第一部分我们介绍了Numpy、Tensor、nn等内容,这些内容是继续学习Pytorch的基础。有了这些基础,进入第二部分就容易多了。第二部分我们将介绍深度学习的一些基本内容,以及如何用Pytorch解决机器学习、深度学习的一些实际问题。
深度学习是机器学习的重要分支,也是机器学习的核心,但深度学习是在机器学习基础上发展起来的,因此理解机器学习的基本概念、基本原理对理解深度学习将大有裨益。
机器学习的体系很庞大,限于篇幅,本章主要介绍基本知识及与深度学习关系比较密切的内容,如果读者希望进一步学习机器学习的相关知识,建议参考周志华老师编著的《机器学习》或李航老师编著的《统计学习方法》。
本章先介绍机器学习中常用的监督学习、无监督学习等,然后介绍神经网络及相关算法,最后介绍传统机器学习中的一些不足及优化方法等,本章主要内容包括:
机器学习的基本任务
机器学习的一般流程
解决过拟合、欠拟合的一些方法
选择合适的激活函数、损失函数、优化器等
GPU加速
5.1 机器学习的基本任务
机器学习的基本任务一般分为四大类,监督学习、无监督学习、半监督学习和强化学习。监督学习、无监督学习比较普遍,大家也比较熟悉。常见的分类、回归等属于监督学习,聚类、降维等属于无监督学习。半监督学习和强化学习的发展历史虽没有前两者这么悠久,但发展势头非常迅猛。图5-1 说明了四种分类的主要内容。
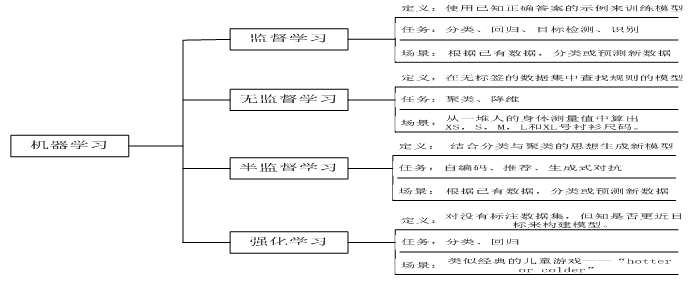
图5-1 机器学习的基本任务
5.1.1监督学习
监督学习是最常见的一种机器学习类型,其任务的特点就是给定学习目标,这个学习目标又称为标签或或标注或实际值等,整个学习过程就是围绕如何使预测与目标更接近。近些年,随着深度学习的发展,分类除传统的二分类、多分类、多标签分类之外,分类也出现一些新内容,如目标检测、目标识别、图像分割等是监督学习重要内容。监督学习过程如图5-2所示。
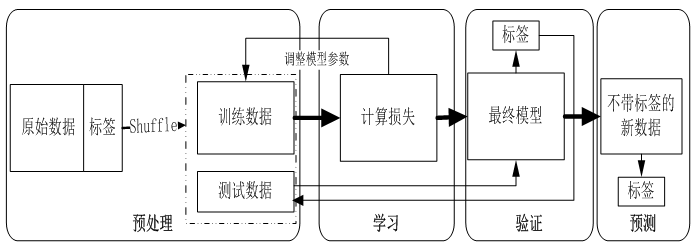
图5-2 监督学习的一般过程
5.1.2 无监督学习
监督学习的输入数据中有标签或目标值,但在实际生活中,有很多数据是没有标签的,或者标签代价很高。这些没有标签的数据也可能包含很重要规则或信息,从这类数据中学习到一个规则或规律的过程称为无监督学习。在无监督学习中,我们通过推断输入数据中的结构来建模,模型包括关联学习、降维、聚类等。
5.1.3 半监督学习
半监督是监督学习与无监督学习相结合的一种学习方法。半监督学习使用大量的未标记数据,同时由部分使用标记数据进行模式识别。半监督学习目前正越来越受到人们的重视。
自编码器是一种半监督学习,其生成的目标就是未经修改的输入。语言处理中根据给定文本中词预测下一个词,也是半监督学习的例子。
对抗生成式网络也是一种半监督学习,给定一些真图像或语音,然后,通过对抗生成网络生成一些与真图片或语音逼真的图形或语音。
5.1.4 强化学习
强化学习是机器学习的一个重要分支,是多学科多领域交叉的一个产物。强化学习主要包含四个元素,智能体(agent),环境状态,行动,奖励, 强化学习的目标就是获得最多的累计奖励。
强化学习把学习看作试探评价过程,Agent选择一个动作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号(奖或惩)反馈给Agent,Agent根据强化信号和环境当前状态再选择下一个动作,选择的原则是使受到正强化(奖)的概率增大。选择的动作不仅影响立即强化值,也影响下一时刻的状态和最终的强化值。
强化学习不同于监督学习,主要表现在教师信号上,强化学习中由环境提供的强化信号是Agent对所产生动作的好坏作一种评价,而不是告诉Agent如何去产生正确的动作。由于外部环境提供了很少的信息,Agent必须靠自身的经历进行学习。通过这种方式,Agent在行动一一评价的环境中获得知识,改进行动方案以适应环境。
AlphaGo Zero带有强化学习内容,它完全摒弃了人类知识,碾压了早期版本的AlphaGo,更足显强化学习和深度学习结合的巨大威力。
5.2 机器学习一般流程
机器学习一般流程首先需要定义问题、收集数据、探索数据、预处理数据,对数据处理后,接下来开始训练模型、评估模型,然后优化模型等步骤,图5-3 为机器学习一般流程图。
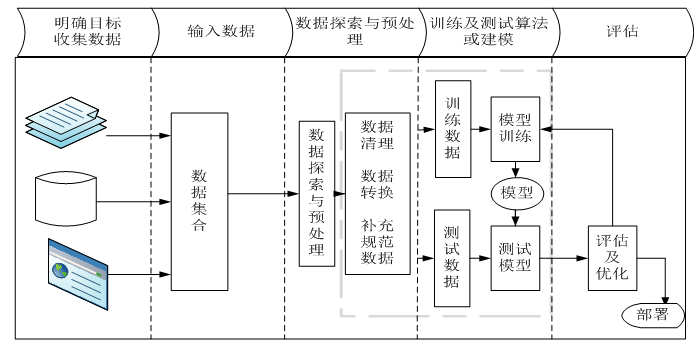
图5-3 机器学习一般流程图
通过这个图形可直观了解机器学习的一般步骤或整体框架,接下来我们就各部分分别加以说明。
5.2.1 明确目标
在实施一个机器学习项目之初,定义需求、明确目标、了解要解决的问题以及目标涉及的范围等非常重要,它们直接影响后续工作的质量甚至成败。明确目标,首先需要明确大方向,比如当前需求是分类问题还是预测问题或聚类问题等。清楚大方向后,需要进一步明确目标的具体含义。如果是分类问题,还需要区分是二分类、多分类或多标签分类;如果是预测问题,要区别是标量预测还是向量预测;其他方法类似。确定问题,明确目标有助于选择模型架构、损失函数及评估方法等。
当然,明确目标还包含需要了解目标的可行性,因为并不是所有问题都可以通过机器学习来解决。
5.2.2收集数据
目标明确后,接下来就是了解数据。为解决这个问题,需要哪些数据?数据是否充分?哪些数据能获取?哪些无法获取?这些数据是否包含我们学习的一些规则等等,都需要全面把握。
接下来就是收集数据,数据可能涉及不同平台、不同系统、不同部分、不同形式等,对这些问题的了解有助于确定具体数据收集方案、实施步骤等。
能收集的数据尽量实现自动化、程序化。
5.2.3 数据探索与预处理
收集到的数据,不一定规范和完整,这就需要对数据进行初步分析或探索,然后根据探索结果与问题目标,确定数据预处理方案。
对数据探索包括了解数据的大致结构、数据量、各特征的统计信息、整个数据质量情况、数据的分布情况等。为了更好体现数据分布情况,数据可视化是一个不错方法。
