本章数据集下载
第10章 构建Spark ML聚类模型
前面我们介绍了推荐、分类、回归等模型,这些模型属于监督学习,在训练模型时,都提供目标值或标签数据,根据目标值训练模型,然后根据模型对测试数据或新数据进行推荐、分类或预测。
但实际数据有很多是没有标签数据,或者预先标签很难,但我们又希望或需要从这些数据中提炼一些规则或特征等,如识别异常数据、对客户进行分类等,解决这类问题就属于无监督学习。
聚类是一种无监督学习,它与分类的不同,聚类所要求划分的类是未知的。
聚类算法的思想就是物以类聚的思想,相同性质的点在空间中表现的较为紧密和接近,主要用于数据探索与异常检测。
聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,它能够从样本数据出发,自动进行分类。聚类分析也有很多方法,使用不同方法往往会得到不同的结论。从实际应用的角度看,聚类分析是数据挖掘的主要任务之一。而且聚类能够作为一个独立的工具获得数据的分布状况,观察每一簇数据的特征,集中对特定的聚簇集合作进一步地分析。聚类分析还可以作为其他算法(如分类和推荐等算法)的预处理步骤。
10.1 K-means模型简介
作为经典的聚类算法,一般的机器学习框架里都有K-means,Spark自然也不例外。
不过spark中的K-means,除有一般K-means的特点外,还进行了如下的优化:
10.2 数据加载
这里我们以某批发经销商的客户对不同产品的年度消费支出(数据来源http://archive.ics.uci.edu/ml/datasets/Wholesale+customers)
读取HDFS中的数据。
|
1 2 3 4 5 6 7 8 9 |
//导入需要的类 import org.apache.spark.ml.clustering.KMeans import org.apache.spark.ml.feature.VectorAssembler import org.apache.spark.ml.feature.OneHotEncoder import org.apache.spark.ml.feature.StandardScaler import org.apache.spark.ml.{Pipeline, PipelineModel} //通过spark.read,读取HDFS中的数据 val rawdata = spark.read.format("csv").option("header", true).load("hdfs://master:9000/home/hadoop/data/customers_sale.csv") |
10.3 探索特征的相关性
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
//数据的样本信息 rawdata.show(3) +-------+------+-----+----+-------+------+----------------+----------+ |Channel|Region|Fresh|Milk|Grocery|Frozen|Detergents_Paper|Delicassen| +-------+------+-----+----+-------+------+----------------+----------+ | 2| 3|12669|9656| 7561| 214| 2674| 1338| | 2| 3| 7057|9810| 9568| 1762| 3293| 1776| | 2| 3| 6353|8808| 7684| 2405| 3516| 7844| +------+-----+----+----+------+-----+--------------+---------+ //查看数据结构 rawdata.printSchema() root |-- Channel: string (nullable = true) |-- Region: string (nullable = true) |-- Fresh: string (nullable = true) |-- Milk: string (nullable = true) |-- Grocery: string (nullable = true) |-- Frozen: string (nullable = true) |-- Detergents_Paper: string (nullable = true) |-- Delicassen: string (nullable = true) |
从以上分析,我们可以看出,rawdata数据集总记录数为440条,最大与最小值相差不大,已统计的特征来看,没有缺失值,数据类型为字符型,这点需要在预处理中转换为Double型。
利用pyspark我们可以画出这些特征间的相关性,这里使用pearson's r,相关系统在[-1,1]之间,如果r=1,表示特征完全正相关;r=0,表示不存在关系;r=-1,表示特征完全负相关。
实现代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt df=pd.read_csv('/home/hadoop/data/customer_sale/customers_sale.csv',header=0) cols=['Channel','Region','Fresh','Milk','Grocery','Frozen','Detergents_Paper','Delicassen'] cm=np.corrcoef(df[cols].values.T) sns.set(font_scale=1.2) hm=sns.heatmap(cm,cbar=True,annot=True,square=True,fmt='.2f',annot_kws={'size':15},yticklabels=cols,xticklabels=cols) plt.show() plt.savefig('sale_corr.png') |
10.4 数据预处理
通过数据探索,发现数据需要又字符转换为数值型,并缓存。
|
1 2 3 4 5 6 7 8 9 |
