文章目录
2024-03-14 创建
2024-03-24 添加GAN,改进DDPM等内容
1. 自编码器(Autoencoder,AE )
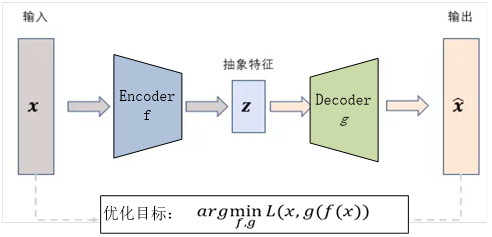
自编码器是神经网络的一种,经过训练后能尝试将输入复制到输出,该网络由两部分构成,,如下图所示,一个是编码器,h=f(x)表示编码器;另一个是解码器  。
。
现代自编码器将编码器和解码器的概念推广,将其中的确定函数推广为随机映射  和
和 。
。
为了从自编码器获取有用特征,通常使编码器的输出h维度较小,这种编码维度小于输入维度的自编码器称为欠完备自编码器,学习欠完备的表示将强制自编码器捕获训练数据中最显著的特征。
学习过程可以简单描述为最小化一个损失函数:

惩罚g(f(x))与x的差异,如均方误差。
如果自编码器的容量太大,那么训练执行复制任务的自编码器可能无法学习到数据集的任何有用信息。
2.去噪自编码器(Denoising autoencoder,DAE )
去噪自编码器的输入为被损坏数据(或添加噪声),并训练来预测原始没被损坏数据作为输出的自编码器。其架构图如下所示:
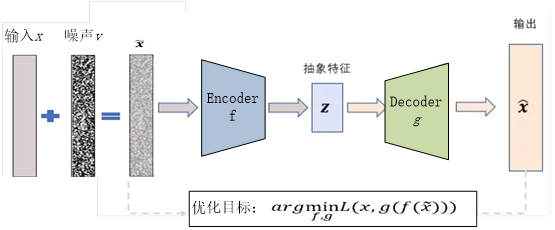
传统自编码的目标函数为:
L(x,g(f(x)))
其中L是一个损失函数,如  范数,惩罚g(f(x))与x的差异。如果模型被赋予过大的容量,L可能仅得g∙f学成一个恒等函数。
范数,惩罚g(f(x))与x的差异。如果模型被赋予过大的容量,L可能仅得g∙f学成一个恒等函数。
相反,去噪自编码最小化目标函数:

其中 是被某种噪声(如满足正态分布的噪声)损坏的副本,因此去噪声自编码器必须撤销这些损坏,而不是简单的复制输入。
是被某种噪声(如满足正态分布的噪声)损坏的副本,因此去噪声自编码器必须撤销这些损坏,而不是简单的复制输入。
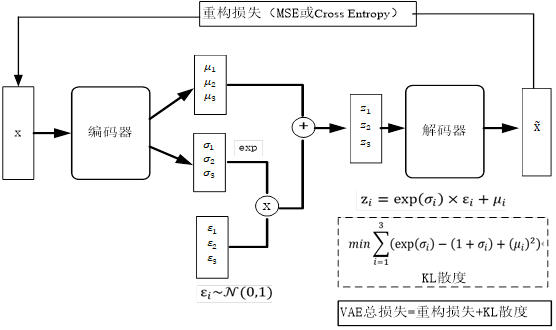
3.VAE模型