通过对数据探索后,可能发会现不少问题:如存在缺失数据、数据不规范、数据分布不均衡、存在奇异数据、有很多非数值数据、存在很多无关或不重要的数据等等。这些问题的存在直接影响数据质量,为此,数据预处理工作应该就是接下来的重点工作,数据预处理是机器学习过程中必不可少的重要步骤,特别是在生产环境中的机器学习,数据往往是原始、未加工和处理过,数据预处理常常占据整个机器学习过程的大部分时间。
数据预处理过程中,一般包括数据清理、数据转换、规范数据、特征选择等工作。
5.2.4 选择模型及损失函数
数据准备好以后,接下就是根据目标选择模型。模型选择上可以先用一个简单、自己比较熟悉的一些方法来实现,用这个方法开发一个原型或比基准更好一点的模型。通过这个简单模型有助于你快速了解整个项目的主要内容。
了解整个项目的可行性、关键点
了解数据质量、数据是否充分等
为你开发一个更好模型奠定基础
在模型选择时,一般不存在某种对任何情况都表现很好的算法(这种现象又称为没有免费的午餐)。因此在实际选择时,一般会选用几种不同方法来训练模型,然后比较它们的性能,从中选择最优的那个。
模型选择后,还需要考虑以下几个关键点:
最后一层是否需要添加softmax或sigmoid激活层
选择合适损失函数
选择合适的优化器
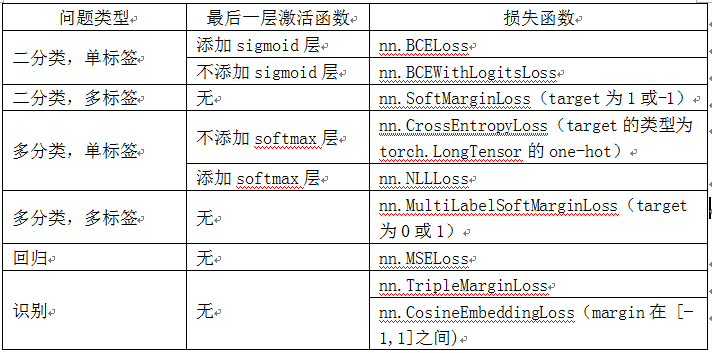
表5-1 列出了常见问题类型最后一层激活函数和损失函数的对应关系,供大家参考。
表5-1 根据问题类型选择损失函数
5.2.5 评估及优化模型
模型确定后,还需要确定一种评估模型性能的方法,即评估方法。评估方法大致有以下三种:
留出法(holdout):留出法的步骤相对简单,直接将数据集划分为两个互斥的集合,其中一个集合作为训练集,另一个作为测试。在训练集上训练出模型后,用测试集来评估测试误差,作为泛化误差的估计。使用留出法,还有一种更好的方法就是把数据分成三部分:训练数据集、验证数据集、测试数据集。训练数据集用来训练模型,验证数据集用来调优超参数,测试集用来测试模型的泛化能力。数据量较大时可采用这种方法。
K折交叉验证:不重复地随机将训练数据集划分为k个,其中k-1个用于模型训练,剩余的一个用于测试。
重复的K折交叉验证:当数据量比较小,数据分布不很均匀时可以采用这种方法。
使用训练数据构建模型后,通常使用测试数据对模型进行测试,测试模型对新数据的
测试。如果对模型的测试结果满意,就可以用此模型对以后的进行预测;如果测试结果不满意,可以优化模型。优化的方法很多,其中网格搜索参数是一种有效方法,当然我们也可以采用手工调节参数等方法。如果出现过拟合,尤其是回归类问题,可以考虑正则化方法来降低模型的泛化误差。
5.3 过拟合与欠拟合
前面我们介绍了机器学习的一般流程,模型确定后,开始训练模型,然后对模型进行评估和优化,这个过程往往是循环往复的。在训练模型过程,经常出现刚开始训练时,训练和测试精度不高(或损失值较大),然后通过增加迭代次数或通过优化,训练精度和测试精度继续提升,如果出现这种情况,当然最好。随着我们训练迭代次数的增加或不断优化,可能出现训练精度或损失值继续改善,但测试精度或损失值不降反升的情况。如图5-4 所示。
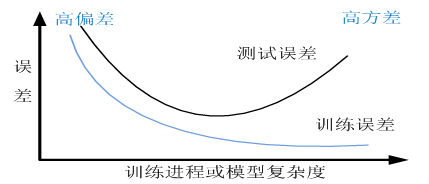
图5-4 训练误差与测试误差
出现这种情况,说明我们的优化过头了,把训练数据中一些无关紧要甚至错误的模式也学到了。这就是我们通常说的出现过拟合了。如何解决这类问题?机器学习中有很多方法,这些方法又统称为正则化,接下来我们介绍一些常用的正则化方法。
5.3.1 权重正则化
如何解决过拟合问题呢?正则化是有效方法之一。正则化不仅可以有效降低高方差,还有利于降低偏差。何为正则化?在机器学习中,很多被显式地用来减少测试误差的策略,统称为正则化。正则化旨在减少泛化误差而不是训练误差。为使大家对正则化的作用及原理有个直观印象,先看正则化示意图5-5 。
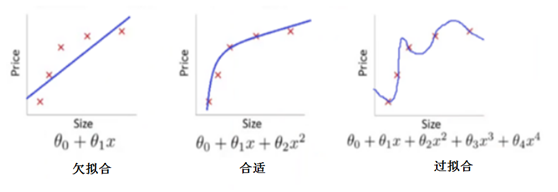
图5-5 正则化示意图
图5-5是根据房屋面积(Size)预测房价(Price)的回归模型。正则化是如何解决模型过复杂这个问题的呢?主要是通过正则化使参数变小甚至趋于原点。在图5-5最右边这个图,其模型或目标函数是一个4次多项式,因它把一些噪音数据也包括进来了,所以导致模型很复杂,实际上房价与房屋面积应该是2次多项式函数,如图5-5中间这个图。
如果要降低模型的复杂度,可以通过缩减它们的系数来实现,如把第3次、4次项的系数θ_3、θ_4缩减到接近于0即可。
在算法中如何实现呢?这个得从其损失函数或目标函数着手。
假设房屋价格与面积间模型的损失函数为:
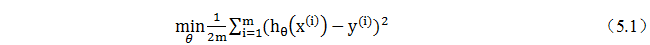
这个损失函数是我们的优化目标,也就是说我们需要尽量减少损失函数的均方误差。
对于这个函数我们对它添加一些正则项,如加上 10000乘以θ_3 的平方,再加上 10000乘以θ_4的平方,得到如下函数:
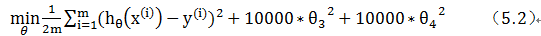
这里取10000只是用来代表它是一个"大值",现在,如果要最小化这个新的损失函数,我们要让θ_3 和θ_4 尽可能小。因为,如果你在原有损失函数的基础上加上 10000乘以θ_3 这一项,那么这个新的损失函数将变得很大,所以,当最小化这个新的损失函数时,将使 θ3 的值接近于 0,同样θ_4 的值也接近于 0,就像我们忽略了这两个值一样。如果做到这一点(θ_3 和θ_4 接近 0 ),那么将得到一个近似的二次函数。如图5-6所示:
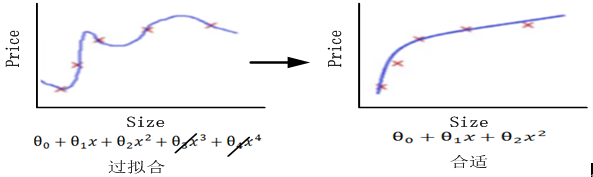
图5-6利用正则化提升模型泛化能力
希望通过上面的简单介绍,能给大家有个直观理解。传统意义上的正则化一般分为L0、L1、L2、L∞等。
