第7章集成学习
7.1集成学习概述
集成学习(ensemble learning)可以说是现在非常火爆的机器学习方法了。它本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务。也就是我们常说的“博采众长”。集成学习可以用于分类问题集成,回归问题集成,特征选取集成,异常点检测集成等等,可以说所有的机器学习领域都可以看到集成学习的身影,甚至在目前最火的深度学习中也常见其影子。
集成学习的主要思想:对于一个比较复杂的任务,综合许多人的意见来进行决策往往比一家独大好,正所谓集思广益。其过程如下:
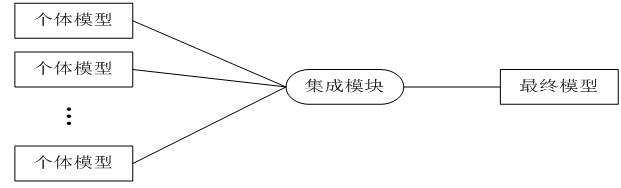
7.2投票分类器(VotingClassifier)
投票分类器的原理是结合了多个不同的机器学习分类器,使用多数票或者平均预测概率(软票),预测类标签。这类分类器对一组相同表现的模型十分有用,同时可以平衡各自的弱点。投票分类又可进一步分为多数投票分类(Majority Class Labels)、加权平均概率(soft vote,软投票)。
7.2.1多数投票分类(MajorityVote Class)
多数投票分类的分类原则为预测标签不同时,按最多种类为最终分类;如果预测标签相同时,则按顺序,选择排在第1的标签为最终分类。举例如下:
预测类型的标签为该组学习器中相同最多的种类:例如给出的分类如下
分类器1 -> 标签1
分类器2 -> 标签1
分类器3 -> 标签2
投票分类器(voting=‘hard’)则该预测结果为‘标签1’。
在各个都只有一个的情况下,则按照顺序来,如下:
分类器1 -> 标签2
分类器2 -> 标签1
最终分类结果为“标签2”
7.2.1.1Iris数据集概述
首先,我们取得数据,下面这个链接中有数据的详细介绍,并可以下载数据集。https://archive.ics.uci.edu/ml/datasets/Iris
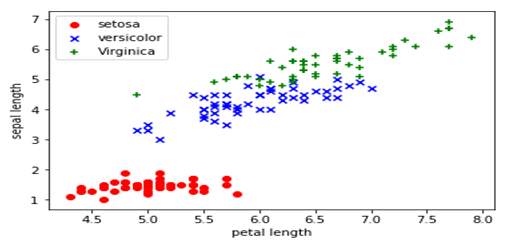
从数据的说明上,我们可以看到Iris有4个特征,3个类别。但是,我们为了数据的可视化,我们只保留2个特征(sepal length和petal length)。数据可视化代码如下:
import pandas as pd
import matplotlib.pylab as plt
import numpy as np
# 加载Iris数据集作为DataFrame对象
df = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
X = df.iloc[:, [0, 2]].values # 取出2个特征,并把它们用Numpy数组表示
plt.scatter(X[:50, 0], X[:50, 1],color='red', marker='o', label='setosa') # 前50个样本的散点图
plt.scatter(X[50:100, 0], X[50:100, 1],color='blue', marker='x', label='versicolor') # 中间50个样本的散点图
plt.scatter(X[100:, 0], X[100:, 1],color='green', marker='+', label='Virginica') # 后50个样本的散点图
plt.xlabel('petal length')
plt.ylabel('sepal length')
plt.legend(loc=2) # 把说明放在左上角,具体请参考官方文档
plt.show()
示例代码如下:
from sklearn import cross_validation
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
eclf = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)], voting='hard', weights=[2,1,2])
for clf, label in zip([clf1, clf2, clf3, eclf], ['Logistic Regression', 'Random Forest', 'naive Bayes', 'Ensemble']):
scores = cross_validation.cross_val_score(clf, X, y, cv=5, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
运行结果如下:
Accuracy: 0.90 (+/- 0.05) [Logistic Regression]
Accuracy: 0.93 (+/- 0.05) [Random Forest]
Accuracy: 0.91 (+/- 0.04) [naive Bayes]
Accuracy: 0.95 (+/- 0.05) [Ensemble]