去噪声自编码器训练过程就是强制编码器f和解码器g隐式地学习输入数据x的分布 。
。
自动编码器有多种衍生品,如带有隐变量并配有一个推断过程变分自编码器能够学习到高容量且完备的模型,进入学习到输入数据有用的结构信息(如分布信息),这些模型被训练为近似输入数据的概率分布而不是简单对输入的复制。
实际上,我们可以把自编码函数f推广到编码分布(如 ),把解码器函数g推广到随机解码器
),把解码器函数g推广到随机解码器
(如 )。如VAE模型就是如此,VAE模型从概率分布视角进行拟合,采样重参数技巧进行采样,从而使VAE生成的图像有一定的创新性。
)。如VAE模型就是如此,VAE模型从概率分布视角进行拟合,采样重参数技巧进行采样,从而使VAE生成的图像有一定的创新性。

VAE模型采用神经网络模拟概率分布,其逻辑架构如下所示:
4.GAN模型
VAE模型生成的图像质量上不过理解,这或许与底维隐空间将丢弃一些较细的信息有关。GAN模型提出了一种思路,采用一种博弈的螺旋上升的一种思路进行。它用判别器和生成器,取代一般生成器的编码器与生成器的架构。GAN的训练过程如下所示:
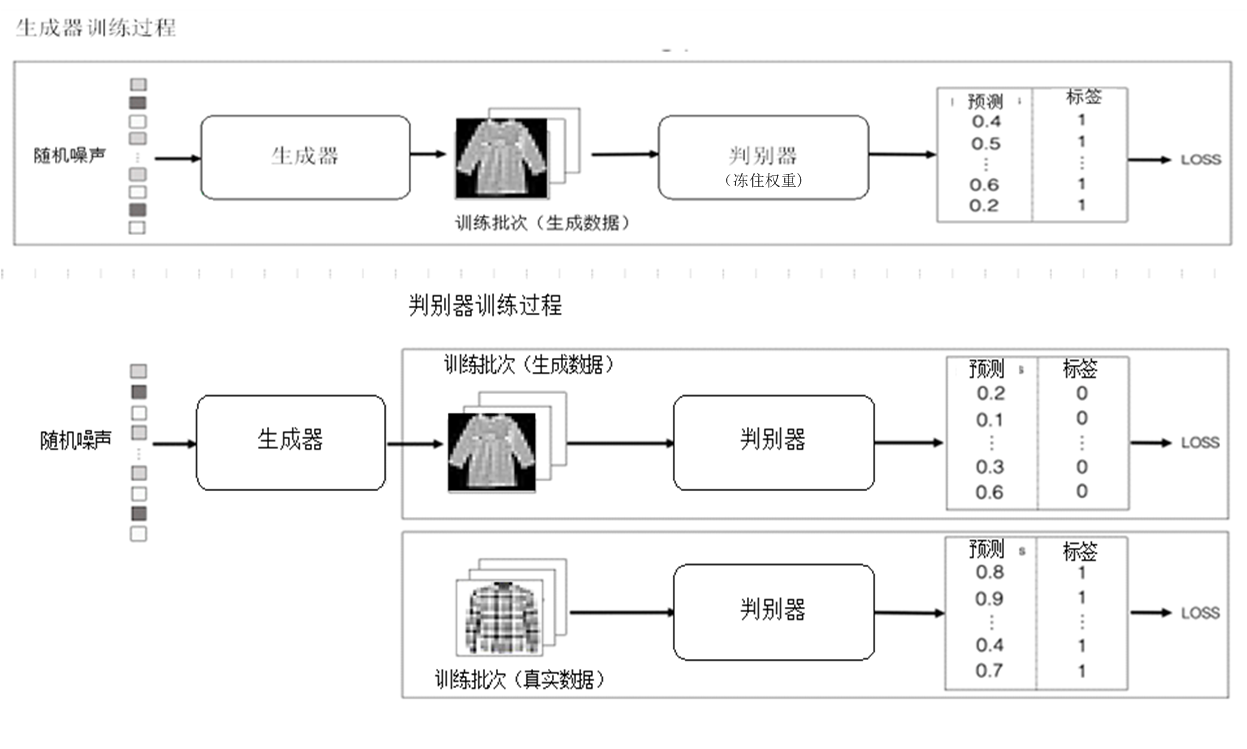
GAN模型采用两部分训练,因此容易导致训练不稳定,另外,训练生成器时,判别器的将被冻住,容易导致模型塌陷的情况,即生成器只要有些生成样本较好,能骗过判别器,就不会再考虑生成更多、更新的样本。为避免AE,DAE,VAE,GAN等模型的不足,人们结合这些模型的优点,提出了一种称为扩散模型的架构。
5.扩散模型
扩散模型有很多,这里主要介绍DDPM(Denoising diffusion probabilistic models)为典型代表。DDPM可以认为是AE的高级版本,其利用了加噪、利用学习数据分布、使用重参数技巧、利用神经网络拟合概率分布、使用变分下界等重要思想。DDPM的架构图如下:
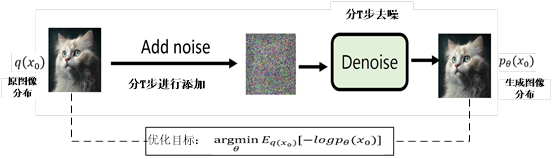
6.如何训练DDPM?