Pytorch如何实现正则化呢?这里以实现L2为例,神经网络的L2正则化称为权重衰减(weight decay)。torch.optim集成了很多优化器,如SGD,Adadelta,Adam,Adagrad,RMSprop等,这些优化器自带的一个参数weight_decay,用于指定权值衰减率,相当于L2正则化中的λ参数,也就是式(5.3)中的λ。
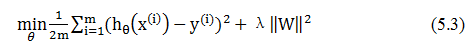
5.3.2 dropout正则化
Dropout是Srivastava等人在2014年的一篇论文中,提出的一种针对神经网络模型的正则化方法 Dropout: A Simple Way to Prevent Neural Networks from Overfitting。
Dropout在训练模型中是如何实现的呢?Dropout的做法是在训练过程中按一定比例(比例参数可设置)随机忽略或屏蔽一些神经元。这些神经元被随机“抛弃”,也就是说它们在正向传播过程中对于下游神经元的贡献效果暂时消失了,反向传播时该神经元也不会有任何权重的更新。所以,通过传播过程,dropout将产生和L2范数相同的收缩权重的效果。
随着神经网络模型的不断学习,神经元的权值会与整个网络的上下文相匹配。神经元的权重针对某些特征进行调优,会产生一些特殊化。周围的神经元则会依赖于这种特殊化,如果过于特殊化,模型会因为对训练数据过拟合而变得脆弱不堪。神经元在训练过程中的这种依赖于上下文的现象被称为复杂的协同适应(complex co-adaptations)。
加入了Dropout以后,输入的特征都是有可能会被随机清除的,所以该神经元不会再特别依赖于任何一个输入特征,也就是说不会给任何一个输入设置太大的权重。网络模型对神经元特定的权重不那么敏感。这反过来又提升了模型的泛化能力,不容易对训练数据过拟合。
Dropout训练的集成包括所有从基础网络除去非输出单元形成子网络,如图5-7所示。
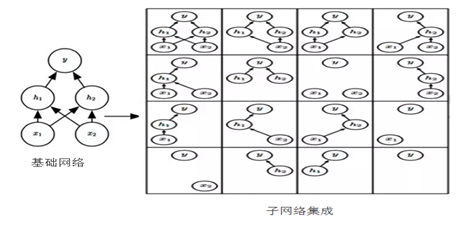
图 5-7基础网络Dropout为多个子网络
Dropout训练所有子网络组成的集合,其中子网络是从基本网络中删除非输出单元构建。我们从具有两个可见单元和两个隐藏单元的基本网络开始,这四个单元有十六个可能的子集。右图展示了从原始网络中丢弃不同的单元子集而形成的所有十六个子网络。在这个例子中,所得到的大部分网络没有输入单元或没有从输入连接到输出的路径。当层较宽时,丢弃所有从输入到输出的可能路径的概率变小,所以,这个问题对于层较宽的网络不是很重要。
较先进的神经网络基于一系列仿射变换和非线性变换,我们可以将一些单元的输出乘零,就能有效地删除一些单元。这个过程需要对模型进行一些修改,如径向基函数网络,单元的状态和参考值之间存在一定区别。为简单起见, 在这里提出乘零的简单Dropout算法,被简单地修改后,可以与其他操作一起工作。
dropout在训练阶段和测试阶段是不同的,一般在训练中使用,测试不使用。不过测试时,为平衡(因训练时舍弃了部分节点或输出),一般将输出按dropout rate比例缩小。
如何或何时使用Dropout呢?以下是一般原则:
(1)通常丢弃率控制在20%~50%比较好,可以从20%开始尝试。如果比例太低则起不到效果,比例太高则会导致模型的欠学习。
(2)在大的网络模型上应用。
当dropout用在较大的网络模型时,更有可能得到效果的提升,模型有更多的机会学习到多种独立的表征。
(3)在输入层和隐藏层都使用dropout。
对于不同的层,设置的keep_prob也不同,一般来说神经元较少的层,会设keep_prob
为1.0或接近于1.0的数;神经元多的层,则会将keep_prob设置的较小,如0.5或更小。
(4)增加学习速率和冲量。
把学习速率扩大10~100倍,冲量值调高到0.9~0.99。
(5)限制网络模型的权重。
大的学习速率往往导致大的权重值。对网络的权重值做最大范数的正则化,被证明能提升模型性能。
以下我们通过实例来比较使用dropout和不使用dropout对训练损失或测试损失的影响。
数据还是房屋销售数据,构建网络层,添加两个dropout,具体构建网络代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
net1_overfitting = torch.nn.Sequential( torch.nn.Linear(13, 16), torch.nn.ReLU(), torch.nn.Linear(16, 32), torch.nn.ReLU(), torch.nn.Linear(32, 1), ) net1_dropped = torch.nn.Sequential( torch.nn.Linear(13, 16), torch.nn.Dropout(0.5), # drop 50% of the neuron torch.nn.ReLU(), torch.nn.Linear(16, 32), torch.nn.Dropout(0.5), # drop 50% of the neuron torch.nn.ReLU(), torch.nn.Linear(32, 1), ) |
获取测试集上不同损失值的代码如下:
|
1 |
writer.add_scalars('test_group_loss',{'origloss':orig_loss.item(),'droploss':drop_loss.item()}, epoch) |
把运行结果,通过tensorboardX在web显示,可看到图5-8的结果。

图5-8 dropout对测试损失值的影响
从图5-8 可以看出,添加dropout层,对提升模型的性能或泛化能力,效果还是比较明显的。
5.3.3 批量正则化
我们介绍了数据归一化,这个一般是针对输入数据而言。但在实际训练过程中,经常出现隐含层因数据分布不均,导致梯度消失或不起作用的情况。如采用sigmoid函数或tanh函数为激活函数时,如果数据分布在两侧,这些激活函数的导数就接近于0,这样一来,BP算法得到的梯度也就消失了。如何解决这个问题?
