文章目录
第4章 预处理文本数据
4.1文本预处理一般流程
图4-1 典型的文本预处理流程
4.2 英文文本预处理实例
这里使用NLTK工具,NLTK,Natural Language Toolkit是一个Python模块,提供了多种语料库(Corpora)和词典(Lexicon)资源,比如WordNet等,以及一系列基本的自然语言处理工具集,包括:分句,标记解析(Tokenization),词干提取(Stemming),词性标注(POS Tagging)和句法分析(Syntactic Parsing)等,是对英文文本数据进行处理的常用工具。
4.2.1 安装配置NLTK
1、安装nltk库
pip install nltk
2、安装语料库
进入官网地址下官网地址
https://gitcode.net/mirrors/nltk/nltk_data?utm_source=csdn_github_accelerator
3、查看解压后的语料库可以放在本地某个些位置(如python安装目录中share目录下),
随后将下载的语料库中的packages包下的所有文件复制到nltk_data(没有就创建该目录)
另外,需要解压(注意:采用解压文件方式)tokenizers下的punkt压缩文件。
4.2.2导入语料库
|
1 2 3 4 5 6 7 8 9 10 |
import nltk # 引用布朗大学的语料库 from nltk.corpus import brown # 查看语料库包含的类别 print(brown.categories()) # 查看brown语料库 print('共有{}个句子'.format(len(brown.sents()))) print('共有{}个单词'.format(len(brown.words()))) |
运行结果
['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies', 'humor', 'learned', 'lore', 'mystery', 'news', 'religion', 'reviews', 'romance', 'science_fiction']
共有57340个句子
共有1161192个单词
4.2.3分词(tokenize)
分词就是将句子拆分成具有语言语义学上意义的词,英文分词:单词之间是以空格作为自然分界符的;中文分词工具:结巴分词。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
sentence = "Python is a widely used high-level programming language for general-purpose programming." tokens = nltk.word_tokenize(sentence) # 需要下载punkt分词模型 print(tokens) # 安装 pip install jieba import jieba seg_list = jieba.cut("欢迎您来到上海张江高科", cut_all=True) print("全模式: " + "/ ".join(seg_list)) # 全模式 seg_list = jieba.cut("欢迎您来到上海张江高科", cut_all=False) print("精确模式: " + "/ ".join(seg_list)) # 精确模式 seg_list = jieba.cut_for_search("欢迎您来到上海张江高科") print("搜索引擎模式: " + "/ ".join(seg_list)) |
打印结果
['Python', 'is', 'a', 'widely', 'used', 'high-level', 'programming', 'language', 'for', 'general-purpose', 'programming', '.']
全模式: 欢迎/ 欢迎您/ 来到/ 上海/ 张/ 江/ 高/ 科
精确模式: 欢迎您/ 来到/ 上海/ 张江/ 高科
搜索引擎模式: 欢迎/ 欢迎您/ 来到/ 上海/ 张江/ 高科
【说明】
jieba.cut():返回的是一个迭代器。参数cut_all是bool类型,默认为False,即精确模式,当为True时,则为全模式。
精确模式,试图将句子最精确地切开,适合文本分析;
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
4.2.4词形归一化
词干提取(stemming),如look, looked, looking,词干提取,如将ing, ed去掉,只保留单词主干,这影响语料学习的准确度。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# PorterStemmer from nltk.stem.porter import PorterStemmer porter_stemmer = PorterStemmer() print(porter_stemmer.stem('looked')) print(porter_stemmer.stem('looking')) #look # SnowballStemmer from nltk.stem import SnowballStemmer snowball_stemmer = SnowballStemmer('english') print(snowball_stemmer.stem('looked')) print(snowball_stemmer.stem('looking')) # LancasterStemmer from nltk.stem.lancaster import LancasterStemmer lancaster_stemmer = LancasterStemmer() print(lancaster_stemmer.stem('looked')) print(lancaster_stemmer.stem('looking')) |
运行结果:
look
look
look
look
look
look
4.2.5词性标注 (Part-Of-Speech)
将单词的各种词形归并成一种形式,如go,went,gone
如果以前没有下载averaged_perceptron_tagger,可以以下方式下载:
nltk.download('averaged_perceptron_tagger')
词性标注
|
1 2 3 4 |
import nltk words = nltk.word_tokenize('Python is a widely used programming language.') print(nltk.pos_tag(words)) # 需要下载 averaged_perceptron_tagger |
运行结果
[('Python', 'NNP'), ('is', 'VBZ'), ('a', 'DT'), ('widely', 'RB'), ('used', 'VBN'), ('programming', 'NN'), ('language', 'NN'), ('.', '.')]
