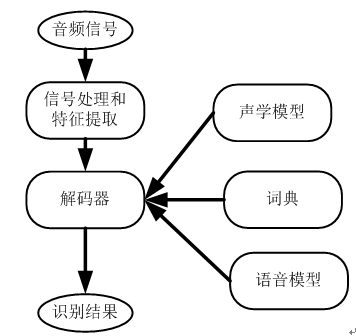
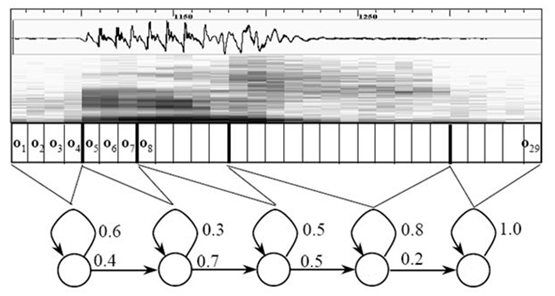
第1章:Keras基础
1.1Keras简介
Tensorflow、theano是神经网络、机器学习的基础框架,但使用它们大家神经网络,尤其深度学习网络,像tensorflow或theano属于符号编程,需要涉及如何定义变量、图形、各层、session、初始化、各种算法等等,有时显得比较繁琐,尤其对新手而言,更是如此,是否有更简单的方法呢?keras就是一个很好工具!Keras是一个高层神经网络API,Keras由纯Python编写而成并基Tensorflow、Theano以及CNTK后端。Keras 为支持快速实验而生,能够把你的想法迅速转换为结果。
其主要特点:
- 简便的原型设计
- 支持CNN和RNN,或二者的结合
- 在CPU和GPU间无缝切换
keras资料:
keras官网:
https://keras.io/
keras中文网
https://keras-cn.readthedocs.io/en/latest/
1.2keras安装
1)安装Python3.6
建议用anaconda安装,先下载最新版anaconda 支持linux或windows
2)安装numpy、scipy
|
|
conda install numpy scipy |
3)安装theano
4) 安装tensorflow
|
|
pip install tensorflow (cpu) pip install tensorfow-gpu (gpu) |
(gpu 需要有GPU卡,并安装GPU驱动及cuda等)
5)安装keras
6)测试
【说明】变更keras后台支持的几种方法
(1)修改~/.keras/keras.json
|
|
hadoop@master:~/.keras$ cat keras.json { "epsilon": 1e-07, "floatx": "float32", "image_data_format": "channels_last", "backend": "tensorflow" } |
(2)在客户端直接修改
改为theano为支持后台
|
|
import os os.environ['KERAS_BACKEND']='theano' |
改为tensorflow为支持后台(缺省)
|
|
import os os.environ['KERAS_BACKEND']='tensorflow' |
在客户端修改,影响范围是当前脚本或session。
1.3 keras常用概念
François Chollet作为人工智能时代的先行者,为无数的开发者提供了开源深度学习框架Keras,目前就职于Google公司,主推tf.keras。
在开始学习Keras之前,我们希望传递一些关于Keras,关于深度学习的基本概念和技术,我们建议新手在使用Keras之前浏览一下本页面提到的内容,这将减少你学习中的困惑。
Keras的底层库使用Theano或TensorFlow,这两个库也称为Keras的后端。无论是Theano还是TensorFlow,都是一个“符号式”的库。
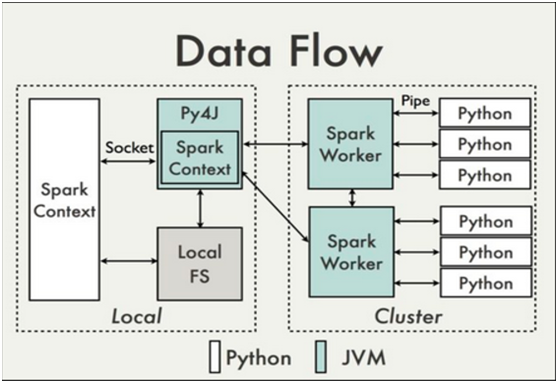
因此,这也使得Keras的编程与传统的Python代码有所差别。笼统的说,符号主义的计算首先定义各种变量,然后建立一个“计算图”,计算图规定了各个变量之间的计算关系。建立好的计算图需要编译以确定其内部细节,然而,此时的计算图还是一个“空壳子”,里面没有任何实际的数据,只有当你把需要运算的输入放进去后,才能在整个模型中形成数据流,从而形成输出值。
就像用管道搭建供水系统,当你在拼水管的时候,里面是没有水的。只有所有的管子都接完了,才能送水。
符号计算也叫数据流图,如下图是一个经典的数据流计算可视化图形。

张量,或tensor,可以看作是向量、矩阵的自然推广,用来表示广泛的数据类型。张量的阶数也叫维度。
0阶张量,即标量,是一个数。
1阶张量,即向量,一组有序排列的数
2阶张量,即矩阵,一组向量有序的排列起来
3阶张量,即立方体,一组矩阵上下排列起来
4阶张量......
