文章目录
XGBoost是Kaggle上的比赛神器,近些年在kaggle或天池比赛上时常能斩获大奖,不过这样的历史正在改变!最近几年神经网络的优势开始从非结构数据向结构数据延伸,而且在一些Kaggle比赛中取得非常不错的成绩。
XGBoost很牛,不过更牛的应该是NN! 这章我们通过一个实例来说明,本实例基于相同数据,使用XGBoost和神经网络(NN)对类别数据转换为数字。XGBoost是属于Tree Model,故是否使用One-hot影响不大(通过测试,确实如此,相反,如果转换为one-hot将大大增加内存开销),所以使用xgboost的数据转换为数字后,没有再转换为one-hot编码。对神经网络(NN)而言,是否把数据转换为One-hot,影响比较大,所以使用NN的模型数据已转换为One-hot。
两种算法测试结果为表2-1。

训练及测试数据没有打乱,其中测试数据是最新原数据的10%。
2.1 XGBoost简介
2.1.1概述
XGBoost的全称是eXtreme Gradient Boosting,由很多CART(Classification And Regression Tree)树集成,其中CART是对分类决策树和回归决策树的总称。
分类决策树一般使用信息增益、信息增益率、基尼系数来选择特征的依据。CART回归树是假设树为二叉树,通过不断将特征进行分裂。比如当前树结点是基于第j个特征值进行分裂的,设该特征值小于s的样本划分为左子树,大于s的样本划分为右子树。因此,当我们为了求解最优的切分特征j和最优的切分点s,就转化为求解这么一个目标函数。
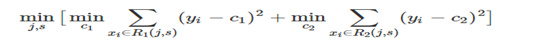
只要遍历所有特征的的所有切分点,就能找到最优的切分特征和切分点。最终得到一棵回归树。
2.1.2 主要原理
XGBoost本质上还是一个GBDT(Gradient Boosting Decision Tree),但为力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted。GBDT的原理就是所有弱分类器的结果相加等于预测值,然后下一个弱分类器去拟合误差函数对预测值的梯度(或残差)(这个梯度/残差就是预测值与真实值之间的误差)。一个弱分类器如何去拟合误差函数残差?
举一个非常简单的例子,比如我今年30岁了,但计算机或者模型GBDT并不知道我今年多少岁,那GBDT咋办呢?
(1)它会在第一个弱分类器(或第一棵树中)随便用一个年龄比如20岁来拟合,然后发现误差有10岁;
(2)在第二棵树中,用6岁去拟合剩下的损失,发现差距还有4岁;
(3)在第三棵树中用3岁拟合剩下的差距,发现差距只有1岁了;
(4)在第四课树中用1岁拟合剩下的残差,完美。
最终,四棵树的结论加起来,就是真实年龄30岁。实际工程中GBDT是计算负梯度,用负梯度近似残差。
注意,为何GBDT可以用用负梯度近似残差呢?
