月度归档:2022年09月
第2章 变量和数据类型
2.1 问题:Python是如何定义变量?
Python最核心理念是:简单好用,少用一个单词就少一份风险!这一理念在Python中处处都有体现。
(1)Java定义变量
|
1 2 3 |
int age=10; float salary=3.13; String name="Python"; |
(2)Python定义变量
|
1 2 3 |
age=10 salary=3.13 name="Python" |
Python无需指明变量类型,也无需用分号结束。
以上是Python理念在定义变量上的一个体现,后续还将介绍Python在逻辑结构方面的独特语法。
2.2 变量
变量是Python最重要的概念之一,变量可以保存任何数,也可修改它的值。
2.2.1 给变量赋值
Python中的变量不需要声明其类型,直接使用=(等号)即可,等号是赋值运算符,例如:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#给变量a赋值 a=10 #打印变量a的值 print(a) #结果为10 #给变量b赋值 b="python" #修改变量a的值 a=10.2 #对变量a乘以一个数 a*100 #打印变量a,b的值 print(a) #结果为10.2 print(b) #结果为python |
2.2.2变量的命名规则
变量名必须遵循以下几条规则:
(1)变量名只能包含字母、数字和下划线(_),不能使用空格,不能以数字开头。
(2)变量名区分大小写,a和A是两个变量。
(3)不能以Python的关键字(如if、while、for、and等)、内置函数(如abs、int、len等)做变量名,如果用这些做变量名将导致错误。
表2-1 合法和非法的变量名
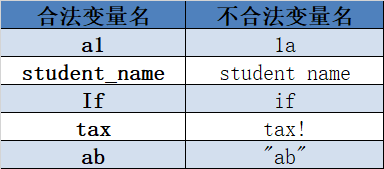
if=10 #将报错SyntaxError: invalid syntax
2.2.3多重赋值
一般一次给一个变量赋值,Python也可一次给多个变量赋值。
|
1 2 3 4 5 6 |
x,y,z=10,"python_numpy",100.0 #打印这3个变量 print(x,y,z) #打印结果 10 python_numpy 100.0 #一次显示多个值,其结果是以元组的形式显示 x,y,z #结果为(10, 'python_numpy', 100.0) |
2.3 字符串
字符串是一系列字符,字符包括字母、数字、标点符号及其他可打印或不可打印的字符。
2.3.1 字符串的多种表示
可以使用三种方式来表示字符串,单引号、双引号、三引号(切记,这些引号都是指英文格式的,如果用中文格式将报错!),单引号与双引号作用相似。不过,有些情况用单引号就不合适,有些用双引号不好表示或表示比较麻烦的,用三引号却迎刃而解。
(1)单引号
如'ok!','I like Python','house'
如果字符串中有',如let's go等,如果把这句话用单引号表示,'let's go',将报错。这时就需要使用双引号表示。
(2)双引号
let's go用双引号表示就没问题,"let's go"。当然,一般用单引号表示,也可用双引号表示,如"ok!","house"等。
如果我们希望表示windows下的路径,该如何表示呢?比如表示路径:C:\Users\lenovo\logs,我们首先想到的可能" C:\Users\lenovo\logs",这个表示是否正确?
我们运行以下语句
|
1 |
path="C:\Users\wumg\jupyter-ipynb\logs" |
结果报错一个SyntaxError错误。错误的原因就是这个字符串中含有一个特殊字符“\”
遇到一些特殊字符(如\,'),Python与C、Java一样,可以在这些特殊字符前加反斜杠($$即可,紧跟\后面的这个字符就成了一般字符。把字符串" C:\Users\lenovo\logs"改为:
" C:\\Users\\wumg\\jupyter-ipynb\\logs "后,第2个\就变成一般字符了。
|
1 2 |
path="C:\\Users\\wumg\\jupyter-ipynb\\logs" print(path) #打印结果为C:\Users\lenovo\logs |
【说明】或改成如下形式也可,效果一样。
|
1 2 |
path=r"C:\Users\wumg\jupyter-ipynb\logs" print(path) |
(3)三引号
三引号(''' a ''',或"""a""")除了具有一般双引号、单引号功能外,还有一些特殊用法,
如表示多行
|
1 2 |
lines='''I like Python, I also like Pytorch! ''' |
此外,还经常用在对一些函数、类的功能注释,及函数或类等帮助信息上。Python的每个对象都有一个属性__doc__,这个属性的内容就用于描述该对象的作用,这些描述都放在三引号内。如:
|
1 2 3 4 5 6 7 8 |
#定义一个函数 def fun01(): '''这是一个测试三引号的函数''' a="Python是人工智能的首先语言!" print(a) #查看对象fun01的__doc__属性,或功能说明 print(fun01.__doc__) #打印结果为:这是一个测试三引号的函数 |
【练习】
打印let's go 这句话。
2.3.2 字符串的长度
统计一个字符串的长度或元素个数,是经常遇到的问题,如何计算字符串的长度?很简单,只要用Python的内置函数len即可(可以使用命令dir(__builtins__)来查看Python的内置函数清单)。如:
|
1 2 3 4 5 |
a="I line Python" print(len(a)) #结果为13 ,其中有两个空格 b="Python是人工智能的首先语言!" print(len(b)) #结果为17,表示元素个数,一个汉字或一个字符都是元素之一 print(len("")) #结果为0,表示空字符 |
2.3.3 拼接字符串
可以使用加号(+)来拼接或合并字符串,比如:
|
1 2 3 4 5 6 |
#拼接两个字符串,中间用空格隔开 "hellow"+" "+"world!" #结果为 'hellow world!' #对同一字符拼接多次 3*"ok" #结果为:'okokok' #拼接后的字符串作为另一个字符串 len('Python'+"3.7") #结果为9 |
【注意】如果把"3.7"改为:3.7,情况将如何?
2.3.4 字符串常用方法
对字符串有一些常用方法,如删除空白、转变字符串大小写等,比如:
(1)删除空格
删除字符串中,首尾多余空格,可以使用rstrip()、lstrip()、strip()等函数。
|
1 2 3 4 5 6 7 |
str1=" I like Python " #删除末尾空格 str1.rstrip() #结果为:' I like Python' #删除开头空格 str1.lstrip() #结果为:'I like Python ' #删除首尾空格 str1.strip() #结果为:'I like Python' |
(2)修改大小写
修改字符串中字母的大小写,可以使用lower()、upper()等。
|
1 2 3 4 5 6 7 8 |
#把删除首尾空格后的字符串赋给另一个变量 str2=str1.strip() #把字符串改为小写 print(str2.lower()) #结果:'i like python' #把字符串改为大写 print(str2.upper()) #结果:'I LIKE PYTHON' #每个单词的首字母,变为大写 print(str2.title()) #结果:'I Like Python' |
(3)分割单词
可以把字符串按指定字符分割,缺省是按空格分割。
|
1 2 3 4 5 |
#以空格分割字符串 str2.split() #运行结果:['I', 'like', 'Python'] #以竖线分割字符串 str3="python|java|keras|pytorch|tensorflow" str3.split('|') #运行结果:['python', 'java', 'keras', 'pytorch', 'tensorflow'] |
【练习】
统计这句话的单词数:str1="NumPy is the fundamental package for scientific computing with Python. NumPy can also be used as an efficient multi-dimensional container of generic data"
2.3.5 输出到屏幕
Python3使用print()函数把数据打印在屏幕上,打印内容必须放在括号()内。如果是Python2版本的,打印内容无需放在括号内。print可以打印任何数据,且打印还可以按指定格式打印。print有两种格式化输出:一种是str%,另一种是str.format
(1)print函数的格式
|
1 |
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False) |
其中
value: 打印的值,可多个
file: 输出流,默认是 sys.stdout
sep: 多个值之间的分隔符
end: 结束符,默认是换行符 \n
flush: 是否强制刷新到输出流,默认否
(2)打印字符串
|
1 2 3 |
