1.机器学习一般流程
机器学习、深度学习的一般流程:
(1)分析业务需求
(2)确定数据源
(3)构建数据处理管道(pipeline)
(4)构建模型
(5)训练模型
(6)评估、优化模型
其中构建数据处理管道,在整个过程中,从时间上来说往往占60%左右,面对大数据其挑战更大。如何解决质量问题?如何解决内存瓶颈问题?如何解决处理效率问题等等。
接下来我们重点介绍如何使用TensorFlow2提供的tf.data工具有效构建数据流。
2.为何要构建数据管道?
使用tf.data API,我们可以使用简单的代码来构建复杂的输入 pipeline。
实现从从内存读取数据、从分布式文件系统中读取数据、进行预处理、合成为 batch、训练中使用数据集等。使用 tf.data API 可以轻松处理大量数据、不同的数据格式以及复杂的转换。
如果数据比较小,我们可以一次性处理后直接加入内存就可以了;但如果数据比较大,而且在数据训练过程中还需要一些动态的处理方法,如分批处理、添加数据增强方法、数据采样等等,此时,通过构建一个数据流就显得非常必要。
数据流可有效提高我们管理数据得效率,此外还可以帮助我们解耦数据的预处理和数据执行的过程,能够帮我们更高效的应用硬件资源,例如当分布式训练的时候,一个好的数据流能够帮我们高效的分发数据到不同的硬件上,从而提高整体的训练效率。
一个合理的数据流,能够让你模型训练更加的高效。数据流的本质就是 ETL。一般来说,数据流由三部分组成,具体如下:
(1)抽取、初始化源数据 (E:即Extract)
(2)添加各种预处理过程 (T: 即Transform)
(3)遍历数据流,把大数据导入模型、训练数据等 (L:Load)
在 Tensorflow2里,我们使用 tf.data 来构建数据管道。
3.tf.data简介
tf.data是TensorFlow提供的构建数据管道的一个工具,与PyTorch的utils.data类似,使用tf.data构建数据集(Dataset),构建和管理数据管道非常方便,它提供了很多操作,如:
shuffle、repeat、map、batch、padded_batch、prefetch等等,这些操作功能很实用,但使用的顺序是有讲究的,如果次序不当,将严重影响数据流的效率和质量,这些操作的顺利大致为:
(1)map->shuffle -> repeat -> map(parse) -> batch -> prefetch ;
(2)有些 map 操作放在 batch 前,有些 map 操作放在 batch 后;
(3)尽量把进行数据过滤和采样放数据流的前面,以提高后续处理效率;
(4)使用 AUTOTUNE 来设置并行执行的数量,不要去手动调节;
(5)使用 cache / interleave / prefetch 这些空间换时间的操作。
为便于更好理解这些操作,通过以下示例进行具体说明。
3.1 生成数据集
这里以手工创建一个非常简单的数据集,该数据包含10个样本,每个样本对应一个标签。
|
1 2 3 4 5 6 7 8 9 10 11 |
import numpy as np import tensorflow as tf data = np.array([0.1, 0.4, 0.6, 0.2, 0.8, 0.8, 0.4, 0.9, 0.3, 0.2]) #其中大于0.5的样本为正样本,即标签记为1,否则为0 label = np.array([0, 0, 1, 0, 1, 1, 0, 1, 0, 0]) #可以通过tf.data.Dataset.from_tensor_slices建立数据集 dataset = tf.data.Dataset.from_tensor_slices((data, label)) for x,y in dataset: print("[{},{}]".format(x.numpy(),y.numpy())) |
运行结果:
[0.1,0]
[0.4,0]
[0.6,1]
[0.2,0]
[0.8,1]
[0.8,1]
[0.4,0]
[0.9,1]
[0.3,0]
[0.2,0]
3.2 map
map对dataset中每个元素做出来,这里每个元素为[x,y],函数为one-hot
该函数把标签转换为one-hot编码。
介绍map()这一核心函数。该函数的输入参数map_func应为一个函数,在该函数中实现我们需要的对数据的变换。
具体应用场景如图片加载、数据增强、标签one hot化等。下面以one hot化和添加噪声为例具体说明。
one hot化的函数实现如下
|
1 2 3 4 5 6 7 8 9 |