回归任务下,GBDT 在每一轮的迭代时对每个样本都会有一个预测值,此时的损失函数为均方差损失函数,表达式如下:
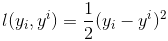
那此时的负梯度是这样计算的,具体表达式如下:
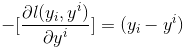
所以,当损失函数选用均方损失函数是时,每一次拟合的值就是(真实值 - 当前模型预测的值),即残差。此时的变量是,即“当前预测模型的值”,也就是对它求负梯度。
更多详细内容可参考:https://blog.csdn.net/v_july_v/article/details/81410574
2.1.3 主要优点
(1)目标表达式:
XGBoost优化了GBDT的目标函数。一方面,在GBDT的基础上加入了正则项,包括叶子节点的个数和每个叶子节点输出的L2模的平方和,正则项可以控制树的复杂度,让模型倾向于学习简单的模型,防止过拟合;另外,XGBoost还支持线性分类器,传统的GBDT是以CART算法作为基学习器。
(2)使用Shrinkage:
对每棵树的预测结果采用了shrinkage,相当于学习率,降低模型对单颗树的依赖,提升模型的泛化能力。
(3)采用列采样:
XGBoost借助了随机森林的优点,采用了列采样,进一步防止过拟合,加速训练过程,而传统的GBDT则没有列采样。
(4)优化方法:
XGBoost对损失函数的展开采用了一阶梯度和二阶梯度,而传统的GBDT只采用了一阶梯度。
(5)增益计算:
对分裂依据进行了优化。不同于CART算法,XGBoost采用了新的基于一阶导数和二阶导数的统计信息作为树的结构分数,采用分列前的结构与分裂后的结构得分的增益作为分裂依据,选择增益最大的特征值作为分裂点,替代了回归树的误差平方和。
(6)最佳增益节点查找:
XGBoost在寻找最佳分离点的方式上采用了近似算法,基于权重的分位数划分方式(权重为二阶梯度)。主要是对特征取值进行分桶,然后基于桶的值计算增益。
(7)预排序。
在寻找最佳增益节点时,将所有数据放入内存进行计算,得到预排序结果,然后在计算分裂增益的时候直接调用。
(8)缺失值处理
对于特征的值有缺失的样本,Xgboost可以自动学习出他的分裂方向。Xgboost内置处理缺失值的规则。
(9)支持并行。
众所周知,Boosting算法是顺序处理的,也是说Boosting不是一种串行的结构吗?怎么并行的?注意XGBoost的并行不是tree粒度的并行。XGBoost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含)。XGBoost的并行式在特征粒度上的,也就是说每一颗树的构造都依赖于前一颗树。
2.1.4 XGBoost的模型参数
XGBoost使用字典的方式存储参数,主要参数有如下这些:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
params = { 'booster':'gbtree', 'objective':'multi:softmax', # 多分类问题 'num_class':10, # 类别数,与multi softmax并用 'gamma':0.1, # 用于控制是否后剪枝的参数,越大越保守,一般0.1 0.2的样子 'max_depth':12, # 构建树的深度,越大越容易过拟合 'lambda':2, # 控制模型复杂度的权重值的L2 正则化项参数,参数越大,模型越不容 易过拟合 'subsample':0.7, # 随机采样训练样本 'colsample_bytree':3,# 这个参数默认为1,是每个叶子里面h的和至少是多少 # 对于正负样本不均衡时的0-1分类而言,假设h在0.01附近, #min_child_weight为1意味着叶子节点中最少需要包含100个样本。 #这个参数非常影响结果,控制叶子节点中二阶导的和的最小值,该 #参数值越小,越容易过拟合。 'silent':0, # 设置成1 则没有运行信息输入,最好是设置成0 'eta':0.007, # 如同学习率 'seed':1000, 'nthread':7, #CPU线程数 #'eval_metric':'auc' } |
安装XGBoost建议使用conda命令。如:conda install py-xgboost=0.90
2.2 NN简介
使用的神经网络结构如下图所示
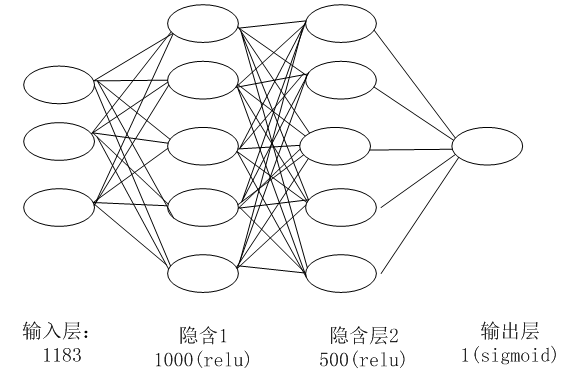
图2-1 神经网络结构
本实例使用的神经网络结构比较简单,共4层,除输入、输出层外,中间是两个全连接层。输入层1183个节点,这个正好是特征转换为one-hot后的元素个数,第1个隐含层的节点是1000,激活函数为relu,第2个隐含层的节点数为500,激活函数为relu,输出层1个节点,激活函数为sigmoid。
2.3 数据集简介
这里使用德国Rossmann超市2013、2014、2015三年的销售数据,具体数据文件包括:
train.csv-包括销售在内的历史数据
test.csv-测试数据(不包括销售)
store.csv-有关商店的补充信息
这些数据可从这里下载:https://www.kaggle.com/c/rossmann-store-sales/data
1、train.csv-包括销售在内的历史数据,共有9列,每列的含义如下:
date(日期):代表存储期
DayOfWeek(星期几):7表示周日,6表示周六以此类推
store(商店):每个商店的唯一ID
sale(销售):特定日期的营业额(这是您的预期)
customer(客户):特定日期的客户数量
open(开):为对存储是否被打开的指示:0 =关闭,1 =开
promo(促销):表示商店当天是否在进行促销
StateHoliday(州假日):通常,除州外,所有商店都在州法定假日关闭。请注意,所有学校在公共假日和周末都关闭。a =公共假期,b =复活节假期,c =圣诞节,0 =无
SchoolHoliday(学校假日):指示(商店,日期)是否受到公立学校关闭的影响
(1)导入数据
|
1 2 3 4 5 |
import pandas as pd import numpy as np store = pd.read_csv(r".\data\rossmann\store.csv") train = pd.read_csv(r".\data\rossmann\train.csv",index_col = "Date",parse_dates = ['Date'],low_memory=False) test = pd.read_csv(r".\data\rossmann\test.csv",index_col = "Date",parse_dates = ['Date'],low_memory=False) |
(2)查看前5行数据。

(3)查看是否有空值
|
1 2 |
#查看是否有空值 train.isnull().sum() |
Store 0
DayOfWeek 0
Sales 0
