这里介绍几种TensorFlow2提升模型性能的几种有效方法,如数据增强、使用经典网络、使用迁移学习、使用新架构等。
一、数据增强
数据增强是提升模型性能的常用方法之一,尤其当训练数据集较小时,通过数据增强方法,效果更加明确。通过数据增强不但可以增加数据量、丰富数据的多样性,从而有效提升模型的泛化能力。
TensorFlow2提供了多种数据增强方法,常用的几种方法为:
有监督的数据增强:
1、使用tf.image的预处理
该方法一般基于dataset,然后把数据增强方法嵌入到map中
2、使用tf.keras.preprocessing.image.ImageDataGenerator
利用实时数据增强技术生成批量的张量图像数据
使用tf.keras.preprocessing.image.ImageDataGenerator,获取数据源的方法主要有:
(1).flow(x, y)
(2).flow_from_directory(directory)
3、使用tf.keras.layers.experimental.preprocessing
更多信息可参考官网:https://keras.io/guides/preprocessing_layers/
无监督的数据增强
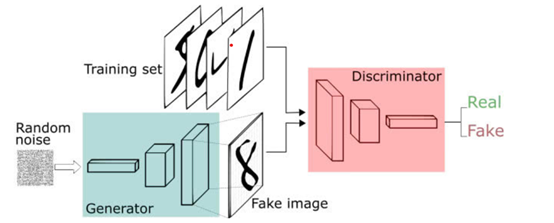
通过模型学习数据的分布,随机生成与训练数据集分布一致的图片,代表方法,GAN。
GAN模型包含两个网络,一个是生成网络(G),一个是判别网络(D),基本原理如下:
(1)G是一个生成图片的网络,它接收随机的噪声z,通过噪声生成图片,记做G(z)。
(2)D是一个判别网络,判别一张图片是不是“真实的”,即是真实的图片,还是由G生成的图片。其架构图如下:
二、使用现代经典模型
现代经典模型主要有: VGG、GoogLeNet、Inception、Xception、ResNet、MobileNet、DenseNet、NASNet等,各种网咯结构可参考:
https://blog.csdn.net/Forrest97/article/details/105630719
具体实例(待续)
三、利用迁移方法
Tensorflow.keras.application下载已经训练好的模型,包括如下预训练模型:
VGG、GoogLeNet、Inception、Xception、ResNet、MobileNet、DenseNet、NASNet等
具体实例(待续)
四、使用新架构如Transformer等
Transformer)模型在NLP领域取得了SOTA成绩,目前人们正把Transformer引用到CV领域,在图像识别、图像分类等领域取得不俗的表现。在目标检测(如DETR)、图像分类(如ViT)、图像分割(如SETR)都取得不错的效果。这里我们重点介绍ViT(Vision Transformer)。如何把Transformer引入CV领域?需要对CV中的图像做哪些处理?
NLP处理的语言数据是序列化的,而CV中处理的图像数据是三维的(height、width和channels)。所以需要通过某种方法将图像这种三维数据转化为序列化的数据。
Vision Transformer将CV和NLP领域知识结合起来,对原始图片进行分块,然后展平成序列,输入进原始Transformer模型的编码器Encoder部分,最后接入一个全连接层对图片进行分类。具体步骤为:
(1)原始图片(H,W,C)进行分块(patches)
进行一个类似卷积操作,把原始图片进行分块,分块数=H*W/P*P(P为块的大小)。
(2)展平每块(Flatten the patches)
把每块展平为一维向量,大小为:P*P*C(对应实例中的patch_dims)
(3)把展平后的块映射为更低维的向量
通过一个全连接层,把展平后块映射为一个更低维的向量(对应实例中的patch embedding),其大小为D(对应实例中的projection_dim),这个维度在各层保存不变,主要为便于使用残差连接。
(4)在patch embedding基础上添加一个类标签
类似BERT的[class] token,在patch embedding的序列之前添加一个可学习的embedding向量xclass
(5)加上位置嵌入(Add positional embeddings)
低维的向量+位置嵌入,
(6)把(5)的结果作为标准transformer encoder的输入
(7)在一个大数据集上训练模型
(8)在下游数据集中,进行微调。
ViT架构图如下:

具体实例
五、练习
1、利用ResNet经典模型提升性能
2、使用keras的数据增强方法提升性能
3、viT中Transformer的输入数据的形状(shape)与哪些因素有关?包括哪些数据?如何生成Transformer的输入数据?