第2章 MySQL入门
2.1 MySQL简介
2.1.1数据库泛述
为什么要学习数据库?
这个问题我觉得还是从反面来回答比较好,数据库出故障了,会发生啥呢?
学数据库与我找工作或找到更好工作有关系吗?有,关系还很大哦。当然,如果你去应聘不用电脑的职业除外。否则,很可能产生“一丑遮百俊”。
学了数据库有哪些好处?
其他好处不好说,但如果你学了熟悉数据库,对学习其他技术有非常大得帮助,尤其对学习大数据相关技术如Hive、HBase、SparkSQL、SparkRDD等等更是如此,数据库很多都是相通或相似的,学好一个学其他的就轻松多了。
有哪些数据库?
数据库种类很多,从大得方面来说,可分为关系型数据库和非关系型数据库,如MySQL、SQL Server、Oracle、DB2、Sybase等属于关系型数据库,近些年比较火的HBase、MongoDB、Redis等属于非关系型数据库,从存储方式方面来说,可分为行存储数据库、列存储数据库、键值数据库、NoSQL数据库等,当然各类关系型数据库或非关系型数据库自身都各有一些特点。这里就不展开说了。
如何学习数据库?
这个问题有点仁者见仁智者见智,一百人可能有一百个答案,不过我个人认为,数据库作为一个基础性非常强、使用非常广泛的系统,多花些时间进行一些有系统的学习是非常必要,好的基础将大大提升你的竞争力、拓展你的职业发展空间。
2.1.2 MySQL特点
为何选择MySQL? 它有哪些特点?
MySQL是由原MySQL AB公司自主研发的,现在已经被Sun公司收购,是目前IT行业最流行的开放源代码的数据库管理系统,同时它也是一个支持多线程高并发多用户的关系型数据库管理系统。支持Linux、Windows、MAC等多种操作系统,虽然功能上没有其他的大型数据库Oracle、DB2等那么齐全,但好用、易用、开源、可靠性等特点受到成千上万企业和用户的青睐重要原因。
向大家推荐几个学习MySQL的网站:
MySQL社区:http://www.mysqlpub.com/
MySQL菜鸟教程: http://www.runoob.com/mysql/mysql-tutorial.html
MySQL官网:http://www.mysql.com/
《深入浅出MySQL》唐汉名等著
2.1.3 数据库基础
数据库是一个长期存储在计算机内的、有组织、共享、统一的数据集合。作为关系型数据其关系可理解为数据库表,表是一系列二维数组的集合。
表定义:表(Table),在关系型数据库中,表是一系列二维数组的集合,由纵向的列和横向的行组成,列又称为字段,行又称为记录。
表样例:stud_info(学生基本信息表)

表要素有:
关系或表、列,字段行,记录
数据类型:
字符串数据类型、整数型、日期/时间类型、浮点数据型等
关键字,主键:
主键(Primary key),唯一标志表的每一条记录,可以定义表中一列或多列为主键, 主键列上不能有重复的值,也不能为空,如stud_info表中代码字段为该表的主键。
关系模式或表结构,格式为:表名称(属性1,属性2,…属性n)
2.1.4 数据库语言
我们一般通过数据库语言与数据库打交道,其中SQL是我们常用的,SQL的含义是结构化查询语言(Structured Query Language)。
SQL语言分类
数据定义语言(DDL)
如:DROP,CREATE,ALTER等
数据操作语言(DML)
如:INSERT,UPDATE,DELETE等
数据查询语言(DQL)
SELECT等
数据控制语言(DCL)
GRANT,REVOKE,COMMIT,ROLLBAK等。
为进一步理解SQL语句含义,下面以创建一张表的SQL语句为例,表名为t_student,具体SQL语句如下:
(
stud_id INT NOT NULL,
stud_name VARCHAR(40) NOT NULL,
stud_sex CHAR(1),
stud_birthday DATE,
PRIMARY KEY (stud_id)
);
这是一个典型的数据定义语言(DDL),该表共有4个字段,分别为stud_id,stud_name,stud_sex,stud_birthday,其中stud_id为主键。
目前这个表是空表,只有结构没有数据,我们可以用数据操作语句(DML)往表插入记录或数据。
VALUES(1001001,'刘芳','F','1995-06-19');
以上记录是否成功插入到表中呢?我们可以通过数据查询语言(DQL)来验证一下:
+---------+-----------+----------+---------------+
| stud_id | stud_name | stud_sex | stud_birthday |
+---------+-----------+----------+---------------+
| 1001001 | 刘芳 | F | 1995-06-19
2.1.5 数据库系统架构
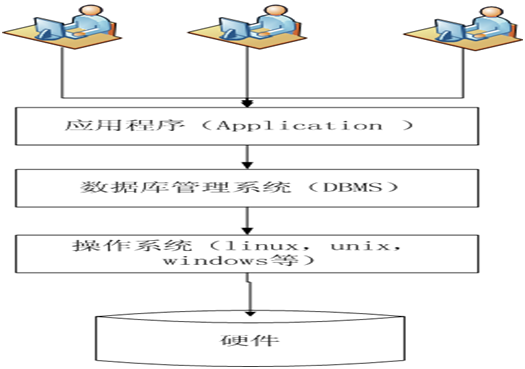
(图1-1 数据库系统架构)
2.1.6 Windows平台下安装配置
MySQL支持多平台,如常见的windows,linux等,这里我们以Windows下安装为主,然后简单说明在Linux平台上的安装。
这里介绍一个针对初学者的Windows版的MySQL安装程序(mysqlSetup.exe,文件下载链接:http://pan.baidu.com/s/1kVHK3eZ),文件大小为35M左右,版本为V5.0,依赖较少,安装方便,但基础功能都有。
以下为详细的安装步骤:
第1步:点击“mysqlSetup.exe”文件,弹出如下界面
第2步:选择安装类型,选择typical(典型安装)。

第3步:是否注册,选择skip sign-up(不注册)
第4步:开始配置服务器
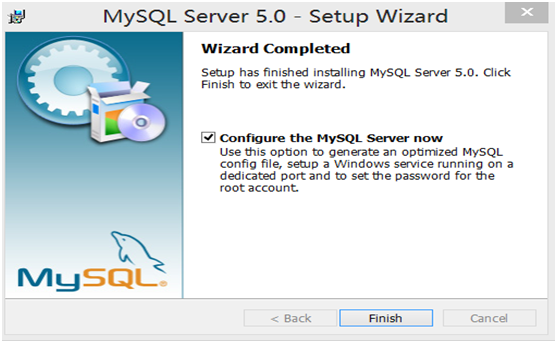
第5步:在配置类型界面中,选择Detailed configuration(详细配置)

第6步:在服务器类型中,作为初学者,可以选择Developer Machine(作为开发机),占用系统资源较少,但基本功能都有。
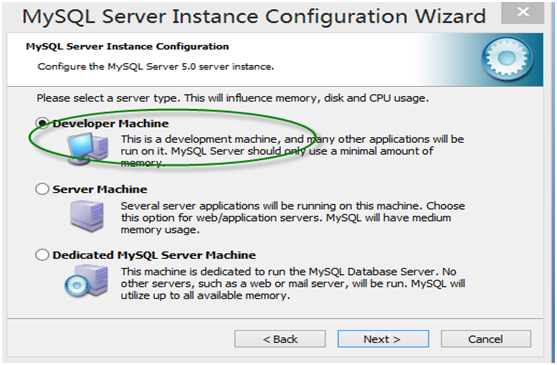
第7步:字符集选择界面,第一个为西文编码,第二个是多字节的通用utf8编码,都不是我们通用的编码,这里选择第三个,然后在Character Set那里选择或填入“gbk”,当然也可以用“gb2312”,区别就是gbk的字库容量大,包括了gb2312的所有汉字。
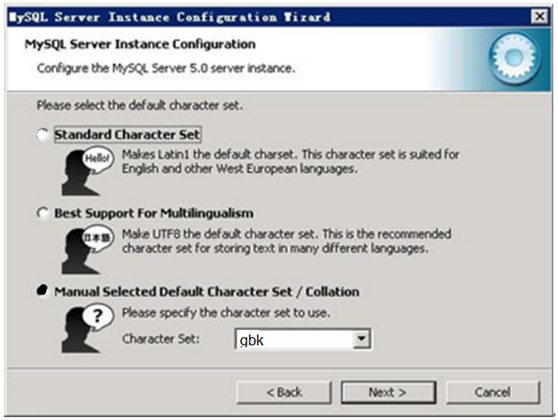
第8步:在数据库用途界面,选择Mutifunctional Database(多功能数据库)。
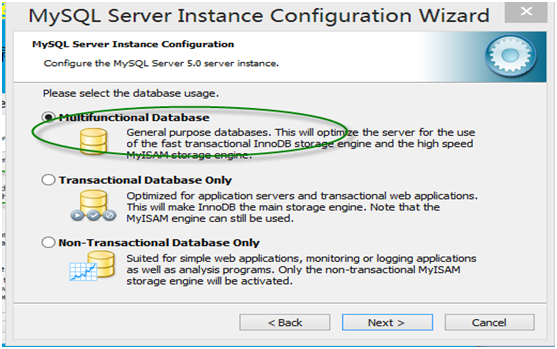
第9步:进入服务器最多并发连接数界面,作为初学者,不涉及很复杂的业务逻辑,而且并发数也需要很多,可选择第一项OLAP或OLTP,并发连接数(concurrent connection)缺省为15,当然你也可以根据需要进行修改。