Sergey Ioffe和Christian Szegedy两位学者提出了批标准化(Batch Normalization)方法。Batch Normalization不仅可以有效解决梯度消失问题,而且还可以让调试超参数更加简单,在提高训练模型效率的同时,还可让神经网络模型更加“健壮”。Batch Normalization是如何做到这些的呢? 首先,我们介绍一下BN的算法流程:
输入:微批次(mini-batch) 数据:B={x_1,x_2⋯x_m}
学习参数:γ,β 类似于权重参数,可以通过梯度下降等算法求得。
其中x_i 并不是网络的训练样本,而是指原网络中任意一个隐藏层激活函数的输入,这些输入是训练样本在网络中前向传播得来的。
输出:{y_i=NB_(γ,β) (x_i)}
#求微批次样本均值:
μ_B ← 1/m 〖∑┴m〗┬(i=1) x_i (5.4)
#求微批次样本方差:
σ_B^2 ← 1/m 〖∑┴m〗┬(i=1) 〖(x〗_i-〖μ_B)〗^2 (5.5)
#对x_i进行标准化处理:
(x_i ) ̂ ← (x_i-μ_B)/√(σ_B^2+ϵ) (5.6)
#反标准化操作:
y_i=γ(x_i ) ̂+β≡NB_(γ,β) (x_i) (5.7)
BN是对隐藏层的标准化处理,它与输入的标准化处理Normalizing inputs是有区别的。Normalizing inputs使所有输入的均值为0,方差为1。而Batch Normalization可使各隐藏层输入的均值和方差为任意值。实际上,从激活函数的角度来说,如果各隐藏层的输入均值在靠近0的区域,即处于激活函数的线性区域,这样不利于训练好的非线性神经网络,而且得到的模型效果也不会太好。式(5.6)就起这个作用,当然它还有将归一化后的 x 还原的功能。BN一般用在哪里呢?BN应作用在非线性映射前,即对x=Wu+b做规范化时,在每一个全连接和激励函数之间。
何时使用BN呢?一般在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时,可以尝试用BN来解决。另外,在一般情况下,也可以加入BN来加快训练速度,提高模型精度,还可以大大提高训练模型的效率。BN具体功能有:
(1)可以选择比较大的初始学习率,让训练速度飙涨。以前还需要慢慢调整学习率,甚至在网络训练到一半的时候,还需要想着学习率进一步调小的比例选择多少比较合适,现在我们可以采用初始很大的学习率,然后学习率的衰减速度也很大,因为这个算法收敛很快。当然,这个算法即使你选择了较小的学习率,也比以前的收敛速度快,因为它具有快速训练收敛的特性。
(2)不用再去理会过拟合中drop out、L2正则项参数的选择问题,采用BN算法后,你可以移除这两项参数,或者可以选择更小的L2正则约束参数了,因为BN具有提高网络泛化能力的特性。
(3)再也不需要使用局部响应归一化层。
(4)可以把训练数据彻底打乱。
下面还是以房价预测为例,比较添加BN层与不添加BN层,两者在测试集上的损失值比较。下例为两者网络结构代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
net1_overfitting = torch.nn.Sequential( torch.nn.Linear(13, 16), torch.nn.ReLU(), torch.nn.Linear(16, 32), torch.nn.ReLU(), torch.nn.Linear(32, 1), ) net1_nb = torch.nn.Sequential( torch.nn.Linear(13, 16), nn.BatchNorm1d(num_features=16), torch.nn.ReLU(), torch.nn.Linear(16, 32), nn.BatchNorm1d(num_features=32), torch.nn.ReLU(), torch.nn.Linear(32, 1), ) |
图5-9 为运行结果图

图5-9 BN层对测试数据的影响
从图5-9 可以看出,添加BN层对改善模型的泛化能力有一定帮助,不过没有dropout那么明显。这个神经网络比较简单,BN在一些复杂网络中,效果会更好。
5.3.4权重初始化
深度学习为何要初始化?传统机器学习算法中很多不是采用迭代式优化,因此需要初始化的内容不多。但深度学习的算法一般采用迭代方法,而且参数多、层数也多,所以很多算法不同程度受到初始化的影响。
初始化对训练有哪些影响?初始化能决定算法是否收敛,如果初始化不适当,初始值过大可能会在前向传播或反向传播中产生爆炸的值;如果太小将导致丢失信息。对收敛的算法适当的初始化能加快收敛速度。初始值选择将影响模型收敛局部最小值还是全局最小值,如图5-10,因初始值的不同,导致收敛到不同的极值点。另外,初始化也可以影响模型的泛化。
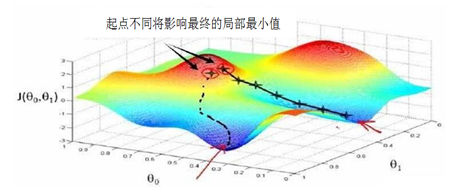
图5-10初始点的选择影响算法是否陷入局部最小点
如何对权重、偏移量进行初始化?初始化这些参数是否有一般性原则?常见的参数初始化有零值初始化、随机初始化、均匀分布初始、正态分布初始和正交分布初始等。一般采用正态分布或均匀分布的初始值,实践表明正态分布、正交分布、均匀分布的初始值能带来更好的效果。
继承nn.Module的模块参数都采取了较合理的初始化策略,一般情况使用其缺省初始化策略就够了。当然,如果你要想修改,Pytorch也提供了nn.init模块,该模块提供了常用的初始化策略,如xavier、kaiming等经典初始化策略,使用这些初始化策略有利于激活值的分布呈现更有广度或更贴近正态分布。xavier一般用于激活函数是S型(如sigmoid、tanh)的权重初始化,kaiming更适合与激活函数为ReLU类的权重初始化。
5.4 选择合适激活函数
激活函数在神经网络中作用有很多,主要作用是给神经网络提供非线性建模能力。如果没有激活函数,那么再多层的神经网络也只能处理线性可分问题。常用的激活函数有sigmoid、tanh、relu、softmax等。它们的图形、表达式、导数等信息如表5-2所示:
表5-2 激活函数各种属性

在搭建神经网络时,如何选择激活函数?如果搭建的神经网络层数不多,选择sigmoid、tanh、relu、softmax都可以;如果搭建的网络层次比较多,那就需要小心,选择不当就可导致梯度消失问题。此时一般不宜选择sigmoid、tanh激活函数,因它们的导数都小于1,尤其是sigmoid的导数在[0,1/4]之间,多层叠加后,根据微积分链式法则,随着层数增多,导数或偏导将指数级变小。所以层数较多的激活函数需要考虑其导数不宜小于1当然也不能大于1,大于1将导致梯度爆炸,导数为1最好,激活函数relu正好满足这个条件。所以,搭建比较深的神经网络时,一般使用relu激活函数,当然一般神经网络也可使用。此外,激活函数softmax由于〖∑ 〗┬i σ_i (z)=1,常用于多分类神经网络输出层。
激活函数在Pytorch中使用示例:
|
1 2 3 |
m = nn.Sigmoid() input = torch.randn(2) output = m(input) |
激活函数输入维度与输出维度是一样的。激活函数的输入维度一般包括批量数N,即输入数据的维度一般是4维,如(N,C,W,H)。
5.5 选择合适的损失函数
