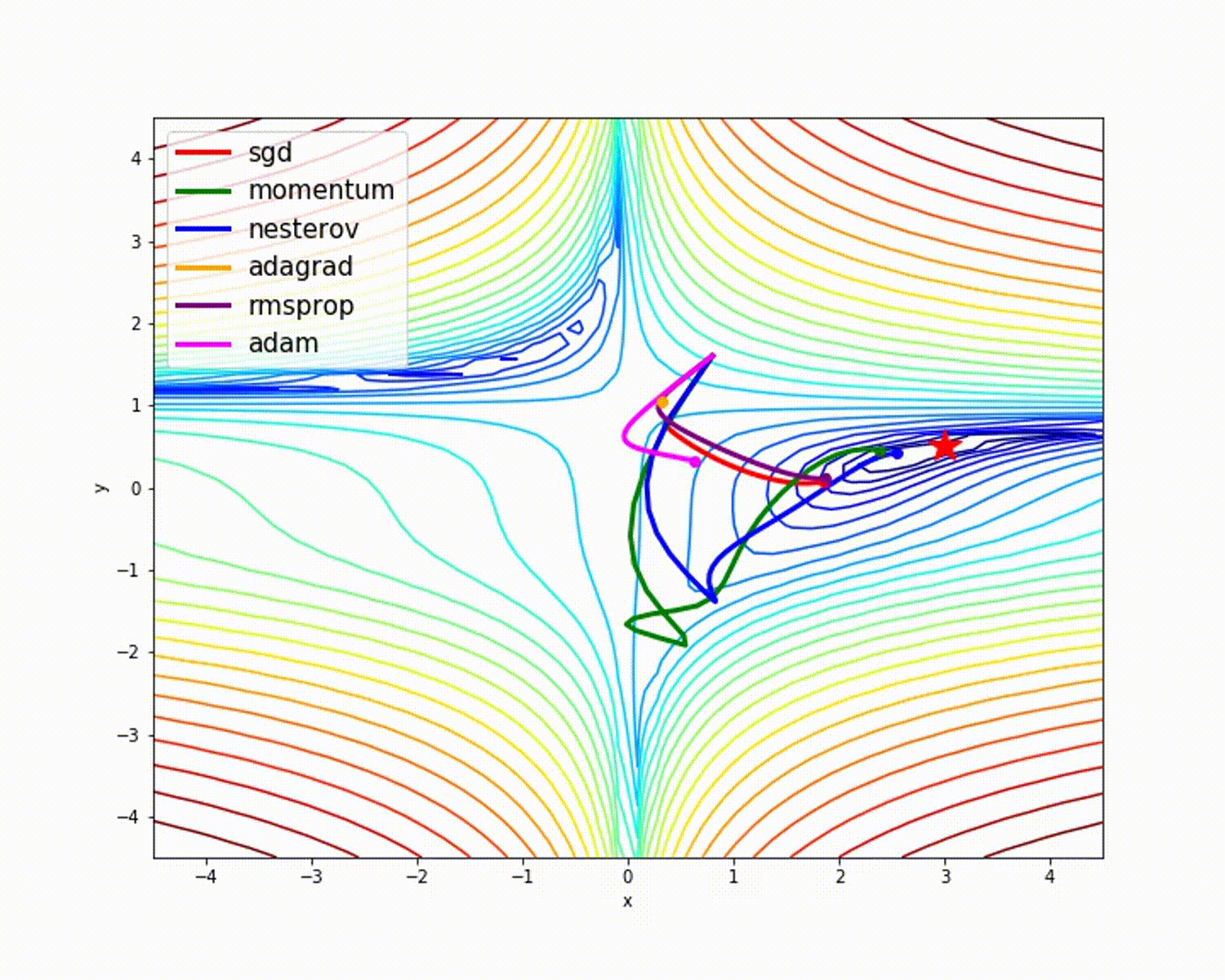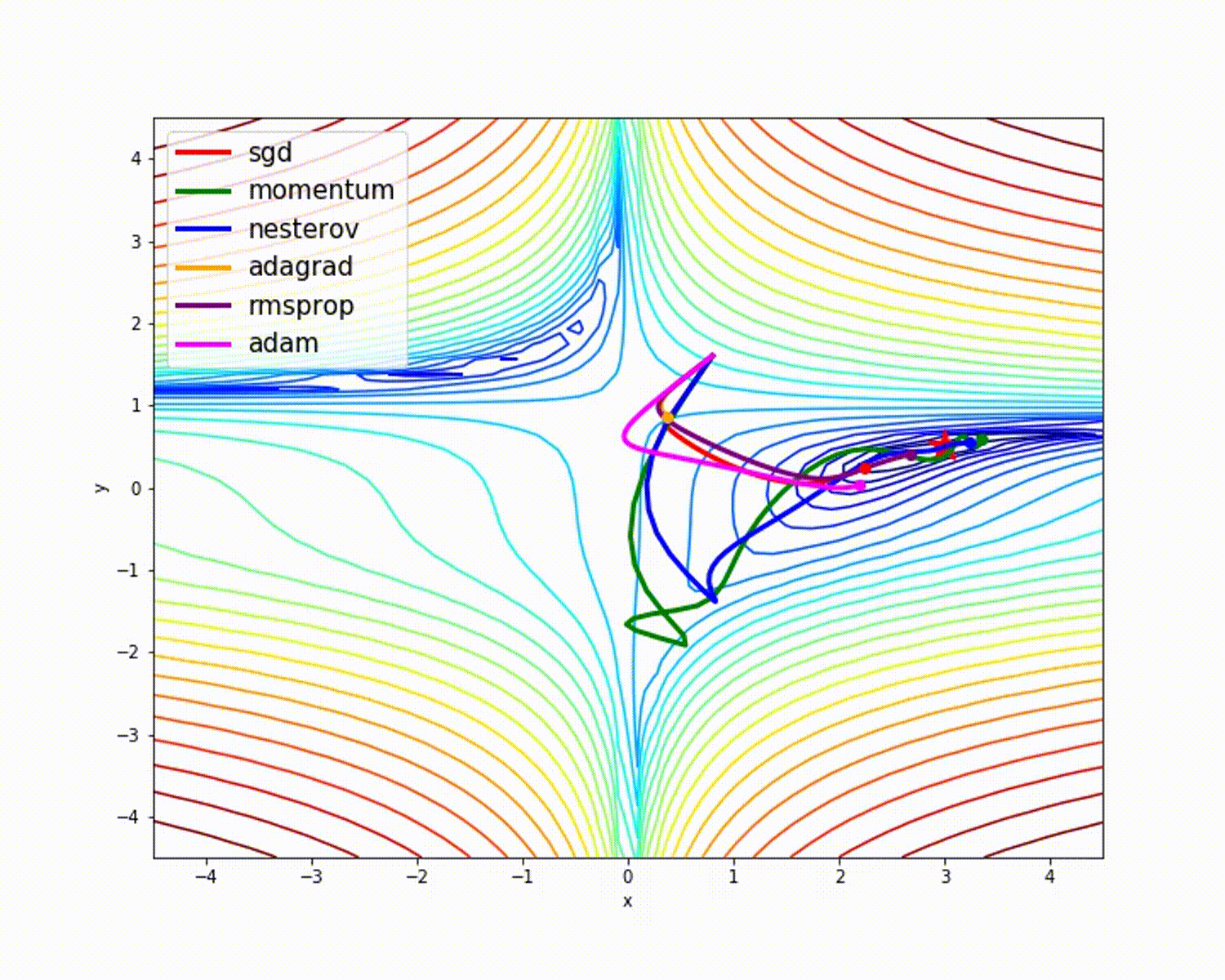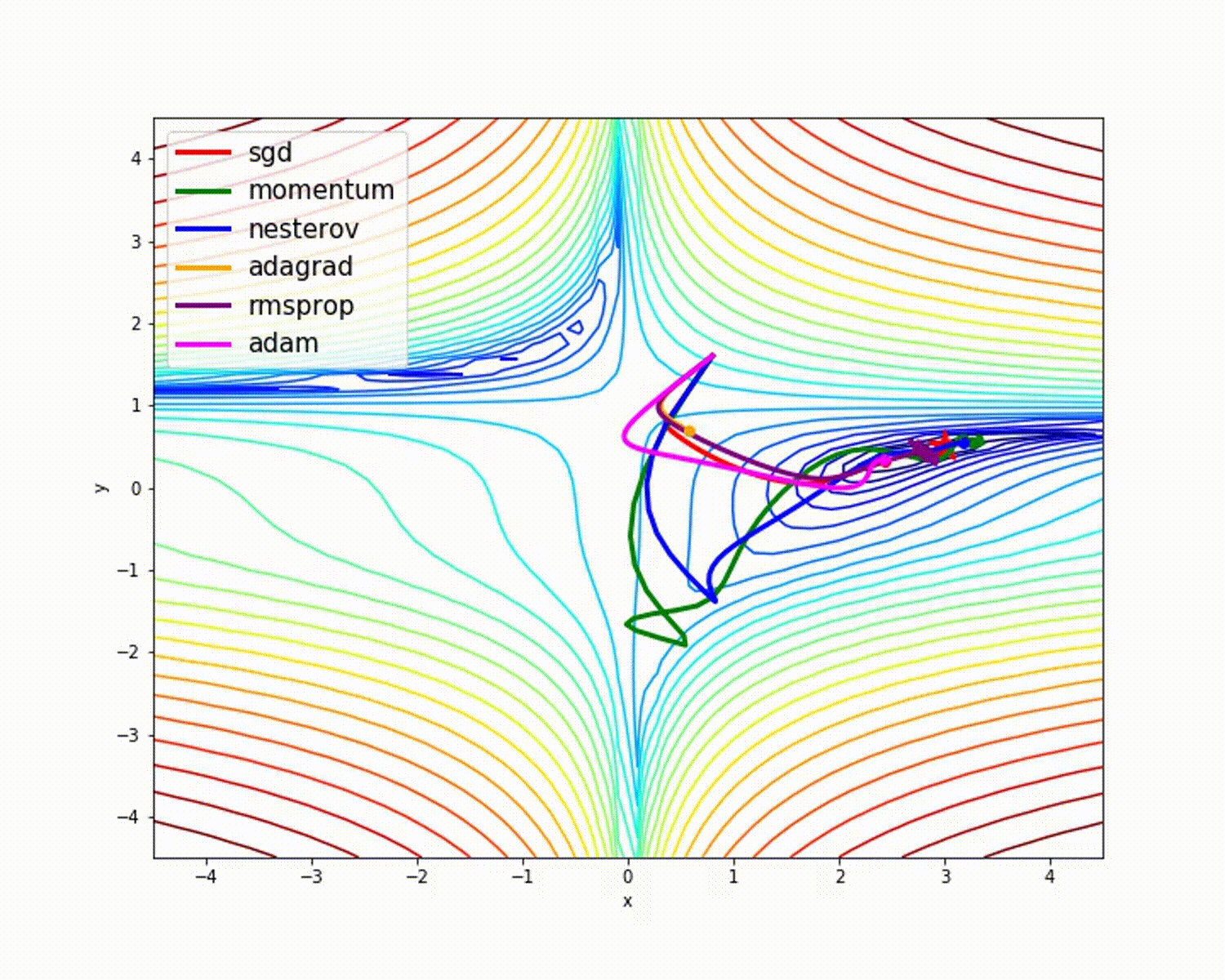











