第3章 数据处理
在介绍MySQL时,我们了解了其查询功能非常强大,既可单表查询、也可多表查询、还可以实现子查询等等,而且实现起来还非常方便,写几个SQL语句就可轻松搞定。假如某天你想参加大数据方面的竞赛,主办方给你的数据不是数据库的表,而是几个数据文件(这样的情况非常普遍),要求你基于这些数据文件(如文本文件、excel文件等)进行预测或分类等,此时你该如何处理呢?把这些文件导入数据库,然后用SQL进行处理?有时也是方法之一,但,假如主办方不提供数据库呢?实际也没关系!我们可以就数据文件进行处理、进行合并、聚合等操作,甚至可以比SQL做更多事情,如何处理呢?这就是本章将介绍的内容。
本章主要内容:
合并数据文件
旋转数据
新增指标
聚合数据
3.1 合并数据
在MySQL的多表查询章节中,我们介绍了两表关联问题,具体请看如下图形;
(图3-1 多表关联)
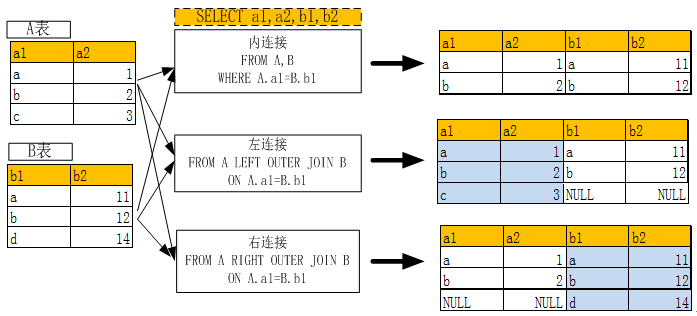
如果现在把表换成数据文件或数据集,该如何实现呢?Python中有类似方法,把连接的关键字有JION改为MERGE一下就可,其它稍作修改,具体请看下表:
(表3-2 两个DataFrame数据集关联格式表)
关联方式 关联语句

下面同时示例来说明以上命令的具体使用。
In [2]: import pandas as pd
In [3]: from pandas import DataFrame
In [4]: import MySQLdb
In [5]: df1=DataFrame({'key':['a','a','b','c','c'],'data1':range(5)},columns=['key','data1'])
In [6]: df2=DataFrame({'key':['a','b','d'],'data2':range(3)},columns=['key','data2'])
In [7]: df1
Out[7]:
key data1
0 a 0
1 a 1
2 b 2
3 c 3
4 c 4
In [8]: df2
Out[8]:
key data2
0 a 0
1 b 1
2 d 2
###内连接的几种方式
In [9]: df3=pd.merge(df1,df2,on='key')
In [10]: df4=pd.merge(df1,df2,on='key',how='inner')
In [11]: df5=pd.merge(df1,df2,left_on='key',right_on='key',how='inner')
In [12]: df5
Out[12]:
key data1 data2
0 a 0 0
1 a 1 0
2 b 2 1
###df1与df2左连接
In [13]: df_l=pd.merge(df1,df2,on='key',how='left')
In [14]: df_l
Out[14]:
key data1 data2
0 a 0 0.0
1 a 1 0.0
2 b 2 1.0
3 c 3 NaN
4 c 4 NaN
###df1与df2右连接
In [15]: df_r=pd.merge(df1,df2,on='key',how='right')
In [16]: df_r
Out[16]:
key data1 data2
0 a 0.0 0
1 a 1.0 0
2 b 2.0 1
3 d NaN 2
###df1与df2进行全连接
In [17]: df_a=pd.merge(df1,df2,on='key',how='outer')
In [18]: df_a
Out[18]:
key data1 data2
0 a 0.0 0.0
1 a 1.0 0.0
2 b 2.0 1.0
3 c 3.0 NaN
4 c 4.0 NaN
5 d NaN 2.0
两个集合连接以后,有些值可能为空或为NaN,NaN值有时计算不方便,我们可以把NaN修改为其它值,如为0值等,如果要修改或补充为0值,该如何操作呢?非常方便,利用DataFrame的fillna函数即可。其使用方法如下:
Out[20]:
key data1 data2
0 a 0.0 0.0
1 a 1.0 0.0
2 b 2.0 1.0
3 c 3.0 0.0
4 c 4.0 0.0
5 d 0.0 2.0
3.2 离散数据
上节我们介绍了有时便于数据分析,需要把两个或多个数据集合并在一起,这在大数据的分析或竞赛中是经常干的事。不过有时为便于分析,需要把一些连续性数据离散化或进行拆分,这也是数据分析常用方法,如对年龄字段,可能需转换成年龄段,这样可能更好地对数据的进行分类或预测,这种处理方式往往能提升分类或预测性能,这种方法又称为离散化或新增衍生指标等。这方面的实例在Spark中将介绍。
如何离散化连续性数据?在一般开发语言中,可以通过控制语句来实现,但如果分类较多时,这种方法不但繁琐,效率也比较低。在Pandas中是否有更好方法?如果有,又该如何实现呢?
pandas有现成方法,如cut或qcut等,不需要编写代码,至于如何使用还是通过实例来说明。
In [2]: import pandas as pd
In [3]: from pandas import DataFrame
In [4]: df9=DataFrame({'age':[21,25,30,32,36,40,45,50],'type':['1','2','1','2','1','1','2','2']},columns=['age','type'])
In [5]: level=[20,30,40,50] ##划分为(20,30],(30,40],(40,50]
In [6]: groups=['A','B','C'] ##对应标签为A,B,C
In [7]: df9['age_t']=pd.cut(df9['age'],level,labels=groups) ##新增字段为age_t
In [8]: df10=df9[['age','age_t','type']]
In [9]: df10
Out[9]:
age age_t type
0 21 A 1
1 25 A 2
2 30 A 1
3 32 B 2
4 36 B 1
5 40 B 1
6 45 C 2
7 50 C 2
对连续性字段进行离散化是机器学习常用方法,此外,对一些类型字段,如上例中type字段,含有1,2两种类型,实际上1,2两种类型是平等,它们只是代表不同类型,并无大小区别,如果在回归分析中如果用1、2代入算法中,则与业务含义就不相符了,对这种情况,我们该如何处理呢?
在机器学习中通常把这些分类变量或字段转换为“指标矩阵”或“哑变量矩阵”,具体做法就是,假设该字段或变量有k种取值(上例中type只有2中取值),则可派生出一个k列矩阵,矩阵值为0或1,0表示无对应分类,1表示有对应分类。我们可以编写程序实现,也可用Pandas中get_dummies函数来实现,具体实现请看以下示例。
In [11]: dummies
Out[11]:
type_1 type_2
0 1.0 0.0
1 0.0 1.0
2 1.0 0.0
3 0.0 1.0
4 1.0 0.0
5 1.0 0.0
6 0.0 1.0
7 0.0 1.0
In [12]: df10.join(dummies) ###通过位置索引与df10进行关联
Out[12]:
age age_t type type_1 type_2
0 21 A 1 1.0 0.0
1 25 A 2 0.0 1.0
2 30 A 1 1.0 0.0
3 32 B 2 0.0 1.0
4 36 B 1 1.0 0.0
5 40 B 1 1.0 0.0
6 45 C 2 0.0 1.0
7 50 C 2 0.0 1.0
【说明】
这种方法,在SparkML中有专门的算法--独热编码(OneHotEncoder),独热编码将标签指标映射为二值向量,其中最多一个单值。这种编码被用于将种类特征使用到需要连续特征的算法,如逻辑回归等。
3.3 行列旋转
我们平常看到的数据格式大多像数据库中的表,如购买图书的基本信息:
(表3-1 客户购买图书信息)
书名 书代码 购买客户 购买数量
这样的数据比较规范,比较适合于一般的统计分析。但如果我们欲依据这些数据来对客户进行推荐或计算客户的相似度,就需要把以上数据转换为如下格式:
(表3-2 客户购买图书的对应关系)
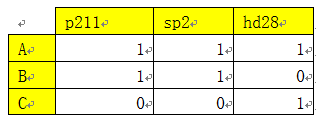
我们观察一下不难发现,把表3-1中书代码列旋转为行就得到表3-2数据。如何实现行列的互换呢?编码能实现,但比较麻烦,还好,pandas提供了现成的方法或函数,如stack、unstack、pivot_table函数等。以下以pivot_table为例说明具体实现。
In [2]: import pandas as pd
In [3]: from pandas import DataFrame
In [4]: df=DataFrame({'book_code':['p211','p211','sp2','sp2','hd28','hd28'],'user':['A','B','A','B','A','C'],'nums':[1,1,1,1,1,1]},columns=['book_code','user','nums'])
In [5]: df
Out[5]:
book_code user nums
0 p211 A 1
1 p211 B 1
2 sp2 A 1
3 sp2 B 1
4 hd28 A 1
5 hd28 C 1
###实现行列互换,把book_code列转换为行或索引
In [6]: pd.pivot_table(df,values='nums',index='user',columns='book_code')
Out[6]:
book_code hd28 p211 sp2
user
A 1.0 1.0 1.0
B NaN 1.0 1.0
C 1.0 NaN NaN
####转换后,出现一些NaN值或空值,我们可以把NaN修改为0
In [7]: pd.pivot_table(df,values='nums',index='user',columns='book_code',fill_value=0)
Out[7]:
book_code hd28 p211 sp2
user
A 1 1 1
B 0 1 1
C 1 0 0
3.4数据分组与聚合
MySQL中我们介绍了分组聚合计算,具体通过函数Group by对数据进行分组统计,参与分组的字段可以一个或多个,分组后可以进行分组汇总、求平均值等计算。在Pandas的DataFrame格式的数据该如何进行分组及聚合呢?与MySQL非常类似,我们可以像操作数据库中表一样操作DataFrame格式数据。这或许得益于DataFrame结构类似于数据库中表。
具体如何实现,我们还是通过示例来说明。
...: 'type1': ['a','b','a','c','b'],
...: 'type2': ['mon','tues','wed','mon','wed'],
...: 'data1': np.random.randn(5),
...: 'data2': np.random.randn(5)
...: })
In [5]: df
Out[5]:
data1 data2 type1 type2
0 -0.188844 -0.011052 a mon
1 0.514468 0.529642 b tues
2 0.798027 0.536333 a wed
3 0.512078 -1.364139 c mon
4 0.013959 1.224628 b wed
In [6]: df.groupby('type1').mean() ##根据type1分组,然后求平均值
Out[6]:
data1 data2
type1
a 0.304591 0.262641
b 0.264213 0.877135
c 0.512078 -1.364139
##根据type1,type2分组,然后求平均值
In [7]: df.groupby(['type1','type2']).mean()
Out[7]:
data1 data2
type1 type2
a mon -0.188844 -0.011052
wed 0.798027 0.536333
b tues 0.514468 0.529642
wed 0.013959 1.224628
c mon 0.512078 -1.364139
Pingback引用通告: Python与人工智能 – 飞谷云人工智能