损失函数(Loss Function)在机器学习中非常重要,因为训练模型的过程实际就是优化损失函数的过程。损失函数对每个参数的偏导数就是梯度下降中提到的梯度,防止过拟合时添加的正则化项也是加在损失函数后面。损失函数用来衡量模型的好坏,损失函数越小说明模型和参数越符合训练样本。任何能够衡量模型预测值与真实值之间的差异的函数都可以叫做损失函数。在机器学习中常用的损失函数有两种,即交叉熵(Cross Entropy)和均方误差(Mean squared error,简称为MSE),分别对应机器学习中的分类问题和回归问题。
对分类问题的损失函数一般采用交叉熵,交叉熵反应的两个概率分布的距离(不是欧氏距离)。分类问题进一步又可分为多目标分类,如一次要判断100张图是否包含10种动物,或单目标分类。
回归问题预测的不是类别,而是一个任意实数。在神经网络中一般只有一个输出节点,该输出值就是预测值。反应的预测值与实际值之间距离可以用欧氏距离来表示,所以对这类问题我们通常使用均方差作为损失函数,均方差的定义如下:

Pytorch中已集成多种损失函数,这里介绍两个经典的损失函数,其他损失函数基本上是在它们的基础上的变种或延伸。
(1)torch.nn.MSELoss
具体格式:
|
1 |
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean') |
计算公式:
l(x,y)=L=〖{l_1,l_2,⋯,l_N}〗^T,l_n=〖(x_n-y_n)〗^2,N是批量大小。
如果参数reduction为非None(缺省值为'mean'),则:
l(x,y)={█(mean(L),if reduction='mean'@sum(L),if reduction='sum')┤ (5.9)
x和y是任意形状的张量,每个张量都有n个元素,如果reduction取'none', l(x,y)将不是标量;如果取'sum', l(x,y)只是差平方的和,但不会除以n。
参数说明:
size_average,reduce将移除,主要看参数reduction,reduction可以取'none','mean','sum',缺省值为'mean'。如果size_average,reduce的取值,将覆盖reduction的取值。
代码示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import torch import torch.nn as nn import torch.nn.functional as F torch.manual_seed(10) loss = nn.MSELoss(reduction='mean') input = torch.randn(1, 2, requires_grad=True) print(input) target = torch.randn(1, 2) print(target) output = loss(input, target) print(output) output.backward() |
(2)torch.nn.CrossEntropyLoss
交叉熵损失(cross-entropy Loss) 又称为对数似然损失(Log-likelihood Loss)、对数损失;二分类时还可称之为逻辑斯谛回归损失(Logistic Loss)。在Pytroch里,它不是严格意义上的交叉熵损失函数,而是先将input经过softmax激活函数,将向量“归一化”成概率形式,然后再与target计算严格意义上的交叉熵损失。 在多分类任务中,经常采用softmax激活函数+交叉熵损失函数,因为交叉熵描述了两个概率分布的差异,然而神经网络输出的是向量,并不是概率分布的形式。所以需要softmax激活函数将一个向量进行“归一化”成概率分布的形式,再采用交叉熵损失函数计算loss。
一般格式:
|
1 |
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean') |
计算公式:
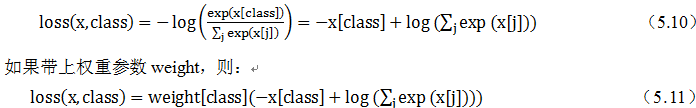
weight(Tensor)- 为每个类别的loss设置权值,常用于类别不均衡问题。weight必须是float类型的tensor,其长度要于类别C一致,即每一个类别都要设置有weight。
代码示例
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import torch import torch.nn as nn torch.manual_seed(10) loss = nn.CrossEntropyLoss() #假设类别数为5 input = torch.randn(3, 5, requires_grad=True) #每个样本对应的类别索引,其值范围为[0,4] target = torch.empty(3, dtype=torch.long).random_(5) output = loss(input, target) output.backward() |
5.6 选择合适优化器
优化器在机器学习、深度学习中往往起着举足轻重的作用,同一个模型,因选择不同的优化器,性能有可能相差很大,甚至导致一些模型无法训练。所以,了解各种优化器的基本原理非常必要。本节重点介绍各种优化器或算法的主要原理,及各自的优点或不足。
5.6.1传统梯度优化的不足
传统梯度更新算法为最常见、最简单的一种参数更新策略。其基本思想是:先设定一个学习率λ,参数沿梯度的反方向移动。假设需更新的参数为θ,梯度为g,则其更新策略可表示为:
θ←θ-λg (5.12)
这种梯度更新算法简洁,当学习率取值恰当时,可以收敛到全面最优点(凸函数)或局部最优点(非凸函数)。
但其不足也很明显,对超参数学习率比较敏感(过小导致收敛速度过慢,过大又越过极值点),如图5-11的右图所示。在比较平坦的区域,因梯度接近于0,易导致提前终止训练,如图5-11的左图所示,要选中一个恰当的学习速率往往要花费不少时间。

图5-11学习速率对梯度的影响
学习率除了敏感,有时还会因其在迭代过程中保持不变,很容易造成算法被卡在鞍点的位置,如图5-12所示。
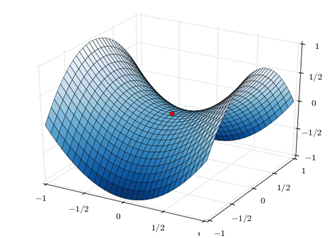
图5-12算法卡在鞍点示意图
另外,在较平坦的区域,因梯度接近于0,优化算法往往因误判,还未到达极值点,就提前结束迭代,如图5-13
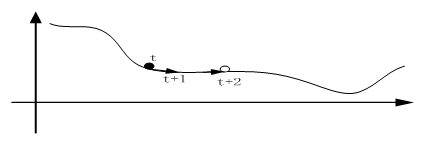
图5-13在较平坦区域,梯度接近于0,优化算法因误判而提前终止迭代。
传统梯度优化方面的这些不足,在深度学习中会更加明显。为此,人们自然想到如何克服这些不足的问题。从式(6.26)可知,影响优化的无非两个因素:一个是梯度方向,一个是学习率。所以很多优化方法大多从这两方面入手,有些从梯度方向入手,如下节介绍的动量更新策略;有些从学习率入手,这涉及调参问题;还有从两方面同时入手,如自适应更新策略,接下来将介绍这些方法。
5.6.2动量算法
梯度下降法在遇到平坦或高曲率区域时,学习过程有时很慢。利用动量算法能比较好解决这个问题。动量算法与传统梯度下降优化的效果如图5-14所示。
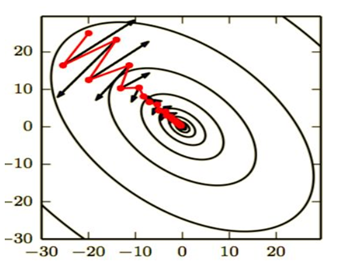
图5-14使用或不使用动量算法的SGD效果比较,红色或振幅较小的为有动量梯度下降行为。
从图5-14 可以看出,不使用动量算法的SGD学习速度比较慢,振幅比较大;而使用动量算法的SGD,振幅较小,而且较快到达极值点。动量算法是如何做到这点的呢?