def one_hot(x, y): if y == 0: return x, np.array([1, 0]) else: return x, np.array([0, 1]) dataset = dataset.map(one_hot) for x,y in dataset_one_hot: print("[{},{}]".format(x.numpy(),y.numpy())) |
运行结果
[0.1,[1 0]]
[0.4,[1 0]]
[0.6,[0 1]]
[0.2,[1 0]]
[0.8,[0 1]]
[0.8,[0 1]]
[0.4,[1 0]]
[0.9,[0 1]]
[0.3,[1 0]]
[0.2,[1 0]]
3.3 shuffle
shuffle()是随机打乱样本次序,参数buffer_size建议设为样本数量,过大会浪费内存空间,过小会导致打乱不充分。
|
1 2 3 |
dataset1 = dataset.shuffle(buffer_size=10) for x,y in dataset1: print("[{},{}]".format(x.numpy(),y.numpy())) |
运行结果
[0.6,[0 1]]
[0.2,[1 0]]
[0.3,[1 0]]
[0.8,[0 1]]
[0.4,[1 0]]
[0.8,[0 1]]
[0.2,[1 0]]
[0.4,[1 0]]
[0.1,[1 0]]
[0.9,[0 1]]
3.4 repeat
使用repeat方法,repeat的功能就是将整个序列或数据集重复多次, 完成整个数据集的一次训练是一个epoch,使用repeat(5)就可以将之变成5个epoch 如果直接调用repeat()的话,生成的序列就会无限重复下去,没有结束,因此也不会抛出tf.errors.OutOfRangeError异常。
|
1 2 3 |
dataset_repeat = dataset1.repeat(2) for x,y in dataset_repeat: print("[{},{}]".format(x.numpy(),y.numpy())) |
运行结果
[0.8,[0 1]]
[0.8,[0 1]]
[0.1,[1 0]]
[0.9,[0 1]]
[0.2,[1 0]]
[0.2,[1 0]]
[0.4,[1 0]]
[0.3,[1 0]]
[0.6,[0 1]]
[0.4,[1 0]]
[0.4,[1 0]]
[0.2,[1 0]]
[0.4,[1 0]]
[0.3,[1 0]]
[0.8,[0 1]]
[0.2,[1 0]]
[0.8,[0 1]]
[0.9,[0 1]]
[0.6,[0 1]]
[0.1,[1 0]]
3.5 batch
batch()是使数据集一次获取多个样本
|
1 2 3 4 |
# batch()是使迭代器一次获取多个样本 dataset_batch =dataset_repeat.batch(batch_size=4) for x,y in dataset_batch: print("[{},{}]".format(x.numpy(),y.numpy())) |
运行结果
[[0.4 0.3 0.6 0.2],[[1 0]
[1 0]
[0 1]
[1 0]]]
[[0.4 0.2 0.8 0.9],[[1 0]
[1 0]
[0 1]
[0 1]]]
[[0.8 0.1 0.6 0.9],[[0 1]
[1 0]
[0 1]
[0 1]]]
[[0.2 0.2 0.4 0.1],[[1 0]
[1 0]
[1 0]
[1 0]]]
[[0.3 0.8 0.8 0.4],[[1 0]
[0 1]
[0 1]
[1 0]]]
3.6map
map()函数,该函数的输入参数map_func应为一个函数,在该函数中实现我们需要的对数据的变换。具体应用场景如图片加载、数据增强、标签one hot化等。
对数据进行固定形式上的变化,可将函数直接作为参数输入。但是,包含随机信息的数据变化则需要tf.py_function辅助实现,
如数据增强中数据添加随机噪声、图像的随机翻转都属于包含随机信息。
|
1 2 3 4 5 6 |
def add_noise(x, y): x += np.random.normal(0.0, 1.0) return x, y dataset_add_noise = dataset.map(lambda x, y: tf.py_function(add_noise, inp=[x, y], Tout=[tf.float64, tf.int32])) for x,y in dataset_add_noise: print("[{},{}]".format(x.numpy(),y.numpy())) |