val data1= rawdata.select( rawdata("Channel").cast("Double"), rawdata("Region").cast("Double"), rawdata("Fresh").cast("Double"), rawdata("Milk").cast("Double"), rawdata("Grocery").cast("Double"), rawdata("Frozen").cast("Double"), rawdata("Detergents_Paper").cast("Double"), rawdata("Delicassen").cast("Double")).cache() |
查看数据的统计信息:
|
1 2 3 4 5 6 7 8 9 10 |
data1.select("Fresh","Milk","Grocery","Frozen","Detergents_Paper","Delicassen").describe().show() +-------+------------------+------------------+-----------------+-----------------+------------------+------------------+ |summary| Fresh| Milk| Grocery| Frozen| Detergents_Paper| Delicassen| +-------+------------------+------------------+-----------------+-----------------+------------------+------------------+ | count| 440| 440| 440| 440| 440| 440| | mean|12000.297727272728| 5796.265909090909|7951.277272727273|3071.931818181818|2881.4931818181817|1524.8704545454545| | stddev|12647.328865076885|7380.3771745708445|9503.162828994346|4854.673332592367| 4767.854447904201|2820.1059373693965| | min| 3.0| 55.0| 3.0| 25.0| 3.0| 3.0| | max| 112151.0| 73498.0| 92780.0| 60869.0| 40827.0| 47943.0| +-------+------------------+------------------+-----------------+-----------------+------------------+------------------+ |
Channel、Region为类别型,其余6个字段为连续型,为此,在训练模型前,需要对类别特征先转换为二元向量,然后,对各特征进行规范化。最后得到一个新的特征向量。
对类别特征转换为二元编码:
|
1 2 3 4 5 6 7 8 9 10 11 |
//把channel特征转换为二元编码 val datahot1=new OneHotEncoder() .setInputCol("Channel") .setOutputCol("Channelvector") .setDropLast(false) //把Region特征转换为二元编码 val datahot2=new OneHotEncoder() .setInputCol("Region") .setOutputCol("Regionvector") .setDropLast(false) |
把新生成的两个特征及原来的6个特征组成一个特征向量
|
1 |
val featuresArray =Array("Channelvector","Regionvector","Fresh","Milk","Grocery","Frozen","Detergents_Paper","Delicassen") |
把源数据组合成特征向量features
|
1 2 3 4 5 6 7 8 9 |
val vecDF = new VectorAssembler() .setInputCols(featuresArray) .setOutputCol("features") 对特征进行规范化 val scaledDF = new StandardScaler() .setInputCol("features") .setOutputCol("scaledFeatures") .setWithStd(true) .setWithMean(false) |
10.5 组装
这里我们只使用了setK、setSeed两个参数,其余的使用缺省值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
val kmeans = new KMeans().setFeaturesCol("scaledFeatures").setK(4).setSeed(123) //把转换二元向量、特征规范化转换等组装到流水线上,因pipeline中无聚类的评估函数,故,这里流水线中不纳入kmeans。具体实现如下: val pipeline1 = new Pipeline().setStages(Array(datahot1,datahot2,vecDF,scaledDF)) val data2=pipeline1.fit(data1).transform(data1) //训练模型 val model=kmeans.fit(data2) val results = model.transform(data2) //评估模型 val WSSSE = model.computeCost(data2) println(s"Within Set Sum of Squared Errors = $WSSSE") //显示聚类结果。 