动量(momentum)是模拟物理里动量的概念,具有物理上惯性的含义,一个物体在运动时具有惯性,把这个思想运用到梯度下降计算中,可以增加算法的收敛速度和稳定性,具体实现如图5-15所示。

图5-15动量算法示意图
由图5-15,可知动量算法每下降一步都是由前面下降方向的一个累积和当前点的梯度方向组合而成。含动量的随机梯度下降法,其算法伪代码:
假设 batch_size=10, m=1000
初始化参数向量θ、学习率为λ、动量参数α、初始速度v
while 停止准则未满足 do
Repeat {
forj = 1, 11, 21, .., 991 {
更新梯度: g ̂←1/(batch_size) 〖 〖∑ 〗┬(i=j)〗┴(j+batch_size) ∇_θL(〖f(x〗^((i) ),θ),y^((i) ))
计算速度:v←αv-λg ̂
更新参数:θ←θ+v
}
}
end while
既然每一步都要将两个梯度方向(历史梯度、当前梯度)做一个合并再下降,那为什么不先按照历史梯度往前走那么一小步,按照前面一小步位置的“超前梯度”来做梯度合并呢?如此一来,可以先往前走一步,在靠前一点的位置(如图5-16中的C点)看到梯度,然后按照那个位置再来修正这一步的梯度方向,如下图5-16所示。这就得到动量算法的一种改进算法,称为Nesterov accelerated gradient 简称 NAG 算法。这种预更新方法能防止大幅振荡,不会错过最小值,并对参数更新更加敏感。

图5-16 NAG下降法示意图
NAG下降法的算法伪代码:
假设 batch_size=10, m=1000
初始化参数向量θ、学习率λ、动量参数α、初始速度v
while 停止准则未满足 do
更新超前点:θ ̃ ← θ+αv
Repeat {
forj = 1, 11, 21, .., 991 {
更新梯度(在超前点): g ̂←1/(batch_size) 〖 〖∑ 〗┬(i=j)〗┴(j+batch_size) ∇_θ ̃ L(〖f(x〗^((i) ),θ ̃),y^((i) ))
计算速度:v←αv-λg ̂
更新参数:θ←θ+v
}
}
end while
NAG动量法和经典动量法的差别就在B点和C点梯度的不同。动量法,更多关注梯度下降方法的优化,如果能从方向和学习率同时优化,效果或许更理想。事实也确实如此,而且这些优化在深度学习中显得尤为重要。接下来我们介绍几种自适应优化算法,这些算法同时从梯度方向及学习率进行优化,效果非常好。
5.6.3 AdaGrad算法
传统梯度下降算法对学习率这个超参数非常敏感,难以驾驭;对参数空间的某些方向也没有很好的方法。这些不足在深度学习中,因高维空间、多层神经网络等因素,常会出现平坦、鞍点、悬崖等问题,因此,传统梯度下降法在深度学习中显得力不从心。还好现在已有很多解决这些问题的有效方法。上节介绍的动量算法在一定程度缓解对参数空间某些方向的问题,但需要新增一个参数,而且对学习率的控制还不很理想。为了更好驾驭这个超参数,人们想出来多种自适应优化算法,使用自适应优化算法,学习率不再是一个固定不变值,它会根据不同情况自动调整来适用情况。这些算法使深度学习向前迈出一大步!这节我们将介绍几种自适应优化算法。
AdaGrad算法是通过参数来调整合适的学习率λ,能独立地自动调整模型参数的学习率,对稀疏参数进行大幅更新和对频繁参数进行小幅更新。因此,Adagrad方法非常适合处理稀疏数据。AdaGrad算法在某些深度学习模型上效果不错。但还有些不足,可能因其累积梯度平方导致学习率过早或过量的减少所致。
AdaGrad算法伪代码:
假设 batch_size=10, m=1000
初始化参数向量θ、学习率λ
小参数δ,一般取一个较小值(如〖10〗^(-7)),该参数避免分母为0
初始化梯度累积变量 r=0
while 停止准则未满足 do
Repeat {
forj = 1, 11, 21, .., 991 {
更新梯度: g ̂←1/(batch_size) 〖 〖∑ 〗┬(i=j)〗┴(j+batch_size) ∇_θL(〖f(x〗^((i) ),θ),y^((i) ))
累积平方梯度:r←r+g ̂⊙g ̂ #⊙表示逐元运算
计算速度:△θ← -λ/(δ+√r)⊙g ̂
更新参数:θ←θ+△θ
}
}
end while
由上面算法的伪代码可知:
(1)随着迭代时间越长,累积梯度r越大,从而学习速率λ/(δ+√r)随着时间就减小,在接近 目标值时,不会因为学习速率过大而越过极值点。
(2)不同参数之间学习速率不同,因此,与前面固定学习速率相比,不容易在鞍点卡住。
(3)如果梯度累积参数r比较小,则学习速率会比较大,所以参数迭代的步长就会比较大。 相反,如果梯度累积参数比较大,则学习速率会比较小,所以迭代的步长会比较小。
5.6.4 RMSProp算法
RMSProp算法修改AdaGrad,为的是在非凸背景下效果更好。针对梯度平方和累计越来越大的问题,RMSProp指数加权的移动平均代替梯度平方和。RMSProp为使用移动平均,引入了一个新的超参数ρ,用来控制移动平均的长度范围。
RMSProp算法伪代码:
假设 batch_size=10, m=1000
初始化参数向量θ、学习率λ、衰减速率ρ
小参数δ,一般取一个较小值(如〖10〗^(-7)),该参数避免分母为0
初始化梯度累积变量 r=0
while 停止准则未满足 do
Repeat {
forj = 1, 11, 21, .., 991 {
更新梯度: g ̂←1/(batch_size) 〖 〖∑ 〗┬(i=j)〗┴(j+batch_size) ∇_θL(〖f(x〗^((i) ),θ),y^((i) ))
累积平方梯度:r←ρr+(1-ρ)g ̂⊙g ̂
计算参数更新:△θ← -λ/(δ+√r)⊙g ̂
更新参数:θ←θ+△θ
}
}
end while
RMSProp算法在实践中已被证明是一种有效且实用的深度神经网络优化算法,在深度学习中得到广泛应用。
5.6.5 Adam算法
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
Adam是另一种学习速率自适应的深度神经网络方法,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习速率。Adam算法伪代码如下:
假设 batch_size=10, m=1000
初始化参数向量θ、学习率λ
矩估计的指数衰减速率ρ_1 和ρ_2在区间[0,1)内。
小参数δ,一般取一个较小值(如〖10〗^(-7)),该参数避免分母为0
初始化一阶和二阶矩变量 s=0,r=0
初始化时间步 t=0
while 停止准则未满足 do
Repeat {
forj = 1, 11, 21, .., 991 {
更新梯度: g ̂←1/(batch_size) 〖 〖∑ 〗┬(i=j)〗┴(j+batch_size) ∇_θL(〖f(x〗^((i) ),θ),y^((i) ))
t←t+1
更新有偏一阶矩估计:s ←ρ_1 s +(1-ρ_1)g ̂
更新有偏二阶矩估计:r← ρ_2 r +(1-ρ_2)g ̂⊙g ̂
修正一阶矩偏差:s ̂=s/(1-ρ_1^t )
修正二阶矩偏差:r ̂=r/(1-ρ_2^t )
累积平方梯度:r←ρr+(1-ρ)g ̂⊙g ̂
计算参数更新:△θ=-λ s ̂/(δ+√(r ̂ ))
更新参数:θ←θ+△θ
}
}