7.2.2多数投票分类(MajorityVote Class)
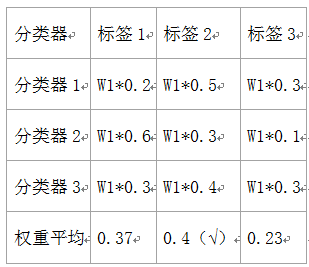
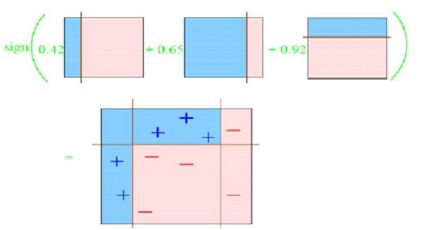
相对于多数投票(hard voting),软投票返回预测概率值的总和最大的标签。可通过参数weights指定每个分类器的权重;若权重提供了,在计算时则会按照权重计算,然后取平均;标签则为概率最高的标签。
举例说明,假设有3个分类器,3个类,每个分类器的权重为:w1=1,w2=1,w3=1。如下表:
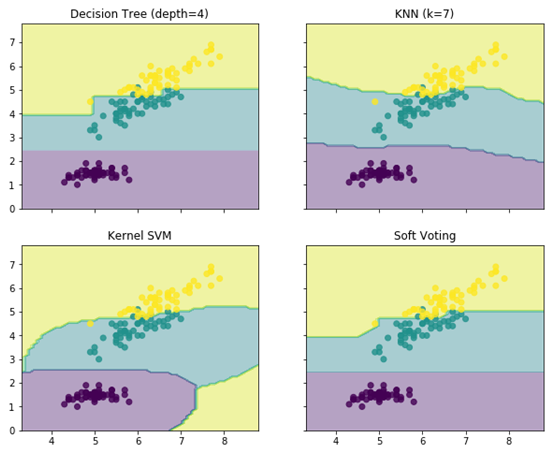
下面例子为线性SVM,决策树,K邻近分类器:
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from itertools import product
from sklearn.ensemble import VotingClassifier
#Loading some example data
iris = datasets.load_iris()
X = iris.data[:, [0,2]]
y = iris.target
#Training classifiers
clf1 = DecisionTreeClassifier(max_depth=4)
clf2 = KNeighborsClassifier(n_neighbors=7)
clf3 = SVC(kernel='rbf', probability=True)
eclf = VotingClassifier(estimators=[('dt', clf1), ('knn', clf2), ('svc', clf3)], voting='soft', weights=[2,1,2])
clf1 = clf1.fit(X,y)
clf2 = clf2.fit(X,y)
clf3 = clf3.fit(X,y)
eclf = eclf.fit(X,y)
##这些分类器分类结果
x_min,x_max = X[:,0].min()-1,X[:,0].max()+1
y_min,y_max = X[:,1].min()-1,X[:,1].max()+1
xx,yy = np.meshgrid(np.arange(x_min,x_max,0.1),
np.arange(y_min,y_max,0.1))
f, axarr = plt.subplots(2, 2, sharex='col', sharey='row', figsize=(10, 8))
for idx, clf, tt in zip(product([0, 1], [0, 1]),
[clf1, clf2, clf3, eclf],
['Decision Tree (depth=4)', 'KNN (k=7)',
'Kernel SVM', 'Soft Voting']):
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx[0], idx[1]].contourf(xx, yy, Z, alpha=0.4)
axarr[idx[0], idx[1]].scatter(X[:, 0], X[:, 1], c=y, alpha=0.8)
axarr[idx[0], idx[1]].set_title(tt)
plt.show()
7.3自适应分类器(Adaboost)
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。使用adaboost分类器可以排除一些不必要的训练数据特征,并放在关键的训练数据上面。
下面的例子展示了AdaBoost算法拟合100个弱学习器
from sklearn.datasets import load_iris
from sklearn.ensemble import AdaBoostClassifier
iris = load_iris()
clf = AdaBoostClassifier(n_estimators=100)
scores = cross_val_score(clf, iris.data, iris.target)
scores.mean()
输出结果为:
0.95996732026143794
实现原理:
1、假设我们有如下样本图:
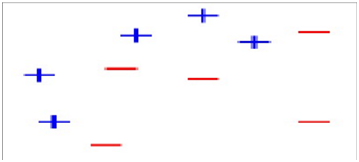
2、第一次分类
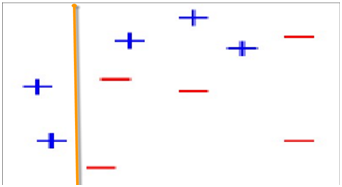
第2次分类
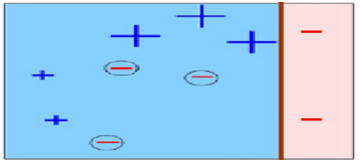
第3次分类
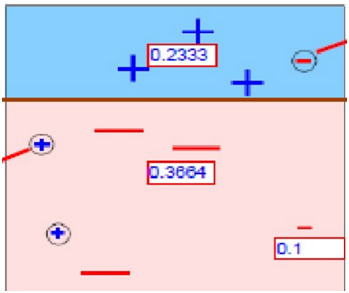
第4次综合以上分类
Pingback引用通告: Python与人工智能 – 飞谷云人工智能
阅读博客获得的进步不亚于阅读一本书。