1.TensorFlow简介
TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统,采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即Tensor(张量),而Flow(流)意味着基于数据流图的计算,TensorFlow为张量从流图的一端流动到另一端计算过程。TensorFlow不只局限于神经网络,其数据流式图支持非常自由的算法表达,当然也可以轻松实现深度学习以外的机器学习算法。事实上,只要可以将计算表示成计算图的形式,就可以使用TensorFlow。TensorFlow可被用于语音识别或图像识别等多项机器深度学习领域,TensorFlow一大亮点是支持异构设备分布式计算,它能够在各个平台上自动运行模型,从手机、单个CPU / GPU到成百上千GPU卡组成的分布式系统。
2、TensorFlow安装
安装TensorFlow,因本环境的python3.6采用anaconda来安装,故这里采用conda管理工具来安装TensorFlow,目前conda缺省安装版本为TensorFlow1.2。
验证安装是否成功,可以通过导入tensorflow来检验。
启动ipython(或python)
测试测试TensorFlow,Jupyter Notebook及matplotlib
import numpy as np
import matplotlib.pyplot as plt
##通知笔记本将matplotlib图表直接显示在浏览器上
%matplotlib inline
a=tf.random_normal([2,40]) ###随机生成一个2x40矩阵
sess=tf.Session() ####启动session,并赋给一个sess对象
out=sess.run(a) ###执行对象a,并将输出数组赋给out
x,y=out ###将out这个2x40矩阵划分为两个1x40的向量x,y
plt.scatter(x,y) ###利用scatter绘制散点图
plt.show()

3、TensorFlow的发展
2015年11月9日谷歌开源了人工智能系统TensorFlow,同时成为2015年最受关注的开源项目之一。TensorFlow的开源大大降低了深度学习在各个行业中的应用难度。TensorFlow的近期里程碑事件主要有:
2016年04月:发布了分布式TensorFlow的0.8版本,把DeepMind模型迁移到TensorFlow;
2016年06月:TensorFlow v0.9发布,改进了移动设备的支持;
2016年11月:TensorFlow开源一周年;
2017年2月:TensorFlow v1.0发布,增加了Java、Go的API,以及专用的编译器和调试工具,同时TensorFlow 1.0引入了一个高级API,包含f.layers,tf.metrics和tf.losses模块。还宣布增了一个新的tf.keras模块,它与另一个流行的高级神经网络库Keras完全兼容。
2017年4月:TensorFlow v1.1发布,为Windows 添加 Java API 支,添加tf.spectral 模块,Keras 2 API等;
2017年6月:TensorFlow v1.2发布,包括 API 的重要变化、contrib API的变化和Bug 修复及其它改变等。
4、TensorFlow的特点
高度的灵活性
TensorFlow 采用数据流图,用于数值计算的开源软件库。只要计算能表示为一个数据流图,你就可以使用Tensorflow。
真正的可移植性
Tensorflow 在CPU和GPU上运行,可以运行在台式机、服务器、云服务器、手机移动设备、Docker容器里等等。
将科研和产品联系在一起
过去如果要将科研中的机器学习想法用到产品中,需要大量的代码重写工作。Tensorflow将改变这一点。使用Tensorflow可以让应用型研究者将想法迅速运用到产品中,也可以 让学术性研究者更直接地彼此分享代码,产品团队则用Tensorflow来训练和使用计算模 型,并直接提供给在线用户,从而提高科研产出率。
自动求微分
基于梯度的机器学习算法会受益于Tensorflow自动求微分的能力。使用Tensorflow,只 需要定义预测模型的结构,将这个结构和目标函数(objective function)结合在一起,并添加数据,Tensorflow将自动为你计算相关的微分导数。
多语言支持
Tensorflow 有一个合理的c++使用界面,也有一个易用的python使用界面来构建和执行你的graphs。你可以直接写python/c++程序,也可以用交互式的Ipython界面来用Tensorflow尝试这些想法,也可以使用Go,Java,Lua,Javascript,或者是R等语言。
性能最优化
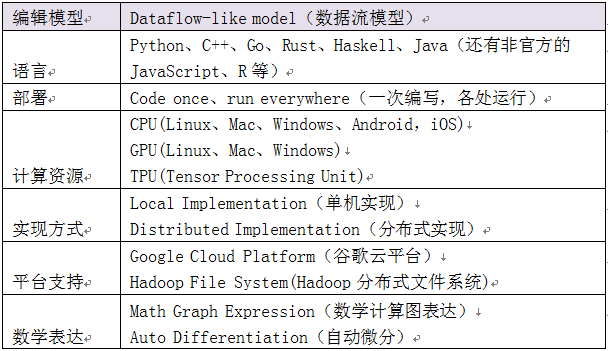
如果你有一个32个CPU内核、4个GPU显卡的工作站,想要将你工作站的计算潜能全发挥出来,由于Tensorflow 给予了线程、队列、异步操作等以最佳的支持,Tensorflow 让你可以将你手边硬件的计算潜能全部发挥出来。你可以自由地将Tensorflow图中的计 算元素分配到不同设备上,充分利用这些资源。下表为TensorFlow的一些主要技术特征:
5、TensorFlow的编程模式
TensorFlow是一个采用数据流图(Data Flow Graphs),节点(Nodes)在图中表示数学操作,图中的边(edges)则表示在节点间相互联系的任何维度的数据数组,即张量(tensor)。数据流图用结点(nodes)和边(edges)的有向无环图(DAG)来描述数学计算。节点一般用来表示施加的数学操作(tf.Operation),但也可以表示数据输入(feed in)的起点/输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。边表示节点之间的输入/输出关系。这些数据“边”可以输运“size可动态调整”的多维数据数组,即“张量”(tensor)。张量从图中流过的直观图像是这个工具取名为“Tensorflow”的原因。
Tensorflow中的计算可以表示为一个有向图(directed graph),或称计算图(computation graph),其中每一个运算操作将作为一个节点(node),节点与节点之间的连接成为边(edge),而在计算图的边中流动(flow)的数据被称为张量(tensor),所以形象的看整个操作就好像数据(tensor)在计算图(computation graphy)中沿着边(edge)流过(flow)一个个节点(node),这就是tensorflow名字的由来的。

计算图中的每个节点可以有任意多个输入和任意多个输出,每个节点描述了一种运算操作(operation, op),节点可以算作运算操作的实例化(instance)。计算图描述了数据的计算流程,它也负责维护和更新状态,用户可以对计算图的分支进行条件控制或循环操作。用户可以使用pyton、C++、Go、Java等语言设计计算图。tensorflow通过计算图将所有的运算操作全部运行在python外面,比如通过c++运行在cpu或通过cuda运行在gpu 上,所以实际上python只是一种接口,真正的核心计算过程还是在底层采用c++或cuda在cpu或gpu上运行。
一个 TensorFlow图描述了计算的过程. 为了进行计算, 图必须在会话(session)里被启动. 会话将图的op分发到诸如CPU或GPU之的备上, 同时提供执行op的方法. 这些方法执行后, 将产生的tensor返回. 在Python语言中, 返回的tensor是numpy ndarray对象; 在C和C++语言中, 返回的tensor是tensorflow::Tensor实例。
从上面的描述中我们可以看到,tensorflow的几个比较重要的概念:tensor, computation graphy, node, session。正如前面所说,整个操作就好像数据(tensor)在计算图(computation graphy)中沿着边(edge)流过(flow)一个个节点(node),然后通过会话(session)启动计算。所以简单来说,要完成这整个过程,我们需要的东西是要定义数据、计算图和计算图上的节点,以及启动计算的会话。所以在实际使用中我们要做的大部分工作应该就是定义这些内容了。
6、TensorFlow实例
TensorFlow如何工作?我们通过一个简单的实例进行说明,为计算x+y,你需要创建下图这张数据流图
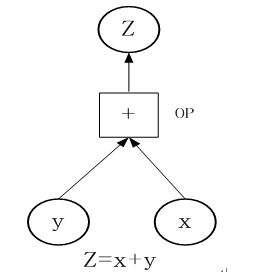
以下构成上数据流图的详细步骤:
1)定义x= [1,3,5],y =[2,4,7],这个图和tf.Tensor一起工作来代表数据的单位,你需要创建恒定的张量:
x = tf.constant([1,3,5])
y = tf.constant([2,4,7])
2)定义操作
3)张量和操作都有了,接下来就是创建图
这一步非必须,在创建回话时,系统将自动创建一个默认图。
4)为了运行这图你将需要创建一个回话(tf.Session),一个tf.Session对象封装了操作对象执行的环境,为了做到这一点,我们需要定义在会话中将要用到哪一张图:
x = tf.constant([1,3,5])
y = tf.constant([2,4,7])
op = tf.add(x,y)
5)想要执行这个操作,要用到tf.Session.run()这个方法:
my_graph = tf.Graph()
with tf.Session(graph=my_graph) as sess:
x = tf.constant([1,3,5])
y = tf.constant([2,4,7])
op = tf.add(x,y)
result = sess.run(fetches=op)
print(result)
6)运行结果:
[ 3 7 12]
7、几乎所有深度框架都是基于计算图,计算图可分为静态计算图和动态计算图。静态计算图,先定义再运行,一次定义多次运行;动态计算图在运行过程中被定义,在运行中构建,可以多次构建多次运行。Tensorflow属于静态图,先构造图形,然后创建sess,最后run。这里我们介绍深度学习另一种框架Pytorch,它属于动态图形,每步生成图的一部分,最后把图组合起来,形成一个完整图形,具体可参考下图。

以上动态图对应的代码为:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import torch #这里采用pytorch 最新版本0.4 # 只要将Tensor类的requires_grad设成True # 就会为这些节点构建计算图 x = torch.tensor(data_x, requires_grad=True) W_x = torch.tensor(data_wx, requires_grad=True) h = torch.tensor(data_h, requires_grad=True) W_h = torch.tensor(data_wh, requires_grad=True) i2h = torch.mm(W_x, x.t()) h2h = torch.mm(W_h, h.t()) next_h = h2h + i2h next_next_h = next_h.tanh() next_next_h.backward() |