本章数据集下载
第9章 构建Spark ML回归模型
回归模型属于监督式学习,每个个体都有一个与之相关联的实数标签,并且我们希望在给出用于表示这些实体的数值特征后,所预测出的标签值可以尽可能接近实际值。
回归算法是试图采用对误差的衡量来探索变量之间的关系的一类算法。回归算法是统计机器学习的利器。在机器学习领域,人们说起回归,有时候是指一类问题,有时候是指一类算法,这一点常常会使初学者有所困惑。常见的回归算法包括:普通最小二乘法(OLS)(Ordinary Least Square),它使用损失函数是平方损失函数(1/2 (w^T x-y)^2),简单的预测就是y=w^T x,标准的最小二乘回归不使用正则化,这就意味着数据中异常数据点非常敏感,因此,在实际应用中经常使用一定程度的正则化(目的避免过拟合、提供泛化能力)。
本章主要介绍Spark ML中的回归模型,以回归分析中常用决策树回归、线性回归为例,对共享单车租赁的情况进行预测,其中介绍了一些特征转换、特征选择、交叉验证等方法的具体使用,主要内容包括:
回归模型简介
把数据加载到HDFS,Spark读取HDFS中的数据
探索特征及其分布信息
预处理数据
把pipeline的多个Stages组装到流水线上
模型优化
9.1 回归模型简介
ML目前支持回归模型有:
Linear regression (线性回归)
Generalized linear regression(广义线性回归)
Decision tree regression (决策树的回归)
Random forest regression(随机森林回归 )
Gradient-boosted tree regression (梯度提高树回归)
Survival regression(生存回归)
Isotonic regression(保序回归)
9.2 数据加载
查看数据大致情况:
|
1 2 3 4 5 6 7 8 9 10 11 |
####查看文件前3行数据 $ head -3 hour.csv instant,dteday,season,yr,mnth,hr,holiday,weekday,workingday,weathersit,temp,atemp,hum,windspeed,casual,registered,cnt 1,2011-01-01,1,0,1,0,0,6,0,1,0.24,0.2879,0.81,0,3,13,16 2,2011-01-01,1,0,1,1,0,6,0,1,0.22,0.2727,0.8,0,8,32,40 ###查看文件记录总数 $ wc -l hour.csv 17380 hour.csv ###查看文件列数 cat hour.csv | head -1 | awk -F ',' '{print NF}' 17 |
从数据集前3行的数据可以看出,第一行为标题,其他为租赁数据,共有17个字段和17380条记录。
把数据文件hour.csv复制到HDFS上。
|
1 |
$ hadoop fs -put hour.csv /home/hadoop/data |
以独立模式启动spark,然后读取数据。
|
1 |
$ spark-shell --master spark://master:7077 --driver-memory 1G --total-executor-cores 4 |
导入需要使用的类。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import org.apache.spark.sql.SparkSession import org.apache.spark.sql.Row import org.apache.spark.sql.DataFrame import org.apache.spark.sql.Dataset import org.apache.spark.ml.Pipeline import org.apache.spark.ml.evaluation.RegressionEvaluator import org.apache.spark.ml.linalg.Vectors import org.apache.spark.ml.feature.{IndexToString, StringIndexer, VectorIndexer,VectorAssembler} import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer} import org.apache.spark.ml.regression.DecisionTreeRegressionModel import org.apache.spark.ml.regression.DecisionTreeRegressor import org.apache.spark.ml.regression.LinearRegression import org.apache.spark.ml.regression.{RandomForestRegressionModel, RandomForestRegressor} import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ |
读取数据,把第一行为列名:
|
1 |
val rawdata = spark.read.format("csv").option("header", true).load("hdfs://master:9000/home/hadoop/data/hour.csv") |
查看前4行样本数据
|
1 2 3 4 5 6 7 8 9 |