第10步:配置网络,使用缺省配置即可。

第11步:在Windows设置界面,记得在勾上“Inclode bin Directory in windows PATH”,这样自动把mysql命令所在目录放在Windows的环境变量Path中,接下来你便可在任何目录下启动mysql。
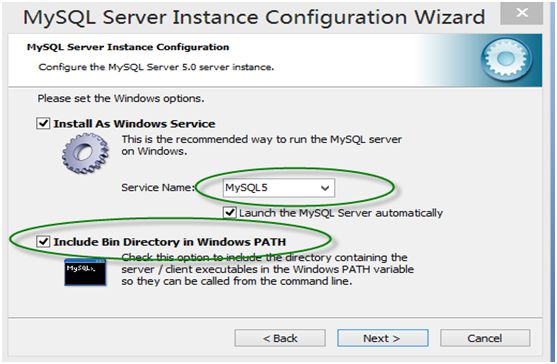
第12步,确认root用户密码
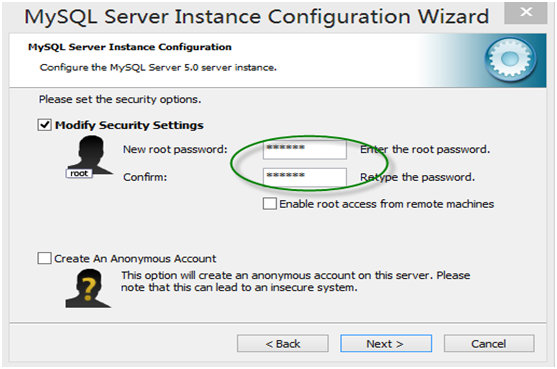
第13步,显示将执行的内容(无需选择),点击“Execute”
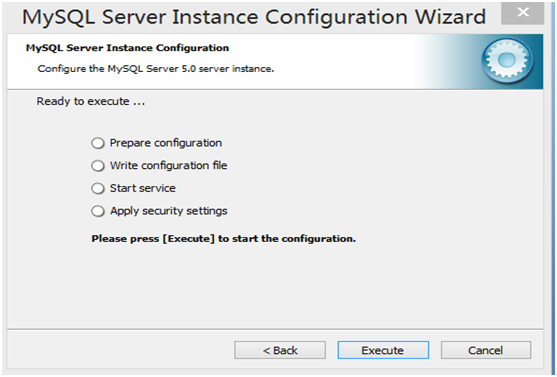
第14步安装结束
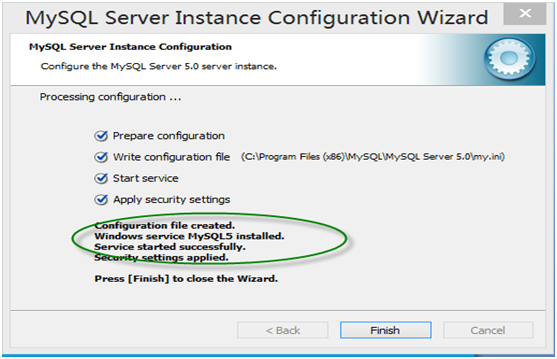
第15步登录MyQL系统。
通过Windows命令行登录
第1步,从开始菜单选择“运行”,打开运行对话框,输入‘cmd’
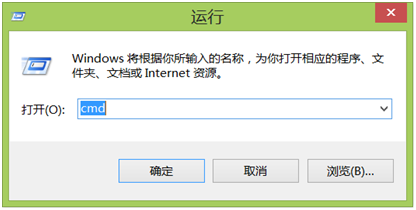
第2步,按确定,打开DOS窗口。
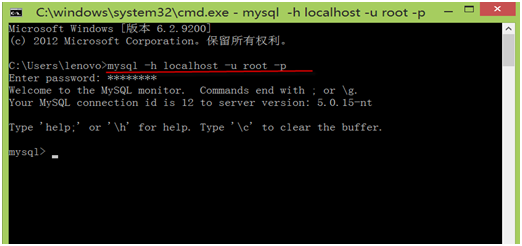
第3步,在DOS窗口中,可以通过输入命令登录MySQL系统,命令格式为:
mysql -h hostname -u username -p
其中mysql为登录命令,
-h 后的参数为服务器名称或IP地址,如果为本地服务器,可为localhost 或127.0.0.1, -u后的参数为用户名称,还没有创建其他用户时,只有root用户。
-p 后的参数为用户密码。
第4步,退出mysql系统,只要在mysql>后,输入quit 然后回车即可。
通过MySQL命令行登录
选择“开始”菜单,点击含“MySQL Command Line Client”字样的图标,进入登录界面,然后输入root用户密码即可登录。
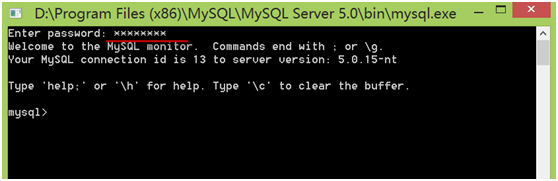
这是在登录windows下MySQL系统的几种方式,下章我们将介绍如何登录远程服务器上的MySQL系统。
2.2 维护表结构
在关系型数据库中,表是是数据库中最重要、最基本的操作对象,是数据存储的基本单位,数据是按行存储的(非关系型数据库有些是按列存储的),同时通过表中的主键、外键、索引、非空等约束来保证数据的一致性和完整性。这一章主要介绍数据表的基本操作:如何创建表、查看表的结构、修改数据表、删除数据表等。
创建表的方式,可以命令行的方式,也可以通过客户端(navicat for mysql)或通过该客户端的建模方式创建,然后,把模型同步到数据库即可。
2.2.1 创建表
创建表的过程就是确定数据列的属性、制定数据完整性、一致性等约束的过程。而这些约束主要通过主键、外键、是否可空、索引等约束来实现的。
创建表的语法形式:
CREATE TABLE 表名称
(
字段名称1 数据类型 [列级的约束] [默认值],
字段名称2 数据类型 [列级的约束] [默认值],
--------
[表级的约束]
);
注:
(1)、表的名称不区分大小写,不能以SQL中的一些关键字为表名,如CREATE、ALTER、INSERT等;
(2)、列名间用逗号隔开。
下面以创建一个学生的基本信息表为例,说明如何创建一张表。
表的定义或结构如下:
学生信息(t_stud_info)表结构
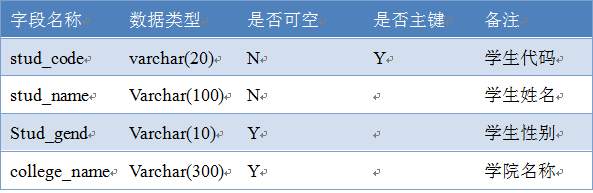
注:
(1)、stud_code这个字段为主键,作为主键(PRIMARY KEY)的字段不能为空,为空的字段不能为主键,主键可以建的一个字段上,也可建的两个或两个以上的字段上,称为组合主键;
(2)、非空字段,是指这些字段的值,不能为空(即为null)。
创建表的SQL语句:
CREATE TABLE t_stud_info
(
stud_code varchar(20) NOT NULL,
stud_name varchar(100) NOT NULL,
stud_gend varchar(10) ,#没有说明NULL,说明是NULL
college_name varchar(300) NULL,
PRIMARY KEY (stud_code) #指明构成主键的字段
);#最后是分号
创建表的SQL以写好,如何执行,如何查看表结构?通过实例来说明:
直接把创建表的SQL语句放在mysql命令行执行:
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> CREATE TABLE t_stud_info
-> (
-> stud_code varchar(20) NOT NULL,
-> stud_name varchar(100) NOT NULL,
-> stud_gend varchar(10) ,
-> college_name varchar(300) NULL,
-> PRIMARY KEY (stud_code)
-> );
Query OK, 0 rows affected (0.31 sec)
mysql> show tables; ###查看已创建的表
+------------------+
| Tables_in_testdb |
+------------------+
| stud_info |
| stud_info_copy |
| stud_score |
| stud_score_view |
| t_stud_info | ###表创建成功
+------------------+
5 rows in set (0.00 sec)
mysql> desc t_stud_info; ###查看表结构
+--------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+--------------+------+-----+---------+-------+
| stud_code | varchar(20) | NO | PRI | NULL | |
| stud_name | varchar(100) | NO | | NULL | |
| stud_gend | varchar(10) | YES | | NULL | |
| college_name | varchar(300) | YES | | NULL | |
+--------------+--------------+------+-----+---------+-------+
4 rows in set (0.17 sec)
mysql> show create table t_stud_info \G ###查看表的详细信息
*************************** 1. row ***************************
Table: t_stud_info