Customers 0
Open 0
Promo 0
StateHoliday 0
SchoolHoliday 0
dtype: int64
(4)查看各特征的不同值
|
1 2 3 4 |
#查看各字段的不同值 train['Year'] = train.index.year print("共有几年的数据:",train['Year'].unique()) print("共有几种促销方法:",train['Promo'].unique()) |
共有几年的数据: [2015 2014 2013]
共有几种促销方法: [1 0]
2、store.csv数据集简介
StoreType- 区分4种不同的商店模型:a,b,c,d
Assortment分类 -描述分类级别:a =基本,b =额外,c =扩展
CompetitionDistance-距离最近的竞争对手商店的距离(以米为单位)
CompetitionOpenSince [Month / Year] -给出最近的竞争对手开放的大概年份和月份。
Promo促销 -表示商店当天是否在进行促销
Promo2 -Promo2是某些商店的连续和连续促销:0 =商店不参与,1 =商店正在参与
Promo2Since [年/周] -描述商店开始参与Promo2的年份和日历周。
PromoInterval-描述启动Promo2的连续间隔,并指定重新开始促销的月份。例如,“ Feb,May,Aug,Nov”表示该商店的每一轮始于该年任何一年的2月,5月,8月,11月

2.4使用Xgboost算法实例
2.4.1 读取数据
(1)导入模块
|
1 2 3 4 5 6 |
import pickle import csv #屏蔽警告信息 import warnings warnings.filterwarnings('ignore') |
(2)定义数据预处理函数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
#把csv文件转换为字典 def csv2dicts(csvfile): data = [] keys = [] for row_index, row in enumerate(csvfile): #把第一行标题打印出来 if row_index == 0: keys = row print(row) continue # if row_index % 10000 == 0: # print(row_index) data.append({key: value for key, value in zip(keys, row)}) return data #如果值为空,则用'0'填充 def set_nan_as_string(data, replace_str='0'): for i, x in enumerate(data): for key, value in x.items(): if value == '': x[key] = replace_str data[i] = x |
(3)读取数据
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
train_data = "train.csv" store_data = "store.csv" store_states = 'store_states.csv' #读取数据 with open(train_data) as csvfile: data = csv.reader(csvfile, delimiter=',') with open('train_data.pickle', 'wb') as f: data = csv2dicts(data) #头尾倒过来 data = data[::-1] #序列化,把数据保存到文件中 pickle.dump(data, f, -1) print(data[:3]) |
2.4.2 预处理数据
(1)导入模块
|
1 2 3 4 5 6 |
import pickle from datetime import datetime from sklearn import preprocessing import numpy as np import random random.seed(42) |
(2)读取处理后的文件
|
1 2 3 4 5 |
with open('train_data.pickle', 'rb') as f: train_data = pickle.load(f) num_records = len(train_data) with open('store_data.pickle', 'rb') as f: store_data = pickle.load(f) |
(3)定义预处理store数据函数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
#对时间特征进行拆分和转换,是是否促销promo等特征转换为整数 def feature_list(record): dt = datetime.strptime(record['Date'], '%Y-%m-%d') store_index = int(record['Store']) year = dt.year month = dt.month day = dt.day day_of_week = int(record['DayOfWeek']) try: store_open = int(record['Open']) except: store_open = 1 promo = int(record['Promo']) #同时返回state对应的简称 return [store_open, store_index, day_of_week, promo, year, month, day, store_data[store_index - 1]['State'] ] |
(4)生成训练数据
|
1 2 3 4 5 6 7 8 9 10 11 |
train_data_X = [] train_data_y = [] for record in train_data: if record['Sales'] != '0' and record['Open'] != '': fl = feature_list(record) train_data_X.append(fl) train_data_y.append(int(record['Sales'])) print("Number of train datapoints: ", len(train_data_y)) print(min(train_data_y), max(train_data_y)) |
2.4.3 保存预处理数据
(1)把各类别特征转换为整数,并保存为pickle文件
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