运行结果
[[1.5635917 1.6635917 2.2635917 2.0635917],[[1 0]
[1 0]
[0 1]
[0 1]]]
[[1.29330552 0.89330552 1.39330552 0.79330552],[[0 1]
[1 0]
[0 1]
[1 0]]]
[[-0.04628853 -0.24628853 -0.04628853 -0.24628853],[[1 0]
[1 0]
[1 0]
[1 0]]]
[[-0.46844772 -0.96844772 -1.16844772 -0.66844772],[[0 1]
[1 0]
[1 0]
[0 1]]]
[[0.40181042 0.20181042 0.80181042 0.90181042],[[1 0]
[1 0]
[0 1]
[0 1]]]
在map()函数中,还有个很重要的参数num_parallel_calls,可以将数据加载与变换过程并行到多个CPU线程上。由于python语言本身的全局解释锁,想要实现真正的并行计算是非常困难的,所以这个参数实际上非常实用,通常的使用情景是网络训练时,GPU做模型运算的同时CPU加载数据。 还可以直接设置num_parallel_calls=tf.data.experimental.AUTOTUNE,这样会自动设置为最大的可用线程数,可充分利用机器算资源。
|
1 2 |
AUTOTUNE = tf.data.experimental.AUTOTUNE dataset_add_noise1 = dataset.map(lambda x, y: tf.py_function(add_noise, inp=[x, y], Tout=[tf.float64, tf.int32]),num_parallel_calls=AUTOTUNE) |
3.7 prefetch
prefetch(buffer_size)创建一个Dataset,从源数据集中预提取元素的,注意:examples.prefetch(2) 将预取2个元素(2个示例),
而examples.batch(20).prefetch(2) 将预取2个元素(2个批次,每个20个示例),buffer_size 表示预取时将缓冲的最大元素数,返回 Dataset。
使用prefetch可有效使用读取数据与模型处理之间松耦合。如下图所示
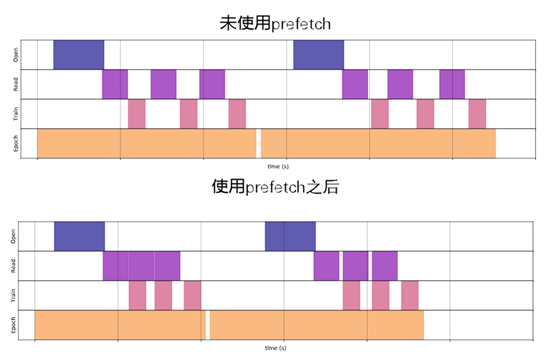
从上图可以看出,使用prefetch函数之后,读取数据与训练数据就可并发处理了,这就大大提升数据处理效率。
4.tf.data读取输入数据
tf.data的架构如下图所示:

从上图可知,Dataset是一个基类,这个类可实例化成迭代器(Iterator),
4.1 Dataset类
Dataset类下有多个子类,常见的有TextLineDataset、tf.data.FixedLengthRecordDataset、TFRecordDataset等,可用使用这些Dateset的子类获取数据,此外,Dataset还有很多方法,如from_tensor_slices、list_files、map、batch、repeat等等,Dataset的这些方法或子类通常用来读取或处理数据,当使用场景有些不同,tf.data常见的读取数据方式有以下几种:
(1)直接从内存中读取(如NumPy数据),tf.data.Dataset.from_tensor_slices()
(2)使用一个 python 生成器 (generator) 初始化,从生成器中读取数据可以使用
tf.data.Dataset.from_generator()
(3)从 TFrecords格式文件读取数据, 可使用tf.data.TFRecordDataset()
(4)读取文本数据,可使用tf.data.TextLineDataset()
(5)从二进制文件读取数据,可用tf.data.FixedLengthRecordDataset()
(6)读取cvs数据,可使用tf.data.experimental.make_csv_dataset()
(7)从文件集中读取数据,可使用tf.data.Dataset.list_files()
4.2对象Iterator
Iterator是Dataset中迭代方法的实例化,主要对数据进行访问,包括四种迭代方法,单次、可初始化、可重新初始化、可馈送等,可实现对数据集中元素的快速迭代,供模型训练使用。