rawdata.show(4) +-------+----------+------+---+----+---+-------+-------+----------+----------+----+------+----+---------+------+----------+---+ |instant| dteday|season| yr|mnth| hr|holiday|weekday|workingday|weathersit|temp| atemp| hum|windspeed|casual|registered|cnt| +-------+----------+------+---+----+---+-------+-------+----------+----------+----+------+----+---------+------+----------+---+ | 1|2011-01-01| 1| 0| 1| 0| 0| 6| 0| 1|0.24|0.2879|0.81| 0| 3| 13| 16| | 2|2011-01-01| 1| 0| 1| 1| 0| 6| 0| 1|0.22|0.2727| 0.8| 0| 8| 32| 40| | 3|2011-01-01| 1| 0| 1| 2| 0| 6| 0| 1|0.22|0.2727| 0.8| 0| 5| 27| 32| | 4|2011-01-01| 1| 0| 1| 3| 0| 6| 0| 1|0.24|0.2879|0.75| 0| 3| 10| 13| +-------+----------+------+---+----+---+-------+-------+----------+----------+----+------+----+---------+------+----------+---+ |
9.3 探索特征分布
Spark读取数据后,我们就可以对数据进行探索和分析,首先查看前4行样本数据
|
1 2 3 4 5 6 7 8 9 |
rawdata.show(4) +-------+----------+------+---+----+---+-------+-------+----------+----------+----+------+----+---------+------+----------+---+ |instant| dteday|season| yr|mnth| hr|holiday|weekday|workingday|weathersit|temp| atemp| hum|windspeed|casual|registered|cnt| +-------+----------+------+---+----+---+-------+-------+----------+----------+----+------+----+---------+------+----------+---+ | 1|2011-01-01| 1| 0| 1| 0| 0| 6| 0| 1|0.24|0.2879|0.81| 0| 3| 13| 16| | 2|2011-01-01| 1| 0| 1| 1| 0| 6| 0| 1|0.22|0.2727| 0.8| 0| 8| 32| 40| | 3|2011-01-01| 1| 0| 1| 2| 0| 6| 0| 1|0.22|0.2727| 0.8| 0| 5| 27| 32| | 4|2011-01-01| 1| 0| 1| 3| 0| 6| 0| 1|0.24|0.2879|0.75| 0| 3| 10| 13| +-------+----------+------+---+----+---+-------+-------+----------+----------+----+------+----+---------+------+----------+---+ |
查看rawdata的数据结构
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
rawdata.printSchema root |-- instant: string (nullable = true) |-- dteday: string (nullable = true) |-- season: string (nullable = true) |-- yr: string (nullable = true) |-- mnth: string (nullable = true) |-- hr: string (nullable = true) |-- holiday: string (nullable = true) |-- weekday: string (nullable = true) |-- workingday: string (nullable = true) |-- weathersit: string (nullable = true) |-- temp: string (nullable = true) |-- atemp: string (nullable = true) |-- hum: string (nullable = true) |-- windspeed: string (nullable = true) |-- casual: string (nullable = true) |-- registered: string (nullable = true) |-- cnt: string (nullable = true) |
目前这些数据的字段都是字符型,后续需要转换为数值型。
查看主要字段的统计信息
|
1 2 3 4 5 6 7 8 9 10 |
rawdata.describe("dteday","holiday","weekday","temp").show() +-------+----------+--------------------+-----------------+-------------------+ |summary| dteday| holiday| weekday| temp| +-------+----------+--------------------+-----------------+-------------------+ | count| 17379| 17379| 17379| 17379| | mean| null|0.028770355026181024|3.003682605443351| 0.4969871684216586| | stddev| null| 0.1671652763843717|2.005771456110986|0.19255612124972202| | min|2011-01-01| 0| 0| 0.02| | max|2012-12-31| 1| 6| 1| +-------+----------+--------------------+-----------------+-------------------+ |
其中有很多字段是类型型,如果使用回归算法时,需要通过OneHotEncoder把数据转换为二元向量,对一些字段或特征进行规范化。
通过pyspark可以画出主要特征的重要程度:
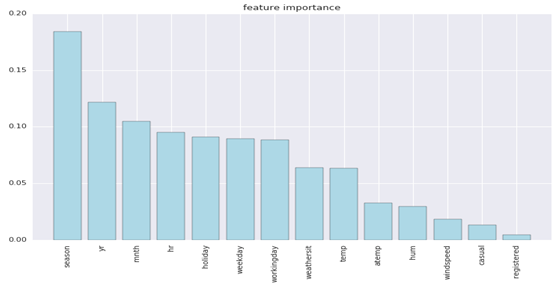
图9-2 各特征的重要性
通过pyspark可以画出其中一些特征的分布情况:
|
1 2 3 4 5 6 7 8 9 |
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt df=pd.read_csv('/home/hadoop/data/bike/hour.csv',header=0) sns.set(style='whitegrid',context='notebook') cols=['season','yr','temp','atemp','hum','windspeed','cnt'] sns.pairplot(df[cols],size=2.5) plt.show() |
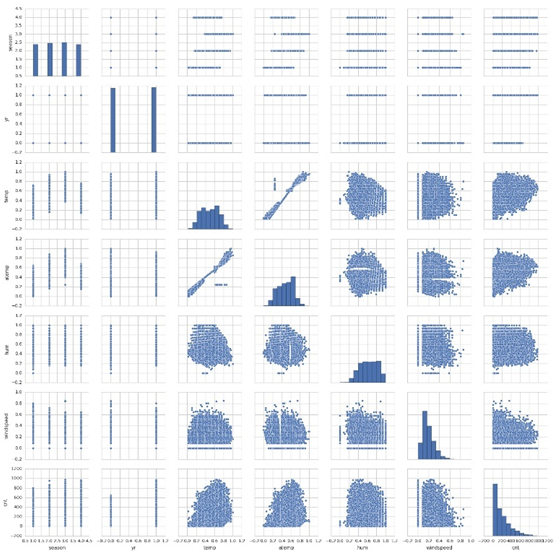
图9-3特征间的关系图
9.4 数据预处理
9.4.1 特征选择
首先把字符型的特征转换为数值类型,并过滤instant、dteday、casual、registered等4个无关或冗余特征。cnt特征作为标志。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
val data1= rawdata.select( rawdata("season").cast("Double"), rawdata("yr").cast("Double"), rawdata("mnth").cast("Double"), rawdata("hr").cast("Double"), rawdata("holiday").cast("Double"), rawdata("weekday").cast("Double"), rawdata("workingday").cast("Double"), rawdata("weathersit").cast("Double"), rawdata("temp").cast("Double"), rawdata("atemp").cast("Double"), rawdata("hum").cast("Double"), rawdata("windspeed").cast("Double"), rawdata("cnt").cast("Double").alias("label")) |
生成一个存放以上预测特征的特征向量
|
1 |
val featuresArray =Array("season","yr","mnth","hr","holiday","weekday","workingday","weathersit","temp","atemp","hum","windspeed") |
把源数据组合成特征向量features
|
1 |
val assembler = new VectorAssembler().setInputCols(featuresArray).setOutputCol("features") |
9.4.2 特征转换
使用决策树回归算法前,我们对类别特征进行索引化或数值化。
|
1 2 3 4 5 6 7 8 9 10 |
val featureIndexer = new VectorIndexer().setInputCol("features").setOutputCol("indexedFeatures").setMaxCategories(24) 对前8个类别字段或特征转换为二元向量。 val data2= new OneHotEncoder().setInputCol("season").setOutputCol("seasonVec") val data3= new OneHotEncoder().setInputCol("yr").setOutputCol("yrVec") val data4= new OneHotEncoder().setInputCol("mnth").setOutputCol("mnthVec") val data5= new OneHotEncoder().setInputCol("hr").setOutputCol("hrVec") val data6= new OneHotEncoder().setInputCol("holiday").setOutputCol("holidayVec") val data7= new OneHotEncoder().setInputCol("weekday").setOutputCol("weekdayVec") val data8= new OneHotEncoder().setInputCol("workingday").setOutputCol("workingdayVec") val data9= new OneHotEncoder().setInputCol("weathersit").setOutputCol("weathersitVec") |
因OneHotEncoder不是Estimator,这里我们对采用回归算法的数据另外进行处理,先建立一个流水线,把以上转换组装到这个流水线上。
|
1 2 |
val pipeline_en = new Pipeline().setStages(Array(data2,data3,data4,data5,data6,data7,data8,data9)) val data_lr = pipeline_en.fit(data1).transform(data1) |
把原来的4个及转换后的8个二元特征向量,拼接成一个feature向量。
|
1 |
val assembler_lr = new VectorAssembler().setInputCols(Array("seasonVec","yrVec","mnthVec","hrVec", "holidayVec","weekdayVec","workingdayVec","weathersitVec","temp","atemp","hum","windspeed")).setOutputCol("features_lr") |
9.5 组装
1)将data1数据分为训练和测试集(30%进行测试,种子设为12):
|
1 2 3 4 5 |
//对data1数据集进行随机划分,这份数据用于决策模型 val Array(trainingData, testData) = data1.randomSplit(Array(0.7, 0.3),12) //对data2数据集进行随机划分,这份数据用于回归模型 val Array(trainingData_lr, testData_lr) = data_lr.randomSplit(Array(0.7, 0.3),12) |
2)设置决策树回归模型参数
|
1 2 3 4 5 |
val dt = new DecisionTreeRegressor() .setLabelCol("label") .setFeaturesCol("indexedFeatures") .setMaxBins(64) .setMaxDepth(15) |
3)设置线性回归模型的参数
|
1 2 3 4 5 6 7 |
val lr =new LinearRegression() .setFeaturesCol("features_lr") .setLabelCol("label") .setFitIntercept(true) .setMaxIter(20) .setRegParam(0.3) .setElasticNetParam(0.8) |
4)把决策树回归模型涉及的特征转换及模型训练组装在一个流水线上。
|
1 |
val pipeline = new Pipeline().setStages(Array(assembler,featureIndexer, dt)) |
5)把线性回归模型涉及的特征转换、模型训练组装载一个流水上线。
|
1 |
val pipeline_lr= new Pipeline().setStages(Array(assembler_lr,lr)) |
6)训练模型
|
1 2 3 4 |
//训练决策树回归模型 val model = pipeline.fit(trainingData) //训练线性回归模型 val lrModel = pipeline_lr.fit(trainingData_lr) |
7)作出预测
|
1 2 3 4 |
//预测决策树回归的值 val predictions = model.transform(testData) //预测线性回归模型的值 val predictions_lr = lrModel.transform(testData_lr) |
8)评估模型
|
1 2 3 4 5 6 7 8 9 10 |
RegressionEvaluator.setMetricName可以定义四种评估器:rmse(缺省)、 mse、r^2、mae。 val evaluator =new RegressionEvaluator() .setLabelCol("label") .setPredictionCol("prediction") .setMetricName("rmse") //决策树模型评估指标 val rmse = evaluator.evaluate(predictions) //rmse: Double = 61.62409114645229 val rmse_lr = evaluator.evaluate(predictions_lr) // rmse_lr: Double = 102.05406408259029 |
从以上使用不同模型情况看来,决策树性能稍好与线性回归,但这仅是粗糙的比较,下面使用模型选择中介绍的一些方法,对线性模型进行优化。
9.6 模型优化
从图9-3可知,temp特征与atemp特征线性相关,而且从图9-2可知,atemp的贡献度较小,所以我们将过滤该特征。
|
1 |
val assembler_lr1 = new VectorAssembler().setInputCols(Array("seasonVec","yrVec","mnthVec","hrVec", "holidayVec","weekdayVec","workingdayVec","weathersitVec","temp","hum","windspeed")).setOutputCol("features_lr1") |
对label标签特征进行转换,使其更接近正态分布,这里我们SQLTransformer转换器,其具体使用可参考第4章。
|
1 2 3 4 5 |
//导入需要的包 import org.apache.spark.ml.feature.SQLTransformer //对特征label进行SQRT运行 val sqlTrans = new SQLTransformer().setStatement( "SELECT *, SQRT(label) as label1 FROM __THIS__") |
这里我们利用训练验证划分法对线性回归模型进行优化,对参数进行网格化,将数据集划分为训练集、验证集和测试集。
1)导入需要用到的包。
|
1 |
import org.apache.spark.ml.tuning.{ParamGridBuilder, TrainValidationSplit} |
2)建立模型,预测label1的值,设置线性回归参数。
|
1 2 3 4 |
val lr1 = new LinearRegression() .setFeaturesCol("features_lr1") .setLabelCol("label1") .setFitIntercept(true) |
3)设置流水线,为便于把特征组合、特征值优化、模型训练等任务组装到这条流水线上。
|
1 |
val pipeline_lr1 = new Pipeline().setStages(Array(assembler_lr1,sqlTrans,lr1)) |
4)建立参数网格。
|
1 2 3 4 5 |
val paramGrid = new ParamGridBuilder() .addGrid(lr1.elasticNetParam, Array(0.0, 0.8, 1.0)) .addGrid(lr1.regParam,Array(0.1,0.3,0.5)) .addGrid(lr1.maxIter, Array(20, 30)) .build() |
5)选择(prediction, label1),计算测试误差。
|
1 2 3 4 5 6 7 8 9 10 |
val evaluator_lr1 =new RegressionEvaluator() .setLabelCol("label1") .setPredictionCol("prediction") .setMetricName("rmse") //利用交叉验证方法 val trainValidationSplit = new TrainValidationSplit() .setEstimator(pipeline_lr1) .setEvaluator(evaluator_lr1) .setEstimatorParamMaps(paramGrid) .setTrainRatio(0.8) |
6)训练模型并自动选择最优参数。
|
1 |
val lrModel1 = trainValidationSplit.fit(trainingData_lr) |
7)查看模型全部参数
|
1 2 3 |
lrModel1.getEstimatorParamMaps.foreach { println } //参数组合 lrModel1.getEvaluator.extractParamMap() //查看评估参数 lrModel1.getEvaluator.isLargerBetter |
8)用最好的参数组合,做出预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
val predictions_lr1 = lrModel1.transform(testData_lr) val rmse_lr1 = evaluator_lr1.evaluate(predictions_lr1) //rmse_lr1: Double = 3.1354674045018514 //显示转换后特征值的前5行信息 predictions_lr1.select("features_lr1","label","label1","prediction").show(5) //结果显示如下: +--------------------+-----+------------------+------------------+ | features_lr1|label| label1| prediction| +--------------------+-----+------------------+------------------+ |(55,[1,4,6,17,40,...| 39.0| 6.244997998398398| 2.544732781830004| |(55,[1,4,6,17,40,...| 7.0|2.6457513110645907|1.1823933720401953| |(55,[1,4,6,17,40,...| 5.0| 2.23606797749979|1.3641560005748419| |(55,[1,4,6,17,40,...| 7.0|2.6457513110645907|1.7674507231166494| |(55,[1,4,6,17,40,...| 12.0|3.4641016151377544|1.5020350291356124| |
看了对标签特征进行转换、利用网格参数及训练验证划分等优化方法,从102下降到3左右,效果比较明显。
9.7 小结
本章主要介绍Spark ML的线性回归模型、决策树回归模型,对共享单车的租赁信息进行预测,由于很多数据不规范,因此,对原数据进行了二元向量转换、对类别数据索引化,然后把这些转换组装到流水线上,在训练集上训练模型,在测试集上进行预测,最后,更加评估指标对模型进行优化。
Pingback引用通告: 深度实践Spark机器学习 – 飞谷云人工智能