full_X = train_data_X full_X = np.array(full_X) train_data_X = np.array(train_data_X) les = [] #对每列进行处理,先把类别转换为数值,然后转换为独热编码 for i in range(train_data_X.shape[1]): le = preprocessing.LabelEncoder() le.fit(full_X[:, i]) les.append(le) train_data_X[:, i] = le.transform(train_data_X[:, i]) with open('les.pickle', 'wb') as f: pickle.dump(les, f, -1) train_data_X = train_data_X.astype(int) train_data_y = np.array(train_data_y) #保存数据到feature_train_data.pickle文件 with open('feature_train_data.pickle', 'wb') as f: pickle.dump((train_data_X, train_data_y), f, -1) print(train_data_X[0], train_data_y[0]) |
2.4.4 采样生成训练与测试数据
(1)读取数据
|
1 2 3 4 5 6 |
train_ratio = 0.9 f = open('feature_train_data.pickle', 'rb') (X, y) = pickle.load(f) num_records = len(X) train_size = int(train_ratio * num_records) |
(2)生成训练与测试集
|
1 2 3 4 |
X_train = X[:train_size] X_val = X[train_size:] y_train = y[:train_size] y_val = y[train_size:] |
(3)定义采样函数
|
1 2 3 4 5 |
def sample(X, y, n): '''random samples''' num_row = X.shape[0] indices = numpy.random.randint(num_row, size=n) return X[indices, :], y[indices] |
(4)采样数据
|
1 2 |
X_train, y_train = sample(X_train, y_train, 200000) # Simulate data sparsity print("Number of samples used for training: " + str(y_train.shape[0])) |
2.4.5 构建模型
(1)导入模块
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import tensorflow as tf import numpy numpy.random.seed(123) from sklearn import linear_model from sklearn.ensemble import RandomForestRegressor from sklearn.svm import SVR from sklearn.preprocessing import StandardScaler import xgboost as xgb from sklearn import neighbors from sklearn.preprocessing import Normalizer from tensorflow.keras.models import Sequential from tensorflow.keras.models import Model as KerasModel from tensorflow.keras.layers import Input, Dense, Activation, Reshape,Flatten from tensorflow.keras.layers import Concatenate from tensorflow.keras.layers import Embedding from tensorflow.keras.callbacks import ModelCheckpoint |
(2)构建xgboost模型
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
class Model(object): def evaluate(self, X_val, y_val): assert(min(y_val) > 0) guessed_sales = self.guess(X_val) relative_err = numpy.absolute((y_val - guessed_sales) / y_val) result = numpy.sum(relative_err) / len(y_val) return result class XGBoost(Model): def __init__(self, X_train, y_train, X_val, y_val): super().__init__() dtrain = xgb.DMatrix(X_train, label=numpy.log(y_train)) evallist = [(dtrain, 'train')] param = {'nthread': -1, 'max_depth': 7, 'eta': 0.02, 'silent': 1, 'objective': 'reg:linear', 'colsample_bytree': 0.7, 'subsample': 0.7} num_round = 3000 self.bst = xgb.train(param, dtrain, num_round, evallist) print("Result on validation data: ", self.evaluate(X_val, y_val)) def guess(self, feature): dtest = xgb.DMatrix(feature) return numpy.exp(self.bst.predict(dtest)) |
2.4.6 训练模型
|
1 2 3 |
models = [] print("Fitting XGBoost...") models.append(XGBoost(X_train, y_train, X_val, y_val)) |
运行结果如下:
[2980] train-rmse:0.148366
[2981] train-rmse:0.148347
[2982] train-rmse:0.148314
[2983] train-rmse:0.148277
[2984] train-rmse:0.148238
[2985] train-rmse:0.148221
[2986] train-rmse:0.148218
[2987] train-rmse:0.148187
[2988] train-rmse:0.148182
[2989] train-rmse:0.148155
[2990] train-rmse:0.148113
[2991] train-rmse:0.148113
[2992] train-rmse:0.148067
[2993] train-rmse:0.148066
[2994] train-rmse:0.148064
[2995] train-rmse:0.148062
[2996] train-rmse:0.148048
[2997] train-rmse:0.148046
[2998] train-rmse:0.148046
[2999] train-rmse:0.148041
Result on validation data: 0.14628885960491078
2.5 使用NN算法实例
2.5.1 预处理数据
导入数据、对数据进行预处理,这些与2.4小节中的2.4.1、2.4.2一样,接下来对个特征先转换为数字,然后转换为one-hot编码,并保存。
(1)把数据转换为one-hot编码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
encoded_x = None full_X = train_data_X full_X = np.array(full_X) train_data_X = np.array(train_data_X) for i in range(train_data_X.shape[1]): label_encoder = preprocessing.LabelEncoder() feature = label_encoder.fit_transform(train_data_X[:,i]) feature = feature.reshape(train_data_X.shape[0], 1) onehot_encoder = preprocessing.OneHotEncoder(sparse=False) feature = onehot_encoder.fit_transform(feature) if encoded_x is None: encoded_x = feature else: encoded_x = np.concatenate((encoded_x,feature),axis=1) print("X shape: : ", encoded_x.shape) |
(2)保存数据
|
1 2 3 4 5 6 7 |
train_data_X =encoded_x.astype(int) train_data_y = np.array(train_data_y) #保存数据到feature_train_data.pickle文件 with open('feature_train_data.pickle', 'wb') as f: pickle.dump((train_data_X, train_data_y), f, -1) print(train_data_X[0], train_data_y[0]) |
2.5.2 生成训练数据
(1)读取数据
|
1 2 3 4 5 6 |
train_ratio = 0.9 f = open('feature_train_data.pickle', 'rb') (X, y) = pickle.load(f) num_records = len(X) train_size = int(train_ratio * num_records) |
(2)生成训练数据
|
1 2 3 4 |
X_train = X[:train_size] X_val = X[train_size:] y_train = y[:train_size] y_val = y[train_size:] |
(3)定义采样函数
|
1 2 3 4 5 |
def sample(X, y, n): '''random samples''' num_row = X.shape[0] indices = numpy.random.randint(num_row, size=n) return X[indices, :], y[indices] |
(4)通过采样生成训练数据
|
1 2 |
X_train, y_train = sample(X_train, y_train, 200000) # Simulate data sparsity print("Number of samples used for training: " + str(y_train.shape[0])) |
2.5.3 构建神经网络模型
(1)导入模块
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import tensorflow as tf import numpy numpy.random.seed(123) from sklearn import linear_model from sklearn.ensemble import RandomForestRegressor from sklearn.svm import SVR from sklearn.preprocessing import StandardScaler import xgboost as xgb from sklearn import neighbors from sklearn.preprocessing import Normalizer from tensorflow.keras.models import Sequential from tensorflow.keras.models import Model as KerasModel from tensorflow.keras.layers import Input, Dense, Activation, Reshape,Flatten from tensorflow.keras.layers import Concatenate from tensorflow.keras.layers import Embedding from tensorflow.keras.callbacks import ModelCheckpoint |
(2)定义Model类
|
1 2 3 4 5 6 7 8 |
class Model(object): def evaluate(self, X_val, y_val): assert(min(y_val) > 0) guessed_sales = self.guess(X_val) relative_err = numpy.absolute((y_val - guessed_sales) / y_val) result = numpy.sum(relative_err) / len(y_val) return result |