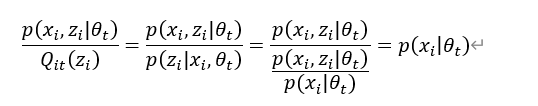




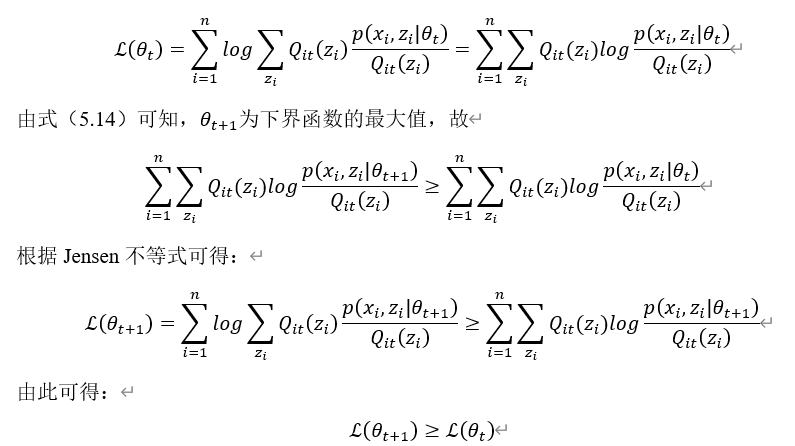









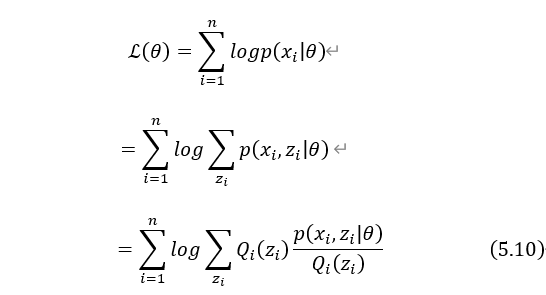
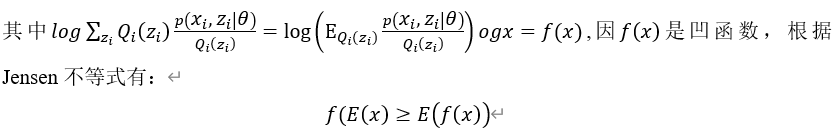
