Create Table: CREATE TABLE <code>t_stud_info</code> (
<code>stud_code</code> varchar(20) NOT NULL,
<code>stud_name</code> varchar(100) NOT NULL,
<code>stud_gend</code> varchar(10) DEFAULT NULL,
<code>college_name</code> varchar(300) DEFAULT NULL,
PRIMARY KEY (<code>stud_code</code>)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ###表的存储引擎、字符集。
通过执行脚本创建表
如果一次要创建几十张表,把创建表的语句直接放在mysql命令行运行就不方便了,此时我们可以把创建这些表的SQL语句保存本地当前目录下,名为t_stud_info.sql的文件中,,具体内容请参看以下system cat t_stud_info.sql部分,然后用source命令在mysql命令下执行这个文件即可。这个source命令有点像shell命令。
DROP TABLE IF EXISTS t_stud_info;
CREATE TABLE t_stud_info
(
stud_code varchar(20) NOT NULL,
stud_name varchar(100) NOT NULL,
stud_gend varchar(10) ,
college_name varchar(300) NULL,
PRIMARY KEY (stud_code)
);
mysql> source t_stud_info.sql;
Query OK, 0 rows affected (0.03 sec)
mysql> show tables;
+------------------+
| Tables_in_testdb |
+------------------+
| stud_info |
| stud_score |
| t_stud_info | ###表创建成功
+------------------+
除了以上两种方法外,还有其他方法,如通过客户端创建、通过模型来创建等等,这里就不展开来说了。
2.2.2 修改表结构
表创建好以后,有时间我们可能根据新的需求,需要修改字段类型、字段名称、添加字段、新建其它约束如索引、是否可空等。当表中无数据时做这些修改比较方便,如果表已有数据可能就需要慎重,否则可能导致修改失败,此时建议备份原表数据,然后清空数据,再做修改,修改后根据新的规则把数据导入新表中。但添加字段、放大自动长度等与是否有数据无关。
2,2.2.1 修改字段类型
如果发现创建的表的某个字段长度太小,需要放大其长度,该如何修改呢?我们可以使用ALTER TABLE 语句来修改。
【注意】如果是正式环境的数据,记得先备份,后修改,有备无患。
修改表字段类型的语法格式:
ALTER TABLE <表名> MODIFY <字段名><字符类型>;
我们创建一张表test01 (a1 varchar(20),a2 int,a3 date),然后,修改a1字段的数据类型,由varchar(20)改为varchar(60)。具体操作如下:
-> (
-> a1 varchar(20),
-> a2 int,
-> a3 date
-> );
Query OK, 0 rows affected (0.07 sec)
mysql> DESC test01; ###查看表结构
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| a1 | varchar(20) | YES | | NULL | |
| a2 | int(11) | YES | | NULL | |
| a3 | date | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.01 sec)
mysql> ALTER TABLE test01 MODIFY a1 varchar(60); ###修改字段a1类型
Query OK, 0 rows affected (0.24 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> DESC test01;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| a1 | varchar(60) | YES | | NULL | | ###修改成功
| a2 | int(11) | YES | | NULL | |
| a3 | date | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
大家考虑一下,是否可以把INT修改为字符型,或把字符型修改整数型?如果要修改需要满足哪些条件?
除了可以修改字段类型,我们还可以修改表名称、字段名称、字段属性等。
2.2.2.2 修改字段名称
修改字段名称的语句与修改字段类型的不一样,其语法格式为:
ALTER TABLE <表名> CHANGE <旧字段名><新字段名><数据类型>;
现在我们把test01表中a1字段名称改为name,数据类型不变。
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| a1 | varchar(60) | YES | | NULL | |
| a2 | int(11) | YES | | NULL | |
| a3 | date | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
mysql> ALTER TABLE test01 CHANGE a1 name varchar(60); ###把字段a1改为name
Query OK, 0 rows affected (0.38 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc test01;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| name | varchar(60) | YES | | NULL | | ###修改成功
| a2 | int(11) | YES | | NULL | |
| a3 | date | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2.2.2.3 新增字段
表创建后,根据需要我们可以修改表名、修改表中字段名称、字段类型,当然也可添加字段,而且可以更加指定位置的添加,如果没有指定,缺省是添加到最后。添加字段的语法格式为:
ALTER TABLE <表名> ADD <新增字段名><字段类型> [字段约束条件][FIRST|AFTER 已有字段名];
我们还是以test01表为例,在name字段后,添加一个名为code的字段,数据类型为varchar(20),并且不能为空或not null。
Query OK, 0 rows affected (0.17 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc test01;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| name | varchar(60) | YES | | NULL | |
| code | varchar(20) | NO | | NULL | |
| a2 | int(11) | YES | | NULL | |
| a3 | date | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2.2.3 修改表的字符集
表的字符集或缺省字符集也能修改?能,这应该也是MySQL特色之一吧,一般数据库系统字符集与数据库绑定在一起,但MySQL把字符集粒度精确到了表甚至字段。虽然这个功能很强大,但也存在很大风险,特别是表中有数据时,可能导致字符类型不兼容问题,为降低风险,还是这句老话,先备份,后修改。
这里的修改一般指修改表的缺省字符集,常用的字符集有:UTF8、GBK、GB2312、latin1等,其中UTF-8用以解决国际上字符的一种多字节编码,它对英文使用8位(即一个字节),中文使用24为(三个字节)来编码。UTF-8包含全世界所有国家需要用到的字符,是国际编码,通用性强。GBK是国家标准GB2312基础上扩容后兼容GB2312的标准。GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示,为了区分中文,将其最高位都设定成1。GBK包含全部中文字符,是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBK大。
GBK、GB2312等与UTF8不兼容,需要通过Unicode编码才能相互转换:
GBK、GB2312--Unicode--UTF8
UTF8--Unicode--GBK、GB2312 。
字符集涉及面比较广,如服务器或数据库或表字符集、应用字符集(如连接字符集、文件字符集等)、客户端字符,一般这些环节的字符集需要一致或兼容,尤其对中文而言,否则可能导致乱码。如何解决乱码问题,后面我们也有介绍。
以下是修改表的字符集的一个简单实例:
+--------+---------------------------------------------------------------------| Table | Create Table
+--------+---------------------------------------------------------------------| test01 | CREATE TABLE <code>test01</code> (
<code>name</code> varchar(60) DEFAULT NULL,
<code>code</code> varchar(20) NOT NULL,
<code>a2</code> int(11) DEFAULT NULL,
<code>a3</code> date DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 | ###缺省字符集为utf8
----------------------------------+
mysql>ALTER TABLE test01 CONVERT TO CHARACTER SET gbk; ###修改缺省字符集为gbk
Query OK, 0 rows affected (0.12 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table test01 ; ###检查修改是否成功
+--------+---------------------------------------------------------------------| Table | Create Table
+--------+---------------------------------------------------------------------| test01 | CREATE TABLE <code>test01</code> (
<code>name</code> varchar(60) DEFAULT NULL,
<code>code</code> varchar(20) NOT NULL,
<code>a2</code> int(11) DEFAULT NULL,
<code>a3</code> date DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=gbk | ###修改成功
修改方式或命令还有很多,大家可以借助其强大的help进一步获取其他命令的使用方法,如可以通过help ALTER TABLE查询其他使用方法,这里就不在一一例举了。
2.2.4 插入数据
往表中插入数据,有多种方法,如通过SQL语句、客户端、数据备份工具等。
1、通过SQL命令:insert into table_name (列1,列2,..) Values(‘’,’’,’’,….);
用这种方法需要注意列与值的对应关系;如果不指定列名,则指所有列:
如insert into table_name values(‘’,’’,’’,…),values(),
2、通过客户端导入;
3、利用工具(load data file或mysqlimport等)借助数据文件来导入数据。
这里我们介绍第1种方法,其它2种后面讲数据备份时将介绍。
往表test01插入一条记录。
Empty set (0.01 sec)
mysql> INSERT INTO test01(name,code,a2,a3)
-> VALUES('mysql','001',10,'2016-10-30'); ###插入1条记录
Query OK, 1 row affected (0.07 sec)
mysql> select * from test01;
+-------+------+------+------------+
| name | code | a2 | a3 |
+-------+------+------+------------+
| mysql | 001 | 10 | 2016-10-30 | ###插入成功
+-------+------+------+------------+
这是往插入1条记录,如果想一次往表插入多条记录如何实现呢?我们只要在后面添加个values即可,如同时往表中插入2条记录:
insert into table_name values(‘’,’’,’’,…) ,(‘’,’’,’’,…)
注意记录间用逗号。
具体操作请看下例
-> VALUES('linux','002',20,'2016-10-30'),
-> ('spark','003',30,'2016-10-30');
Query OK, 2 rows affected (0.06 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from test01; ###检查结果,插入成功
+-------+------+------+------------+
| name | code | a2 | a3 |
+-------+------+------+------------+
| mysql | 001 | 10 | 2016-10-30 |
| linux | 002 | 20 | 2016-10-30 |
| spark | 003 | 30 | 2016-10-30 |
+-------+------+------+------------+
2.3 增删改数据
存储数据时用来查询分析用的,所以查询分析数据是平时重要任务,但数据库中数据它不会自动生成,需要我们去维护,当然大部分是系统自动维护,不需要手工去操作,不过维护程序还是需要写的,这章我们介绍如何维护数据库数据。这里我们主要介绍如何新增数据、如何修改数据、如何删除数据等。
2.3.1 插入数据
插入数据语句的语法:
INSERT INTO表名[(列名1,……列名n)] values(值1,…..值n);
这个SQL语句一次往表中插入1条记录,如果一次要插入多条记录是否可以呢?可以,而且很方便,插入多条语句为:
INSERT INTO表名[(列名1,……列名n)] VALUES(值1,…..值n), (值1,…..值n),..;
下面我们还是通过一些实例来进步说明如何操作。
Query OK, 0 rows affected (0.17 sec)
mysql> DESC TEST03; ###查看表结构
ERROR 1146 (42S02): Table 'testdb.TEST03' doesn't exist
mysql> DESC test03;
+----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+-------+
| id | int(11) | NO | | NULL | |
| name | varchar(20) | YES | | NULL | |
| birthday | date | YES | | NULL | |
+----------+-------------+------+-----+---------+-------+
3 rows in set (0.04 sec)
mysql> INSERT INTO test03 VALUES(100,'张华', '2000-01-01'); ##对所有字段插值
Query OK, 1 row affected (0.16 sec)
mysql> INSERT INTO test03(id,name) VALUES(200,'刘婷'); ###选择字段插值
Query OK, 1 row affected (0.13 sec)
mysql> SELECT * FROM test03;
+-----+--------+------------+
| id | name | birthday |
+-----+--------+------------+
| 100 | 张华 | 2000-01-01 |
| 200 | 刘婷 | NULL |
+-----+--------+------------+
2 rows in set (0.00 sec)
mysql> INSERT INTO test03(id,name) VALUES(300,'貂蝉'),(400,'吕布'); ##插入多条
Query OK, 2 rows affected (0.03 sec)
Records: 2 Duplicates: 0 Warnings: 0
2.3.2 修改数据
修改数据也是很常见的,不过修改数据前,记得备份数据。如何备份数据后面将介绍。
修改数据的一般语法:
UPDATE表名SET列名1=值1,….列名n=值n
[WHERE条件];
以下以修改id为200对应的name为例,假设发现id为200对应的name输错了,不是刘婷,而是刘涛。
Query OK, 1 row affected (0.02 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT * FROM test03 WHERE id=200; ###查询验证结果
+-----+--------+----------+
| id | name | birthday |
+-----+--------+----------+
| 200 | 刘涛 | NULL | ###修改成功
+-----+--------+----------+
1 row in set (0.00 sec)
2.3.3 删除数据
删除数据时,我们可以选择删除几条,或满足某些条件的记录,当然也可以删除所有记录。在日常工作中,删除数据需要非常谨慎,务必养成一个良好习惯,先备份,后删除。对生产环境数据、或正式环境的数据,不建议物理删除,最好采用逻辑删除的方式(即修改对应记录的状态或有效时间等)。数据都有价值。
用DELETE删除数据的一般语法:
DELETE FROM表名 [WHERE条件];
DELETE 加上条件,就可以有条件删除记录;如果没有条件,将删除所有数据。删除所有数据也可用TRUNCATE命令(这种方式删除数据比较快),其命令格式为:
TRUNCATE [table] 表名;
使用DELETE FROM 表名或TRUNCATE [table] 表名命令删除全部记录时,有一种情况需要注意,如果一个表中有自增字段,这个自增字段将起始值恢复成1.如果你不想这样做的话,可以在DELETE语句中加上永真的WHERE,如WHERE 1或WHERE true。
+-----+--------+------------+
| id | name | birthday |
+-----+--------+------------+
| 100 | 张华 | 2000-01-01 |
| 200 | 刘涛 | NULL |
| 300 | 貂蝉 | NULL |
| 400 | 吕布 | NULL |
+-----+--------+------------+
4 rows in set (0.00 sec)
mysql> DELETE FROM test03 WHERE (id=300 or id=400);
Query OK, 2 rows affected (0.02 sec)