println("Cluster Centers: ") model.clusterCenters.foreach(println) results.collect().foreach(row => {println( row(10) + " is predicted as cluster " + row(11))}) //部分结果 [0.0,0.0,1.0,0.0,0.0,0.0,1.0,11867.0,3327.0,4814.0,1178.0,3837.0,120.0] is predicted as cluster [0.0,0.0,2.1365167114232353,0.0,0.0,0.0,2.220261941072331,0.9383008955170281,0.4507899693071525,0.5065681906777801,0.24265278408979063,0.8047644998237361,0.0425515929773675] [0.0,0.0,1.0,0.0,0.0,0.0,1.0,16117.0,46197.0,92780.0,1026.0,40827.0,2944.0] is predicted as cluster [0.0,0.0,2.1365167114232353,0.0,0.0,0.0,2.220261941072331,1.2743402319919055,6.259436192390298,9.763065378289248,0.21134274743304346,8.562971132213624,1.0439324143780826] //当k=4的记录数 results.select("scaledFeatures","prediction").groupBy("prediction").count.show() +----------+-----+ |prediction|count| +----------+-----+ | 1| 10| | 3| 136| | 2| 64| | 0| 230| +----------+-----+ //由此可知,第0,3族较大,1,2比较小 results.select("scaledFeatures","prediction").filter(i=>i(1)==0).show(20) val result0=results.select("scaledFeatures","prediction").filter(i=>i(1)==0).select("scaledFeatures") |
10.6 模型优化
聚类模型中最重要的是参数k的选择,下面我们通过循环来获取哪个k值的性能最好。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
val KSSE = (2 to 20 by 1).toList.map { k => val kmeans = new KMeans().setFeaturesCol("scaledFeatures").setK(k).setSeed(123) val model = kmeans.fit(data2) // 评估性能. val WSSSE = model.computeCost(data2) // K,实际迭代次数,SSE,聚类类别编号,每类的记录数,类中心点 (k, model.getMaxIter, WSSSE, model.summary.cluster, model.summary.clusterSizes, model.clusterCenters) } //显示k、WSSSE评估指标,并按指标排序 KSSE.map(x=>(x._1,x._3)).sortBy(x=>x._2).foreach(println) //显示结果 (20,635.6231456631109) (19,674.1240263779249) (18,696.2925462727684) (17,747.697734807987) (15,848.393503421027) (16,878.8045714559038) (14,932.4137349866897) (13,988.2458378719449) (12,1026.9426528633646) (11,1165.7468060138433) (10,1201.1295734061587) (9,1242.388169008257) (8,1399.0770764839624) (7,1523.4613624094593) (6,1965.6551642041663) (5,2405.5349119889274) (4,2595.7328287620885) (3,3123.9948271417393) (2,3480.224930619828) //把该结果保存到HDFS上 KSSE.map(x=>(x._1,x._3)).sortBy(x=>x._2).toDF.write.save("/home/hadoop/data/ksse") |
以上数据可视化的图形如图10-2所示。

图10-2聚类模型中族K与评估指标的关系
从图10-2中不难看出,k<12时,性能(computeCost)提升比较明显,>12后,逐渐变缓。所以K越大不一定越好,恰当才是重要的。
当k=10时,聚类结果如下:
+----------+-----+
|prediction|count|
+----------+-----+
| 1| 65|
| 6| 18|
| 3| 86|
| 5| 27|
| 9| 3|
| 4| 2|
| 8| 2|
| 7| 46|
| 2| 27|
| 0| 164|
+----------+-----+
图10-3为k取10时(族0对应的channel和Region分别为1和3;族3对应的channel和Region分别为2和3),前两大族的销售均值比较图,从图中可以看出,团购冷藏食品均值大于或接近零售冷藏食品均值。说明团购对冷藏食品量比较大。
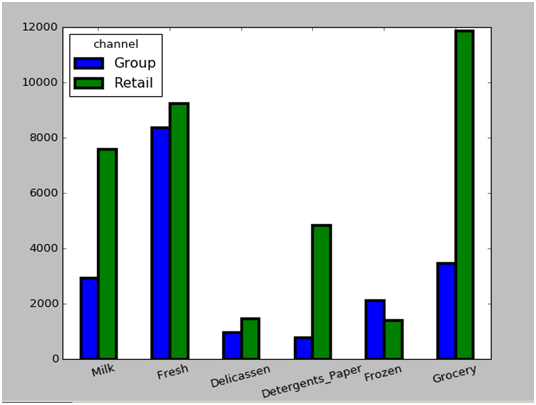
图10-3 聚类模型中K=10时0和3族平均销售额对比
10.7 小结
本章主要介绍了用Spark ML中的聚类算法,对某地多种销售数据进行聚类分析,在分析前对数据集主要特征进行了相关性分析,并对类别数据进行二元向量化,对连续性数据进行规范和标准化,然后把这些stages组装在流水线上,在模型训练中,我们尝试不同K的取值,以便获取最佳族群数。
不错!不错!感觉好极了!
博客还真是个好东西!