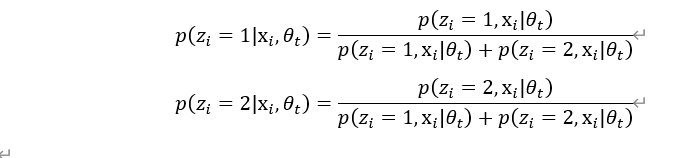


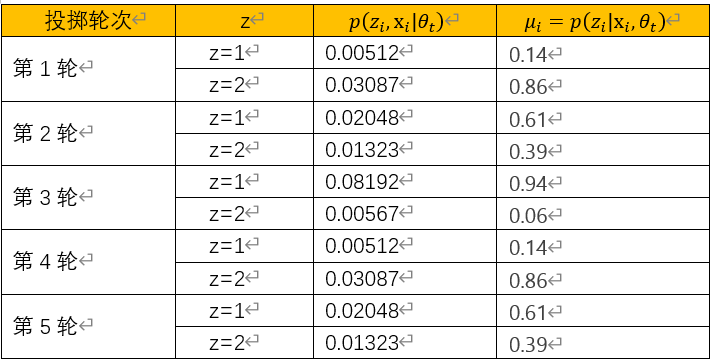









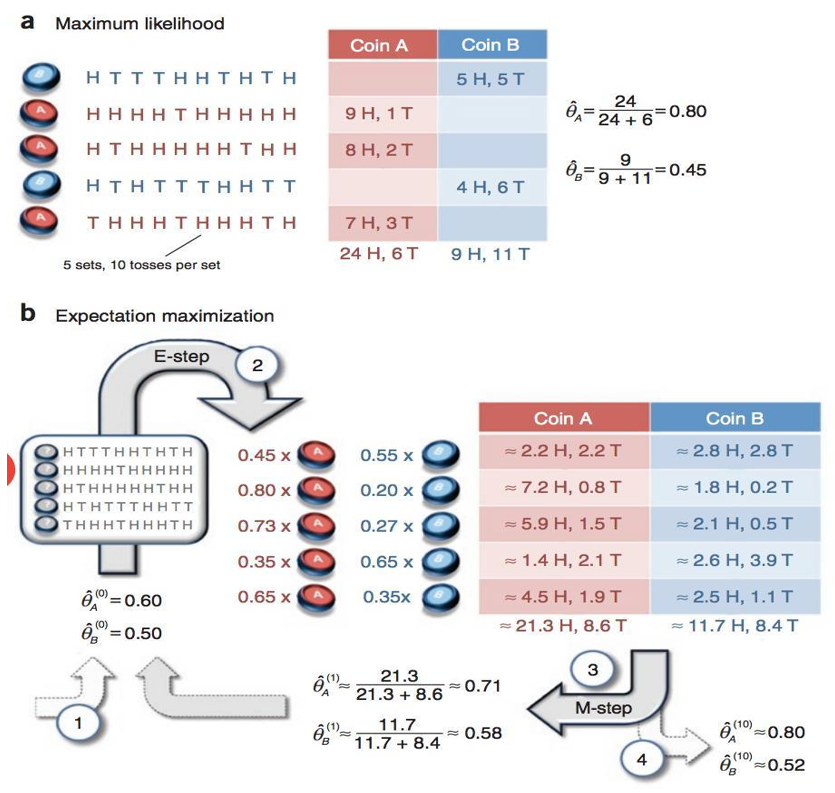
![x_1=[1,3,7,4],x_2=[5,2,9,8]](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_dd840113e7c03d2b8b98de86afd6350b.gif)