end while
前文介绍了深度学习的正则化方法,它是深度学习核心之一;优化算法也是深度学习的核心之一。优化算法很多,如随机梯度下降法、自适应优化算法等,那么具体使用时该如何选择呢?
RMSprop,Adadelta和Adam被认为是自适应优化算法,因为它们会自动更新学习率。而使用SGD时,必须手动选择学习率和动量参数,通常会随着时间的推移而降低学习率。
有时可以考虑综合使用这些优化算法,如采用先用Adam,然后用SGD优化方法,这个想法,实际上由于在训练的早期阶段SGD对参数调整和初始化非常敏感。因此,我们可以通过先使用Adam优化算法进行训练,这将大大节省训练时间,且不必担心初始化和参数调整,一旦用Adam训练获得较好的参数后,我们可以切换到SGD +动量优化,以达到最佳性能。采用这种方法有时能达到很好效果,如图5-17所示,迭代次数超过150后,用SGD效果好于Adam。
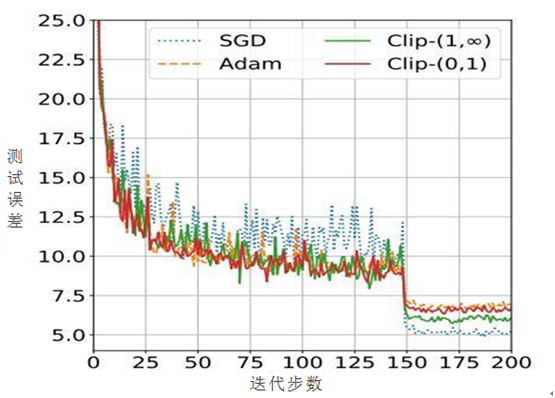
图5-17 迭代次数与测试误差间的对应关系
5.7GPU加速
深度学习涉及很多向量或多矩阵运算,如矩阵相乘、矩阵相加、矩阵-向量乘法等。深层模型的算法,如BP,Auto-Encoder,CNN等,都可以写成矩阵运算的形式,无须写成循环运算。然而,在单核CPU上执行时,矩阵运算会被展开成循环的形式,本质上还是串行执行。GPU(Graphic Process Units,图形处理器)的众核体系结构包含几千个流处理器,可将矩阵运算并行化执行,大幅缩短计算时间。随着NVIDIA、AMD等公司不断推进其GPU的大规模并行架构,面向通用计算的GPU已成为加速可并行应用程序的重要手段。得益于GPU众核(many-core)体系结构,程序在GPU系统上的运行速度相较于单核CPU往往提升几十倍乃至上千倍。
目前,GPU已经发展到了较为成熟的阶段。利用GPU来训练深度神经网络,可以充分发挥其数以千计计算核心的能力,在使用海量训练数据的场景下,所耗费的时间大幅缩短,占用的服务器也更少。如果对适当的深度神经网络进行合理优化,一块GPU卡相当于数十甚至上百台CPU服务器的计算能力,因此GPU已经成为业界在深度学习模型训练方面的首选解决方案。
如何使用GPU?现在很多深度学习工具都支持GPU运算,使用时只要简单配置即可。Pytorch支持GPU,可以通过to(device)函数来将数据从内存中转移到GPU显存,如果有多个GPU还可以定位到哪个或哪些GPU。Pytorch一般把GPU作用于张量(Tensor)或模型(包括torch.nn下面的一些网络模型以及自己创建的模型)等数据结构上。
5.7.1 单GPU加速
使用GPU之前,需要确保GPU是可以使用,可通过torch.cuda.is_available()的返回值来进行判断。返回True则具有能够使用的GPU。
通过torch.cuda.device_count()可以获得能够使用的GPU数量。
如何查看平台GPU的配置信息?在命令行输入命令nvidia-smi即可 (适合于Linux或Windows环境)。图5-18是GPU配置信息样例,从中可以看出共有2个GPU。

图5-18 GPU配置信息
把数据从内存转移到GPU,一般针对张量(我们需要的数据)和模型。
对张量(类型为FloatTensor或者是LongTensor等),一律直接使用方法.to(device)或.cuda()即可。
|
1 2 3 4 5 6 |
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #或device = torch.device("cuda:0") device1 = torch.device("cuda:1") for batch_idx, (img, label) in enumerate(train_loader): img=img.to(device) label=label.to(device) |
对于模型来说,也是同样的方式,使用.to(device)或.cuda来将网络放到GPU显存。
|
1 2 3 4 |
#实例化网络 model = Net() model.to(device) #使用序号为0的GPU #或model.to(device1) #使用序号为1的GPU |
5.7.2 多GPU加速
这里我们介绍单主机多GPUs的情况,单机多GPUs主要采用的DataParallel函数,而不是DistributedParallel,后者一般用于多主机多GPUs,当然也可用于单机多GPU。
使用多卡训练的方式有很多,当然前提是我们的设备中存在两个及以上的GPU。
使用时直接用model传入torch.nn.DataParallel函数即可,如下代码:
|
1 2 |
#对模型 net = torch.nn.DataParallel(model) |
这时,默认所有存在的显卡都会被使用。
如果你的电脑有很多显卡,但只想利用其中一部分,如只使用编号为0、1、3、4的四个GPU,那么可以采用以下方式:
|
1 2 3 4 5 6 7 |
#假设有4个GPU,其id设置如下 device_ids =[0,1,2,3] #对数据 input_data=input_data.to(device=device_ids[0]) #对于模型 net = torch.nn.DataParallel(model) net.to(device) |
或者
|
1 2 |
os.environ["CUDA_VISIBLE_DEVICES"] = ','.join(map(str, [0,1,2,3])) net = torch.nn.DataParallel(model) |
其中CUDA_VISIBLE_DEVICES 表示当前可以被Pytorch程序检测到的GPU。
下面为单机多GPU的实现代码。
(1)背景说明
这里使用波士顿房价数据为例,共506个样本,13个特征。数据划分成训练集和测试集,然后用data.DataLoader转换为可批加载的方式。采用nn.DataParallel并发机制,环境有2个GPU。当然,数据量很小,按理不宜用nn.DataParallel,这里只是为了说明使用方法。
(2)加载数据
|
1 2 3 4 5 6 |
boston = load_boston() X,y = (boston.data, boston.target) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) #组合训练数据及标签 myset = list(zip(X_train,y_train)) |
(3)把数据转换为批处理加载方式
批次大小为128,打乱数据。
|
1 2 3 4 |
from torch.utils import data device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") dtype = torch.FloatTensor train_loader = data.DataLoader(myset,batch_size=128,shuffle=True) |
(4)定义网络
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