mysql> SELECT * FROM test03;
+-----+--------+------------+
| id | name | birthday |
+-----+--------+------------+
| 100 | 张华 | 2000-01-01 |
| 200 | 刘涛 | NULL |
+-----+--------+------------+
2 rows in set (0.00 sec)
mysql> DELETE FROM test03;
Query OK, 2 rows affected (0.01 sec)
mysql> SELECT * FROM test03;
Empty set (0.00 sec)
2.4 查询数据
数据库主要功能是存储数据,但存储数据不是最终目的,存储数据最终目的是为了展示和分析,如何分析展示数据库中数据,数据查询就是重要手段。MySQL提供了功能强大、又非常灵活、非常方便的语句实现这些操作。这一章将介绍使用SELECT语句实现简单查询、子查询、连接查询、分组查询及利用正则表达式查询等。
2.4.1 一般查询语句
最简单的是SELECT [列名]FROM [表名] WHERE [条件] 。然后你可以在后面加上像[LIMIT][ORDER BY][GROUP BY][HAVING]等。
[列名]: 可以多个字段(列间用逗号分隔),也可所以字段(一般用*表示所有字段)
[表名]: 可以是一个表名或视图名,也可以是多表或多视图(表间用逗号分隔)。
[条件]: 为可选项,如果选择该项,将限制行必须满足的查询条件。
[LIMIT]: 后跟[位置偏移量,] 行数(第1行的位置偏移量为0,第2行为1,以此类推。)
[ORDER BY]: 后跟字段,可一个或多个,根据这些字段进行分组。
[GROUP BY]: 后跟可一个或多个字段,根据这些字段进行排序,升序(ASC)或降序(DESC)。
其后也可跟WITH ROLLUP,增加一条合计记录。
[HAVING]: 一般与GROUP BY一起使用,用来显示满足条件的分组记录。
2.4.2 单表查询
单表查询就是从1张表中查询数据,后续将介绍多表查询。为查询表数据我们需要先做些准备工作。
2.4.2.1 准备工作
准备工作包括:1、定义表结构,创建表;2、查看分析数据文件;3.把数据导入到表中。
1.首先我们创建一个存储学生各科成绩的表(stud_score),表的定义如下:

(表6-1 学生成绩表 stud_score)
字段名称 字段描述 数据类型 主键 外键 非空 自增
stud_code 学生代码 VARCHAR(20) 是 否 是 否
sub_code 学科代码 VARCHAR(20) 是 否 是 否
sub_name 学科名称 VARCHAR(100) 否 否 否 否
sub_tech 学科老师代码 VARCHAR(20) 否 否 否 否
sub_score 学科成绩 SMALLINT(10) 否 否 否 否
stat_date 统计日期 DATE 否 否 否 否
转换为建表的SQL语句为:
DROP TABLE IF EXISTS stud_score;
CREATE TABLE stud_score (
stud_code varchar(20) NOT NULL,
sub_code varchar(20) NOT NULL,
sub_name varchar(100) default NULL,
sub_tech varchar(20) default NULL COMMENT '教师代码',
sub_score smallint(10) default NULL,
stat_date date default NULL,
PRIMARY KEY (stud_code,sub_code)
);
2、创建这个表以后,我们需要把一个包含该表数据的文件(在slave02节点的/tmp目录下,名称为stud_score.csv)导入该表,另该文件第1行为字段名称,需过滤掉。我们先操作,具体语法等我们后续会介绍。
查看该数据文件信息
/tmp
hadoop@master:/tmp$ ls -l |grep 'stud*'
-rw-rw-r-- 1 feigu feigu 1508 Jul 6 15:47 stud_info.csv
-rw-rw-rw- 1 mysql mysql 7157 Jul 2 11:32 stud_score_0702.txt
-rw-rw-rw- 1 mysql mysql 7157 Jul 2 21:43 stud_score_0703.txt
-rw-rw-r-- 1 feigu feigu 4652 Jul 2 10:26 stud_score.csv
hadoop@master:/tmp$ head -2 stud_score.csv
stud_code,sub_code,sub_nmae,sub_tech,sub_score,stat_date
2015101000,10101,数学分析,,90,
hadoop@master:/tmp$ cat stud_score.csv |wc -l ###查看文件记录总数
122
3.把数据文件导入表中
Query OK, 0 rows affected (0.36 sec)
mysql> CREATE TABLE stud_score ( ###创建表
-> stud_code varchar(20) NOT NULL,
-> sub_code varchar(20) NOT NULL,
-> sub_name varchar(100) default NULL,
-> sub_tech varchar(20) default NULL COMMENT '教师代码',
-> sub_score smallint(10) default NULL,
-> stat_date date default NULL,
-> PRIMARY KEY (stud_code,sub_code)
-> );
Query OK, 0 rows affected (0.07 sec)
mysql> select * from stud_score; ###查看是否有数据
Empty set (0.00 sec)
mysql> load data infile '/tmp/stud_score.csv' into table stud_score fields terminated by "," ignore 1 lines; ###把数据导入到表中
Query OK, 121 rows affected, 121 warnings (0.25 sec)
Records: 121 Deleted: 0 Skipped: 0 Warnings: 121
mysql> select count(*) from stud_score; ###查看验证记录总数
+----------+
| count(*) |
+----------+
| 121 |
+----------+
