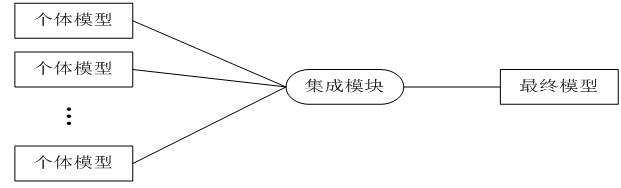
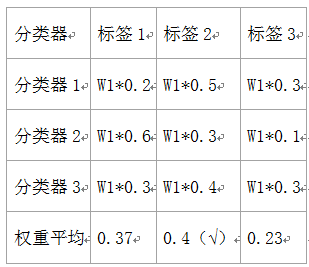
第13章、神经网络
13.1简介
神经网络是一门重要的机器学习技术。它是目前最火热的研究方向--深度学习的基础。学习神经网络不仅可以让你掌握一门强大的机器学习方法,同时也可以更好地帮助你理解深度学习技术。
目前,深度学习(Deep Learning,简称DL)在人工智能领域可谓是大红大紫,现在不只是互联网、人工智能,在教育、医疗、智慧城市、出行、司法、安全、金融等众多领域,都能反映出深度学习引起巨大变化。要学习深度学习,首先要熟悉深度学习的源头--神经网络(Neural Networks,简称NN)。又称为人工神经网络(Artificial Neural Networks,简称ANN)。
神经网络最早是人工智能领域的一种算法或者说是模型,目前神经网络已经发展成为一类多学科交叉的学科领域,它也随着深度学习取得的进展重新受到重视和推崇。
其实,神经网络最为一种算法模型很早就已经开始研究了,最早可以回溯到1946年,到现在近70年了。一路走来,经历了很多波折,其中比较代表性的是其三次大起大落:
1)20世纪40年代到60年代,期间人们陆续发明了第一款的感知神经网络软件和聊天软件,证明了数学定理。不过,很快到了70年代后期,人们发现过去的理论和模型,只能解决一些非常简单的问题,很快人工智能进入了第一次的冬天。
2)20世纪80年代到90年代,随着1982年Hopfield神经网络和BT训练算法的提出,大家发现人工智能的春天又来了。80年代又兴起一拨人工智能的热潮,包括语音识别、语音翻译计划,以及日本提出的第五代计算机。不过,到了90年代后期,人们发现这种东西离我们的实际生活还很遥远。大家都有印象IBM在90年代的时候提出了一款语音听写的软件叫IBM Viavoice,在演示当中效果不错,但是真正用的时候却很难使用。因此,在2000年左右第二次人工智能的浪潮又破灭了。
3)直到2006年,随着2006年Hinton提出的深度学习的技术,以及在图像、语音识别以及其他领域内取得的一些成功,大家认为经过了两次起伏,神经网络、深度学习开始进入了真正爆发的前夜。
我们可以通过一个图来总结这三次浪潮:
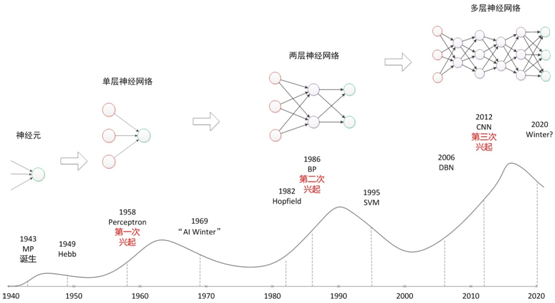
本图片选自:http://www.cnblogs.com/subconscious/p/5058741.html
图中的起伏线,我觉得表达人们对神经网络情感的起落,但从技术上角度来说,应该是条递增曲线。
本章以神经网络为主,着重介绍一些相关的基础知识,然后在此基础上引出深度学习的基本概念。
13.2神经元
1943年,心理学家McCulloch和数学家Pitts参考了生物神经元的结构(请看下图),发表了抽象的神经元模型MP。
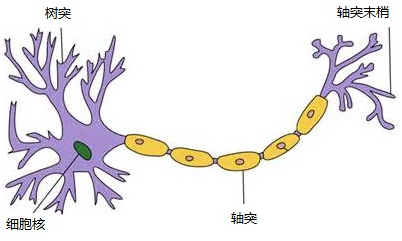
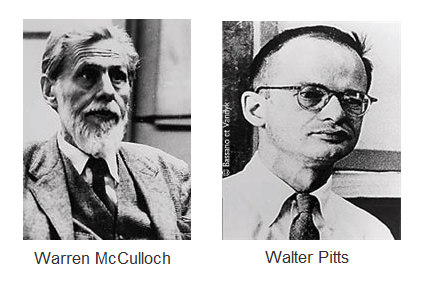
一个神经元模型包含输入,输出与计算功能的模型。下图是一个典型的神经元模型:包含有3个输入,1个输出,以及2个计算功能(一个求和,一个函数f)。