依次类推
重点:关于维度的理解
假如有一个10长度的列表,那么我们横向看有10个数字,也可以叫做10维度,纵向看只能看到1个数字,那么就叫1维度。注意这个区别有助于理解Keras或者神经网络中计算时出现的维度问题
张量的阶数有时候也称为维度,或者轴,轴这个词翻译自英文axis。譬如一个矩阵[[1,2],[3,4]],是一个2阶张量,有两个维度或轴,沿着第0个轴(为了与python的计数方式一致,本文档维度和轴从0算起)你看到的是[1,2],[3,4]两个向量,沿着第1个轴你看到的是[1,3],[2,4]两个向量。
数据格式(data_format)
目前主要有两种方式来表示张量:
a) th模式或channels_first模式,Theano和caffe使用此模式。
b)tf模式或channels_last模式,TensorFlow使用此模式。
模式的修改,可以通修改配置文件~/.keras/keras.json中的image_data_format。
下面举例说明两种模式的区别:
对于100张RGB3通道的16×32(高为16宽为32)彩色图,
th表示方式:(100,3,16,32)
tf表示方式:(100,16,32,3)
唯一的区别就是表示通道个数3的位置不一样。
Keras有两种类型的模型,序贯(或序列)模型(Sequential)和函数式模型(Model),函数式模型应用更为广泛,序贯模型是函数式模型的一种特殊情况。
a)序贯模型(Sequential):单输入单输出,一条路通到底,层与层之间只有相邻关系,没有跨层连接。这种模型编译速度快,操作也比较简单
b)函数式模型(Model):多输入多输出,层与层之间任意连接。这种模型编译速度慢。
这个概念与Keras无关,老实讲不应该出现在这里的,但是因为它频繁出现,而且不了解这个技术的话看函数说明会很头痛,这里还是简单说一下。
深度学习的优化算法,说白了就是梯度下降。每次的参数更新有两种方式。
第一种,遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新梯度。这种方法每更新一次参数都要把数据集里的所有样本都看一遍,计算量开销大,计算速度慢,不支持在线学习,这称为Batch gradient descent,批梯度下降。
另一种,每看一个数据就算一下损失函数,然后求梯度更新参数,这个称为随机梯度下降,stochastic gradient descent。这个方法速度比较快,但是收敛性能不太好,可能在最优点附近晃来晃去,hit不到最优点。两次参数的更新也有可能互相抵消掉,造成目标函数震荡的比较剧烈。
为了克服两种方法的缺点,现在一般采用的是一种折中手段,mini-batch gradient decent,小批的梯度下降,这种方法把数据分为若干个批,按批来更新参数,这样,一个批中的一组数据共同决定了本次梯度的方向,下降起来就不容易跑偏,减少了随机性。另一方面因为批的样本数与整个数据集相比小了很多,计算量也不是很大。
基本上现在的梯度下降都是基于mini-batch的,所以Keras的模块中经常会出现batch_size,就是指这个。
epochs指的就是训练过程中数据将被“轮”多少次。
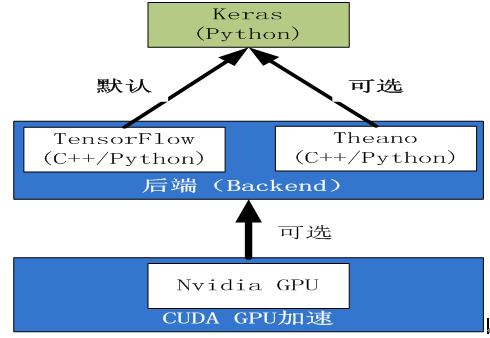
1.4 keras与Tensorflow
1.5 keras的主要模块
【说明】
这里选择了一些常用模块,更多或更详细的说明请参考keras中文网站:
https://keras-cn.readthedocs.io/en/latest/
我们先从总体上了解一下Keras的主要模块及常用层,可参考下图,然后我们对各模块和常用层展开详细说明。
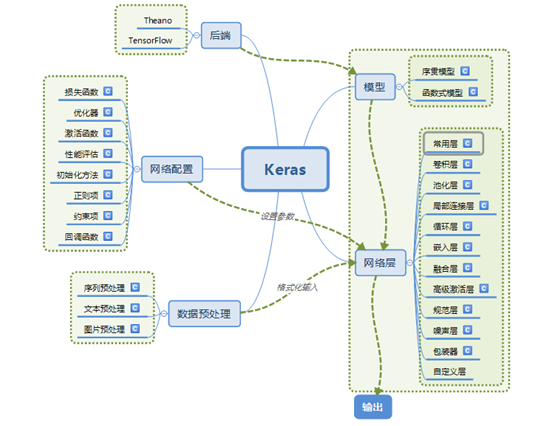
该图取自:http://blog.csdn.net/zdy0_2004/article/details/74736656
1.5.1优化器(optimizers)
优化器是调整每个节点权重的方法,看一个代码示例:
|
|
model = Sequential() model.add(Dense(64, init='uniform', input_dim=10)) model.add(Activation('tanh')) model.add(Activation('softmax')) sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss='mean_squared_error', optimizer=sgd) |
可以看到优化器在模型编译前定义,作为编译时的两个参数之一。
代码中的sgd是随机梯度下降算法
lr表示学习速率
momentum表示动量项
decay是学习速率的衰减系数(每个epoch衰减一次)
Nesterov的值是False或者True,表示使不使用Nesterov momentum
除了sgd,还可以选择的优化器有RMSprop(适合递归神经网络)、Adagrad、Adadelta、Adam、Adamax、Nadam等。
1.5.2目标函数(objectives)
目标函数又称损失函数(loss),目的是计算神经网络的输出与样本标记的差的一种方法,代码示例:
|
|
model = Sequential() model.add(Dense(64, init='uniform', input_dim=10)) model.add(Activation('tanh')) model.add(Activation('softmax')) sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss='mean_squared_error', optimizer=sgd) |
mean_squared_error就是损失函数的名称。
可以选择的损失函数有:
mean_squared_error,mean_absolute_error,squared_hinge,hinge,binary_crossentropy,categorical_crossentropy
其中binary_crossentropy 和 categorical_crossentropy也就是交叉熵为logloss,一般用于分类模型。
1.5.3激活函数(activations)
每一个神经网络层都需要一个激活函数,代码示例:
|
|
from keras.layers.core import Activation, Dense model.add(Dense(64)) model.add(Activation('tanh')) #或把上面两行合并为: model.add(Dense(64, activation='tanh')) |
可以选择的激活函数有:
linear、sigmoid、hard_sigmoid、tanh、softplus、relu、 softplus,softmax、softsign
还有一些高级激活函数,比如如PReLU,LeakyReLU等。
1.5.4 参数初始化(Initializations)
这个模块的作用是在添加layer时调用init进行这一层的权重初始化,有两种初始化方法
1.5.4.1 通过制定初始化方法的名称
示例代码:
|
|
model.add(Dense(64, init='uniform')) |
可以选择的初始化方法有:
uniform、lecun_uniform、normal、orthogonal、zero、glorot_normal、he_normal等。
1.5.4.2 通过调用对象
该对象必须包含两个参数:shape(待初始化的变量的shape)和name(该变量的名字),该可调用对象必须返回一个(Keras)变量,例如K.variable()返回的就是这种变量,示例代码:
|
|
from keras import backend as K import numpy as np def my_init(shape, name=None): value = np.random.random(shape) return K.variable(value, name=name) model.add(Dense(64, init=my_init)) |
或者
|
|
from keras import initializations def my_init(shape, name=None): return initializations.normal(shape, scale=0.01, name=name) model.add(Dense(64, init=my_init)) |
所以说可以通过库中的方法设定每一层的初始化权重,
也可以自己初始化权重,自己设定的话可以精确到每个节点的权重。
1.5.5 常用层(layer)
keras的层主要包括:
常用层(Core)、卷积层(Convolutional)、池化层(Pooling)、局部连接层、递归层(Recurrent)、嵌入层( Embedding)、高级激活层、规范层、噪声层、包装层,当然也可以编写自己的层
1.5.5.1 Dense层(全连接层)
keras.layers.core.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
Dense就是常用的全连接层,所实现的运算是output = activation(dot(input, kernel)+bias)。其中activation是逐元素计算的激活函数,kernel是本层的权值矩阵,bias为偏置向量,只有当use_bias=True才会添加。如果本层的输入数据的维度大于2,则会先被压为与kernel相匹配的大小。
参数:
units:大于0的整数,代表该层的输出维度。
activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
use_bias: 布尔值,是否使用偏置项
kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
bias_initializer:偏置向量初始化方法,为预定义初始化方法名的字符串,或用于初始化偏置向量的初始化器。参考initializers
kernel_regularizer:施加在权重上的正则项,为Regularizer对象
bias_regularizer:施加在偏置向量上的正则项,为Regularizer对象
activity_regularizer:施加在输出上的正则项,为Regularizer对象
kernel_constraints:施加在权重上的约束项,为Constraints对象
bias_constraints:施加在偏置上的约束项,为Constraints对象
输入
形如(batch_size, ..., input_dim)的nD张量,最常见的情况为(batch_size, input_dim)的2D张量。
输出
形如(batch_size, ..., units)的nD张量,最常见的情况为(batch_size, units)的2D张量。
示例
|
|
# as first layer in a sequential model: model = Sequential() model.add(Dense(32, input_shape=(16,))) # model.add(Dense(32, input_dim=16)) # now the model will take as input arrays of shape (*, 16) # and output arrays of shape (*, 32) # after the first layer, you don't need to specify the size of the input anymore model.add(Dense(32)) |
1.5.5.2 Flatten层
Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
keras.layers.core.Flatten()
示例
|
|
model = Sequential() model.add(Convolution2D(64, 3, 3, border_mode='same', input_shape=(3, 32, 32))) # now: model.output_shape == (None, 64, 32, 32) model.add(Flatten()) # now: model.output_shape == (None, 65536) |
1.5.5.3 dropout层
为输入数据施加Dropout。Dropout将在训练过程中每次更新参数时随机断开一定百分比(p)的输入神经元连接,Dropout层用于防止过拟合。
keras.layers.core.Dropout(p)
1.5.5.4 卷积层(Convolutional)
1.5.5.4.1 Conv1D层
keras.layers.convolutional.Conv1D(filters, kernel_size, strides=1, padding='valid', dilation_rate=1, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
一维卷积层(即时域卷积),用以在一维输入信号上进行邻域滤波。当使用该层作为首层时,需要提供关键字参数input_shape。例如(10,128)代表一个长为10的序列,序列中每个信号为128向量。而(None, 128)代表变长的128维向量序列。
该层生成将输入信号与卷积核按照单一的空域(或时域)方向进行卷积。如果use_bias=True,则还会加上一个偏置项,若activation不为None,则输出为经过激活函数的输出。
参数
filters:卷积核的数目(即输出的维度)
kernel_size:整数或由单个整数构成的list/tuple,卷积核的空域或时域窗长度
strides:整数或由单个整数构成的list/tuple,为卷积的步长。任何不为1的strides均与任何不为1的dilation_rate均不兼容
padding:补0策略,为“valid”, “same” 或“causal”,“causal”将产生因果(膨胀的)卷积,即output[t]不依赖于input[t+1:]。当对不能违反时间顺序的时序信号建模时有用。参考WaveNet: A Generative Model for Raw Audio, section 2.1.。“valid”代表只进行有效的卷积,即对边界数据不处理。“same”代表保留边界处的卷积结果,通常会导致输出shape与输入shape相同。
activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
dilation_rate:整数或由单个整数构成的list/tuple,指定dilated convolution中的膨胀比例。任何不为1的dilation_rate均与任何不为1的strides均不兼容。
use_bias:布尔值,是否使用偏置项
kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
bias_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
kernel_regularizer:施加在权重上的正则项,为Regularizer对象
bias_regularizer:施加在偏置向量上的正则项,为Regularizer对象
activity_regularizer:施加在输出上的正则项,为Regularizer对象
kernel_constraints:施加在权重上的约束项,为Constraints对象
bias_constraints:施加在偏置上的约束项,为Constraints对象
输入shape
形如(samples,steps,input_dim)的3D张量。
输出shape
形如(samples,new_steps,nb_filter)的3D张量,因为有向量填充的原因,steps的值会改变。
1.5.5.4.2 Conv2D层
keras.layers.convolutional.Conv2D(filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
二维卷积层,即对图像的空域卷积。该层对二维输入进行滑动窗卷积,当使用该层作为第一层时,应提供input_shape参数。例如input_shape = (128,128,3)代表128*128的彩色RGB图像(data_format='channels_last')
1.5.5.4.3 Conv3D层
keras.layers.convolutional.Conv3D(filters, kernel_size, strides=(1, 1, 1), padding='valid', data_format=None, dilation_rate=(1, 1, 1), activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
三维卷积对三维的输入进行滑动窗卷积,当使用该层作为第一层时,应提供input_shape参数。例如input_shape = (3,10,128,128)代表对10帧128*128的彩色RGB图像进行卷积。数据的通道位置仍然有data_format参数指定。
1.5.5.5池化层
1.5.5.5.1 MaxPooling1D层
keras.layers.pooling.MaxPooling1D(pool_size=2, strides=None, padding='valid')
对时域1D信号进行最大值池化
参数
pool_size:整数,池化窗口大小
strides:整数或None,下采样因子,例如设2将会使得输出shape为输入的一半,若为None则默认值为pool_size。
padding:‘valid’或者‘same’
输入shape
形如(samples,steps,features)的3D张量
输出shape
形如(samples,downsampled_steps,features)的3D张量
1.5.5.5.2 MaxPooling2D层
keras.layers.pooling.MaxPooling2D(pool_size=(2, 2), strides=None, padding='valid', data_format=None)
为空域信号施加最大值池化
1.5.5.5.3 AveragePooling1D层
keras.layers.pooling.AveragePooling1D(pool_size=2, strides=None, padding='valid')
对时域1D信号进行平均值池化
1.5.5.5.4 AveragePooling2D层
keras.layers.pooling.AveragePooling2D(pool_size=(2, 2), strides=None, padding='valid', data_format=None)
为空域信号施加平均值池化
1.5.5.6 循环层(Recurrent)
循环层包含三种模型:LSTM、GRU和SimpleRNN。
所有的循环层(LSTM,GRU,SimpleRNN)都继承本层,因此下面的参数可以在任何循环层中使用。
1.5.5.6.1抽象层,不能直接使用
keras.layers.recurrent.Recurrent(return_sequences=False, go_backwards=False, stateful=False, unroll=False, implementation=0)
weights:numpy array的list,用以初始化权重。该list形如[(input_dim, output_dim),(output_dim, output_dim),(output_dim,)]
return_sequences:布尔值,默认False,控制返回类型。若为True则返回整个序列,否则仅返回输出序列的最后一个输出
go_backwards:布尔值,默认为False,若为True,则逆向处理输入序列并返回逆序后的序列
stateful:布尔值,默认为False,若为True,则一个batch中下标为i的样本的最终状态将会用作下一个batch同样下标的样本的初始状态。
unroll:布尔值,默认为False,若为True,则循环层将被展开,否则就使用符号化的循环。当使用TensorFlow为后端时,循环网络本来就是展开的,因此该层不做任何事情。层展开会占用更多的内存,但会加速RNN的运算。层展开只适用于短序列。
implementation:0,1或2, 若为0,则RNN将以更少但是更大的矩阵乘法实现,因此在CPU上运行更快,但消耗更多的内存。如果设为1,则RNN将以更多但更小的矩阵乘法实现,因此在CPU上运行更慢,在GPU上运行更快,并且消耗更少的内存。如果设为2(仅LSTM和GRU可以设为2),则RNN将把输入门、遗忘门和输出门合并为单个矩阵,以获得更加在GPU上更加高效的实现。注意,RNN dropout必须在所有门上共享,并导致正则效果性能微弱降低。
input_dim:输入维度,当使用该层为模型首层时,应指定该值(或等价的指定input_shape)
input_length:当输入序列的长度固定时,该参数为输入序列的长度。当需要在该层后连接Flatten层,然后又要连接Dense层时,需要指定该参数,否则全连接的输出无法计算出来。注意,如果循环层不是网络的第一层,你需要在网络的第一层中指定序列的长度(通过input_shape指定)。
1.5.5.6.2全连接RNN网络
keras.layers.SimpleRNN(units, activation='tanh', use_bias=True, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0, return_sequences=False, return_state=False, go_backwards=False, stateful=False, unroll=False)
全连接RNN网络,RNN的输出会被回馈到输入
参数说明
• units:输出维度
• activation:激活函数,为预定义的激活函数名(参考激活函数)
• use_bias: 布尔值,是否使用偏置项
• kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
• recurrent_initializer:循环核的初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
• bias_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
• kernel_regularizer:施加在权重上的正则项,为Regularizer对象
• bias_regularizer:施加在偏置向量上的正则项,为Regularizer对象
• recurrent_regularizer:施加在循环核上的正则项,为Regularizer对象
• activity_regularizer:施加在输出上的正则项,为Regularizer对象
• kernel_constraints:施加在权重上的约束项,为Constraints对象
• recurrent_constraints:施加在循环核上的约束项,为Constraints对象
• bias_constraints:施加在偏置上的约束项,为Constraints对象
• dropout:0~1之间的浮点数,控制输入线性变换的神经元断开比例
• recurrent_dropout:0~1之间的浮点数,控制循环状态的线性变换的神经元断开比例
• 其他参数参考Recurrent的说明
输入shape
形如(samples,timesteps,input_dim)的3D张量
输出shape
如果return_sequences=True:返回形如(samples,timesteps,output_dim)的3D张量
否则,返回形如(samples,output_dim)的2D张量
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# as the first layer in a Sequential model model = Sequential() model.add(LSTM(32, input_shape=(10, 64))) # now model.output_shape == (None, 32) # note: `None` is the batch dimension. # 以下与上面相同: model = Sequential() model.add(LSTM(32, input_dim=64, input_length=10)) # for subsequent layers, no need to specify the input size: model.add(LSTM(16)) # to stack recurrent layers, you must use return_sequences=True # on any recurrent layer that feeds into another recurrent layer. # note that you only need to specify the input size on the first layer. model = Sequential() model.add(LSTM(64, input_dim=64, input_length=10, return_sequences=True)) model.add(LSTM(32, return_sequences=True)) model.add(LSTM(10)) |
1.5.5.6.3 LSTM层
keras.layers.recurrent.LSTM(units, activation='tanh', recurrent_activation='hard_sigmoid', use_bias=True, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', unit_forget_bias=True, kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0)
Keras长短期记忆模型
forget_bias_init:遗忘门偏置的初始化函数,建议初始化为全1元素。
inner_activation:内部单元激活函数
1.5.5.6.4 GRU
keras.layers.recurrent.GRU(units, activation='tanh', recurrent_activation='hard_sigmoid', use_bias=True, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0)
门限循环单元
1.5.5.6.5Embedding层
keras.layers.embeddings.Embedding(input_dim, output_dim, init='uniform', input_length=None, W_regularizer=None, activity_regularizer=None, W_constraint=None, mask_zero=False, weights=None, dropout=0.0)
只能作为模型第一层
mask_zero:布尔值,确定是否将输入中的‘0’看作是应该被忽略的‘填充’(padding)值,该参数在使用递归层处理变长输入时有用。设置为True的话,模型中后续的层必须都支持masking,否则会抛出异常
1.5.6 model层
model层是最主要的模块,model层可以将上面定义了各种基本组件组合起来。
model的方法:
model.summary() : 打印出模型概况
model.get_config() :返回包含模型配置信息的Python字典
model.get_weights():返回模型权重张量的列表,类型为numpy array
model.set_weights():从numpy array里将权重载入给模型
model.to_json:返回代表模型的JSON字符串,仅包含网络结构,不包含权值。可以从JSON字符串中重构原模型:
|
|
from models import model_from_json json_string = model.to_json() model = model_from_json(json_string) model.to_yaml:与model.to_json类似,同样可以从产生的YAML字符串中重构模型 from models import model_from_yaml yaml_string = model.to_yaml() model = model_from_yaml(yaml_string) |