1 row in set (0.07 sec)
2.4.2.2 查看指定行数据
+------------+----------+--------------+----------+-----------+------------+
| stud_code | sub_code | sub_name | sub_tech | sub_score | stat_date |
+------------+----------+--------------+----------+-----------+------------+
| 2015101000 | 10102 | 高等代数 | | 88 | 0000-00-00 |
| 2015101001 | 10102 | 高等代数 | | 78 | 0000-00-00 |
| 2015101002 | 10102 | 高等代数 | | 97 | 0000-00-00 |
| 2015101003 | 10102 | 高等代数 | | 87 | 0000-00-00 |
| 2015101004 | 10102 | 高等代数 | | 77 | 0000-00-00 |
| 2015101005 | 10102 | 高等代数 | | 65 | 0000-00-00 |
| 2015101006 | 10102 | 高等代数 | | 68 | 0000-00-00 |
| 2015101007 | 10102 | 高等代数 | | 80 | 0000-00-00 |
| 2015101008 | 10102 | 高等代数 | | 96 | 0000-00-00 |
| 2015101009 | 10102 | 高等代数 | | 79 | 0000-00-00 |
| 2015101010 | 10102 | 高等代数 | | 52 | 0000-00-00 |
+------------+----------+--------------+----------+-----------+------------+
mysql> SELECT * FROM stud_score LIMIT 3; ###查看前3行
+------------+----------+--------------+----------+-----------+------------+
| stud_code | sub_code | sub_name | sub_tech | sub_score | stat_date |
+------------+----------+--------------+----------+-----------+------------+
| 2015101000 | 10101 | 数学分析 | | 90 | 0000-00-00 |
| 2015101000 | 10102 | 高等代数 | | 88 | 0000-00-00 |
| 2015101000 | 10103 | 大学物理 | | 67 | 0000-00-00 |
+------------+----------+--------------+----------+-----------+------------+
3 rows in set (0.00 sec)
mysql> SELECT * FROM stud_score LIMIT 2, 2; ###查看第3行开始后2行
+------------+----------+-----------------+----------+-----------+------------+
| stud_code | sub_code | sub_name | sub_tech | sub_score | stat_date |
+------------+----------+-----------------+----------+-----------+------------+
| 2015101000 | 10103 | 大学物理 | | 67 | 0000-00-00 |
| 2015101000 | 10104 | 计算机原理 | | 78 | 0000-00-00 |
+------------+----------+-----------------+----------+-----------+------------+
2 rows in set (0.00 sec)
2.4.2.3 模糊查询
利用LIKE 关键字可以进行模糊查询。下例查询学科代码以101开头的记录总数。
+----------+
| count(*) |
+----------+
| 55 |
+----------+
mysql>select * from stud_info where birthday REGEXP '^1998' ;
mysql> select * from stud_info where birthday REGEXP '10$' ;
2.4.2.4 分组查询
如果我们希望按学科来统计学生成绩、班级成绩该如何实现呢?这就涉及到分组统计问题,如果需要按学科统计,可以GROUP BY sub_code;然后取前3名学科,具体实现请看下例:
+----------+----------------+
| sub_code | SUM(sub_score) |
+----------+----------------+
| 10101 | 863 |
| 10102 | 867 |
| 10103 | 830 |
| 10104 | 932 |
| 10105 | 857 |
| 20101 | 870 |
| 20102 | 892 |
| 20103 | 866 |
| 20104 | 864 |
| 20105 | 822 |
| 20106 | 843 |
+----------+----------------+
11 rows in set (0.00 sec)
mysql> SELECT sub_code,SUM(sub_score) AS sum_score from stud_score GROUP BY sub_code
-> ORDER BY sum_score DESC LIMIT 3; ###按学科总分排序,取前3。
+----------+-----------+
| sub_code | sum_score |
+----------+-----------+
| 10104 | 932 |
| 20102 | 892 |
| 20101 | 870 |
+----------+-----------+
2.4.3 多表查询
多表查询,需要连接2张或2张以上的表一起查询,连接有多种方式,如内连接(通常缺省连接)、外链接(又分为左连接,右连接)等。多表连接时,建议不宜一下连接很多表,尤其是数据比较大时,可以采用两两连接等方式。
要实现多表连接,还需创建一个存储学生基本信息的表(stud_info)并导入数据.