其间的箭头线称为“连接”。每个连接上有一个“权值”,如上图〖的w〗_i,权重是最重要的东西。一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好。
我们使用x来表示输入,用w来表示权值。一个表示连接的有向箭头可以这样理解:在初端,传递的信号大小仍然是x,端中间有加权参数w,经过这个加权后的信号会变成x*w,因此在连接的末端,信号的大小就变成了x*w。
输出y是在输入和权值的线性加权和叠加了一个函数f的值。在MP模型里,函数f又称为激活函数。
从机器学习的角度,我们习惯把已知的属性称之为特征,未知的属性称之为目标。假设特征与目标之间确实是线性关系,并且我们已经得到表示这个关系的权值w1,w2,w3。那么,我们就可以通过神经元模型预测新样本的目标。
11.3 单层神经网络(感知器)
1958年,计算科学家Rosenblatt提出了由两层神经元组成的神经网络。他取名为“感知器”(Perceptron)感知器是当时首个可以学习的人工神经网络。Rosenblatt现场演示了其学习识别简单图像的过程,在当时的社会引起了轰动。
人们认为已经发现了智能的奥秘,许多学者和科研机构纷纷投入到神经网络的研究中。美国军方大力资助了神经网络的研究,并认为神经网络比“原子弹工程”更重要。这段时间直到1969年才结束,这个时期可以看作神经网络的第一次高潮。
单层神经网络在原来MP模型的“输入”位置添加神经元节点,标志其为“输入单元”。其余不变,于是我们就有了下图:
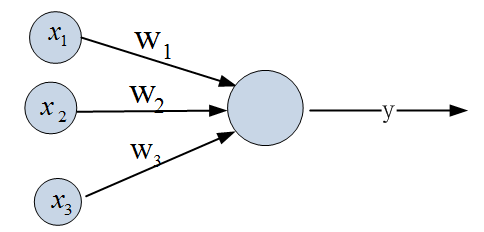
在“感知器”中,有两个层次。分别是输入层和输出层。输入层里的“输入单元”只负责传输数据,不做计算。输出层里的“输出单元”则需要对前面一层的输入进行计算。
假如我们要预测的目标不再是一个值,而是一个向量,例如[0,1]。那么可以在输出层再增加一个“输出单元”。
下图显示了带有两个输出单元的单层神经网络,其中输出单元f1的计算公式如下图。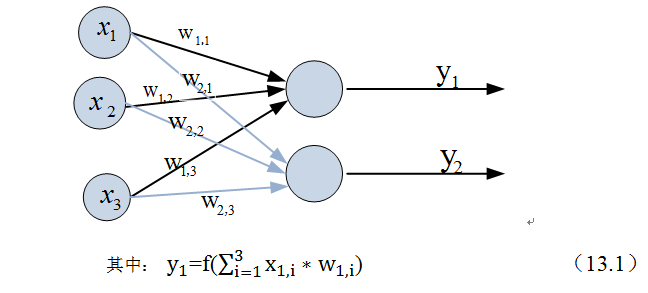

f(W * X) = Y;
这个公式就是神经网络中从前一层计算后一层的矩阵运算。其中f是激活函数,激活函数一般特点是:
1)非线性:为提高模型的学习能力,如果是线性,那么再多层都相当于只有两层效果。
2)可微性:基于梯度的模型最优化方法。
3)单调性:保证模型简单
与神经元模型不同,感知器中的权值是通过训练得到的,它类似一个逻辑回归模型,可以做线性分类任务,但感知器只能做简单的线性分类任务。不过,当时的人们并没有认识到这一点,感知器刚出来一段时间,人们热情高涨,以为找到了打开人工智能的钥匙,当人工智能领域的巨擘Minsky指出其局限性时,事态就发生了变化。
Minsky在1969年出版了一本叫《Perceptron》的书,里面用详细的数学证明了感知器的弱点,尤其是感知器对XOR(异或)这样的简单分类任务都无法解决。如果将计算层增加到两层,计算量则过大,而且没有有效的学习算法。所以,他认为研究更深层的网络是没有价值的。或许由于Minsky的巨大影响力以及书中呈现的悲观态度,让很多学者和实验室纷纷放弃了神经网络的研究,神经网络的研究陷入了第一次低谷。
13.4 两层神经网络(多层感知器)
Minsky说过单层神经网络无法解决异或问题。但是当增加一个计算层以后,两层神经网络不仅可以解决异或问题,而且具有非常好的非线性分类效果。不过两层神经网络的计算是一个问题,没有一个较好的解法。
1986年,Hinton和Rumelhar等人提出了反向传播(Backpropagation,BP)算法,解决了两层神经网络所需要的复杂计算量问题,从而带动了业界使用两层神经网络研究的热潮。目前,大量的教授神经网络的教材,都是重点介绍两层(带一个隐藏层)神经网络的内容。

两层神经网络除了包含一个输入层,一个输出层以外,还增加了一个中间层。此时,中间层(又称为隐含层)和输出层都是计算层,如下图:

现在,我们的权值矩阵增加到了两个,我们用上标来区分不同层次之间的变量。

由此可见,使用矩阵运算来表达是很简洁的,而且也不会受到节点数增多的影响(无论有多少节点参与运算,乘法两端都只有一个变量)。因此神经网络的教程中大量使用矩阵运算来描述。
不知大家是否注意到,到目前为止,我们对神经网络的结构图的讨论中都没有提到偏置节点。事实上,这些节点一般默认存在的。它本质上是一个只含有存储功能,且存储值永远为1的单元。在神经网络的每个层次中,除了输出层以外,都会含有这样一个偏置单元。正如线性回归模型与逻辑回归模型中的一样。
偏置单元与后一层的所有节点都有连接,我们设这些参数值为向量b,称之为偏置。如下图:
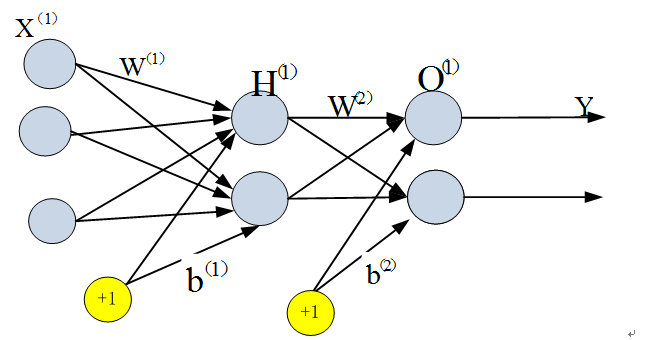
可以看出,偏置节点很好认,因为其没有输入(前一层中没有箭头指向它)。有些神经网络的结构图中会把偏置节点明显画出来,有些不会。一般情况下,我们都不会明确画出偏置节点。
在考虑了偏置以后的一个神经网络的矩阵运算如下:

事实上,神经网络的本质就是通过参数与激活函数来拟合特征与目标之间的真实函数关系。
前面我们讲了,单层网络只能做线性分类任务,无法对非线性数据集分类。两层神经网络能对非线性数据集分类吗?可以的。
与单层神经网络不同。理论证明,两层神经网络可以无限逼近任意连续函数。那它是如何做到的呢?
从公式(13.4)、(13.5)我们可以看出,从输入层到隐藏层时,为矩阵和向量相乘,本质上就是对向量的坐标空间进行一个变换,使其可以被线性分类,然后输出层的决策分界划出了一个线性分类分界线,对其进行分类。
这里需要强调一下,如果只引入隐含层无法保证可以处理非线性数据。除了增加隐含层,还一个关键要素是隐含层神经元引入激活函数,而且这些激活函数必须非线性。如果这些激活函数是线性,那么可以证明(具体证明大家可参考黄安埠编写的《深入浅出深度学习》),即使增加了隐含层,那么多层神经网络,其效果与单层神经网络没有区别,即,不管增加多少层隐含层,也只能处理线性数据,无法处理非线性数据集。
在设计一个神经网络时,输入层的节点数需要与特征的维度匹配,输出层的节点数要与目标的维度匹配。而中间层的节点数,却是由设计者指定的。节点数设置是否合理,会影响到整个模型的效果。
我们该如何决定隐含层的节点数呢?目前业界没有完善的理论来指导这个决策。一般是根据经验来设置。较好的方法就是预先设定几个可选值,通过切换这几个值来看整个模型的预测效果,最后选择效果较好的那个。
13.5 前向传播与反向传播详解
以下我们通过一个实例来具体说明神经网络的前向传播与反向传播的实现方法,理解神经网络的信息传播(包括误差传播)对理解深度学习中很多技术非常有帮助。如深度学习中梯度消失、梯度爆炸等原因将一目了然。
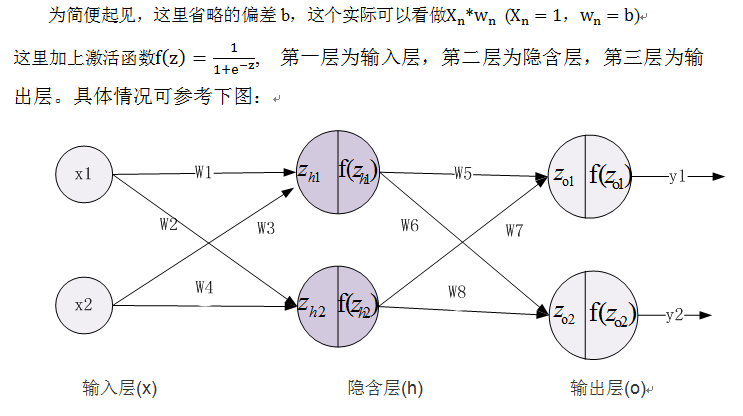
13.5.1 前向传播
在神经网络中,前向传播是利用当前的权重参数和输入数据,从下到上(即从输入层到输出层),求取预测结果,并利用预测结果与真实值求解损失函数的值。如下图:

具体步骤如下:
1、有输入层到隐含层

2、有隐含层到输出层

13.5.2 反向传播
在神经网络中,反向传播是利用前向传播求解的损失函数,从上到下(即从输出层到输入层),求解网络的参数梯度或新的参数值,经过前向和反向两个操作后,完成了一次迭代过程,如下图:
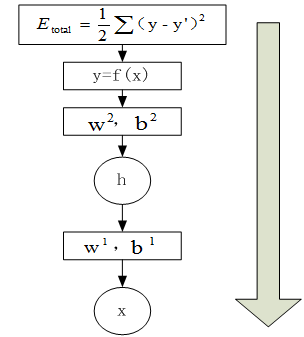
具体步骤如下:
1、计算总误差