class Net1(nn.Module): """ 使用sequential构建网络,Sequential()函数的功能是将网络的层组合到一起 """ def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim): super(Net1, self).__init__() self.layer1 = torch.nn.Sequential(nn.Linear(in_dim, n_hidden_1)) self.layer2 = torch.nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2)) self.layer3 = torch.nn.Sequential(nn.Linear(n_hidden_2, out_dim)) def forward(self, x): x1 = F.relu(self.layer1(x)) x1 = F.relu(self.layer2(x1)) x2 = self.layer3(x1) #显示每个GPU分配的数据大小 print("\tIn Model: input size", x.size(),"output size", x2.size()) return x2 |
(5)把模型转换为多GPU并发处理格式
|
1 2 3 4 5 6 7 8 |
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #实例化网络 model = Net1(13, 16, 32, 1) if torch.cuda.device_count() > 1: print("Let's use", torch.cuda.device_count(), "GPUs") # dim = 0 [64, xxx] -> [32, ...], [32, ...] on 2GPUs model = nn.DataParallel(model) model.to(device) |
运行结果
Let's use 2 GPUs
DataParallel(
(module): Net1(
(layer1): Sequential(
(0): Linear(in_features=13, out_features=16, bias=True)
)
(layer2): Sequential(
(0): Linear(in_features=16, out_features=32, bias=True)
)
(layer3): Sequential(
(0): Linear(in_features=32, out_features=1, bias=True)
)
)
)
(6)选择优化器及损失函数
|
1 2 |
optimizer_orig = torch.optim.Adam(model.parameters(), lr=0.01) loss_func = torch.nn.MSELoss() |
(7)模型训练,并可视化损失值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from tensorboardX import SummaryWriter writer = SummaryWriter(log_dir='logs') for epoch in range(100): model.train() for data,label in train_loader: input = data.type(dtype).to(device) label = label.type(dtype).to(device) output = model(input) loss = loss_func(output, label) # 反向传播 optimizer_orig.zero_grad() loss.backward() optimizer_orig.step() print("Outside: input size", input.size() ,"output_size", output.size()) writer.add_scalar('train_loss_paral',loss, epoch) |
运行的部分结果
In Model: input size torch.Size([64, 13]) output size torch.Size([64, 1])
In Model: input size torch.Size([64, 13]) output size torch.Size([64, 1])
Outside: input size torch.Size([128, 13]) output_size torch.Size([128, 1])
In Model: input size torch.Size([64, 13]) output size torch.Size([64, 1])
In Model: input size torch.Size([64, 13]) output size torch.Size([64, 1])
Outside: input size torch.Size([128, 13]) output_size torch.Size([128, 1])
从运行结果可以看出,一个批次数据(batch-size=128)拆分成两份,每份大小为64,分别放在不同的GPU上。此时用GPU监控也可发现,两个GPU都同时在使用,如图5-19所示。

图5-19 同时使用多个GPU的情况
(8)通过web查看损失值的变化情况,如图5-20所示。
图5-20 并发运行训练损失值变化情况
图形中出现较大振幅,是由于采用批次处理,而且数据没有做任何预处理,对数据进行规范化应该更平滑一些,大家可以尝试一下。
单机多GPU也可使用DistributedParallel,它多用于分布式训练,但也可以用在单机多GPU的训练,配置比使用nn.DataParallel稍微麻烦一点,但是训练速度和效果更好一点。具体配置为:
|
1 2 3 4 |
#初始化使用nccl后端 torch.distributed.init_process_group(backend="nccl") #模型并行化 model=torch.nn.parallel.DistributedDataParallel(model) |
单机运行时使用下列方法启动
|
1 |
python -m torch.distributed.launch main.py |
5.7.3使用GPU注意事项
使用GPU可以提升训练的速度,但如果使用不当,可能影响使用效率,具体使用时要注意以下几点:
(1)GPU的数量尽量为偶数,奇数的GPU有可能会出现异常中断的情况;
(2)GPU很快,但数据量较小时,效果可能没有单GPU好,甚至还不如CPU;
(3)如果内存不够大,使用多GPU训练的时候可通过设置pin_memory为False,当然使用精度稍微低一点的数据类型有时也有效果。
5.8 小结
本章从机器学习的这个比深度学习更宽泛的概念出发,首先说明其基本任务、一般流程等,然后说明在机器学习中解决过拟合、欠拟合的一些常用技巧或方法。同时介绍了各种激活函数、损失函数、优化器等机器学习、深度学习的核心内容。最后说明在程序中如何设置GPU设备、如何用GPU加速训练模型等内容。这章是深度学习的基础,接下来我们将从视觉处理、自然语言处理、生成式网络等方面,深入介绍深度学习的基础又核心的内容。