使用U-Net网络结构预测高斯噪音 。
。
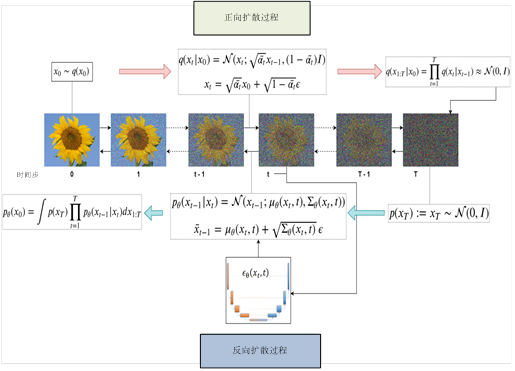
7.改进DDPM
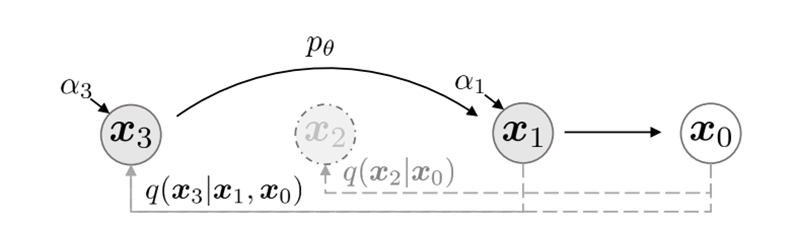
对于扩散模型来说,需要设置较长的扩散步数才能得到好的效果,但这导致了生成样本的速度较慢,比如扩散步数T为1000的话,那么生成一个样本(从噪声到数据,从t=T到t=0)就要模型依次(而不能平行)推理1000次,这使用生成过程非常缓慢。针对这一问题去噪扩散隐式模型(Denoising Diffusion Implicit Models,DDIM)提出一种更高效(快几十倍)的采样方法,生成图像时使用更少的采样步数,却能获得相同甚至更好的性能。DDIM和DDPM有相同的训练目标,但是它不再限制扩散过程必须是一个马尔卡夫链,这使得DDIM可以采用更小的采样步数来加速生成过程。
设计了两种方法来采样子序列方法,分别是:
线性法(Linear):采用线性的序列;![T_i=[C*i]](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_804a84d357dd8e2a67e038c9763eb063.gif)
平方法(Quadratic):采样二次方的序列;![T_i=[C*i^2]](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_fc23122d22fd48c921cd0d431ddda821.gif)
其中C是一个定数,其设置原则是使T[-1]接近T。下图为T=[1,3]的简单示例:
改进效果如何?
对比DDPM与DDIM的效果比较:

上表为不同的η下以及不同采样步数下的对比结果,可以看到DDIM(η=0)在较短的步数下就能得到比较好的效果,媲美DDPM(η=1)的生成效果。如果设置为50,那么相比原来的生成过程就可以加速20倍。
8.Sora的核心架构DiTs
DiTs的主要目的就是用Transformer架构替换DDPM中U-Net主干网络。DiTs架构如下:
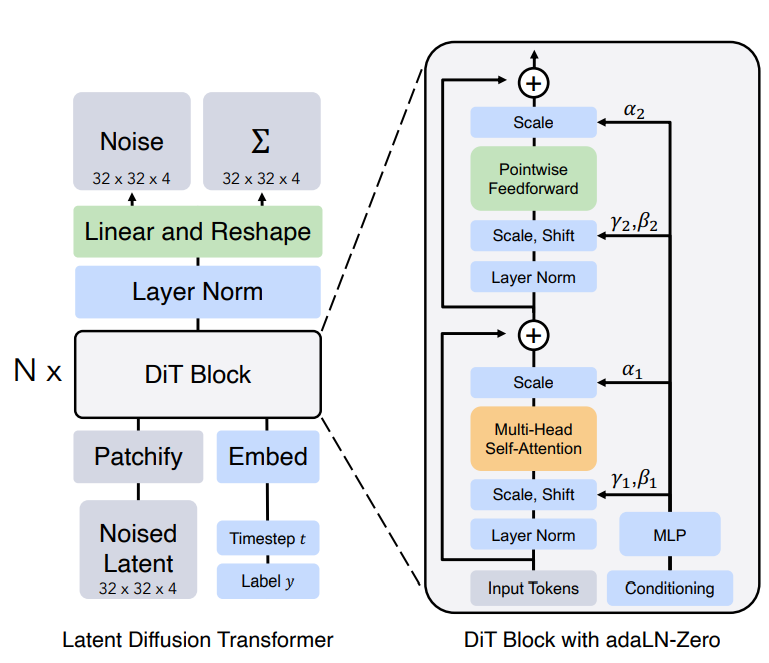
DiT基于Vision Transformer(ViT)架构,该架构在块(patches)序列上运行。DiT保留了ViTs的许多最佳实践。