2、由输出层到隐含层,假设我们需要分析权重参数w5对整个误差的影响,可以用整体误差对w5求偏导求出:这里利用微分中的链式法则,涉及过程包括:f(Z_O1)--->Z_O1----->W5
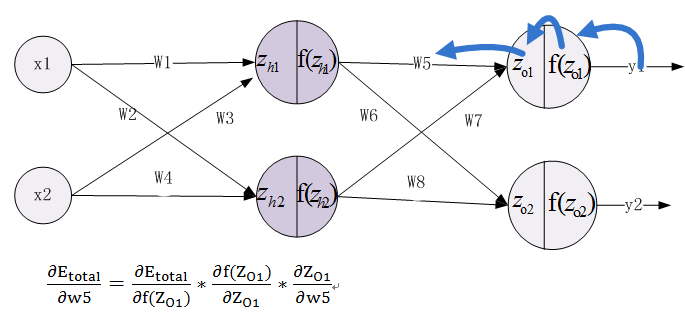
根据公式11.10--11.16,不难求出各部分的偏导数。
最后,调整后的权重为w5’,具体计算公式如下:
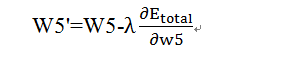
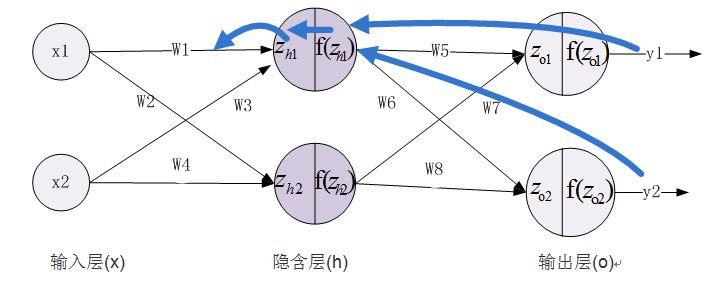
3、由隐含层到输入层,假设我们需要分析权重参数w1对整个误差的影响,可以用整体误差对w1求偏导求出,涉及过程包括:f(Z_h1)--->Z_h1----->W1,不过而f(Z_h1)会接受E_O1和E_O2两个地方传来的误差,所以这个地方两个都要计算。

13.6 两层神经网络的优势与局限
两层神经网络在多个地方的应用说明了其效用与价值。10年前困扰神经网络界的异或问题被轻松解决。神经网络在这个时候,已经可以发力于语音识别,图像识别,自动驾驶等多个领域。
历史总是惊人的相似,神经网络的学者们再次登上了《纽约时报》的专访。人们认为神经网络可以解决许多问题。就连娱乐界都开始受到了影响,当年的《终结者》电影中的阿诺都赶时髦地说一句:我的CPU是一个神经网络处理器,一个会学习的计算机。
但是神经网络仍然存在若干的问题:尽管使用了BP算法,一次神经网络的训练仍然耗时太久,而且困扰训练优化的一个问题就是局部最优解问题,这使得神经网络的优化较为困难。同时,隐藏层的节点数需要调参,这使得使用不太方便,工程和研究人员对此多有抱怨。
90年代中期,由Vapnik等人发明的SVM(Support Vector Machines,支持向量机)算法诞生,很快就在若干个方面体现出了对比神经网络的优势:无需调参;高效;全局最优解。基于以上种种理由,SVM迅速打败了神经网络算法成为主流。神经网络的研究再次陷入低谷。
 Vladimir Vapnik
Vladimir Vapnik
11.7 多层神经网络与深度学习
我们延续两层神经网络的方式来设计一个多层神经网络。
在两层神经网络的输出层后面,继续添加层次。原来的输出层变成中间层,新加的层次成为新的输出层。所以可以得到下图:
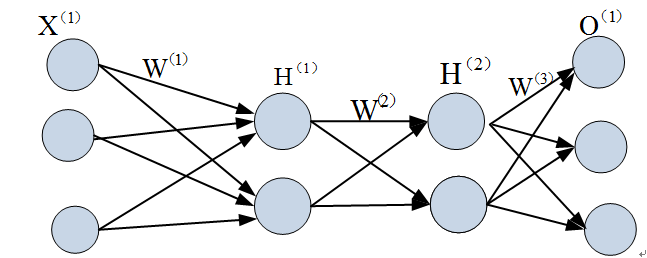
当然,我们也可在这个基础继续添加新层、最终得到一个几十、几百、甚至上千层的神经网络。随着层数的不断增多,也出现很多新问题,如维度爆炸、过拟合、梯度消失、梯度爆炸等等,对这些新出现的问题,该如何解决?这里就展开来说,后面我们介绍深度学习时,会涉及到。
2006年,Hinton在《Science》和相关期刊上发表了论文,首次提出了“深度信念网络”的概念。与传统的训练方式不同,“深度信念网络”有一个“预训练”(pre-training)的过程,这可以方便的让神经网络中的权值找到一个接近最优解的值,之后再使用“微调”(fine-tuning)技术来对整个网络进行优化训练。这两个技术的运用大幅度减少了训练多层神经网络的时间。他给多层神经网络相关的学习方法赋予了一个新名词--“深度学习”。
很快,深度学习在语音识别领域暂露头角。接着,2012年,深度学习技术又在图像识别领域大展拳脚。Hinton与他的学生在ImageNet竞赛中,用多层的卷积神经网络成功地对包含一千类别的一百万张图片进行了训练,取得了分类错误率15%的好成绩,这个成绩比第二名高了近11个百分点,充分证明了多层神经网络识别效果的优越性。

深度学习有很多方法,如卷积神经网络(CNN),循环神经网络(RNN)等,这些神经网络涉及内容比较多,这里就不展开说了,后面在介绍深度学习内容时将详细介绍。这里我们只涉及全连接的深度学习。
增加更多的层次有什么好处?更深入的表示特征,以及更强的函数模拟能力。
更深入的表示特征可以这样理解,随着网络的层数增加,每一层对于前一层次的抽象表示更深入。在神经网络中,每一层神经元学习到的是前一层神经元值的更抽象的表示。例如第一个隐藏层学习到的是“边缘”的特征,第二个隐藏层学习到的是由“边缘”组成的“形状”的特征,第三个隐藏层学习到的是由“形状”组成的“图案”的特征,最后的隐藏层学习到的是由“图案”组成的“目标”的特征。通过抽取更抽象的特征来对事物进行区分,从而获得更好的区分与分类能力。
关于逐层特征学习的例子,可以参考下图:

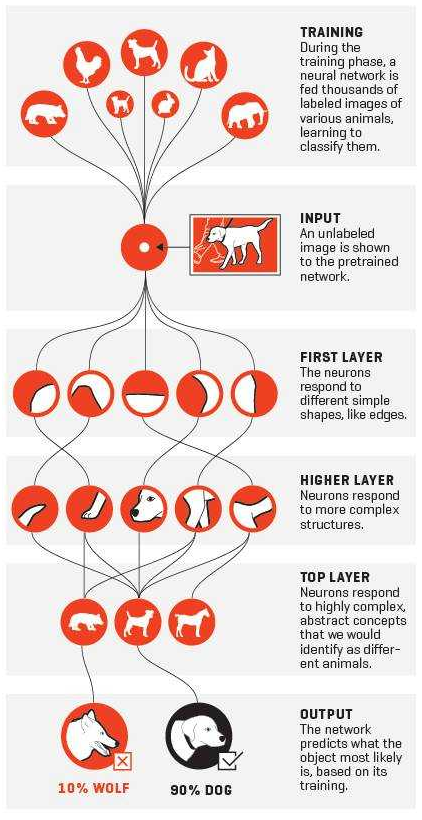
这一个特征不断抽象的过程:像素==>边==>器官==>人脸
这种对特征逐层抽象的思想,在深度学习中非常普遍而且重要。以下是利用深度学习模型识别猫或狗的训练步骤:
13.8多层网络训练方法
在单层神经网络时,我们使用的激活函数符号函数,如sgn函数。到了两层神经网络时,我们使用的最多的是sigmoid函数。而到了多层神经网络时,通过一系列的研究发现,ReLU函数在训练多层神经网络时,更容易收敛,并且预测性能更好。因此,目前在深度学习中,最流行的非线性函数是ReLU函数。ReLU函数不是传统的非线性函数,而是分段线性函数。其表达式非常简单,就是y=max(x,0)。简而言之,在x大于0,输出就是输入,而在x小于0时,输出就保持为0。这种函数的设计启发来自于生物神经元对于激励的线性响应,以及当低于某个阈值后就不再响应的模拟。
在多层神经网络中,训练的主题仍然是优化和泛化。当使用足够强的计算芯片(例如GPU图形加速卡)时,梯度下降算法以及反向传播算法在多层神经网络中的训练中仍然工作的很好。目前学术界主要的研究既在于开发新的算法,也在于对这两个算法进行不断的优化,例如,增加了一种带动量因子(momentum)的梯度下降算法。
在深度学习中,泛化技术变的比以往更加的重要。这主要是因为神经网络的层数增加了,参数也增加了,表示能力大幅度增强,很容易出现过拟合现象。因此正则化技术就显得十分重要。目前,Dropout技术,以及数据扩容(Data-Augmentation)技术是目前使用的最多的正则化技术。
目前,深度神经网络在人工智能界占据统治地位。但凡有关人工智能的产业报道,必然离不开深度学习。神经网络界当下的四位引领者除了前文所说的Ng,Hinton以外,还有CNN的发明人Yann Lecun,以及《Deep Learning》的作者Bengio。

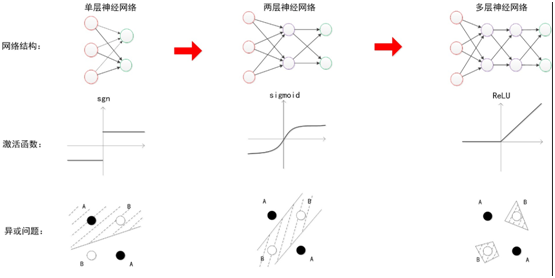
随着层数的不断增加,训练的方法也在不断变化,下图说明期间的一些主要变化:
13.9神经网络分类
神经网络其实是一个非常宽泛的称呼,它包括两类,一类是用计算机的方式去模拟人脑,这就是我们常说的ANN(人工神经网络),另一类是研究生物学上的神经网络,又叫生物神经网络。对于我们计算机人士而言,肯定是研究前者。神经网络大致分类,可参考下图:
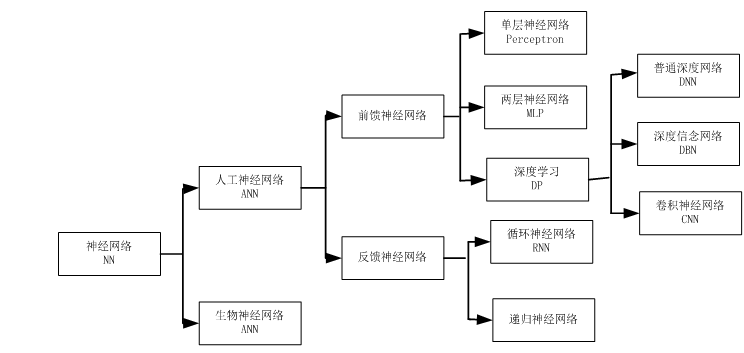
在人工神经网络之中,又分为前馈神经网络和反馈神经网络这两种。那么它们两者的区别是什么呢?这个其实在于它们的结构图。我们可以把结构图看作是一个有向图。其中神经元代表顶点,连接代表有向边。对于前馈神经网络中,这个有向图是没有回路的。你可以仔细观察本文中出现的所有神经网络的结构图,确认一下。而对于反馈神经网络中,结构图的有向图是有回路的。反馈神经网络也是一类重要的神经网络。其中Hopfield网络就是反馈神经网络。深度学习中的RNN也属于一种反馈神经网络。
具体到前馈神经网络中,就有了本文中所分别描述的三个网络:单层神经网络,双层神经网络,以及多层神经网络。深度学习中的CNN属于一种特殊的多层神经网络。另外,在一些Blog中和文献中看到的BP神经网络是什么?其实它们就是使用了反向传播BP算法的两层前馈神经网络。也是最普遍的一种两层神经网络。
参考:http://www.cnblogs.com/subconscious/p/5058741.html










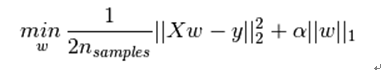
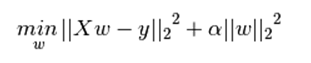
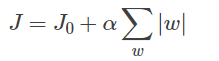

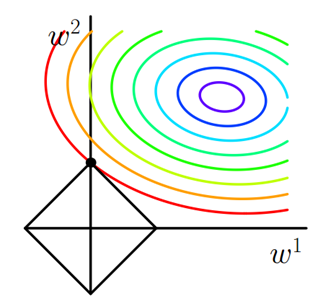













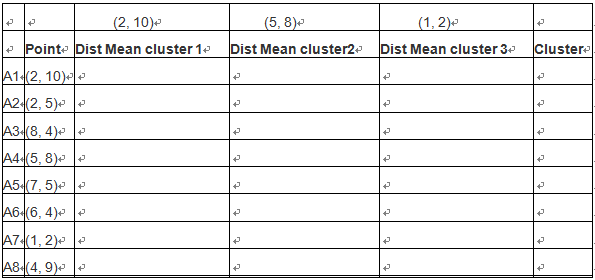
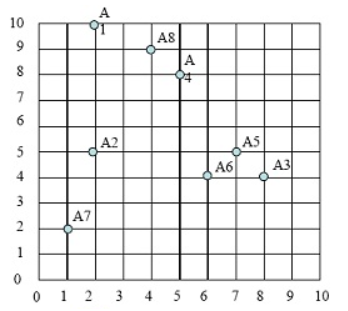

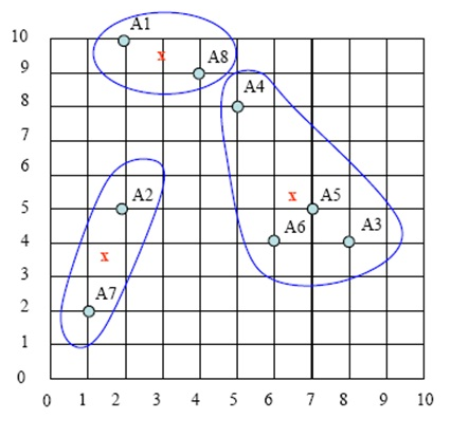 持续迭代,直到前后两次迭代不发生变化为止,如下:
持续迭代,直到前后两次迭代不发生变化为止,如下: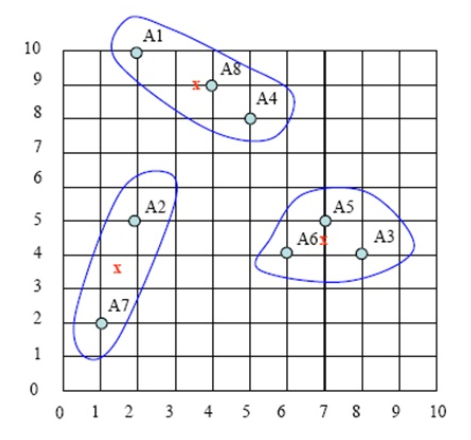
 " />
" />