4.2.6去除停用词
为节省存储空间和提高搜索效率,NLP中会自动过滤掉某些字或词。
中文停用词表:
中文停用词库• 哈工大停用词表• 四川大学机器智能实验室停用词库• 百度停用词列表
英文使用NLTK去除停用词
使用函数stopwords.words()
|
1 2 3 4 5 |
from nltk.corpus import stopwords # 需要下载stopwords filtered_words = [word for word in words if word not in stopwords.words('english')] print('原始词:', words) print('去除停用词后:', filtered_words) |
运行结果
原始词: ['Python', 'is', 'a', 'widely', 'used', 'programming', 'language', '.']
去除停用词后: ['Python', 'widely', 'used', 'programming', 'language', '.']
4.3 中文文本数据处理
在自然语言处理(NLP)任务中,我们将自然语言交给机器学习算法来处理,但机器无法直接理解人类的语言,因此,首先要做的就是将语言数字化。如何对自然语言进行数字化呢?词向量提供了一种很好的方式。何为词向量?简单来说就是对字典D中的任意词w指定一个固定长度的实值向量,如v(w)∈R^m, v(w) 就称为w的词向量,m为词量的长度。
中文文本数据处理一般步骤,如图4-2所示。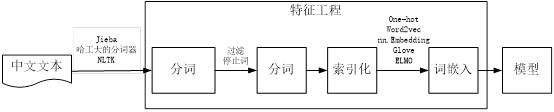
图4-2 中文文本处理一般步骤
接下来,我们先用PyTorch的词嵌入模块把语句用词向量表示,然后把这些词向量导入GRU模型中,这是自然语言处理的基础,也是核心部分。
以下是中文文本处理代码示例。
1)收集数据,定义停用词。
|
1 2 3 4 |
import jieba raw_text = """我爱上海 她喜欢北京""" stoplist=[' ','\n'] #停用词包括空格''、回车符'\n' |
2)利用jieba进行分词,并过滤停止词。
|
1 2 3 4 5 6 |
#利用jieba进行分词 words = list(jieba.cut(raw_text)) #过滤停用词,如空格,回车符\n等 words=[i for i in words if i not in stoplist] words #['我', '爱', '上海', '她', '喜欢', '北京'] |
3)去重,然后对每个词加上索引或给一个整数。
|
1 2 3 |
word_to_ix = { i: word for i, word in enumerate(set(words))} word_to_ix # {0: '爱', 1: '她', 2: '我', 3: '北京', 4: '喜欢', 5: '上海'} |
4)词向量或词嵌入。
这里采用PyTorch的nn.Embedding层,把整数转换为向量,参数为(词总数,向量长度)。
|
1 2 3 4 5 6 7 8 9 |
from torch import nn import torch embeds = nn.Embedding(6, 8) lists=[] for k,v in word_to_ix.items(): tensor_value=torch.tensor(k) lists.append((embeds(tensor_value).data)) lists |
运行结果如下:
[tensor([-1.2987, -1.7718, -1.2558, 1.1263, -0.3844, -1.0864, -1.1354, -0.5142]),
tensor([ 0.3172, -0.3927, -1.3130, 0.2153, -0.0199, -0.4796, 0.9555, -0.0238]),
tensor([ 0.9242, 0.8165, -0.0359, -1.9358, -0.0850, -0.1948, -1.6339, -1.8686]),
tensor([-0.3601, -0.4526, 0.2154, 0.3406, 0.0291, -0.6840, -1.7888, 0.0919]),
tensor([ 1.3991, -0.0109, -0.4496, 0.0665, -0.5131, 1.3339, -0.9947, -0.6814]),
tensor([ 0.8438, -1.5917, 0.6100, -0.0655, 0.7406, 1.2341, 0.2712, 0.5606])]