(3)构建神经网络
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
class NN(Model): def __init__(self, X_train, y_train, X_val, y_val): super().__init__() self.epochs = 10 self.checkpointer = ModelCheckpoint(filepath="best_model_weights.hdf5", verbose=1, save_best_only=True) self.max_log_y = max(numpy.max(numpy.log(y_train)), numpy.max(numpy.log(y_val))) self.__build_keras_model() self.fit(X_train, y_train, X_val, y_val) def __build_keras_model(self): self.model = Sequential() self.model.add(Dense(1000, kernel_initializer="uniform", input_dim=1183)) #self.model.add(Dense(1000, kernel_initializer="uniform", input_dim=8)) self.model.add(Activation('relu')) self.model.add(Dense(500, kernel_initializer="uniform")) self.model.add(Activation('relu')) self.model.add(Dense(1)) self.model.add(Activation('sigmoid')) self.model.compile(loss='mean_absolute_error', optimizer='adam') def _val_for_fit(self, val): val = numpy.log(val) / self.max_log_y return val def _val_for_pred(self, val): return numpy.exp(val * self.max_log_y) def fit(self, X_train, y_train, X_val, y_val): self.model.fit(X_train, self._val_for_fit(y_train), validation_data=(X_val, self._val_for_fit(y_val)), epochs=self.epochs, batch_size=128, # callbacks=[self.checkpointer], ) # self.model.load_weights('best_model_weights.hdf5') print("Result on validation data: ", self.evaluate(X_val, y_val)) def guess(self, features): result = self.model.predict(features).flatten() return self._val_for_pred(result) |
2.5.4 训练模型
|
1 2 3 4 |
models = [] print("Fitting NN...") for i in range(1): models.append(NN(X_train, y_train, X_val, y_val)) |
运行结果:
Fitting NN...
Train on 200000 samples, validate on 84434 samples
Epoch 1/10
200000/200000 [==============================] - 12s 60us/sample - loss: 0.0121 - val_loss: 0.0142
Epoch 2/10
200000/200000 [==============================] - 11s 54us/sample - loss: 0.0080 - val_loss: 0.0104
Epoch 3/10
200000/200000 [==============================] - 11s 53us/sample - loss: 0.0071 - val_loss: 0.0100
Epoch 4/10
200000/200000 [==============================] - 11s 54us/sample - loss: 0.0064 - val_loss: 0.0099
Epoch 5/10
200000/200000 [==============================] - 11s 54us/sample - loss: 0.0059 - val_loss: 0.0098
Epoch 6/10
200000/200000 [==============================] - 11s 54us/sample - loss: 0.0055 - val_loss: 0.0103
Epoch 7/10
200000/200000 [==============================] - 11s 55us/sample - loss: 0.0051 - val_loss: 0.0100
Epoch 8/10
200000/200000 [==============================] - 11s 54us/sample - loss: 0.0047 - val_loss: 0.0099
Epoch 9/10
200000/200000 [==============================] - 11s 53us/sample - loss: 0.0045 - val_loss: 0.0102
Epoch 10/10
200000/200000 [==============================] - 11s 54us/sample - loss: 0.0042 - val_loss: 0.0100
Result on validation data: 0.10825838109273625
接下来将用更多实例,从多个角度比较NN与传统ML的比较,带EE(Entity Embedding)的NN与不带NN的比较,带EE的传统ML与不带EE的传统ML,以及EE在ML的顶级应用(如推荐算法、预测等问题上的使用)。
EE就像一座桥梁,把结构化数据与NN(或深度学习算法)连接在一起,大大发挥了NN在处理结构化数据方面的潜能(即NN强大的学习能力),深度学习将彻底改变传统机器学习。