#打印字符串 print("Python") print("Pytorch") |
Python
Pytorch
(3)不换行打印
默认情况下,print打印完内容后添加一个换行符:\n,即打印后光标移动下一行。要是内容打印在同一行,可以加上参数end=',',说明把结束符改为逗号。例如:
|
1 2 3 |
#在同一行打印字符串 print("Python",end=',') print("Pytorch") |
打印结果
Python,Pytorch
(4)格式打印,传统方法print(str%())
|
1 2 3 |
a=7.8420 b=6.7890 print("今年国庆出游人数:%.2f 亿,去年国庆出游人数:%.0f"%(a,b)) |
运行结果
今年国庆出游人数:7.84 亿,去年国庆出游人数:7
(5)format格式,print(str.format())
|
1 |
print("今年国庆出游人数:{:.2f},去年国庆出游人数:{:.0f}".format(a,b)) |
带编号
|
1 |
print("去年国庆出游人数:{1},今年国庆出游人数:{0}".format(a,b)) |
带编号及格式
|
1 |
print("去年国庆出游人数:{1:.2f},今年国庆出游人数:{0:.0f}".format(a,b)) |
2.4 数字与运算符
Python3的数字类型包括整型、浮点型、布尔型等,声明变量时无需说明数字类型。由Python内置的基本数据类型管理变量,在程序的后台负责数值与类型的关联,以及类型的转换等操作。
运算符是对数字的操作,包括算术运算符、关系运算符和逻辑运算符等,以下是具体运算符及实例。
2.4.1 算术运算符
表2-2 算术运算符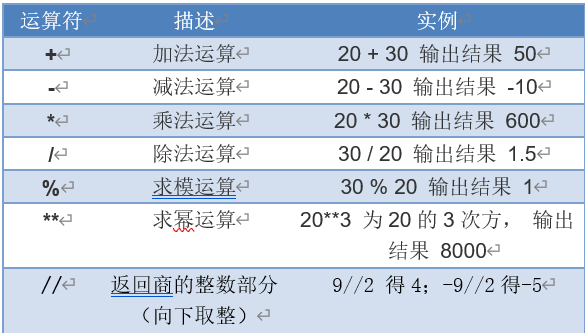
2.4.2 关系运算符
表2-3 关系运算符,(假设a=2,b=3)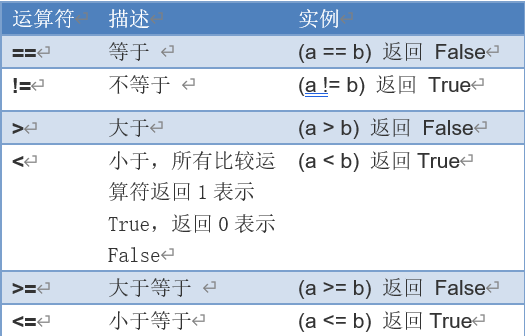
2.4.3 逻辑运算符
表2-4 逻辑算法符

2.4.4 赋值运算符
表2-5 赋值运算符
2.5数据类型转换
转换数据类型是经常遇到的问题,如"python"+3将报错。因3是整数,不是字符串,故不能相加。若要相加,需要先把3转换为字符型。实现类型转换,Python提供了很多内置函数,接下来我们将介绍这些内置函数。
2.5.1 将整数和浮点数转换为字符串
函数str(x)将数x转换为字符串,例如:
|
1 2 |
"Python "+str(3) #结果:'Python 3' "TensorFlow "+str(2.1) #结果:'TensorFlow 2.1' |
2.5.2 把整数转换为浮点数
把整数转换为浮点数,可以使用float(x)函数,例如:
|
1 2 3 4 |
#显式转换 float(10) #结果: 10.0 #隐式转换,Python自动先将10转换为10.0,然后再与0.1相加 10+0.1 #结果:10.1 |
2.5.3 把浮点数转换为整数
把浮点数转换为整数,情况比较复杂,涉及如何对待小数部分。如果只是简单的想去掉小数部分,可以使用int(x)函数即可;如果需要考虑向下取整或向上取整,就需要使用round(x)。另外Python的math模块也提供了很多函数,如math.ceil(x)、math.trunc(x)等,以下通过实例来说明。
(1)直接删除小数部分,可以int(x)函数。
|
1 2 |
int(4.52) #结果:4 int(-10.89) #结果:-10 |
(2)使用round(x),一般采用四舍五入的规则,但如果x小数部分为.5时,将取x最接近的偶数。
|
1 2 3 4 5 6 |
#使用四舍五入规则 round(7.7) #结果:8 round(7.4) #结果:7 #round(x)中x为.5时,取x最接近的偶数 round(6.5) #结果:6 round(-9.5) #结果:-10 |
2.5.4 把字符串转换为数字
把字符串转换为数字比较简单,使用内置函数int(x)或float(x)即可,例如:
|
1 2 3 |
int('3') #结果:3 float("10.35") #结果:10.35 float("-9.8") #结果:-9.8 |
2.5.5 使用input函数
input()函数用于接收用户的输入,它的返回值是字符串,其格式为:
|
1 |
input('提示符') |
input()函数使用实例
(1)输入一个字符串
|
1 2 3 4 5 6 7 |
#输入一个字符串,显示该字符串的长度 a=input("输入一个字符串:") #打印该字符串的长度 print(len(a)) #运行结果如下############# 输入一个字符串:python 6 |
【练习】输入两个整数,打印它们的和。
2.6 注释
注释用于说明代码的功能、使用的算法、注意事项等等。代码越复杂,注释就越重要,否则,将给后续代码维护、分享带来极大不便。
注释很简单,只要在需要说明的语句前加上#号即可。Python编译器,遇到带#号的行将忽略。
注释的文字,可以是英文或中文等,注释尽量做到言简意赅。以下为一段代码的注释。
|
1 2 3 4 5 6 7 8 9 10 11 |
################################ #创建时间:2019年8月15日 #修改时间:2019年9月10日 #修改人:张云飞 #代码主要功能:****** ################################# ‘’’ #初始化参数 lr=0.001 #学习率参数 batch_size=64 #批量大小 n=100 #迭代次数 |
2.7 练习
(1)用input函数输入任意两个数字,打印它们的平方和。
(2)把(1)写成一个脚本,然后,在命令行或Jupyer notebook上执行这个脚本。
第1章 Python安装配置
1.1 问题:Python能带来哪些优势?
我们认为主要有以下原因。
(1)简单易学
(2)简单高效
(3)生态完备
Python的生态非常完备,目前已广泛应用于人工智能、云计算开发、大数据开发、数据分析、科学运算、网站开发、爬虫、自动化运维、自动化测试、游戏开发等领域,而且领域在成千上万的无私奉献者努力下,还在不断开疆拓土。
1.2安装Python
Python使用平台包括Linux、macOS以及Windows,其编写的代码在不同平台上运行时,几乎不需要做较大的改动,非常方便。在各平台上的安装和配置也很简单,Python的安装方法有很多,本书建议使用Aanaconda这个发行版。该发现版包括Conda, NumPy, Scipy, Ipython Notebook、Matplotlib等超过180个科学包及其依赖项,大小约600M左右。
1.2.1在Linux系统上安装
在Linux环境下安装Python,具体步骤如下:
(1)下载Python
安装Python建议采用Anaconda方式安装,先从Anaconda的官网:https://www.anaconda.com/distribution, 如图1-1 所示。
图1-1 下载Anaconda界面
下载Anaconda3的最新版本,如Anaconda3-5.0.1-Linux-x86_64.sh,建议使用3系列,3系列代表未来发展。另外,下载时根据自己环境,选择操作系统等。
(2)在命令行,执行如下命令,开始安装Python。
把下载的这个sh文件放在某个目录下(如用户当前目录),然后执行如下命令。
|
1 |
Anaconda3-2019.03-Linux-x86_64.sh |
(3)根据安装提示,按回车即可。其间会提示选择安装路径,如果没有特殊要求,可以按回车使用默认路径(~/ anaconda3),然后就开始安装。
(4)安装完成后,程序提示我们是否把anaconda3的binary路径加入到当前用户的.bashrc配置文件中,建议添加。添加后就可以在任意目录下执行python、ipython命令。
(5)验证安装
安装完成后,运行Python命令,看是否成功,如果不报错,说明安装成功。退出Python编译环境,执行exit()即可。
(6)安装第三方包
|
1 2 3 |
conda install 第三方包名称#如 conda install tensorflow #或者采用pip安装 pip install 第三方包名称#如 pip install tensorflow |
(7)卸载第三方包
|
1 2 3 |
conda remove 第三方包名称#如 conda remove tensorflow #或者采用pip安装 pip uninstall 第三方包名称#如 pip uninstall tensorflow |
(8)查看已安装包
|
1 |
conda list |
1.2.2在Windows系统上安装
在windows下安装与Linux环境下安装类似,不同之处:
(1)选择windows操作系统
(2)下载的文件名称不是sh文件,而是一个exe文件,如:
Anaconda3-2021.05-Windows-x86_64
(3)安装时,双击这个执行文件,后续步骤与Linux环境安装类似。
1.2.3 在macOS系统上安装
在mac OS下安装与Linux环境下安装类似,不同之处:
(1)选择mac OS操作系统
(2)下载的文件名称不是sh文件,而是一个pkg文件,如:
Anaconda3-2019.03-MacOSX-x86_64.pkg
(3)安装时,双击这个pkg文件,后续步骤与Linux环境安装类似。
1.3 配置开发环境
Python开发环境的配置比较简单,Python可以在Windows、Linux、macOS等环境开发。
1.3.1 自带开发环境IDLE
在安装Python后,将自动安装一个IDLE(在安装目录的Scripts目录下),它是Python软件包自带的一个集成开发环境,它是一个Python shell,是入门级的开发环境,程序员可以利用它创建、运行、调试Python程序。运行Python程序有两种方式,交互式和文件式,交互式指Python解释器即时响应用户输入的每条代码,立即给出结果。文件式指用户将python程序写在一个或多个文件中, 然后启动Python解释器批量执行文件中的代码。交互式般用于调试少量代码,文件式则是最常用的编程方式。windows下使用IDLE步骤如下:
(1)找到idle.bat文件,双击该文件,进入交互式编辑界面,如图1-2所示:
图1-2 IDLE界面
(2)运行Python语句
图1-3 交互式运行Python语句
(3)文件式界面
打开IDLE,按快捷键Ctrl+N打开一个新窗口,或在菜单中选择File- +New File选项。这个新窗口不是交互模式,它是一个具备Python语法高亮辅助的编辑器,可以进行代码编辑。在其中输入Python代码,例如,输入Hello World程序并保存为hello.py文件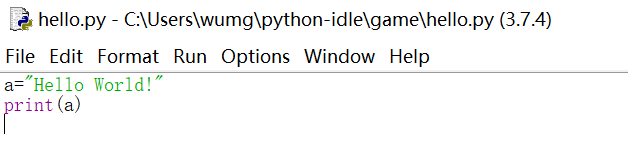
图1-4 编写一个简单Python代码
(4)运行脚本
按快捷键F5,或在菜单中选择Run->RunModule选项运行该文件,在IDLE交互界面输出图1-5的结果。
图1-5 运行结果
1.3.2 安装配置Pycharm
PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具。PyCharm在敲代码时会有纠错,提示的功能,用起来非常方便,比较适合开发Python项目。
1.3.3 Linux下配置Jupyter book
Jupyter Notebook非常好用,配置也简单,主要步骤如下。
(1)生成配置文件
|
1 |
jupyter notebook --generate-config |
将在当前用户目录下生成文件:.jupyter/jupyter_notebook_config.py
(2)生成当前用户登录jupyter密码
打开Ipython, 创建一个密文密码
|
1 2 3 4 |
In [1]: from notebook.auth import passwd In [2]: passwd() Enter password: Verify password: |
(3)修改配置文件
vim ~/.jupyter/jupyter_notebook_config.py
进行如下修改:
c.NotebookApp.ip='*' # 就是设置所有ip皆可访问
c.NotebookApp.password = u'sha:ce...刚才复制的那个密文'
c.NotebookApp.open_browser = False # 禁止自动打开浏览器
c.NotebookApp.port =8888 #这是缺省端口,也可指定其他端口
(4)启动Jupyter notebook
|
1 2 |
#后台启动jupyter:不记日志: nohup jupyter notebook >/dev/null 2>&1 & |
在浏览器上,输入IP:port,即可看到图1-6所示的界面。
图1-6 登录Jupyter的界面
接下来就可以在浏览器进行开发调试Pytorch、Python等任务了。
1.3.4 Windows下配置Jupyter book
(1)生成配置文件
在cmd或Anaconda Prompt 下运行以下命令:
jupyter notebook --generate-config
将在当前用户目录下生成文件:.jupyter/jupyter_notebook_config.py
(2)打开文件jupyter_notebook_config.py,找到含有
#c.NotebookApp.notebook_dir=' '的行
把该行改为:
c.NotebookApp.notebook_dir ='D:\python-script\py'
这里假设希望在'D:\python-script\py' 目录下启动jupyter notebook,并在这个目录自动生成ipyb文件。当然,这个目录可以根据实际环境进行修改。
(3)找到jupyer notebook命令的快捷方式,点击右键,进人属性页面,如下图1-7所示: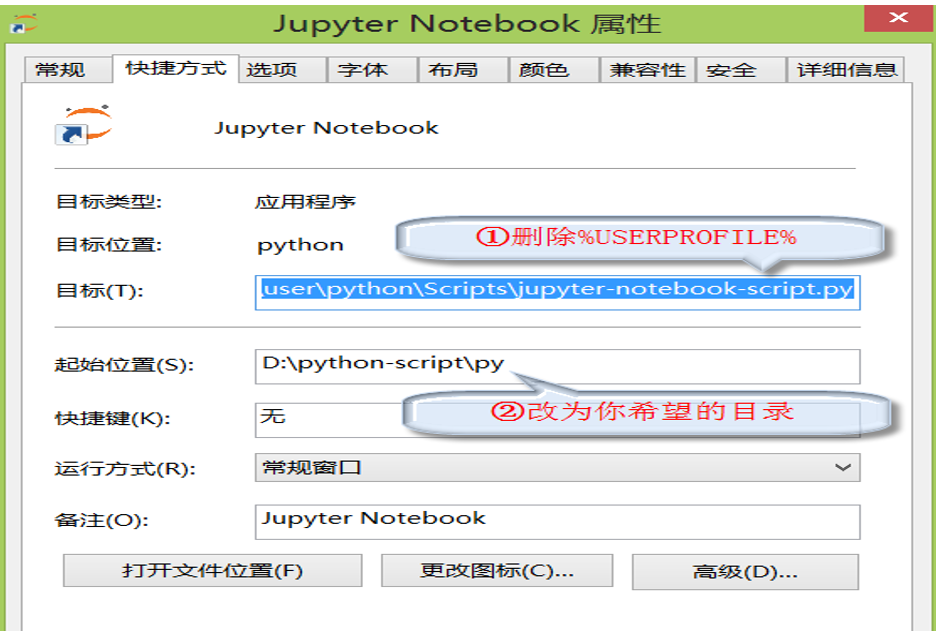
图1-7 修改Jupyter Notebook启动目录界面
(4)最后,启动Jupyter Notebook之后,自动弹出一个网页(网址为:localhost:8888),点击其中的new下拉菜单,选择pyhton3,就可进行编写代码、运行代码。
1.4 试运行Python
以Windows环境为例(对Linux中使用shell而不是windows的dos命令)。
(1)如何执行cell中的代码
同时按Shift键和Enter键即可。以下为代码示例。
|
1 2 3 |
a="python" b=10.2829 print("开发语言为:{0:s},b显示小数点后两位的结果:{1:.2f}".format(a,b)) |
运行结果
开发语言:python
|
1 2 3 4 5 6 7 8 9 |
#定义一个函数 '''这是一个测试脚本''' def fun01(): name="北京2022冬奥会欢迎您!" print(name) #运行函数 if __name__=='__main__': fun01() |
(3)导入该脚本(或模块),并查看该模块的功能简介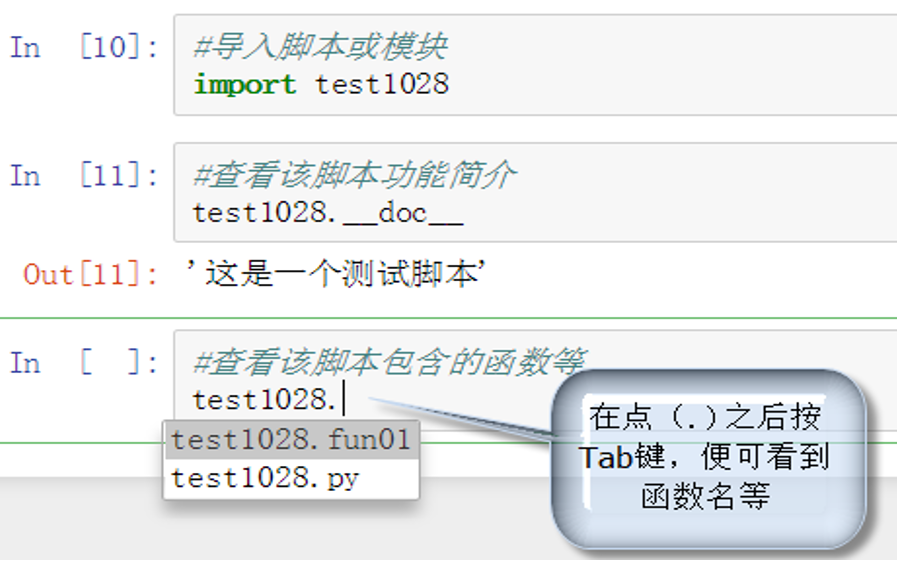
图1-8 运行Python命令
(4)执行Python脚本
图1-9 运行Python脚本
【说明】
①为了使该脚本有更好的移植性,可在第一行加上一句#!/usr/bin/python
②运行.py文件时,python自动创建相应的.pyc文件,.pyc文件包含目标代码(编译后的代码),它是一种python专用的语言,以计算机能够高效运行的方式表示的python源代码。这种代码无法阅读,故可以不管这个文件。
(5)修改文件名称
Jupyter的文件自动保存,名称也是自动生成的,对自动生成的文件名称,我们也可重命名,具体步骤如下;
点击目前文件名称:
图1-10 修改文件名称
然后重命名,并点击rename即可,具体可参考下图:
图1-11 点击修改名称按钮
(6)画图
以下是画一条抛物线的代码,在Jupyter显示图形,需要加上一句:%matplotlib inline,具体代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import numpy as np import matplotlib.pyplot as plt %matplotlib inline #生成x的值 x=np.array([-3,-2,-1,0,1,2,3]) #得到y的值 y=x**2+1 ##绘制一个图,长为6,宽为4(默认值是每个单位80像素) plt.figure(figsize=(6,4)) ###可视化x,y数据 plt.plot(x,y) plt.show() |
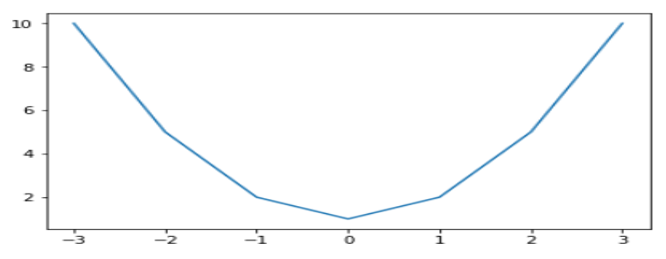
图1-12显示图像
(7)查看帮助信息
在Jupyter 里查看函数、模块的帮助信息也很方便。
在函数或模块后加点(.) 然后按tab键 可查看所有的函数。
在函数或模块后加问号(?) 回车,可查看对应命令的帮助信息。
|
1 2 |
import numpy as np a1=np.array([1,2,6,4,1]) |
查看a1数组,可以使用的函数
图1-13 显示可以的函数
要查看argmax函数的具体使用方法,只要在函数后加上一个问号(?),然后运行,就会弹出一个详细帮助信息的界面,具体可参考图1-14: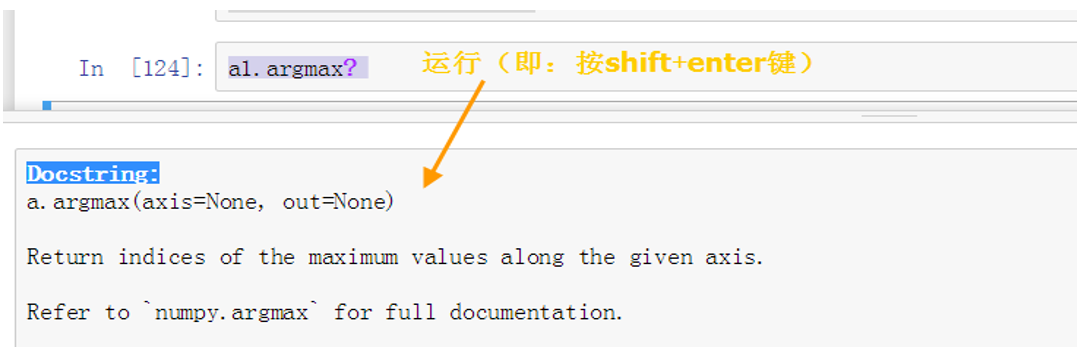
图1-14 显示帮助信息
1.5 练习
(1)尝试写一个py脚本,输出你的姓名,分别在命令行和Jupyter notebook上运行。
(2)尝试在Jupyter notebook中,查看print命令的使用方法。
线性代数
机器学习、深度学习的基础除了编程语言外,还有一个就是应用数学。它一般包括线性代数、概率与信息论、概率图、数值计算与最优化等。其中线性代数又是基础的基础。线性代数是数学的一个重要分支,广泛应用于科学和工程领域。大数据、人工智能的源数据在模型训练前,都需要转换为向量或矩阵,而这些运算正是线性代数的主要内容。
如在深度学习的图像处理中,如果1张图由28*28像素点构成,那这28*28就是一个矩阵。在深度学习的神经网络中,权重一般都是矩阵,我们经常把权重矩阵W与输入X相乘,输入X一般是向量,这就涉及矩阵与向量相乘的问题。诸如此类,向量或矩阵之间的运算在深度学习中非常普遍,也非常重要。
本章主要介绍如下内容:
- 自动求解线性方程组
- 标量、向量、矩阵和张量
- 矩阵和向量运算
- 特殊矩阵与向量
- 特征值分解
- 奇异值分解
- 迹运算
- 实例
第1章 线性代数基础
1.1自动求解线性方程组
假设有如下线性方程组:

这个线性方程组,如果用高中知识,手工很快能求得结果。如何用Python实现该方程组的自动求解呢?要实现Python求解,先要解决哪些问题?
要用Python处理这个问题,首先,需要用Python的方式表示这个方程组。
用矩阵、向量的方式表示这个线性方程组,如图2-1所示:
图2-1 用矩阵表示方程组
要使用Python实现式(2.1)的求解,首先需要把式(2.1)用矩阵和向量的方式表示,然后利用相关线性代数相关知识进行求解。具体步骤如下:
1)用矩阵、向量表示式(2.1)或图2-1中关系。
假设系数矩阵为A,变量构成的向量为X,右边的值构成的向量为B,则他们之间的关系,可用下式表示:
AX=B (2.2)
其中A与X是点积(dot)的关系。
2)用NumPy表示矩阵、向量。
|
1 2 |
A=np.array([[1,1,1],[0,2,5],[2,5,-1]]) B=np.array([6,-4,27]) |
3) 因行列式|A|≠0(可计算:np.linalg.det(A) ≠0),由此可知,矩阵A可逆,
即存在A的可逆矩阵 ,使得
,使得 (单位矩阵),对式(2.2)两边同时乘以矩阵
(单位矩阵),对式(2.2)两边同时乘以矩阵 ,可得:
,可得:

即
由此可得:
4)求线性方程组的解
A的逆矩阵(用A1表示)可表示为:
|
1 |
A1=np.linalg.inv(A) |
所以
|
1 |
X=np.dot(A1,B) |
可得线性方程组的解为:
array([ 5., 3., -2.])
1.2标量、向量、矩阵和张量
在机器学习、深度学习中,首先遇到的就是数据,如果按类别来划分,我们通常会遇到以下4种类型的数据。
1.2.1 标量(scalar)
一个标量就是一个单独的数,一般用小写的变量名称表示,如a,x等。
1.2.2 向量(vector)
向量就是一列数或一个一维数组,这些数是有序排列的。通过次序中的索引,我们可以确定向量中每个单独的数。通常我们赋予向量粗体的小写变量名称,如x、y等。一个向量一般有很多元素,这些元素如何表示?我们一般通过带脚标的斜体表示,如 表示向量x中的第一个元素,
表示向量x中的第一个元素, 表示第二元素,依次类推。向量元素的个数称为向量的维数。
表示第二元素,依次类推。向量元素的个数称为向量的维数。
当需要明确表示向量中的元素时,我们一般将元素排列成一个方括号包围的一行,如下式:
![X=[ x_1,x_2,\ldots,x_n] \tag {2.3}](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_f3faacff1adc5bae86068b573ec11d67.gif)
X称为行向量。
X也可表示为列向量:
![\left[\begin{matrix} x_1\cr x_2 \cr\vdots \cr x_n\end{matrix}\right]\tag{2.4}](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_607faf3f0ef417e04b5be7fcc630a1ea.gif)
我们可以把向量看作空间中的点,每个元素是不同的坐标轴上的坐标。
向量可以这样表示,那我们如何用编程语言如python来实现呢?如何表示一个向量?如何获取向量中每个元素呢?请看如下实例:
|
1 2 3 4 5 |
import numpy as np a=np.array([1,2,4,3,8]) print(a.size) print(a[0],a[1],a[2],a[-1]) |
打印结果如下:
5
1 2 4 8
这说明向量元素个数为5,向量中索引一般从0开始,如a[0]表示第一个元素1,a[1]
表示第二个元素2,a[2]表示第三个元素4,依次类推。这是从左到右的排列顺序,如果从右到左,我们可用负数来表示,如a[-1]表示第1个元素(注:从右到左),a[-2]表示第2个元素,依次类推。
1.2.3 矩阵(matrix)
矩阵是二维数组,其中的每一个元素被两个索引而非一个所确定。我们通常会赋予矩阵粗体的大写变量名称,比如A。如果一个实数矩阵高度为m,宽度为n,那么我们说 。
。
与向量类似,可以通过给定行和列的下标表示矩阵中元素,下标用逗号分隔,如 表示A左上的元素,
表示A左上的元素, 表示第一行第二列对应的元素,依次类推;这是表示单个元素,如果我们想表示1列或1行,该如何表示呢?我们可以引入冒号":"来表示,如第1行,可用A1,:表示,第2行,用A2,:表示,第1列用A:,1表示,第n列用A:,n表示。
表示第一行第二列对应的元素,依次类推;这是表示单个元素,如果我们想表示1列或1行,该如何表示呢?我们可以引入冒号":"来表示,如第1行,可用A1,:表示,第2行,用A2,:表示,第1列用A:,1表示,第n列用A:,n表示。
如何用Python来表示或创建矩阵呢?如果希望获取其中某个元素,该如何实现呢?请看如下实例:
|
1 2 3 4 5 6 7 8 |
import numpy as np A=np.array([[1,2,3],[4,5,6]]) print(A) print(A.size) #显示矩阵元素总个数 print(A.shape) #显示矩阵现状,即行行和列数。 print(A[0,0],A[0,1],A[1,1]) print(A[1,:]) #打印矩阵第2行 |
打印结果:
[[1 2 3]
[4 5 6]]
6
(2, 3)
1 2 5
[4 5 6]
矩阵可以用嵌套向量生成,和向量一样,在Numpy中,矩阵元素的下标索引也是从0开始的。
1.2.4张量(tensor)
几何代数中定义的张量是向量和矩阵的推广或更通用的称呼,我们可以将标量视为零阶张量,向量视为一阶张量,那么矩阵就是二阶张量,三阶的就称为三阶张量,以此类推。在机器学习、深度学习中经常遇到多维矩阵,如一张彩色图片就是一个三阶张量,三个维度分别是图片的高度、宽度和色彩数据。
张量(tensor)也是深度学习框架TensorFlow、PyTorch的重要概念。TensorFlow由tensor(张量)+flow(流)构成。
同样我们可以用Python来生成张量及获取其中某个元素或部分元素,请看实例:
|
1 2 3 4 5 6 |
B=np.arange(16).reshape((2, 2, 4)) #生成一个3阶矩阵 print(B) print(B.size) #显示矩阵元素总数 print(B.shape) #显示矩阵的维度 print(B[0,0,0],B[0,0,1],B[0,1,1]) print(B[0,1,:]) |
打印结果如下:
[[[ 0 1 2 3]
[ 4 5 6 7]]
[[ 8 9 10 11]
[12 13 14 15]]]
16
(2, 2, 4)
0 1 5
[4 5 6 7]
第1章 NumPy基础
为何第1章介绍NumPy基础?在机器学习和深度学习中,图像、声音、文本等首先要数字化,如何实现数字化?数字化后如何处理?这些都涉及NumPy。NumPy是数据科学的通用语言,它是科学计算、矩阵运算、深度学习的基石。PyTorch中的重要概念张量(Tensor)与NumPy非常相似,它们之间可以方便地进行转换,掌握NumPy是学好PyTorch的重要基础,故我们把它列为全书第1章。
基于NumPy的运算有哪些优势?实际上Python本身含有列表(list)和数组(array),但对于大数据来说,这些结构有很多不足。因列表的元素可以是任何对象,因此列表中所保存的是对象的指针。例如为了保存一个简单的[1,2,3],都需要有3个指针和三个整数对象。对于数值运算来说这种结构显然比较浪费内存和CPU等宝贵资源。 至于array对象,它直接保存数值,和C语言的一维数组比较类似。但是由于它不支持多维,建立在上面的函数也不多,因此也不适合做数值运算。
NumPy(Numerical Python 的简称)的诞生弥补了这些不足,NumPy提供了两种基本的对象:ndarray(N-dimensional array object)和 ufunc(universal function object)。ndarray是存储单一数据类型的多维数组,而ufunc则为数组进行和处理提供了丰富的函数。
NumPy的主要特点:
1) ndarray,快速和节省空间的多维数组,提供数组化的算术运算和高级的广播功能。
2) 使用标准数学函数对整个数组的数据进行快速运算,而不需要编写循环。
3) 读取/写入磁盘上的阵列数据和操作存储器映像文件的工具。
4) 线性代数,随机数生成,和傅里叶变换的能力。
5) 集成C,C++,Fortran代码的工具。
本章主要内容如下:
♦ 把图像数字化
♦ 存取元素
♦ NumPy的算术运算
♦ 数组变形
♦ 批量处理
♦ 节省内存
♦ 通用函数
♦ 广播机制
1.1生成NumPy数组
NumPy是Python的第三方库,若要使用它,需要先导入NumPy。
|
1 |
import numpy as np |
导入NumPy后,可通过np.+Tab键查看可使用的函数,如图1-1所示。如果对其中一些函数的使用不很清楚,想看对应函数的帮助信息,可以在对应函数+?,再运行,就可很方便地看到使用函数的帮助信息。

图1-1 通过np.+Tab键查看可用函数
运行如下命令,便可查看函数abs的详细帮助信息。
|
1 |
np.abs? |
NumPy不但强大,而且非常友好。接下来我们将介绍NumPy的一些常用方法,尤其是与机器学习、深度学习相关的一些内容。
NumPy封装了一个新的数据类型ndarray(n-dimensional array,n维数组),它是一个多维数组对象。该对象封装了许多常用的数学运算函数,方便我们做数据处理、数据分析等。如何生成ndarray呢?这里我们介绍生成ndarray的几种方式,如从已有数据中创建、利用random创建、创建特殊多维数组、使用arange函数等。
机器学习中图像、自然语言、语音等在输入模型之前,都需要数字化。这里我们用cv2把一个汽车图像(如图1-2所示)转换为NumPy多维数组,然后查看该多维数组的基本属性,具体代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#使用OpenCV开源库读取图像数据 import cv2 from matplotlib import pyplot as plt %matplotlib inline # 读取一张照片,把图像转换为2维的numpy数组 img = cv2.imread('../data/car.jpg') #使用plt显示图像 plt.imshow(img) # 显示img的数据类型及大小 print("数据类型:{},形状:{}".format(type(img),img.shape)) |
运行结果如下:
数据类型:<class 'numpy.ndarray'>,形状:(675, 1200, 3)

图1-2 把轿车图像转换为NumPy
1.1.1 数组属性
在NumPy中,维度被称为轴,比如把轿车图像转换为一个NumPy之后的数组是1个三维数组,这个数组中有3个轴,这3个轴的长度分别为675、1200、3。
NumPy的ndarray对象有3个重要的属性。
ndarray.ndim:数组的维度(轴)的个数。
ndarray.shap:数组的维度,值是一个整数元祖,元祖的值代表其所对应的轴的长度。 比如对于二维数组,它用来表达这是个几行几列的矩阵,值为(x, y),其中x代表这个数组中有几行, y代表有几列。
ndarray.dtype:数据类型,描述数组中元素的类型。
比如上面的img数组:
|
1 2 3 |
print("img数组的维度:",img.ndim) #其值为:3 print("img数组的形状:",img.shape) #其值为:(675, 1200, 3) print("img数组的数据类型:",img.dtype) #其值为: uint8 |
为更好地理解ndarray对象的3个重要属性,我们把一维数组、二维数组、三维数组进行可视化,如图1-3所示。

图1-3 多维数组的可视化表示。
1.1.2从已有数据中创建数组
直接对 Python 的基础数据类型(如列表、元组等) 进行转换来生成 ndarray:
1)将列表转换成 ndarray。
|
1 2 3 4 5 6 7 8 |
import numpy as np lst1 = [3.14, 2.17, 0, 1, 2] nd1 =np.array(lst1) print(nd1) # [3.14 2.17 0. 1. 2. ] print(type(nd1)) # <class 'numpy.ndarray'> |
2)嵌套列表可以转换成多维 ndarray。
|
1 2 3 4 5 6 7 8 9 |
import numpy as np lst2 = [[3.14, 2.17, 0, 1, 2], [1, 2, 3, 4, 5]] nd2 =np.array(lst2) print(nd2) # [[3.14 2.17 0. 1. 2. ] # [1. 2. 3. 4. 5. ]] print(type(nd2)) # <class 'numpy.ndarray'> |
如果把上面示例中的列表换成元组,上述方法也同样适合。
1.1.3利用 random 模块生成数组
在深度学习中,我们经常需要对一些参数进行初始化。为了更有效地训练模型,提高模型的性能,有些初始化还需要满足一定条件,如满足正态分布或均匀分布等。这里我们介绍几种常用的方法,表1-1列举了 np.random 模块常用的函数。
1-1 np.random模块常用函数
下面我们来看看这些函数的具体使用方法:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import numpy as np print('生成形状(4, 4),值在0-1之间的随机数:') print(np.random.random((4, 4)), end='\n\n') # 产生一个取值范围在[1, 50)之间的数组,数组的shape是(3, 3) # 参数起始值(low)默认为0, 终止值(high)默认为1。 print('生成形状(3, 3),值在low-high之间的随机整数::') print(np.random.randint(low=1, high=50, size=(3,3)), end='\n\n') print('产生的数组元素是均匀分布的随机数:') print(np.random.uniform(low=1, high=3, size=(3, 3)), end='\n\n') print('生成满足正态分布的形状为(3, 3)的矩阵:') print(np.random.randn(3,3)) |
运行结果如下:
生成形状(4, 4),值在0-1之间的随机数:
[[0.32033334 0.46896779 0.35755437 0.93218211]
[0.83150807 0.34724136 0.38684007 0.80832335]
[0.17085778 0.60505495 0.85251224 0.66465297]
[0.5351041 0.59959828 0.59819534 0.36759263]]
生成形状(3, 3),值在low-high之间的随机整数::
[[29 23 49]
[44 10 30]
[29 20 48]]
产生的数组元素是均匀分布的随机数:
[[2.16986668 1.43805178 2.84650421]
[2.59609848 1.96242833 1.02203859]
[2.64679581 1.30636158 1.42474749]]
生成满足正态分布的形状为(3, 3)的矩阵:
[[-0.26958446 -0.04919047 -0.86747396]
[-0.16477117 0.39098747 1.97640843]
[ 0.73003926 -1.03079529 -0.1624292 ]]
用以上方法生成的随机数是无法重现的,比如调用两次np.random.randn(3, 3), 输出结果一样的概率极低。如果我们想要多次生成同一份数据怎么办?我们可以使用np.random.seed函数设置种子。设置一个种子,然后调用随机函数产生一个数组,如果想要再次得到一个一模一样的数组,只要再次设置同样的种子就可以。
|
1 2 3 4 5 6 7 8 9 10 |
import numpy as np np.random.seed(10) print("按指定随机种子,第1次生成随机数:") print(np.random.randint(1, 5, (2, 2))) # 想要生成同样的数组,必须再次设置相同的种子 np.random.seed(10) print("按相同随机种子,第2次生成的数据:") print(np.random.randint(1, 5, (2, 2))) |
运行结果如下:
按指定随机种子,第1次生成随机数:
[[2 2]
[1 4]]
按相同随机种子,第2次生成的数据:
[[2 2]
[1 4]]
1.1.4创建特定形状的多维数组
在对参数进行初始化时,有时需要生成一些特殊矩阵,如全是0或1的数组或矩阵,这时我们可以利用np.zeros、np.ones、np.diag来实现,如表1-2所示。
表1-2 创建特定形状多维数组的函数
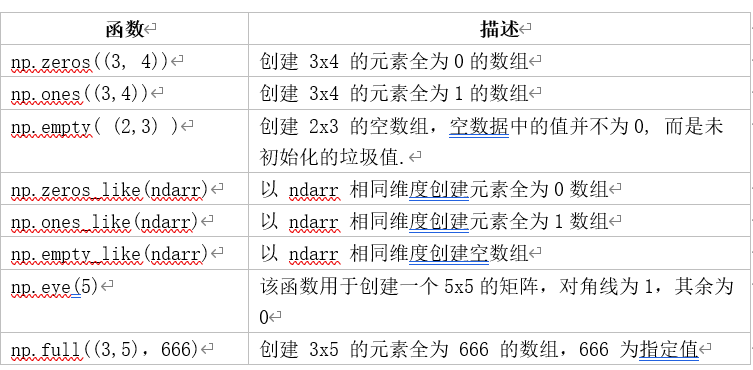
下面我们通过几个示例来说明:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import numpy as np # 生成全是 0 的 3x3 矩阵 nd5 =np.zeros([3, 3]) #生成与nd5形状一样的全0矩阵 #np.zeros_like(nd5) # 生成全是 1 的 3x3 矩阵 nd6 = np.ones([3, 3]) # 生成 3 阶的单位矩阵 nd7 = np.eye(3) # 生成 3 阶对角矩阵 nd8 = np.diag([1, 2, 3]) print("*"*6+"nd5"+"*"*6) print(nd5) print("*"*6+"nd6"+"*"*6) print(nd6) print("*"*6+"nd7"+"*"*6) print(nd7) print("*"*6+"nd8"+"*"*6) print(nd8) |
运行结果如下:
******nd5******
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
******nd6******
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
******nd7******
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
******nd8******
[[1 0 0]
[0 2 0]
[0 0 3]]
有时我们可能需要把生成的数据暂时保存起来,以备后续使用。
|
1 2 3 4 5 6 |
import numpy as np nd9 =np.random.random([5, 5]) np.savetxt(X=nd9, fname='./test1.txt') nd10 = np.loadtxt('./test1.txt') print(nd10) |
运行结果如下:
[[0.41092437 0.5796943 0.13995076 0.40101756 0.62731701]
[0.32415089 0.24475928 0.69475518 0.5939024 0.63179202]
[0.44025718 0.08372648 0.71233018 0.42786349 0.2977805 ]
[0.49208478 0.74029639 0.35772892 0.41720995 0.65472131]
[0.37380143 0.23451288 0.98799529 0.76599595 0.77700444]]
1.1.5利用 arange、linspace 函数生成数组
一些情况下,我们还希望获得一组具有特定规律的数据,这时可以使用NumPy提供的arange、linspace函数实现。
arange 是 numpy 模块中的函数,其格式为:
arange([start,] stop[,step,], dtype=None)
其中start 与 stop 用于指定范围,step 设定步长,生成一个 ndarray,start 默认为 0,步长 step 可为小数。Python中的内置函数range的功能与此类似。
|
1 2 3 4 5 6 7 8 9 10 |
import numpy as np print(np.arange(10)) # [0 1 2 3 4 5 6 7 8 9] print(np.arange(0, 10)) # [0 1 2 3 4 5 6 7 8 9] print(np.arange(1, 4, 0.5)) # [1. 1.5 2. 2.5 3. 3.5] print(np.arange(9, -1, -1)) # [9 8 7 6 5 4 3 2 1 0] |
linspace 也是 numpy 模块中常用的函数,其格式为:
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
它可以根据输入的指定数据范围以及等份数量,自动生成一个线性等分向量,其中endpoint (包含终点)默认为 True,等分数量num默认为 50。如果将retstep设置为 True,则会返回一个带步长的 ndarray。
|
1 2 3 4 5 |
import numpy as np print(np.linspace(0, 1, 10)) #[0. 0.11111111 0.22222222 0.33333333 0.44444444 0.55555556 # 0.66666667 0.77777778 0.88888889 1. ] |
值得一提的是,这里并没有像我们预期的那样,生成 0.1, 0.2, ... 1.0 这样步长为0.1的 ndarray,这是因为 linspace 必定会包含数据起点和终点,那么其步长则为(1-0) / 9 = 0.11111111。如果需要产生 0.1, 0.2, ... 1.0 这样的数据,只需要将数据起点 0 修改为 0.1 即可。
除了上面介绍到的 arange 和 linspace函数,NumPy还提供了 logspace 函数,该函数的使用方法与linspace的使用方法一样,读者不妨自己动手试一下。
1.2读取元素
上节介绍了生成ndarray的几种方法,当生成数据后,如何读取我们需要的数据呢?这节将介绍几种常用的读取数据的方法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import numpy as np np.random.seed(2019) nd11 = np.random.random([10]) #获取指定位置的数据,获取第4个元素 nd11[3] #截取一段数据 nd11[3:6] #截取固定间隔数据 nd11[1:6:2] #倒序取数 nd11[::-2] #截取一个多维数组的一个区域内数据 nd12=np.arange(25).reshape([5,5]) nd12[1:3,1:3] #截取一个多维数组中,数值在一个值域之内的数据 nd12[(nd12>3)&(nd12<10)] #截取多维数组中,指定的行,如读取第2,3行 nd12[[1,2]] #或nd12[1:3,:] ##截取多维数组中,指定的列,如读取第2,3列 nd12[:,1:3] |
如果对上面这些获取方式还不是很清楚,没关系,下面以图形的方式加以说明,如图1-4所示,左边为表达式,右边为表达式获取的元素。注意,不同的边界表示不同的表达式。
0 1 2 3 4
5 6 7 8 9
10 11 12 13 14
15 16 17 18 19
20 21 22 23 24
图1-4 获取多维数组中的元素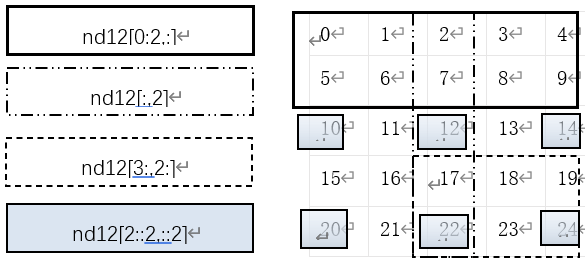
除了可以通过指定索引标签获取数组中的部分元素外,还可以使用一些函数来实现,如可以通过random.choice函数从指定的样本中随机抽取数据。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import numpy as np from numpy import random as nr a=np.arange(1,25,dtype=float) c1=nr.choice(a,size=(3,4)) #size指定输出数组形状 c2=nr.choice(a,size=(3,4),replace=False) #replace默认为True,即可重复抽取。 #下式中参数p指定每个元素对应的抽取概率,默认为每个元素被抽取的概率相同。 c3=nr.choice(a,size=(3,4),p=a / np.sum(a)) print("随机可重复抽取") print(c1) print("随机但不重复抽取") print(c2) print("随机但按制度概率抽取") print(c3) |
运行结果如下:
随机可重复抽取
[[ 7. 22. 19. 21.]
[ 7. 5. 5. 5.]
[ 7. 9. 22. 12.]]
随机但不重复抽取
[[ 21. 9. 15. 4.]
[ 23. 2. 3. 7.]
[ 13. 5. 6. 1.]]
随机但按制度概率抽取
[[ 15. 19. 24. 8.]
[ 5. 22. 5. 14.]
[ 3. 22. 13. 17.]]
1.3 NumPy的算术运算
机器学习和深度学习中涉及大量的数组或矩阵运算,这节将重点介绍两种常用的运算。一种是对应元素相乘,又称为逐元乘法(Element-Wise Product),或哈达玛积(Hadamard Product),运算符为np.multiply(), 或 *。另一种是点积或内积元素,运算符为np.dot()。
1.3.1遂元素操作
遂元素操作(又称为对应元素相乘)是两个矩阵中对应元素乘积。np.multiply 函数用于数组或矩阵对应元素相乘,输出的大小与相乘数组或矩阵的大小一致,其格式如下:
|
1 |
numpy.multiply(x1, x2, /, out=None, *, where=True,casting='same_kind', order='K', dtype=None, subok=True[, signature, extobj]) |
其中x1、x2之间的对应元素相乘遵守广播规则,NumPy的广播规则将在1.8节介绍。下面我们通过一些示例来进一步说明。
|
1 2 3 4 5 6 7 8 9 10 11 |
A = np.array([[1, 2], [-1, 4]]) B = np.array([[2, 0], [3, 4]]) A*B ##结果如下: array([[ 2, 0], [-3, 16]]) #或另一种表示方法 np.multiply(A,B) #运算结果也是 array([[ 2, 0], [-3, 16]]) |
矩阵A和B的对应元素相乘,如图1-5所示。
图1-5 对应元素相乘示意图
NumPy数组不仅可以和数组进行对应元素相乘,也可以和单一数值(或称为标量)进行运算。运算时,NumPy数组的每个元素和标量进行运算,其间会用到广播机制,例如:
|
1 2 |
print(A*2.0) print(A/2.0) |
运行结果如下:
[[ 2. 4.]
[-2. 8.]]
[[ 0.5 1. ]
[-0.5 2. ]]
由此,推而广之,数组通过一些激活函数后,输出与输入形状一致。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
X=np.random.rand(2,3) def sigmoid(x): return 1/(1+np.exp(-x)) def relu(x): return np.maximum(0,x) def softmax(x): return np.exp(x)/np.sum(np.exp(x)) print("输入参数X的形状:",X.shape) print("激活函数sigmoid输出形状:",sigmoid(X).shape) print("激活函数relu输出形状:",relu(X).shape) print("激活函数softmax输出形状:",softmax(X).shape) |
运行结果如下:
输入参数X的形状: (2, 3)
激活函数sigmoid输出形状: (2, 3)
激活函数relu输出形状: (2, 3)
激活函数softmax输出形状: (2, 3)
1.3.2 点积运算
点积(Dot Product)运算又称为内积运算,在NumPy中用np.dot表示,其一般格式为:
numpy.dot(a, b, out=None)
下面通过一个示例来说明dot的具体使用及注意事项。
|
1 2 3 4 |
X1=np.array([[1,2],[3,4]]) X2=np.array([[5,6,7],[8,9,10]]) X3=np.dot(X1,X2) print(X3) |
运行结果如下:
[[21 24 27]
[47 54 61]]
以上运算可表示为如图1-6所示形式。
图1-6 矩阵的点积示意图,对应维度的元素个数需要保持一致
如图1-6所示,矩阵X1和矩阵X2进行点积运算,其中X1和X2对应维度(即X1的第2个维度与X2的第1个维度)的元素个数必须保持一致,此外,矩阵X3是由矩阵X1的行数与矩阵X2的列数构成的。
点积运算在神经网络中使用非常频繁,如图1-7所示的神经网络,输入I与权重矩阵W之间的运算就是点积运算。
图1-7 内积运算可视化示意图
1.4数组变形
在机器学习以及深度学习的任务中,我们通常需要将处理好的数据以模型能接收的格式发送给模型,然后由模型通过一系列运算,最终返回一个处理结果。然而,由于不同模型所接收的输入格式不一样,往往需要先对其进行一系列变形和运算,将数据处理成符合模型要求的格式。最常见的是矩阵或者数组的运算,我们经常会遇到需要把多个向量或矩阵按某轴方向合并,或展平(如在卷积或循环神经网络中,在全连接层之前,需要把矩阵展平)的情况。下面介绍几种常用数据变形方法。
1.4.1 修改数组的形状
修改指定数组的形状是NumPy中最常见的操作之一,常见的方法有很多,表1-3 列出了一些常用函数。
表1-3 NumPy中改变向量形状的一些函数
下面我们来看一些示例。
1)reshape函数。
|
1 2 3 4 5 6 7 8 9 |
import numpy as np arr =np.arange(10) print(arr) # 将向量 arr 维度变换为2行5列 print(arr.reshape(2, 5)) # 指定维度时可以只指定行数或列数, 其他用 -1 代替 print(arr.reshape(5, -1)) print(arr.reshape(-1, 5)) |
运行结果如下:
[0 1 2 3 4 5 6 7 8 9]
[[0 1 2 3 4]
[5 6 7 8 9]]
[[0 1]
[2 3]
[4 5]
[6 7]
[8 9]]
[[0 1 2 3 4]
[5 6 7 8 9]]
值得注意的是,reshape 函数支持只指定行数或列数,其余设置为-1即可。注意,所指定的行数或列数一定要能被整除,例如将上面代码修改为arr.reshape(3,-1)将报错,因为10不能被3整除。
2)resize函数。
|
1 2 3 4 5 6 7 |
import numpy as np arr =np.arange(10) print(arr) # 将向量 arr 维度变换为2行5列 arr.resize(2, 5) print(arr) |
运行结果如下:
[0 1 2 3 4 5 6 7 8 9]
[[0 1 2 3 4]
[5 6 7 8 9]]
3)T函数。
|
1 2 3 4 5 6 7 |
import numpy as np arr =np.arange(12).reshape(3,4) # 向量 arr 为3行4列 print(arr) # 将向量 arr 进行转置为4行3列 print(arr.T) |
运行结果如下:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
4)ravel函数。
ravel 函数接收一个根据C语言格式(即按行优先排序)或者Fortran语言格式(即按列优先排序)来进行展平的参数,默认情况下是按行优先排序。
|
1 2 3 4 5 6 7 8 9 10 |
import numpy as np arr =np.arange(6).reshape(2, -1) print(arr) # 按照列优先,展平 print("按照列优先,展平") print(arr.ravel('F')) # 按照行优先,展平 print("按照行优先,展平") print(arr.ravel()) |
运行结果如下:
[[0 1 2]
[3 4 5]]
按照列优先,展平
[0 3 1 4 2 5]
按照行优先,展平
[0 1 2 3 4 5]
5)flatten(order='C')函数。
把矩阵转换为向量,展平方式默认是行优先(即参数order='C'),这种需求经常出现在卷积网络与全连接层之间。
|
1 2 3 4 |
import numpy as np a =np.floor(10*np.random.random((3,4))) print(a) print(a.flatten(order='C')) |
运行结果如下:
[[4. 0. 8. 5.]
[1. 0. 4. 8.]
[8. 2. 3. 7.]]
[4. 0. 8. 5. 1. 0. 4. 8. 8. 2. 3. 7.]
Flatten(展平)运算,在神经网络中经常使用,一般在网络的后面需要把2维、3维等多维数组转换为一维数组,此时就需要用到展平这个操作,如图1-8所示。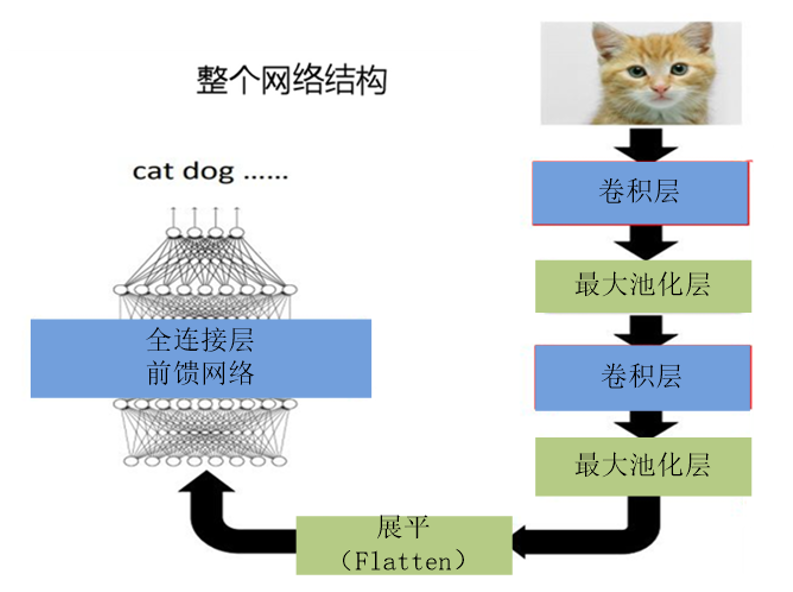
图1-8 含flatten运算的神经网络示意图
6)squeeze函数。
squeeze函数是一个主要用于降维的函数,可以把矩阵中含1的维度去掉。
|
1 2 3 4 5 6 7 8 |
import numpy as np arr =np.arange(3).reshape(3, 1) print(arr.shape) #(3,1) print(arr.squeeze().shape) #(3,) arr1 =np.arange(6).reshape(3,1,2,1) print(arr1.shape) #(3, 1, 2, 1) print(arr1.squeeze().shape) #(3, 2) |
7)transpose函数
transpose函数主要用于对高维矩阵进行轴对换,在深度学习中经常用到,比如把图像表示颜色的RGB顺序改为GBR的顺序。
|
1 2 3 4 5 |
import numpy as np arr2 = np.arange(24).reshape(2,3,4) print(arr2.shape) #(2, 3, 4) print(arr2.transpose(1,2,0).shape) #(3, 4, 2) |
1.4.2 合并数组
合并数组也是最常见的操作之一,表1-4列举了常用的NumPy数组或向量合并的方法。
表1-4 常用的NumPy 数组合并的方法
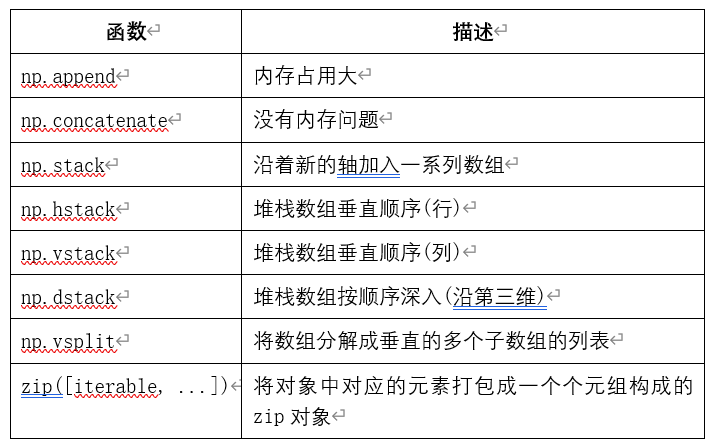
[说明]
1)append、concatnate以及stack函数都有一个 axis 参数,用于控制数组合并是按行还是按列排序。
2)append和concatnate函数中待合并的数组必须有相同的行数或列数(满足一个即可)。
3)stack、hstack、dstack函数中待合并的数组必须具有相同的形状( shape)。
下面选择一些常用函数进行说明。
1.append
合并一维数组:
|
1 2 3 4 5 6 7 |
import numpy as np a =np.array([1, 2, 3]) b = np.array([4, 5, 6]) c = np.append(a, b) print(c) # [1 2 3 4 5 6] |
合并多维数组:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import numpy as np a =np.arange(4).reshape(2, 2) b = np.arange(4).reshape(2, 2) # 按行合并 c = np.append(a, b, axis=0) print('按行合并后的结果') print(c) print('合并后数据维度', c.shape) # 按列合并 d = np.append(a, b, axis=1) print('按列合并后的结果') print(d) print('合并后数据维度', d.shape) |
运行结果如下:
按行合并后的结果
[[0 1]
[2 3]
[0 1]
[2 3]]
合并后数据维度 (4, 2)
按列合并后的结果
[[0 1 0 1]
[2 3 2 3]]
合并后数据维度 (2, 4)
2.concatenate
沿指定轴连接数组或矩阵:
|
1 2 3 4 5 6 7 8 |
import numpy as np a =np.array([[1, 2], [3, 4]]) b = np.array([[5, 6]]) c = np.concatenate((a, b), axis=0) print(c) d = np.concatenate((a, b.T), axis=1) print(d) |
运行结果如下:
[[1 2]
[3 4]
[5 6]]
[[1 2 5]
[3 4 6]]
3.stack
沿指定轴堆叠数组或矩阵:
|
1 2 3 4 5 |
import numpy as np a =np.array([[1, 2], [3, 4]]) b = np.array([[5, 6], [7, 8]]) print(np.stack((a, b), axis=0)) |
运行结果如下:
[[[1 2]
[3 4]]
[[5 6]
[7 8]]]
4.zip
zip是Python的一个内置函数,多用于张量运算中。
|
1 2 3 4 5 6 7 8 |
import numpy as np a =np.array([[1, 2], [3, 4]]) b = np.array([[5, 6], [7, 8]]) c=c=zip(a,b) for i,j in c: print(i, end=",") print(j) |
运行结果如下:
[1 2],[5 6]
[3 4],[7 8]
zip函数组合两个向量。
|
1 2 3 4 5 6 7 8 |
import numpy as np a1 = [1,2,3] b1 = [4,5,6] c1=zip(a1,b1) for i,j in c1: print(i, end=",") print(j) |
运行结果如下:
1,4
2,5
3,6
1.5 批量处理
在深度学习中,由于源数据都比较大,所以通常需要采用批处理。如利用批量来计算梯度的随机梯度法(SGD)就是一个典型应用。深度学习的计算一般比较复杂,加上数据量一般比较大,如果一次处理整个数据,往往出现资源瓶颈。为了更有效地计算,一般将整个数据集分成多个小批量。与处理整个数据集的另一个极端是每次处理一条记录,这种方法也不科学,因为一次处理一条记录无法充分发挥GPU、NumPy平行处理优势。因此,在实际使用中我们往往采用批量处理(mini-batch)。
如何把大数据拆分成多个批次呢?可采用如下步骤:
• 得到数据集
• 随机打乱数据
• 定义批大小
• 批处理数据集
下面通过一个示例来具体说明:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import numpy as np #生成10000个形状为2X3的矩阵 data_train = np.random.randn(10000,2,3) #这是一个3维矩阵,第一个维度为样本数,后两个是数据形状 print(data_train.shape) #(10000,2,3) #打乱这10000条数据 np.random.shuffle(data_train) #定义批量大小 batch_size=100 #进行批处理 for i in range(0,len(data_train),batch_size): x_batch_sum=np.sum(data_train[i:i+batch_size]) print("第{}批次,该批次的数据之和:{}".format(i,x_batch_sum)) |
最后5行结果如下:
第9500批次,该批次的数据之和:17.63702580438092
第9600批次,该批次的数据之和:-1.360924607368387
第9700批次,该批次的数据之和:-25.912226239266445
第9800批次,该批次的数据之和:32.018136957835814
第9900批次,该批次的数据之和:2.9002576614446935
【说明】
批次从0开始,所以最后一个批次是9900。
1.6 节省内存
在NumPy操作数据过程中,有大量涉及变量、数组的操作,尤其在机器学习、深度学习中,参数越来越多,数据量也越来越大,如何有效保存、更新这些参数,将直接影响内存的使用。这里我们介绍几种节省内存的简单方法。
1. 使用X=X+Y与X += Y的区别
假设X、Y为向量或矩阵,这种操作在机器学习中非常普遍。两个表达式从数学角度来说是完全一样的,但对使用内存的开销来说,却完全不同。X += Y操作可减少内存开销。
下面我们用Python的id()函数来说明。id()函数提供了内存中引用对象的确切地址。 运行X = X+Y后,我们会发现id(X)指向另一个位置。 这是因为Python首先计算X+Y,为结果分配新的内存,然后使X指向内存中的这个新位置。
|
1 2 3 4 5 |
Y = np.random.randn(10,2,3) X=np.zeros_like(Y) print(id(X)) X=X+Y print(id(X)) |
运行结果如下:
1852224075136
1852224037312
X在运行X=X+Y前后id不同,说明指向不同内存区域。
|
1 2 3 4 5 |
Y = np.random.randn(10,2,3) X=np.zeros_like(Y) print(id(X)) X+=Y print(id(X)) |
运行结果如下:
1852224018672
1852224018672
X在运行X+=Y前后id相同,说明指向一个内存区域。
2. X=X+Y与X[:]=X+Y的区别
实现代码如下:
|
1 2 3 4 5 |
Y = np.random.randn(10,2,3) X=np.zeros_like(Y) print(id(X)) X=X+Y print(id(X)) |
运行结果如下:
1852224017152
1852224018672
X在运行X=X+Y前后id不同,说明指向不同内存区域。
|
1 2 3 4 5 |
Y = np.random.randn(10,2,3) X=np.zeros_like(Y) print(id(X)) X[:]=X+Y print(id(X)) |
X在运行X[:]=X+Y前后id相同,说明指向一个内存区域。
1.7通用函数
NumPy提供了两种基本的对象,即ndarray和ufunc对象。前面我们介绍了ndarray,本节将介绍NumPy的另一个对象通用函数——ufunc。ufunc是universal function的缩写,是一种能对数组的每个元素进行操作的函数。许多ufunc函数都是用C语言实现的,因此它们的计算速度非常快。此外,它们比math模块中函数更灵活。math模块的输入一般是标量,但NumPy中函数的输入可以是向量或矩阵,而利用向量或矩阵可以避免使用循环语句,这点在机器学习、深度学习中非常重要。表1-5列举了几个NumPy的常用通用函数。
表1-5 NumPy的常用通用函数
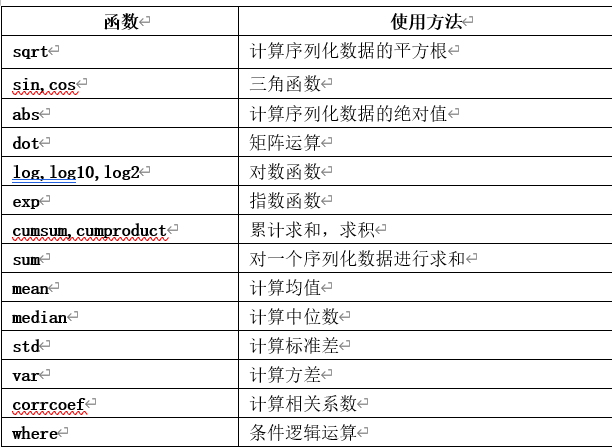
【说明】np.max,np.sum,np.min等函数中,都涉及一个有关轴的参数(即axis),该参数的具体含义,可参考图1-9。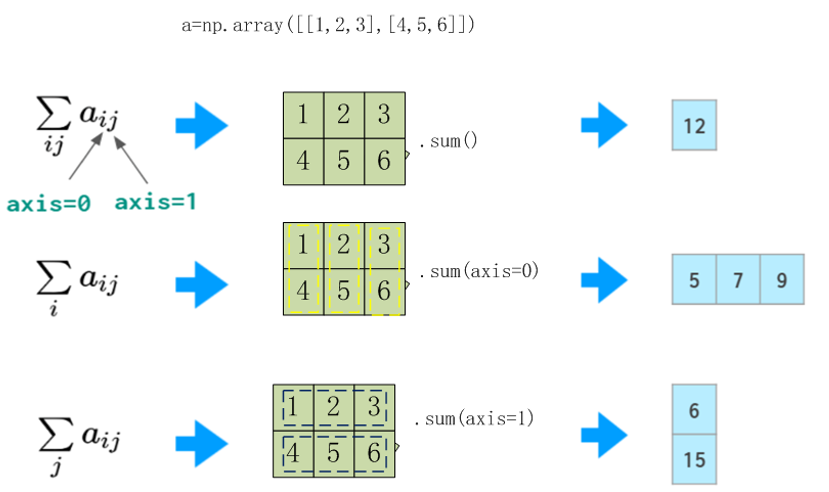
-图1-9 可视化参数axis的具体含义
1.math与numpy函数的性能比较
实现代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import time import math import numpy as np x = [i * 0.001 for i in np.arange(1000000)] start = time.clock() for i, t in enumerate(x): x[i] = math.sin(t) print ("math.sin:", time.clock() - start ) x = [i * 0.001 for i in np.arange(1000000)] x = np.array(x) start = time.clock() np.sin(x) print ("numpy.sin:", time.clock() - start ) |
运行结果如下:
math.sin: 0.5169950000000005
numpy.sin: 0.05381199999999886
由此可见,numpy.sin比math.sin快近10倍。
2.循环与向量运算比较
充分使用Python的NumPy库中的内建函数(built-in function),实现计算的向量化,可大大提高运行速度。NumPy库中的内建函数使用了SIMD指令。如下使用的向量化要比使用循环计算速度快得多。如果使用GPU,其性能将更强大,不过NumPy不支持GPU。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import time import numpy as np x1 = np.random.rand(1000000) x2 = np.random.rand(1000000) ##使用循环计算向量点积 tic = time.process_time() dot = 0 for i in range(len(x1)): dot+= x1[i]*x2[i] toc = time.process_time() print ("dot = " + str(dot) + "\n for loop----- Computation time = " + str(1000*(toc - tic)) + "ms") ##使用numpy函数求点积 tic = time.process_time() dot = 0 dot = np.dot(x1,x2) toc = time.process_time() print ("dot = " + str(dot) + "\n verctor version---- Computation time = " + str(1000*(toc - tic)) + "ms") |
运行结果如下:
dot = 250215.601995
for loop----- Computation time = 798.3389819999998ms
dot = 250215.601995
verctor version---- Computation time = 1.885051999999554ms
从运行结果上来看,使用for循环的运行时间大约是向量运算的400倍。因此,深度学习算法中,一般都使用向量化矩阵运算。
3.np.where的使用
np.where()有两种使用方法,其功能类似于列表中的推导式。
(1)np.where(condition, x, y)
满足条件(condition)(可理解为非0),输出x,不满足输出y。其中condition、y和z都是数组,它的返回值是一个形状与condition相同的数组。
先看condition为一维的情况。
|
1 2 3 4 5 |
import numpy as np a = np.arange(-2,10) x=np.where(a,1,-1) print("a的值:",a) print("x的值",x) |
a的值: [-2 -1 0 1 2 3 4 5 6 7 8 9]
x的值 [ 1 1 -1 1 1 1 1 1 1 1 1 1]
如果condtion为二维的情况,实例如下:
|
1 2 |
z=np.where([[True,False], [True,True]], [[1,2], [3,4]], [[9,8], [7,6]]) print("z的值",z) |
运行结果:
z的值 [[1 8] [3 4]]
(2)np.where(condition)
只有条件 (condition),没有x和y,则输出满足条件 (即非0) 元素的索引 (等价于numpy.nonzero),以元组方式输出。
|
1 2 3 |
b = np.array([2,4,6,8,10]) c=np.where(b > 5) print("c的值",c) |
运行结果
c的值 (array([2, 3, 4], dtype=int64),)
|
1 2 3 4 |
d = np.arange(12).reshape(3,4) e=np.where(d > 5) print("d的值",d) print("d的值",e) |
运行结果
d的值 [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
d的值 (array([1, 1, 2, 2, 2, 2], dtype=int64), array([2, 3, 0, 1, 2, 3], dtype=int64))
1.8 广播机制
NumPy的通用函数中要求输入的数组形状(shape)是一致的,当数组的形状不相等时,则会使用广播机制。不过,调整数组使得shape一样时,需满足一定规则,否则将出错。这些规则可归结为以下4条:
1)让所有输入数组都向其中shape最长的数组看齐,shape中不足的部分都通过在前面加1补齐;如:a为2x3x2,b为3x2,则b向a看齐,在b的前面加1,变为1x3x2;
2)输出数组的shape是输入数组shape的各个轴上的最大值;
3)如果输入数组的某个轴和输出数组的对应轴的长度相同或者其长度为1时,这个数组能够用来计算,否则将出错;
4)当输入数组的某个轴的长度为1时,沿着此轴运算时都用(或复制)此轴上的第一组值。
广播在整个NumPy中用于决定如何处理形状迥异的数组;涉及算术运算包括(+,-,*,/…)。这些规则说的很严谨,但不直观,下面我们结合图形与代码进一步说明。
目的:A+B,其中A为4x1矩阵,B为一维向量 (3,)。
要实现A、B相加,需要做如下处理。
1)根据规则1,B需要向看齐,把B变为(1,3)。
2)根据规则2,输出的结果为各个轴上的最大值,即输出结果应该为(4,3)矩阵,
那么A如何由(4,1)变为(4,3)矩阵?B如何由(1,3)变为(4,3)矩阵?
3)根据规则4,用此轴上的第一组值(要主要区分是哪个轴),进行复制(但在实际处理中不是真正复制,否则太耗内存,而是采用其他对象如ogrid对象,进行网格处理)即可,
详细处理如图1-10所示。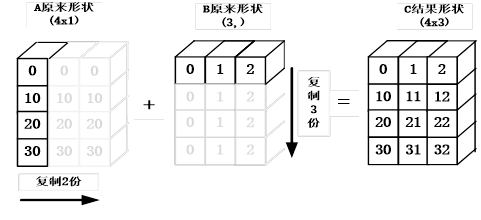
图1-10 NumPy广播规则示意图
代码实现如下:
|
1 2 3 4 5 6 7 |
import numpy as np A = np.arange(0, 40,10).reshape(4, 1) B = np.arange(0, 3) print("A矩阵的形状:{},B矩阵的形状:{}".format(A.shape,B.shape)) C=A+B print("C矩阵的形状:{}".format(C.shape)) print(C) |
运行结果如下:
A矩阵的形状:(4, 1),B矩阵的形状:(3,)
C矩阵的形状:(4, 3)
[[ 0 1 2]
[10 11 12]
[20 21 22]
[30 31 32]]
1.9小结
本章主要介绍了NumPy的使用。机器学习、深度学习涉及很多向量与向量、向量与矩阵、矩阵与矩阵的运算,这些运算都离不开NumPy,NumPy为各种运算提供了各种高效方法,同时NumPy也是PyTorch张量运算的重要基础。
1.NumPy基础
2.线性代数
3.微积分
4.概率统计
5.信息论
6.随机过程
7.强化学习
8.概率图模型
9.构建目标函数
学好数学,将使您更具创新能力!
本例是数学在构建多分类任务的损失函数时的一个经典应用
多分类的目标函数可作为二分类的推广,多分类任务的学习过程如下:
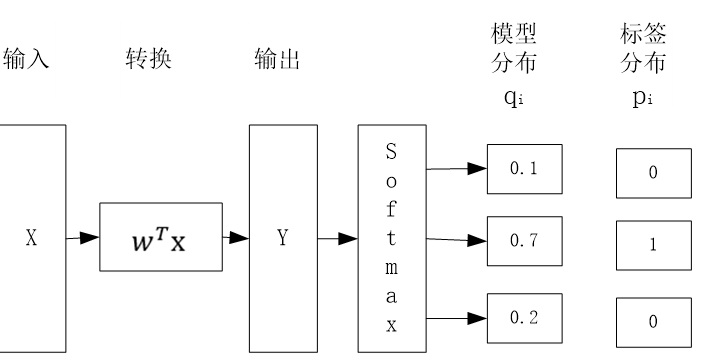
模型分布服从多项分布,其对数似然函数为:

为计算最大似然估计,把上式添加负号,并对各样本进行累加可得,多分类任务的损失函数为:

其中m表示样本总数,c表示类别总数
 表示样本i的真实类别为1,否则取0。
表示样本i的真实类别为1,否则取0。
 表示样本i属于类别j的预测值或概率值。
表示样本i属于类别j的预测值或概率值。
上式实际上就是模型分布与标签分布的交叉熵,这个交叉熵可以很好衡量模型分布与标签分布的差异,同时通过迭代法求该损失函数最小值的过程,等价于进行最大似然估计的过程,实现了最小化损失函数与进行最大似然估计的完美统一!
对其原理有一定了解后,自然对这种损失函数的优缺点会有进一步认识。以交叉熵构成的损失函数一般把标签转换为独热编码(One-Hot),这样标签向量中只有一个1其余都是0,这说明它只关心对于正确标签预测概率的准确性,忽略了其他非正确标签的差异。如果类别数很多或有些类别是相近的(如同不同角度的同一个人脸),这种方式就有点过于严苛,为此改进这些不足,人们想到了很多优化方法,比如对softmax进行改进,如L-Softmax、SM-Softmax、AM-Softmax等。