2.4.3.1 准备工作
创建一个学生基本信息的表(表定义如下),并把数据(一个数据文件)导入到表中。
准备步骤,1.定义并创建表,2,查看分析数据文件,3. 导入数据,并验证导入结果。
1.定义并创建表
-> stud_code varchar(20) NOT NULL,
-> stud_name varchar(100) NOT NULL,
-> stud_sex char(1) NOT NULL default 'M' COMMENT '性别',
-> birthday date default NULL,
-> log_date date default NULL,
-> orig_addr varchar(100) default NULL,
-> lev_date date default NULL,
-> college_code varchar(10) default NULL COMMENT '学院编码',
-> college_name varchar(100) default NULL,
-> state varchar(10) default NULL,
-> PRIMARY KEY (stud_code)
-> ) ;
Query OK, 0 rows affected (0.05 sec)
2.查看分析数据文件
-rw-rw-r-- 1 feigu feigu 1508 Jul 6 15:47 stud_info.csv
hadoop@master:/tmp$ cat stud_info.csv|wc -l ###查看文件记录总数
23
hadoop@master:/tmp$ head -3 stud_info.csv ###查看前3行
stud_code,stud_name,stud_gend,birthday,log_date,orig_addr,lev_date,college_code,college_name,state
2015101000,王进,M,1997/8/1,2014/9/1,苏州,,10,理学院,1
2015101001,刘海,M,1997/9/29,2014/9/1,上海,,10,理学院,1
3.导入数据并验证结果
+----------+
| count(*) |
+----------+
| 0 |
+----------+
1 row in set (0.00 sec)
mysql> load data infile '/tmp/stud_info.csv' into table stud_info fields terminated by "," ignore 1 lines;
Query OK, 22 rows affected, 22 warnings (0.05 sec)
Records: 22 Deleted: 0 Skipped: 0 Warnings: 22
mysql> select count(*) from stud_info; ###成功导入22条记录
+----------+
| count(*) |
+----------+
| 22 |
+----------+
1 row in set (0.00 sec)
2.4.3.2 多表连接查询
两表内连接、左连接,右连接的含义及使用关键字请参看下图:
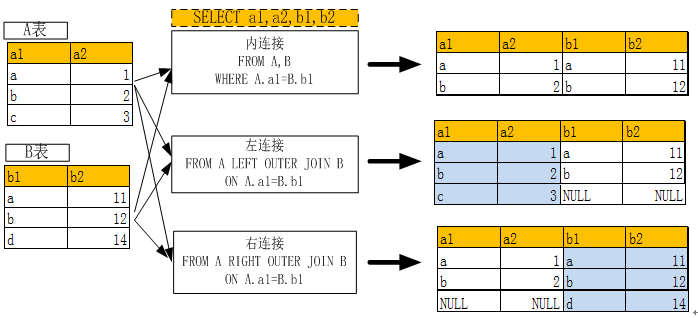
(图6-1 多表连接示意图)
以下通过几个实例进一步说明多表连接的使用方法:
+-----------+--------------+-----------+
| stud_name | sub_name | sub_score |
+-----------+--------------+-----------+
| 王进 | 数学分析 | 90 |
| 王进 | 高等代数 | 88 |
| 王进 | 大学物理 | 67 |
+-----------+--------------+-----------+
mysql> SELECT a.stud_name,b.sub_name,b.sub_score FROM stud_info a LEFT OUTER JOIN stud_score b ON a.stud_code=b.stud_code LIMIT 3; ###左连接
+-----------+--------------+-----------+
| stud_name | sub_name | sub_score |
+-----------+--------------+-----------+
| 王进 | 数学分析 | 90 |
| 王进 | 高等代数 | 88 |
| 王进 | 大学物理 | 67 |
+-----------+--------------+-----------+
3 rows in set (0.00 sec)
mysql> SELECT a.stud_name,b.sub_name,b.sub_score FROM stud_info a RIGHT OUTER JOIN stud_score b ON a.stud_code=b.stud_code LIMIT 3; ###右连接
+-----------+--------------+-----------+
| stud_name | sub_name | sub_score |
+-----------+--------------+-----------+
| 王进 | 数学分析 | 90 |
| 王进 | 高等代数 | 88 |
| 王进 | 大学物理 | 67 |
+-----------+--------------+-----------+
3 rows in set (0.00 sec)
2.4.3.3 子连接查询
这里介绍以用IN关键字实现子链接,基本格式为:
SELECT * FROM 表名WHERE 字段 IN (SELECT 字段 FROM 表名 WHERE 条件);
使用子查询,比较灵活,且有利于把大表关联转换为小表关联。下例为表stud_info中
stud_code从表stud_score中成绩为大于或等于90分的子查询中获取。
+-----------+
| stud_name |
+-----------+
| 王进 |
| 刘海 |
| 张飞 |
+-----------+
3 rows in set (0.02 sec)
2.4.3.4 视图查询
上面的查询语句,有的比较简单,有的比较复杂,像对那些复杂的查询语句,包含了很多信息量,而且有可能还要经常使用,但命令行是无法保证这些语句的,如果下次还要使用是否又重新写一遍呢?大可不必,我们可以把这个查询语句以视图的形式保存到数据库中,然后直接查询这个视图即可。
如上面内连接的SQL语句:SELECT a.stud_name,b.sub_name,b.sub_score FROM stud_info a,stud_score b WHERE a.stud_code=b.stud_code LIMIT 3;
我们可以把它定义为一个视图V_STUD,然后查询视图即可,非常方便!而且视图会保存到数据库中,但视图本身不保存数据。具体实现请看下例:
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT * FROM V_STUD; ###查询视图
+-----------+--------------+-----------+
| stud_name | sub_name | sub_score |
+-----------+--------------+-----------+
| 王进 | 数学分析 | 90 |
| 王进 | 高等代数 | 88 |
| 王进 | 大学物理 | 67 |
+-----------+--------------+-----------+
3 rows in set (0.00 sec)
2.5课后练习
一、在testdb库上创建表,表结构如下:
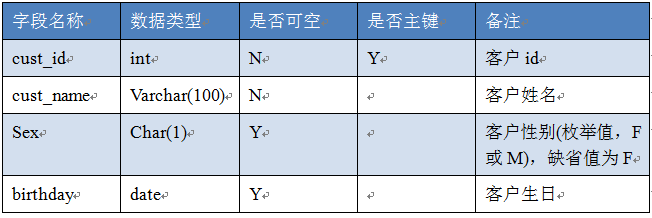
写一个sql文件,功能包括:
1、创建以上表结构,表名为:test_学号;
2、往表test_序号插入至少3条数据;
3、在表最后位置添加一个字段,字段要求如下:

二、创建表并把数据导入表中,然后查询相关数据,把这些操作放到一个SQL文件中,具体要求如下:
1、创建两表,表名分别为,stud_score_学号:stud_info_学号,表结构请参考第6.2.1节和6.3.1节
2、导入数据,把/tmp目录下stud_info.csv,stud_score.csv分别导入到表stud_info_学号,stud_score_学号中
3、查询数据,查询表stud_info_学号中,把姓刘的同学过滤出来。
三、多表查询,在一个SQL语句实现以下功能
1、内连接,实现stud_score_学号:stud_info_学号的内连接,连接字段为stud_code
2、左连接, 实现stud_score_学号:stud_info_学号的左连接,连接字段为stud_code
四、聚合查询
1、把选了大于5门课的同学的名称及各科总成绩打印出来。
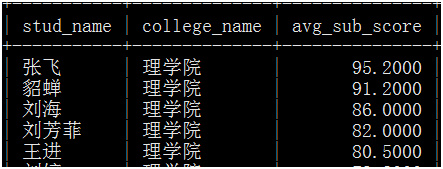
五、写一个存储过程,实现功能,输入学院代码,输出,学生名称、学院名称、各科平均成绩,如下图: