文章目录
本章数据集下载
第12章 Spark R 朴素贝叶斯模型
前一章我们介绍了PySpark,就是用Python语言操作Spark大数据计算框架上的任务,这样把自然把Python的优点与Spark的优势进行叠加。Spark提供了Python的API,也提供了R语言的API,其组件名称为Spark R。Spark R的运行原理或架构,具体请看图12-1。
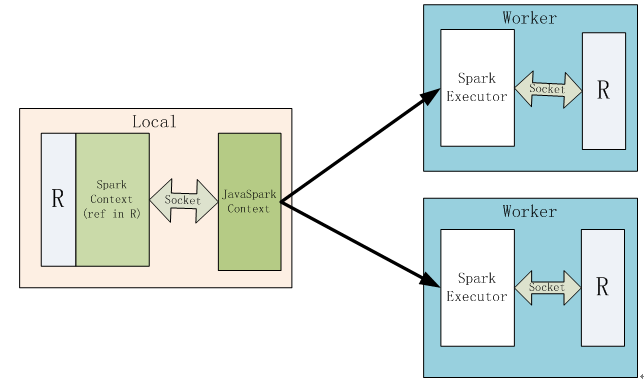
图12-1 Spark R 架构图
Spark R的架构类似于PySpark,Driver端除了一个JVM进程(包含一个SparkContext,在Spark2.X中SparkContext已经被SparkSession所代替)外,还有起一个R的进程,这两个进程通过Socket进行通信,用户可以提交R语言代码,R的进程会执行这些R代码,
当R代码调用Spark相关函数时,R进程会通过Socket触发JVM中的对应任务。
当R进程向JVM进程提交任务的时候,R会把子任务需要的环境进行打包,并发送到JVM的driver端。通过R生成的RDD都会是RRDD类型,当触发RRDD的action时,Spark的执行器会开启一个R进程,执行器和R进程通过Socket进行通信。执行器会把任务和所需的环境发送给R进程,R进程会加载对应的package,执行任务,并返回结果。
本章通过一个实例来说明如何使用Spark R,具体内容如下:
Spark R简介
把数据上传到HDFS,然后导入Hive,最后从Hive读取数据
使用朴素贝叶斯分类器
探索数据
预处理数据
训练模型
评估模型
12.1. Spark R简介
目前SparkR的最新版本为2.0.1,API参考文档(http://spark.apache.org/docs/latest/api/R/index.html)。
12.2获取数据
12.2.1 SparkDataFrame数据结构说明
SparkDataFrame是Spark提供的分布式数据格式(DataFrame)。类似于关系数据库中的表或R语言中的DataFrame。SparkDataFrames可以从各种各样的源构造,例如:结构化数据文件,Hive中的表,外部数据库或现有的本地数据。
12.2.2创建SparkDataFrame
1.从本地文件加载数据,生成SparkDataFrame
SparkR支持通过SparkDataFrame接口对各种数据源进行操作。示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
library("SparkR", lib.loc="/u01/bigdata/spark/R/lib")#加载sparkR ## ## Attaching package: 'SparkR' ## The following objects are masked from 'package:stats': ## ## cov, filter, lag, na.omit, predict, sd, var, window ## The following objects are masked from 'package:base': ## ## as.data.frame, colnames, colnames<-, drop, endsWith, ## intersect, rank, rbind, sample, startsWith, subset, summary, ## transform, union sparkR.session(sparkHome ='/u01/bigdata/spark' )#启动Spark环境 ## Spark package found in SPARK_HOME: /u01/bigdata/spark ## Launching java with spark-submit command /u01/bigdata/spark/bin/spark-submit sparkr-shell /tmp/RtmpA30Gvz/backend_port2ad11c0705d8 ## Java ref type org.apache.spark.sql.SparkSession id 1 # 读取本地csv文件 Sparkdf <-read.df("/u01/bigdata/data/df2.csv",source='csv',header='TRUE',inferSchema ="true") # 查看SparkDataFrame head(Sparkdf) ## Sepal_Length Sepal_Width Petal_Length Petal_Width Species ## 1 5.1 3.5 1.4 0.2 setosa ## 2 4.9 3.0 1.4 0.2 setosa ## 3 4.7 3.2 1.3 0.2 setosa ## 4 4.6 3.1 1.5 0.2 setosa ## 5 5.0 3.6 1.4 0.2 setosa ## 6 5.4 3.9 1.7 0.4 setosa |
2.利用R环境的data frames创建SparkDataFrame
创建SparkDataFrame的最简单的方法是将本地R环境变量中的data frames转换为SparkDataFrame。我们可以使用as.DataFrame或createDataFrame函数来创建SparkDataFrame。作为示例,我们使用R自带的iris数据集来创建SparkDataFrame。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
library("SparkR", lib.loc="/u01/bigdata/spark/R/lib")#加载sparkR ## ## Attaching package: 'SparkR' ## The following objects are masked from 'package:stats': ## ## cov, filter, lag, na.omit, predict, sd, var, window ## The following objects are masked from 'package:base': ## ## as.data.frame, colnames, colnames<-, drop, endsWith, ## intersect, rank, rbind, sample, startsWith, subset, summary, ## transform, union sparkR.session(sparkHome ='/u01/bigdata/spark' )#启动Spark环境 ## Java ref type org.apache.spark.sql.SparkSession id 1 # 创建SparkDataFrame Sparkdf,数据来自iris数据集 Sparkdf <-as.DataFrame(iris) # 查看刚创建好的SparkDataFrame head(Sparkdf) ## Sepal_Length Sepal_Width Petal_Length Petal_Width Species ## 1 5.1 3.5 1.4 0.2 setosa ## 2 4.9 3.0 1.4 0.2 setosa ## 3 4.7 3.2 1.3 0.2 setosa ## 4 4.6 3.1 1.5 0.2 setosa ## 5 5.0 3.6 1.4 0.2 setosa ## 6 5.4 3.9 1.7 0.4 setosa |
3.从HDFS文件系统加载数据,生成SparkDataFrame
示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
library("SparkR", lib.loc="/u01/bigdata/spark/R/lib")#加载sparkR ## ## Attaching package: 'SparkR' ## The following objects are masked from 'package:stats': ## ## cov, filter, lag, na.omit, predict, sd, var, window ## The following objects are masked from 'package:base': ## ## as.data.frame, colnames, colnames<-, drop, endsWith, ## intersect, rank, rbind, sample, startsWith, subset, summary, ## transform, union ## Java ref type org.apache.spark.sql.SparkSession id 1 # 读取HDFS文件 Sparkdf <-read.df("hdfs://192.168.1.112:9000/u01/bigdata/data/df2.csv",source='csv',header='TRUE',inferSchema ="true") # 查看SparkDataFrame head(Sparkdf) ## Sepal_Length Sepal_Width Petal_Length Petal_Width Species ## 1 5.1 3.5 1.4 0.2 setosa ## 2 4.9 3.0 1.4 0.2 setosa ## 3 4.7 3.2 1.3 0.2 setosa ## 4 4.6 3.1 1.5 0.2 setosa ## 5 5.0 3.6 1.4 0.2 setosa ## 6 5.4 3.9 1.7 0.4 setosa |
4.读取Hive数据仓库中的表,生成SparkDataFrame
我们还可以从Hive表创建SparkDataFrame。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
library("SparkR", lib.loc="/u01/bigdata/spark/R/lib")#加载sparkR # 查看数据库 sql('show databases') ## SparkDataFrame[databaseName:string] # 选择hive库 sql('use hive') ## SparkDataFrame[] # 查看hive数据库的表 sql('show tables') ## SparkDataFrame[database:string, tableName:string, isTemporary:boolean] # 查看表df2的信息 sql('desc df2') ## SparkDataFrame[col_name:string, data_type:string, comment:string] # 读取hive表df2,生成SparkDataFrame Sparkdf<-sql('select * from df2') # 查看SparkDataFrame head(Sparkdf) ## height weight ## 1 0.3307575 -1.4197984 ## 2 0.4970992 -1.4364733 ## 3 1.4477968 -0.7579736 ## 4 0.6815300 -1.7573564 ## 5 0.8915567 1.1815332 ## 6 -2.2494993 -1.6438995 |
12.2.3 SparkDataFrame的常用操作
1.选择行,或者列
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
df <-as.DataFrame(iris) str(df) ## 'SparkDataFrame': 5 variables: ## $ Sepal_Length: num 5.1 4.9 4.7 4.6 5 5.4 ## $ Sepal_Width : num 3.5 3 3.2 3.1 3.6 3.9 ## $ Petal_Length: num 1.4 1.4 1.3 1.5 1.4 1.7 ## $ Petal_Width : num 0.2 0.2 0.2 0.2 0.2 0.4 ## $ Species : chr "setosa" "setosa" "setosa" "setosa" "setosa" "setosa" head(df) ## Sepal_Length Sepal_Width Petal_Length Petal_Width Species ## 1 5.1 3.5 1.4 0.2 setosa ## 2 4.9 3.0 1.4 0.2 setosa ## 3 4.7 3.2 1.3 0.2 setosa ## 4 4.6 3.1 1.5 0.2 setosa ## 5 5.0 3.6 1.4 0.2 setosa ## 6 5.4 3.9 1.7 0.4 setosa # 选择Sepal_Length列 head(select(df, df$Sepal_Length)) ## Sepal_Length ## 1 5.1 ## 2 4.9 ## 3 4.7 ## 4 4.6 ## 5 5.0 ## 6 5.4 # 或者 head(select(df, "Sepal_Length")) ## Sepal_Length ## 1 5.1 ## 2 4.9 ## 3 4.7 ## 4 4.6 ## 5 5.0 ## 6 5.4 # 过滤出Sepal_Length小于5的行 head(filter(df, df$Sepal_Length <5)) ## Sepal_Length Sepal_Width Petal_Length Petal_Width Species ## 1 4.9 3.0 1.4 0.2 setosa ## 2 4.7 3.2 1.3 0.2 setosa ## 3 4.6 3.1 1.5 0.2 setosa ## 4 4.6 3.4 1.4 0.3 setosa ## 5 4.4 2.9 1.4 0.2 setosa ## 6 4.9 3.1 1.5 0.1 setosa |
2.数据分组,聚合
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
df <-as.DataFrame(faithful) #数据分组,并统计每组出现的个数 head(summarize(groupBy(df, df$waiting), count =n(df$waiting))) ## waiting count ## 1 70 4 ## 2 67 1 ## 3 69 2 ## 4 88 6 ## 5 49 5 ## 6 64 4 # 对结果进行排序 waiting_counts <-summarize(groupBy(df, df$waiting), count =n(df$waiting)) head(arrange(waiting_counts, desc(waiting_counts$count))) ## waiting count ## 1 78 15 ## 2 83 14 ## 3 81 13 ## 4 77 12 ## 5 82 12 ## 6 79 10 |
3.对SparkDataFrame的列进行运算操作
|
1 2 3 4 5 6 7 8 9 |
df$waiting_secs <-df$waiting *60 head(df) ## eruptions waiting waiting_secs ## 1 3.600 79 4740 ## 2 1.800 54 3240 ## 3 3.333 74 4440 ## 4 2.283 62 3720 ## 5 4.533 85 5100 ## 6 2.883 55 3300 |
4.apply系列函数的应用
• dapply函数类似于R语言的apply函数,看一个示例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
df <-as.DataFrame(iris) df1 <-dapply(df, function(x) { x[x[,1]>6,]},schema =schema(df)) head(collect(df1)) ## Sepal_Length Sepal_Width Petal_Length Petal_Width Species ## 1 7.0 3.2 4.7 1.4 versicolor ## 2 6.4 3.2 4.5 1.5 versicolor ## 3 6.9 3.1 4.9 1.5 versicolor ## 4 6.5 2.8 4.6 1.5 versicolor ## 5 6.3 3.3 4.7 1.6 versicolor ## 6 6.6 2.9 4.6 1.3 versicolor str(df1) ## 'SparkDataFrame': 5 variables: ## $ Sepal_Length: num 7 6.4 6.9 6.5 6.3 6.6 ## $ Sepal_Width : num 3.2 3.2 3.1 2.8 3.3 2.9 ## $ Petal_Length: num 4.7 4.5 4.9 4.6 4.7 4.6 ## $ Petal_Width : num 1.4 1.5 1.5 1.5 1.6 1.3 ## $ Species : chr "versicolor" "versicolor" "versicolor" "versicolor" "versicolor" "versicolor" dim(df1) ## [1] 61 5 |
12.3朴素贝叶斯分类器
该案例数据来自泰坦尼克号人员存活情况,响应变量为Survived,包含2个分类(yes,no),特征变量有Sex 、 Age 、Class(船舱等级),说明如下:
Class :0 = crew, 1 = first, 2 = second, 3 = third Age :1 = adult, 0 = child Sex :1 = male, 0 = female Survived :1 = yes, 0 = no
12.3.1数据探查
让我们来观察一下数据,
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
library("SparkR", lib.loc="/u01/bigdata/spark/R/lib")#加载sparkR ## ## Attaching package: 'SparkR' ## The following objects are masked from 'package:stats': ## ## cov, filter, lag, na.omit, predict, sd, var, window ## The following objects are masked from 'package:base': ## ## as.data.frame, colnames, colnames<-, drop, endsWith, ## intersect, rank, rbind, sample, startsWith, subset, summary, ## transform, union ## Java ref type org.apache.spark.sql.SparkSession id 1 ## SparkDataFrame[] #从hive仓库加载数据 titanic <-sql('select * from titanic') # 查看SparkDataFrame head(titanic) ## class age sex survived ## 1 1 1 1 1 ## 2 1 1 1 1 ## 3 1 1 1 1 ## 4 1 1 1 1 ## 5 1 1 1 1 ## 6 1 1 1 1 dim(titanic) ## [1] 2201 4 # 查看SparkDataFrame dim(titanic)#查看数据的记录数以及维度数量 ## [1] 2201 4 |
12.3.2对原始数据集进行转换
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
titanic_df=as.data.frame(titanic) titanic <-as.data.frame(table(titanic_df)) colnames(titanic)<-paste0(toupper(substring(colnames(titanic),1,1)),substring(colnames(titanic),2)) titanic_temp<-titanic[titanic$Freq >0, -5] head(titanic_temp) ## Class Age Sex Survived ## 4 3 0 0 0 ## 5 0 1 0 0 ## 6 1 1 0 0 ## 7 2 1 0 0 ## 8 3 1 0 0 ## 12 3 0 1 0 |
12.3.3查看不同船舱的生还率差异
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
library(ggplot2) library(dplyr) ## ## Attaching package: 'dplyr' ## The following objects are masked from 'package:SparkR': ## ## arrange, between, collect, contains, count, cume_dist, ## dense_rank, desc, distinct, explain, filter, first, group_by, ## intersect, lag, last, lead, mutate, n, n_distinct, ntile, ## percent_rank, rename, row_number, sample_frac, select, sql, ## summarize, union ## The following objects are masked from 'package:stats': ## ## filter, lag ## The following objects are masked from 'package:base': ## ## intersect, setdiff, setequal, union tempdata<-aggregate(Freq~Class+Survived,data = titanic,FUN = sum) ggplot(data = tempdata,mapping =aes(x = Class,y=Freq,fill=Survived))+geom_bar(position ='dodge',stat ='identity')+ylab("number")+xlim(c("1","2","3","0"))+theme(text=element_text(family ="Italic",size=18)) |
然后,对比一下不同性别之间的生还率:
|
1 2 |
tempdata<-aggregate(Freq~Sex+Survived,data = titanic,FUN = sum) ggplot(data = tempdata,mapping =aes(x = Sex,y=Freq,fill=Survived))+geom_bar(position ='dodge',stat ='identity') |
最后再看看不同年龄段的生还情况:
|
1 2 |
tempdata<-aggregate(Freq~Age+Survived,data = titanic,FUN = sum) ggplot(data = tempdata,mapping =aes(x = Age,y=Freq,fill=Survived))+geom_bar(position ='dodge',stat ='identity') |
12.3.4转换成SparkDataFrame格式的数据
|
1 2 |
titanicDF <-createDataFrame(titanic[titanic$Freq >0, -5]) nbDF |
12.3.5模型概要
|
1 2 3 4 5 6 7 8 9 |
summary(nbModel) ## $apriori ## 1 0 ## [1,] 0.5769231 0.4230769 ## ## $tables ## Class_3 Class_2 Class_1 Sex_0 Age_1 ## 1 0.3125 0.3125 0.3125 0.5 0.5625 ## 0 0.4166667 0.25 0.25 0.5 0.75 |
12.3.6预测
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
nbPredictions <-predict(nbModel, nbTestDF) showDF(nbPredictions) ## +-----+---+---+--------+--------------------+--------------------+----------+ ## |Class|Age|Sex|Survived| rawPrediction| probability|prediction| ## +-----+---+---+--------+--------------------+--------------------+----------+ ## | 3| 0| 0| 0|[-3.9824097993521...|[0.60062402496099...| 1| ## | 0| 1| 0| 0|[-2.9426380107070...|[0.50318824507901...| 1| ## | 1| 1| 0| 0|[-3.7310953710712...|[0.58003280993672...| 1| ## | 2| 1| 0| 0|[-3.7310953710712...|[0.58003280993672...| 1| ## | 3| 1| 0| 0|[-3.7310953710712...|[0.39192399049881...| 0| ## | 3| 0| 1| 0|[-3.9824097993521...|[0.60062402496099...| 1| ## | 0| 1| 1| 0|[-2.9426380107070...|[0.50318824507901...| 1| ## | 1| 1| 1| 0|[-3.7310953710712...|[0.58003280993672...| 1| ## | 2| 1| 1| 0|[-3.7310953710712...|[0.58003280993672...| 1| ## | 3| 1| 1| 0|[-3.7310953710712...|[0.39192399049881...| 0| ## | 1| 0| 0| 1|[-3.9824097993521...|[0.76318223866790...| 1| ## | 2| 0| 0| 1|[-3.9824097993521...|[0.76318223866790...| 1| ## | 3| 0| 0| 1|[-3.9824097993521...|[0.60062402496099...| 1| ## | 0| 1| 0| 1|[-2.9426380107070...|[0.50318824507901...| 1| ## | 1| 1| 0| 1|[-3.7310953710712...|[0.58003280993672...| 1| ## | 2| 1| 0| 1|[-3.7310953710712...|[0.58003280993672...| 1| ## | 3| 1| 0| 1|[-3.7310953710712...|[0.39192399049881...| 0| ## | 1| 0| 1| 1|[-3.9824097993521...|[0.76318223866790...| 1| ## | 2| 0| 1| 1|[-3.9824097993521...|[0.76318223866790...| 1| ## | 3| 0| 1| 1|[-3.9824097993521...|[0.60062402496099...| 1| ## +-----+---+---+--------+--------------------+--------------------+----------+ ## only showing top 20 rows |
12.3.7评估模型
|
1 2 3 4 5 6 7 8 9 |
nbPredictions<-as.data.frame(nbPredictions) # 计算混淆矩阵 ct<-table(titanic_temp$Survived,nbPredictions$prediction) ct ## ## 0 1 ## 0 2 8 ## 1 2 12 |
计算准确率
|
1 2 |
(ct[1,1]+ct[2,2])/sum(ct) ## [1] 0.5833333 |
计算召回率
|
1 2 |
ct[2,2]/(ct[2,2]+ct[2,1]) ## [1] 0.8571429 |
计算精准率
|
1 2 |
ct[2,2]/(ct[2,2]+ct[1,2]) ## [1] 0.6 |
12.4 小结
本章主要介绍了如何使用Spark R组件的问题,Spark R 给R开发人员提供很多API,利用这些API,开发人员就可以通过R语言操作Spark,把用R编写的代码放在Spark这个大数据技术平台运行,这样可以使R不但可以操作HDFS或Hive中数据,也自然使用Spark分布式基于内存的架构。