文章目录
本章数据集下载
第11章 PySpark 决策树模型
Spark不但好用、而且还易用、通用,它提供多种的开发语言的API,除了Scala外,还有Java、Python、R等,可以说集成目前市场最有代表性的开发语言,使得Spark受众上升几个数据量级,同时也无形中降低了学习和使用它的门槛,使得很多熟悉Java、Python、R的编程人员、数据分析师,也可方便地利用Spark大数据计算框架来实现他们的大数据处理、机器学习等任务。
Python作为机器学习中的利器,一直被很多开发者和学习者所推崇的一种语言。除了开源、易学以及简洁的代码风格的特性之外,Python当中还有很多优秀的第三方的库,为我们对数据进行处理、探索和模型的构建提供很大的便利,如Pandas、Numpy、Scipy、Matplotlib、StatsModels、Scikit-Learn、Keras等。Python的强大还体现在它的与时俱进,它与大数据计算平台Spark的结合,可为是强强联合、优势互补、相得益彰,这就有了现如今Spark当中一个重要分支--PySpark。其内部架构可参考图11-1(该图取自https://cwiki.apache.org/confluence/display/SPARK/PySpark+Internals?spm=5176.100239.0.0.eI85ij)。
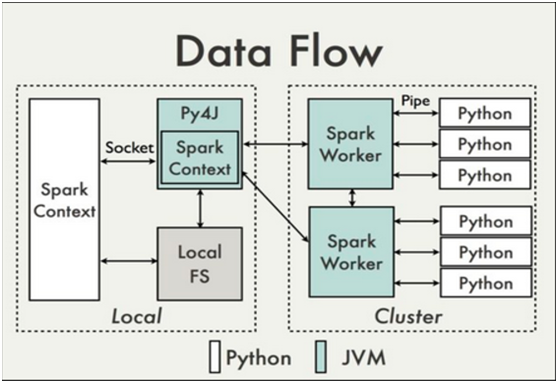
图11-1 PySpark架构图
PySpark的Python解释器在启动时会同时启动一个JVM,Python解释器与JVM进程通过socket进行通信,在python driver端,SparkContext利用Py4J启动一个JVM并产生一个JavaSparkContext。Py4J只使用在driver端,用于本地python与Java SparkContext objects的通信。大量数据的传输使用的是另一个机制。RDD在python下的转换会被映射成java环境下PythonRDD。在远端worker机器上,PythonRDD对象启动一些子进程并通过pipes与这些子进程通信,以此send用户代码和数据。
本章节就机器学习中的决策树模型,使用PySpark中的ML库以及IPython交互式环境进行示例。具体内容如下:
决策树简介
数据加载
数据探索
创建决策树模型
训练模型并进行预测
利用交叉验证、网格参数等进行模型调优
最后生成一个可执行python脚本
11.1 PySpark 简介
在Spark的官网上这么介绍PySpark:“PySpark is the Python API for Spark”,也就是说PySpark其实是Spark为Python提供的编程接口。此外,Spark还提供了关于Scala、Java和R的编程接口,关于Spark为R提供的编程接口(Spark R)将在第12章进行介绍。
11.2 决策树简介
决策树在机器学习中是很常见且经常使用的模型,它是一个强大的非概率模型,可以用来表达复杂的非线性模式和特征相互关系。
图11-2决策树结构
关于决策树的原理,这里不再赘述。本章着重讨的是,决策树的分类模型在PySpark中的应用。
11.3数据加载
11.3.1 原数据集初探
这里的数据选择为某比赛的数据集,用来预测推荐的一些页面是短暂(昙花一现)还是长久(长时流行)。原数据集为train.tsv,存放路径在 /home/hadoop/data/train.tsv。
先使用shell命令对数据进行试探性的查看,并做一些简单的数据处理。
1) 查看前2行数据
|
1 2 3 4 |
$ head -2 train.tsv "url" "urlid" "boilerplate" "alchemy_category" "alchemy_category_score" "avglinksize" "commonlinkratio_1" "commonlinkratio_2" "commonlinkratio_3" "commonlinkratio_4" "compression_ratio" "embed_ratio" "framebased" "frameTagRatio" "hasDomainLink" "html_ratio" "image_ratio" "is_news" "lengthyLinkDomain" "linkwordscore" "news_front_page" "non_markup_alphanum_characters" "numberOfLinks" "numwords_in_url" "parametrizedLinkRatio" "spelling_errors_ratio" "label" "http://www.bloomberg.com/news/2010-12-23/ibm-predicts-holographic-calls-air-breathing-batteries-by-2015.html" "4042" "{""title"":""IBM Sees Holographic Calls Air Breathing Batteries ibm sees holographic calls, air-breathing batteries"",""body"":""A sign stands outside the International Business Machines Corp IBM Almaden Research Center campus in San Jose Cali "8" .............. "0.152941176" "0.079129575" "0" |
数据集中的第1行为标题(字段名)行,下面是一些的字段说明。
查看文件记录总数
|
1 2 |
$ cat train.tsv |wc -l 7396 |
结果显示共有:数据集一共有7396条数据
2) 由于textFile目前不好过滤标题行数据,为便于spark操作数据,需要先删除标题。
|
1 |
$ sed 1d train.tsv >train_noheader.tsv |
3) 将数据文件上传到 hdfs
|
1 |
$ hdfs dfs -put train_noheader.tsv /data |
4) 查看是否成功
|
1 2 3 4 |
hadoop@master:~/data$ hdfs dfs -ls /data 17/05/24 00:46:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 1 items -rw-r--r-- 1 hadoop supergroup 21972457 2017-05-24 00:46 /data/train_noheader.tsv |
11.3.2 PySpark 的启动
以spark Standalone模式启动spark集群,保证内存分配充足。
|
1 |
$ pyspark --master spark://master:7077 --driver-memory 1G --total-executor-cores 4 |
[注]:使用pyspark --help 可以查看指令的详细帮助信息。
|
1 2 3 4 |
# Default to standard python interpreter unless told otherwise if [[ -z "$PYSPARK_DRIVER_PYTHON" ]]; then PYSPARK_DRIVER_PYTHON="${PYSPARK_PYTHON:-"ipython"}" fi |
11.3.3 基本函数
这里将本章节中需要用到函数和方法做一个简单的说明,如表11-4所示。
表11-4 本章使用的一些函数或方法简介

11.4数据探索
1) 通过sc对象的textFile方法,载入本地数据文件,创建RDD
|
1 |
In [1]: raw_data = sc.textFile("hdfs://master:9000/data/train_noheader.tsv") |
2) 查看第1行数据
|
1 2 3 |
In [2]: raw_data.take(2) Out[2]:[u'"http://www.bloomberg.com/news/2010-12-23/ibm-predicts-holographic-calls-air-breathing-batteries-by-2015.html"\t"4042"\t"{""title"":""IBM Sees Holographic Calls Air Breathing Batteries ibm sees holographic calls, air-breathing batteries"",""body"":""A sign stands outside the International Business Machines Corp IBM Almaden Research Center campus in San Jose Cali..."\t...\t"8"\t"0.152941176"\t"0.079129575"\t"0"', u'"http://www.popsci.com/technology/article/2012-07/electronic-futuristic-starting-gun-eliminates-advantages-races"\t"8471"\t"{""title"":""The Fully Electronic Futuristic Starting Gun That Eliminates Advantages in Races the fully electronic, futuristic starting gun that eliminates advantages in races the fully electronic, futuristic starting gun that eliminates advantages in races"",""body"":""And that can be carried on a plane without the hassle too The Omega..."\t...\t"9"\t"0.181818182"\t"0.125448029"\t"1"'] |
3) 查看数据文件的总行数
|
1 2 3 |
In [3]: numRaws = raw_data.count() In [4]: numRaws Out[4]: 7395 |
4) 按键进行统计
|
1 2 |
In [5]: raw_data.countByKey() Out[5]: defaultdict(int, {u'"': 7395}) |
原数据文件总的行数为7396,由于我们在数据加载中将数据集的第一行数据已经去除掉,所以这里结果为7395。
11.5数据预处理
1) 由于后续的算法我们不需要时间戳以及网页的内容,所以这里先将其过滤掉。
|
1 |
In [6]: records = raw_data.map(lambda line: line.split('\t')) |
2) 查看records 数据结构
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
In [7]: records.first() Out[7]: [u'"http://www.bloomberg.com/news/2010-12-23/ibm-predicts-holographic-calls-air-breathing-batteries-by-2015.html"', u'"4042"', u'"{""title"":""IBM Sees Holographic Calls Air Breathing Batteries ibm sees holographic calls, air-breathing batteries"",""body"":""A sign stands outside the International Business Machines Corp IBM Almaden Research Center campus in San Jose California Photographer Tony Avelar...""}"', u'"business"', u'"0.789131"', u'"2.055555556"', u'"0.676470588"', u'"0.205882353"', u'"0.047058824"', u'"0.023529412"', u'"0.443783175"', u'"0"', u'"0"', u'"0.09077381"', u'"0"', u'"0.245831182"', u'"0.003883495"', u'"1"', u'"1"', u'"24"', u'"0"', u'"5424"', u'"170"', u'"8"', u'"0.152941176"', u'"0.079129575"', u'"0"'] |
3) 查看每一行的列数
|
1 2 |
In [8]: len(records.first()) Out[8]: 27 |
导入Vectors 矢量方法
|
1 |
In [9]: from pyspark.ml.linalg import Vectors |
导入决策树分类器
|
1 |
In [10]: from pyspark.ml.classification import DecisionTreeClassifier |
4) 将RDD中的所有元素以列表的形式返回
|
1 |
In [11]: data = records.collect() |
5) 查看data数据一行有多少列
|
1 2 3 |
In [12]: numColumns = len(data[0]) In [13]: numColumns Out[13]: 27 |
6) 定义一个列表data1,存放清理过的数据,格式为[(label_1, features_1), (label_2, features_2),…]
|
1 |
In [14]: data1 = [] |
对数据进行清理工作中的1,2,3步
|
1 2 3 4 5 6 7 |
In [15]: for i in range(numRaws): trimmed = [ each.replace('"', "") for each in data[i] ] label = int(trimmed[-1]) features = map(lambda x: 0.0 if x == "?" else x, trimmed[4:numColumns-1]) c = (label, Vectors.dense(map(float, features))) data1.append(c) |
11.6创建决策树模型
1) 将data1 转换为DataFrame对象,label表示标签列,features 表示特征值列
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
In [16]: df= spark.createDataFrame(data1, ["label","features"]) In [17]: df.show(10) +-----+--------------------+ |label| features| +-----+--------------------+ | 0|[0.789131,2.05555...| | 1|[0.574147,3.67796...| | 1|[0.996526,2.38288...| | 1|[0.801248,1.54310...| | 0|[0.719157,2.67647...| | 0|[0.0,119.0,0.7454...| | 1|[0.22111,0.773809...| | 0|[0.0,1.883333333,...| | 1|[0.0,0.471502591,...| | 1|[0.0,2.41011236,0...| +-----+--------------------+ only showing top 10 rows # 显示 df 的Schema In [18]: df.printSchema() root |-- label: long (nullable = true) |-- features: vector (nullable = true) |
2) 由于后面会经常使用,所以将df载入内存
|
1 2 |
In [19]: df.cache() Out[19]: DataFrame[label: double, features: vector] |
3) 建立特征索引
|
1 2 |
In [20]: from pyspark.ml.feature import VectorIndexer In [20]: featureIndexer = VectorIndexer(inputCol="features", outputCol="indexedFeatures", maxCategories=24).fit(df) |
4) 将数据切分成80%训练集和20%测试集
|
1 2 3 4 5 6 7 8 |
#seed=1234L,表示每次随机生成的训练集和测试集的总行数不变 In [21]: (trainingData, testData) = df.randomSplit([0.8, 0.2],seed=1234L) In [22]: trainingData.count() Out[22]: 5912 In [23]: testData.count() Out[23]: 1483 |
5) 指定决策树模型的深度、标签列,特征值列,使用信息熵(entropy)作为评估方法,并训练数据。
|
1 |
In [24]: dt = DecisionTreeClassifier(maxDepth=5, labelCol="label", featuresCol="indexedFeatures", impurity="entropy") |
6) 构建流水线工作流
|
1 2 3 4 5 |
In [25]: from pyspark.ml import Pipeline In [26]: pipeline = Pipeline(stages=[featureIndexer, dt]) In [27]: model = pipeline.fit(trainingData) ## 训练模型 |
下面我们用一组已知数据和一组新数据重新预测下结果:
11.7训练模型进行预测
1) 使用第一行数据进行预测结果,看看是否相符合,这里先来看一下原数据集第一行数据
|
1 2 3 4 |
In [28]: data1[0] Out[28]: (0.0, DenseVector([0.7891, 2.0556, 0.6765, 0.2059, 0.0471, 0.0235, 0.4438, 0.0, 0.0, 0.0908, 0.0, 0.2458, 0.0039, 1.0, 1.0, 24.0, 0.0, 5424.0, 170.0, 8.0, 0.1529, 0.0791])) |
2) 使用数据集中第一行的特征值数据进行预测
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
In [29]: test0 = spark.createDataFrame([(data1[0][1],)], ["features"]) In [30]: result = model.transform(test0) # 查看预测结果 In [31]: result.show() +--------------------+--------------------+-------------+--------------------+----------+ | features| indexedFeatures|rawPrediction| probability|prediction| +--------------------+--------------------+-------------+--------------------+----------+ |[0.789131,2.05555...|[0.789131,2.05555...|[274.0,310.0]|[0.46917808219178...| 1.0| +--------------------+--------------------+-------------+--------------------+----------+ In [32]: predictedResult.select(['prediction']).show() #只获取预测值 +----------+ |prediction| +----------+ | 1.0| +----------+ |
3) 将第一行的特征值数据修改掉2个(这里换掉第一个和第二个值),进行该特征值下的预测.
|
1 2 3 4 5 6 7 8 |
# 将第一行的数据进行修改 In [33]: firstRaw = list(data1[0][1]) In [34]: firstRaw[0] = 2.7891 In [35]: firstRaw[1] = 0.0556 In [36]: predictedData = Vectors.dense(firstRaw) In [37]: predictedData Out[37]: DenseVector([2.7891, 0.0556, 0.6765, 0.2059, 0.0471, 0.0235, 0.4438, 0.0, 0.0, 0.0908, 0.0, 0.2458, 0.0039, 1.0, 1.0, 24.0, 0.0, 5424.0, 170.0, 8.0, 0.1529, 0.0791]) |
4) 进行新数据的预测
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
In [38]: predictedRaw = spark.createDataFrame([(predictedData,)], ["features"]) In [39]: predictedResult = model.transform(predictedRaw) In [40]: predictedResult.show() +--------------------+--------------------+-------------+--------------------+----------+ | features| indexedFeatures|rawPrediction| probability|prediction| +--------------------+--------------------+-------------+--------------------+----------+ |[2.7891,0.0556,0....|[2.7891,0.0556,0....|[274.0,310.0]|[0.46917808219178...| 1.0| +--------------------+--------------------+-------------+--------------------+----------+ In [41]: predictedResult.select(['prediction']).show() +----------+ |prediction| +----------+ | 1.0| +----------+ |
5) 下面我们用测试数据做决策树准确度测试
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
# 通过模型,预测测试集 In [42]: predictedResultAll = model.transform(testData) #查看预测值 In [43]: predictedResultAll.select("prediction").show() +----------+ |prediction| +----------+ | 0.0| | 0.0| | 1.0| | 1.0| | 0.0| | 0.0| | 0.0| | 0.0| | 0.0| | 1.0| +----------+ only showing top 10 rows #由于预测值是DataFrame对象,每一行是Raw型,不可做修改 #需将预测值转换为pandas,然后转换为列表 In [44]:df_prediction = predictedResultAll.select("prediction").toPandas() In [45]: dtPredictions = list(df_prediction.prediction) #查看前10个预测值 In [46]: dtPredictions[:10] Out[46]: [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0] #对预测值做准确性统计 In [47]: dtTotalCorrect = 0 #获取测试集的总行数 In [48]: testRaw = testData.count() In [49]: testLabel = testData.select("label").collect() In [50]: for i in range(testRaw): if dtPredictions[i] == testLabel[i]: dtTotalCorrect += 1 In [51]: dtTotalCorrect Out[51]: 940 In [52]: 1.0 * dtTotalCorrect / testRaw Out[52]: 0.6338503034389751 |
11.8模型优化
在上一个小节中,我们发现使用决策树的正确率不算高,只有63.3850%。在这一小节,我们探究一下改进预测准确率的方法。
11.8.1特征值的优化
1) 先将之前用到的一些代码加载进来。
|
1 2 3 4 5 6 7 8 9 10 |
In [1]: from pyspark.ml.linalg import Vectors In [2]: from pyspark.ml.classification import DecisionTreeClassifier In [3]: from pyspark.ml.feature import VectorIndexer In [4]: from pyspark.ml import Pipeline In [5]: raw_data = sc.textFile("hdfs://master:9000/data/train_noheader.tsv") In [6]: numRaws = raw_data.count() In [7]: records = raw_data.map(lambda line: line.split('\t')) In [8]: data = records.collect() In [9]: numColumns = len(data[0]) In [10]: data1 = [] |
2) 由于这里对网页类型的标识有很多,需要单独挑选出来进行处理。
|
1 2 |
#将第三列网页类型的引号去除掉 In [11]: category = records.map(lambda x: x[3].replace("\"","")) |
将网页的唯一类型删选出来,并进行排序。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
In [12]: categories = sorted(category.distinct().collect()) In [13]: categories Out[13]: [u'?', u'arts_entertainment', u'business', u'computer_internet', u'culture_politics', u'gaming', u'health', u'law_crime', u'recreation', u'religion', u'science_technology', u'sports', u'unknown', u'weather'] |
3) 查看网页类型的个数。
|
1 2 3 |
In [14]: numCategories = len(categories) In [15]: numCategories Out[15]: 14 |
4) 紧接着,我们定义一个函数,用于返回当前网页类型的列表。
|
1 2 3 4 5 6 |
In [16]: def transform_category(x): markCategory = [0] * numCategories index = categories.index(x) markCategory[index] = 1 return markCategory |
5) 通过这样的处理,我们将网页类型这一个特征值转化14个特征值,整体的特征值其实就增加了14个。接下来,我们在处理的时候将这个些特征值加入进去。
|
1 2 3 4 5 6 7 8 |
In [17]: for i in range(numRaws): trimmed = [ each.replace('"', "") for each in data[i] ] label = float(trimmed[-1]) cate = transform_category(trimmed[3]) #调用函数,返回一个类型列表 features = cate + map(lambda x: 0.0 if x == "?" else (x), trimmed[4:numColumns - 1]) c = (label, Vectors.dense(map(float, features))) data1.append(c) |
6) 创建DataFrame对象。
|
1 2 3 4 5 |
In [18]: df= spark.createDataFrame(data1, ["label","features"]) #由于后面经常使用df,所以载入内存 In [19]: df.cache() Out[20]: DataFrame[label: double, features: vector] |
7) 建立特征索引。
|
1 2 |
In [21]: from pyspark.ml.feature import VectorIndexer In [22]: featureIndexer = VectorIndexer(inputCol="features", outputCol="indexedFeatures", maxCategories=24).fit(df) |
8) 将数据切分成80%训练集和20%测试集。
|
1 2 3 4 5 6 7 |
In [23]: (trainingData, testData) = df.randomSplit([0.8, 0.2],seed=1234L) In [24]: trainingData.count() Out[24]: 5912 In [25]: testData.count() Out[25]: 1483 |
9) 创建决策树模型。
|
1 |
In [26]: dt = DecisionTreeClassifier(maxDepth=5, labelCol="label", featuresCol="indexedFeatures", impurity="entropy") |
10) 构建流水线工作流。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
In [27]: pipeline = Pipeline(stages=[featureIndexer, dt]) In [28]: model = pipeline.fit(trainingData) ## 训练模型 11) 用测试数据再一次做下决策树准确度测试。 In [29]: predictedResultAll = model.transform(testData) In [30]:df_prediction = predictedResultAll.select("prediction").toPandas() In [31]: dtPredictions = list(df_prediction.prediction) #对预测值做准确性统计 In [32]: dtTotalCorrect = 0 #测试集的总行数 In [33]: testRaw = testData.count() In [49]: testLabel = testData.select("label").collect() In [34]: for i in range(testRaw): if dtPredictions[i] == testLabel[i]: dtTotalCorrect += 1 In [35]: dtTotalCorrect Out[35]: 967 In [36]: 1.0 * dtTotalCorrect / testRaw Out[36]: 0.6520566419420094 |
可以看到,准确率增大到了63.3850%,而未做优化前的准确率是65.2057%。增长了1.88%。效果还是比较显著的。
11.8.2交叉验证和网格参数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
In [1]: from pyspark.ml.linalg import Vectors In [2]: from pyspark.ml.classification import DecisionTreeClassifier In [3]: from pyspark.ml.feature import VectorIndexer In [4]: from pyspark.ml import Pipeline In [5]: raw_data = sc.textFile("hdfs://master:9000/data/train_noheader.tsv") In [6]: numRaws = raw_data.count() In [7]: records = raw_data.map(lambda line: line.split('\t')) In [8]: data = records.collect() In [9]: numColumns = len(data[0]) In [10]: data1 = [] In [11]: category = records.map(lambda x: x[3].replace("\"","")) In [12]: categories = sorted(category.distinct().collect()) In [13]: numCategories = len(categories) In [14]: def transform_category(x): markCategory = [0] * numCategories index = categories.index(x) markCategory[index] = 1 return markCategory In [15]: for i in range(numRaws): trimmed = [ each.replace('"', "") for each in data[i] ] label = float(trimmed[-1]) cate = transform_category(trimmed[3]) #调用函数,返回一个类型列表 features = cate + map(lambda x: 0.0 if x == "?" else (x), trimmed[4:numColumns - 1]) c = (label, Vectors.dense(map(float, features))) data1.append(c) In [16]: df= spark.createDataFrame(data1, ["label","features"]) In [17]: df.cache() In [18]: featureIndexer = VectorIndexer(inputCol="features", outputCol="indexedFeatures", maxCategories=24).fit(df) In [19]: dt = DecisionTreeClassifier(maxDepth=5, labelCol="label", featuresCol="indexedFeatures", impurity="entropy") In [20]: pipeline = Pipeline(stages=[featureIndexer, dt]) In [21]: (trainingData, testData) = df.randomSplit([0.8, 0.2],seed=1234L) |
创建交叉验证和网格参数
|
1 2 3 4 5 6 7 8 9 |
# 导入交叉验证和参数网格 In [22]: from pyspark.ml.tuning import CrossValidator, ParamGridBuilder #导入二分类评估器 In [23]: from pyspark.ml.evaluation import BinaryClassificationEvaluator In [24]: evaluator = BinaryClassificationEvaluator() # 初始化一个评估器 #设置参数网格 In [25]: paramGrid = ParamGridBuilder().addGrid(dt.maxDepth, [4,5,6]).build() #设置交叉验证的参数 In [26]: cv = CrossValidator().setEstimator(pipeline).setEvaluator(evaluator).setEstimatorParamMaps(paramGrid).setNumFolds(2) |
通过交叉验证来训练模型
|
1 |
In [27]: cvModel = cv.fit(trainingData) |
测试模型
|
1 |
In [28]: Predictions=cvModel.transform(testData) |
准确率统计
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
In [29]: df_prediction = Predictions.select("prediction").toPandas() In [30]: dtPredictions = list(df_prediction.prediction) #对预测值做准确性统计 In [31]: dtTotalCorrect = 0 #测试集的总行数 In [32]: testRaw = testData.count() In [34]: testLabel = testData.select("label").collect() In [33]: for i in range(testRaw): if dtPredictions[i] == testLabel[i]: dtTotalCorrect += 1 In [34]: dtTotalCorrect Out[34]: 960 In [35]: 1.0 * dtTotalCorrect / testRaw Out[35]: 0.6473364801078895 我们还可以查看最匹配模型的具体参数 In [36]: bestmodel = cvModel.bestModel.stages[1] In [37]: bestmodel.numFeatures #决策树有36个特征值 Out[37]: 36 In [38]: bestmodel.depth #最大深度为10 Out[38]: 6 In [39]: bestmodel.numNodes #决策树中点有457个 |
11.9脚本方式运行
11.9.1 在脚本中添加配置信息
创建一个decisionTree.py文件,添加如下代码来配置启动pyspark。将上述在pyspark的IPython中的代码添加到该文件中来。
本文的示例程序存为 /home/hadoop/projects/spark/pyspark/decisionTree.py。
|
1 2 3 4 5 6 7 8 9 10 |
from pyspark import SparkConf, SparkContext from pyspark.sql import SparkSession #指定本地运行spark conf = SparkConf().setMaster("local[*]") sc = SparkContext(conf=conf) spark = SparkSession.builder.master('local') \ .appName('DecisionTree') \ .config("spark.some.config.option", "some-value") \ .getOrCreate() |
11.9.2运行脚本程序
spark 2.0 之前使用pyspark decisionTree.py 来执行文件,spark 2.0之后统一用spark-submit decisionTree.py 执行文件。读者可以使用spark-submit --help来查看相关命令的帮助信息。
|
1 |
$ spark-submit decisionTree.py |
11.10小结
本章我们了Spark中的 PySpark使用方法,对于PySpark做了简单的介绍。讨论了分类模型中最常见的决策树模型在PySpark 的应用,用实例讲解了如何对数据进行清理、转换,分析了分类模型的准确性有待提高的的原因,通过可视化对决策树的不同深度下的准确度进行讨论。