model.save_weights(filepath):将模型权重保存到指定路径,文件类型是HDF5(后缀是.h5)。
model.load_weights(filepath, by_name=False):从HDF5文件中加载权重到当前模型中, 默认情况下模型的结构将保持不变。如果想将权重载入不同的模型(有些层相同)中,则设置by_name=True,只有名字匹配的层才会载入权重。
keras有两种model,分别是Sequential模型和泛型模型。
1.5.6.1 Sequential模型
Sequential是多个网络层的线性堆叠
可以通过向Sequential模型传递一个layer的list来构造该模型:
|
|
from keras.models import Sequential from keras.layers import Dense, Activation model = Sequential([Dense(32, input_dim=784), Activation('relu'), Dense(10), Activation('softmax'),]) |
也可以通过.add()方法一个个的将layer加入模型中:
|
|
model = Sequential() model.add(Dense(32, input_dim=784)) model.add(Activation('relu')) |
还可以通过merge将两个Sequential模型通过某种方式合并
Merge层提供了一系列用于融合两个层或两个张量的层对象和方法。以大写首字母开头的是Layer类,以小写字母开头的是张量的函数。小写字母开头的张量函数在内部实际上是调用了大写字母开头的层。
keras.engine.topology.Merge(layers=None, mode='sum', concat_axis=-1, dot_axes=-1, output_shape=None, node_indices=None, tensor_indices=None, name=None)
layers:该参数为Keras张量的列表,或Keras层对象的列表。该列表的元素数目必须大于1。
mode:合并模式,如果为字符串,则为下列值之一{“sum”,“mul”,“concat”,“ave”,“cos”,“dot”}
其中sum和mul是对待合并层输出做一个简单的求和、乘积运算,因此要求待合并层输出shape要一致。concat是将待合并层输出沿着最后一个维度进行拼接,因此要求待合并层输出只有最后一个维度不同。
Merge是一个层对象,在多个sequential组成的网络模型中,如果
x:输入数据。如果模型只有一个输入,那么x的类型是numpy array,如果模型有多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpy array
y:标签,numpy array
否则运行时很可能会提示意思就是你输入的维度与实际不符
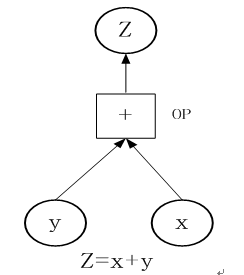
Add
keras.layers.Add()
添加输入列表的图层。
该层接收一个相同shape列表张量,并返回它们的和,shape不变。
|
|
import keras input1 = keras.layers.Input(shape=(16,)) x1 = keras.layers.Dense(8, activation='relu')(input1) input2 = keras.layers.Input(shape=(32,)) x2 = keras.layers.Dense(8, activation='relu')(input2) added = keras.layers.Add()([x1, x2]) # equivalent to added = keras.layers.add([x1, x2]) out = keras.layers.Dense(4)(added) model = keras.models.Model(inputs=[input1, input2], outputs=out) |
Concatenate
keras.layers.Concatenate(axis=-1)
该层接收一个列表的同shape张量,并返回它们的按照给定轴相接构成的向量。
1.5.6.2 函数式(Functional)模型
在Keras 2里我们将这个词改译为“函数式”,对函数式编程有所了解的同学应能够快速get到该类模型想要表达的含义。函数式模型称作Functional,但它的类名是Model,因此我们有时候也用Model来代表函数式模型。
Keras函数式模型接口是用户定义多输出模型、非循环有向模型或具有共享层的模型等复杂模型的途径。一句话,只要你的模型不是类似VGG一样一条路走到黑的模型,或者你的模型需要多于一个的输出,那么你总应该选择函数式模型。函数式模型是最广泛的一类模型,序贯模型(Sequential)只是它的一种特殊情况。
这部分的文档假设你已经对Sequential模型已经比较熟悉
让我们从简单一点的模型开始
第一个模型:全连接网络
Sequential当然是实现全连接网络的最好方式,但我们从简单的全连接网络开始,有助于我们学习这部分的内容。在开始前,有几个概念需要澄清:
层对象接受张量为参数,返回一个张量。
输入是张量,输出也是张量的一个框架就是一个模型,通过Model定义。
这样的模型可以被像Keras的Sequential一样被训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from keras.layers import Input, Dense from keras.models import Model # This returns a tensor inputs = Input(shape=(784,)) # a layer instance is callable on a tensor, and returns a tensor x = Dense(64, activation='relu')(inputs) x = Dense(64, activation='relu')(x) predictions = Dense(10, activation='softmax')(x) # This creates a model that includes # the Input layer and three Dense layers model = Model(inputs=inputs, outputs=predictions) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(data, labels) # starts training |
所有的模型都是可调用的,就像层一样
利用函数式模型的接口,我们可以很容易的重用已经训练好的模型:你可以把模型当作一个层一样,通过提供一个tensor来调用它。注意当你调用一个模型时,你不仅仅重用了它的结构,也重用了它的权重。
|
|
x = Input(shape=(784,)) # This works, and returns the 10-way softmax we defined above. y = model(x) |
使用函数式模型的一个典型场景是搭建多输入、多输出的模型,如下图:
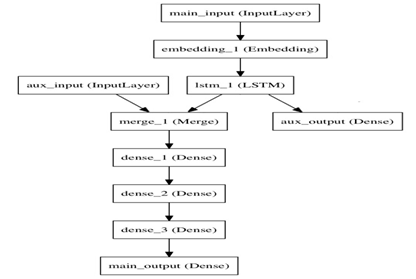
|
|
auxiliary_input = Input(shape=(5,), name='aux_input') x = keras.layers.concatenate([lstm_out, auxiliary_input]) # We stack a deep densely-connected network on top x = Dense(64, activation='relu')(x) x = Dense(64, activation='relu')(x) x = Dense(64, activation='relu')(x) # And finally we add the main logistic regression layer main_output = Dense(1, activation='sigmoid', name='main_output')(x) |
第2章 keras的使用流程
2.1 流程说明
第1步:构造数据:定义输入数据
第2步:构造模型:确定各个变量之间的计算关系
第3步:编译模型:编译已确定其内部细节
第4步:训练模型:导入数据,训练模型
第5步:测试模型
第6步:保存模型
把这些步骤进一步图形化为:

2.2 实例-详细说明使用流程
第1步:构造数据
我们需要根据模型fit(训练)时需要的数据格式来构造数据的shape,这里我们用numpy构造两个矩阵:一个是数据矩阵,一个是标签矩阵。
|
|
import numpy as np from keras.utils import np_utils from keras.models import Sequential from keras.layers import Dense, Activation from keras.optimizers import Adam x_train = np.random.random((1000, 784)) y_train = np.random.randint(2, size=(1000, 1)) x_test = np.random.random((200, 784)) y_test = np.random.randint(2, size=(200, 1)) |
通过numpy的random生成随机矩阵,数据矩阵是1000行784列的矩阵,标签矩阵是1000行1列的句子,所以数据矩阵的一行就是一个样本,这个样本是784维的。
第2步 构造模型
我们来构造一个神经网络模型,keras构造深度学习模型可以采用序列模型(基于Sequential类)或函数模型(又称为通用模型)(基于Model类)。两种间差异是拓扑结构不一样。这里我们采用序列模型。
|
|
model = Sequential() model.add(Dense(32, activation='relu', input_dim=784)) model.add(Dense(1, activation='sigmoid')) |
在这一步中可以add多个层,也可以merge合并两个模型。
第3步:编译模型
我们编译上一步构造好的模型,并指定一些模型的参数,optimizer(优化器),loss(目标函数或损失函数),metrics(评估模型的指标)等。编译模型时损失函数和优化器这两项是必须的。
|
|
model.compile(optimizer='Adam',loss='binary_crossentropy',metrics=['accuracy']) |
第4步:训练模型
传入要训练的数据和标签,并指定训练的一些参数,然后进行模型训练。
|
|
model.fit(x_train, y_train, epochs=10,verbose=2, batch_size=32,) |
Epoch 1/10
- 1s - loss: 0.7063 - acc: 0.5010
Epoch 2/10
- 0s - loss: 0.6955 - acc: 0.5110
.................................
Epoch 10/10
- 0s - loss: 0.5973 - acc: 0.6980
epochs:整数,训练的轮数。
verbose:训练时显示实时信息,0表示不显示数据,1表示显示进度条,2表示用只显示一个数据。
batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
第5步:测试模型
用测试数据测试已经训练好的模型,并可以获得测试结果,从而对模型进行评估
|
|
score = model.evaluate(x_test, y_test, batch_size=32) |
200/200 [==============================] - 0s 146us/step
本函数返回一个测试误差的标量值(如果模型没有其他评价指标),或一个标量的list(如果模型还有其他的评价指标)
第6步:保存模型
|
|
#将模型保存为json json_string = model.to_json() #从保存的json中加载模型 from keras.models import model_from_json model_re = model_from_json(json_string) |
【项目延伸】
上面是采用全连接的神经网络,包括输入层、一个隐含层及一个输出层。如果我们卷积神经网络是否可以?例如:一个卷积层+池化层+展平+全连接+输出层。
第3章 keras实现单层神经网络
3.1利用keras实现单层神经
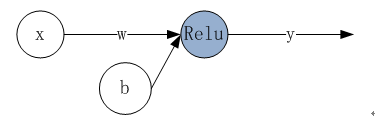
本章利用Keras架构实现一个传统机器学习算法---线性回归
根据输入数据及目标数据,模拟一个线性函数y=kx+b
这里使用一个神经元,神经元中使用Relu作为激活函数。如下图:
第1步:构造数据
|
|
import numpy as np from keras.models import Sequential from keras.layers import Dense import matplotlib.pyplot as plt %matplotlib inline #构造数据 X = np.linspace(-2, 2, 200) np.random.shuffle(X) # randomize the data #添加一些噪音数据 Y = 0.5 * X + 2 + np.random.normal(0, 0.05, (200, )) # 显示输入数据 plt.scatter(X, Y) plt.show() |
把200份数据划分为训练数据、测试数据。
|
|
X_train, Y_train = X[:160], Y[:160] # first 160 data points X_test, Y_test = X[160:], Y[160:] # last 40 data points |
第2步 构造模型
|
|
# build a neural network from the 1st layer to the last layer model = Sequential() model.add(Dense(units=1,activation='relu', input_dim=1)) |
第3步 编译模型
|
|
# choose loss function and optimizing method model.compile(loss='mse', optimizer='sgd') |
第4步 训练模型
|
|
model.fit(X_train, Y_train, epochs=100,verbose=0, batch_size=64,) |
第5步 测试模型
|
|
# test print('\nTesting ------------') cost = model.evaluate(X_test, Y_test, batch_size=40) print('test cost:', cost) W, b = model.layers[0].get_weights() print('Weights=', W, '\nbiases=', b) |
Testing ------------
40/40 [==============================] - 0s 996us/step
test cost: 0.00395184289664
Weights= [[ 0.48489931]]
biases= [ 1.95838749]
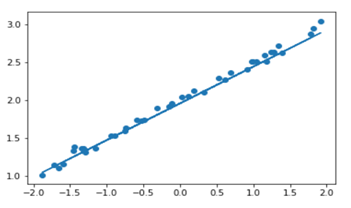
可视化结果:
|
|
# plotting the prediction Y_pred = model.predict(X_test) plt.scatter(X_test, Y_test) plt.plot(X_test, Y_pred) plt.show() |
第4章 keras实现多层神经网络
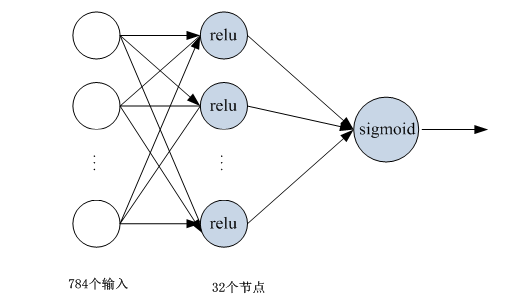
利用keras构造一个多层神经网络,用该神经网络识别手写数字,上次我们采用python来实现,这里我们采用keras来构造多层神经网络。
网络构造图形:
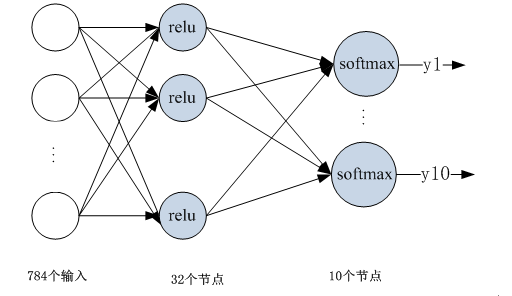
在整个网络设计中,输入数据的维度,优化方法、损失函数需要重点考虑。当然激活函数也很重要,特别是层数较多时。
这里为便于说明keras构建多层神经网络的方法,采用MNIST数据集,MNIST是一个手写数字0-9的数据集,它有60000个训练样本集和10000个测试样本集它是NIST数据库的一个子集。该数据集keras有现成的数据处理API(mnist.load_data())。
数据预处理:
(1)展平矩阵:
原数据为28*28图片,在利用全连接前,需要把矩阵拉平为一维数组,大小为784;
(2)规范训练数据
转换为都是0-255的像素,为提高模型的泛化能力,需要对数据规范化,即除以255,使数据范围都在[0,1]之间;
(3)规范标签数据
把标签数据转换为one-hot格式,向量维度为10,每行除一个1元素外,其它都是0,如把2标签转换为[0,0,1,0,0,0,0,0,0,0]
以下为详细计算步骤:
第1步: 构建数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import numpy as np from keras.datasets import mnist from keras.utils import np_utils from keras.models import Sequential from keras.layers import Dense, Activation from keras.optimizers import Adam # download the mnist to the path '~/.keras/datasets/' (X_train, y_train), (X_test, y_test) = mnist.load_data() #查看数据集维度 print("展平前") print(X_train.shape,y_train.shape) # data pre-processing X_train = X_train.reshape(X_train.shape[0], -1) / 255. # normalize X_test = X_test.reshape(X_test.shape[0], -1) / 255. # normalize y_train = np_utils.to_categorical(y_train, num_classes=10) y_test = np_utils.to_categorical(y_test, num_classes=10) print("展平后") print(X_train.shape,y_train.shape) |
运行结果:
Using TensorFlow backend.
展平前
(60000, 28, 28) (60000,)
展平后
(60000, 784) (60000, 10)
第2步 构建网络
|
|
model = Sequential([ Dense(32, input_dim=784), Activation('relu'), Dense(10), Activation('softmax'), ]) |
第3步 编译模型
|
|
model.compile(optimizer='Adam',loss='categorical_crossentropy',metrics=['accuracy']) |
运行结果:
【备注】
如果我们需要对优化方法进行某些定制化,也很方便:
|
|
Adam1 =Adam(lr=0.001, beta_1=0.5, epsilon=1e-08, decay=0.0) |
第4步 训练模型
|
|
print('Training ------------') model.fit(X_train, y_train, epochs=2,verbose=2, batch_size=32) |
运行结果:
Training ------------
Epoch 1/2
- 7s - loss: 0.1584 - acc: 0.9539
Epoch 2/2
- 6s - loss: 0.1340 - acc: 0.9607
第5步 测试模型
|
|
print('\nTesting ------------') # Evaluate the model with the metrics we defined earlier loss, accuracy = model.evaluate(X_test, y_test) print('test loss: ', loss) print('test accuracy: ', accuracy) |
运行结果:
test loss: 0.132445694927
test accuracy: 0.9614