文章目录
Python有了NumPy的Pandas,用Python处理数据就像使用Exel或SQL一样简单方便。
Pandas是基于NumPy的Python 库,它被广泛用于快速分析数据,以及数据清洗和准备等工作。可以把 Pandas 看作是 Python版的Excel或Table。Pandas 有两种数据结构:
Series和DataFrame,Pandas经过几个版本的更新,目前已经成为数据清洗、处理和分析的不二选择。
本章主要介绍Pandas的两个数据结构:
Serial简介
DataFrame简介
10.1 问题:Pandas有哪些优势?
科学计算方面NumPy是优势,但NumPy中没有标签,数据清理、数据处理就不是其强项了。而DataFrame有标签,就像SQL中的表一样,所以在数据处理方面DataFrame就更胜一筹了,具体包含以下几方面:
(1)读取数据方面
Pandas提供强大的IO读取工具,csv格式、Excel文件、数据库等都可以非常简便地读取,对于大数据,pandas也支持大文件的分块读取。
(2)在数据清洗方面
面对数据集,我们遇到最多的情况就是存在缺失值,Pandas把各种类型数据类型的缺失值统一称为NaN,Pandas提供许多方便快捷的方法来处理这些缺失值NaN。
(3)分析建模阶段
在分析建模阶段,Pandas自动且明确的数据对齐特性,非常方便地使新的对象可以正确地与一组标签对齐,由此,Pandas就可以非常方便地将数据集进行拆分-重组操作。
(4)结果可视化方面
结果展示方面,我们都知道Matplotlib是个数据视图化的好工具,Pandas与Matplotlib搭配,不用复杂的代码,就可以生成多种多样的数据视图。
10.2 Pandas数据结构
Pandas中两个最常用的对象是Series和DataFrame。使用pandas前,需导入以下内容:
|
1 2 3 |
import numpy as np from pandas import Series,DataFrame import pandas as pd |
Pandas主要采用Series和DataFrame两种数据结构。Series是一种类似一维数据的数据结构,由数据(values)及索引(indexs)组成,而DataFrame是一个表格型的数据结构,它有一组序列,每列的数据可以为不同类型(NumPy数据组中数据要求为相同类型),它既有行索引,也有列索引。
|
1 2 3 4 5 |
a1=np.array([1,2,3,4]) a2=np.array([5,6,7,8]) a3=np.array(['a','b','c','d']) df=pd.DataFrame({'a':a1,'b':a2,'c':a3}) df |
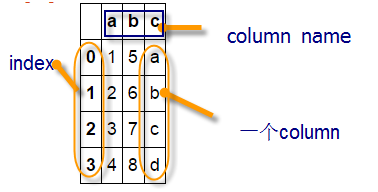
图10-1 DataFrame结构
10.3 Series
上章节我们介绍了多维数组(ndarray),当然,它也包括一维数组,Series类似一维数组,为啥还要介绍Series呢?或Series有哪些特点?
Series一个最大特点就是可以使用标签索引,序列及ndarray也有索引,但都是位置索引或整数索引,这种索引有很多局限性,如根据某个有意义标签找对应值,切片时采用类似[2:3]的方法,只能取索引为2这个元素等等,无法精确定位。
Series的标签索引(它位置索引自然保留)使用起来就方便多了,且定位也更精确,不会产生歧义。以下通过实例来说明。
(1)使用Series
|
1 2 3 4 5 6 7 |
import numpy as np from pandas import Series,DataFrame import pandas as pd s1=Series([1,3,6,-1,2,8]) s1 |
0 1
1 3
2 6
3 -1
4 2
5 8
dtype: int64
(2)使用Series的索引
|
1 2 3 4 |
s1.values #显示s1的所有值 s1.index #显示s1的索引(位置索引或标签索引) s2=Series([1,3,6,-1,2,8],index=['a','c','d','e','b','g']) #定义标签索引 s2 |
a 1
c 3
d 6
e -1
b 2
g 8
dtype: int64
(3)根据索引找对应值
|
1 2 3 4 |
s2[['a','e']] ###根据标签索引找对应值 #当然,Series除了标签索引外,还有其它很多优点,如运算的简洁: s2[s2>1] s2*10 |
10.4 DataFrame
DataFrame除了索引有位置索引也有标签索引,而且其数据组织方式与MySQL的表极为相似,除了形式相似,很多操作也类似,这就给操作DataFrame带来极大方便。这些是DataFrame特色的一小部分,它还有比数据库表更强大的功能,如强大统计、可视化等等。
DataFrame有几个要素:index、columns、values等,columns就像数据库表的列表,index是索引,values就是值。
|
1 2 3 |
####自动生成一个3行4列的DataFrame,并定义其索引(如果不指定,缺省为整数索引)####及列名 d1=DataFrame(np.arange(12).reshape((3,4)),columns=['a1','a2','a3','a4'], index=['a','b','c']) d1 |
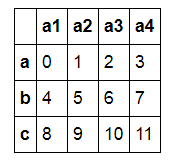
图10-2 DataFrame结果
|
1 2 3 |
d1.index #显示索引(有标签索引则显示标签索引,否则显示位置索引) d1.columns ##显示列名 d1.values ##显示值 |
10.4.1 生成DataFrame
生成DataFrame有很多,比较常用的有导入等长列表、字典、numpy数组、数据文件等。
|
1 2 3 4 5 6 |
data={'name':['zhanghua','liuting','gaofei','hedong'],'age':[40,45,50,46],'addr':['jianxi','pudong','beijing','xian']} d2=DataFrame(data) #改变列的次序 d3=DataFrame(data,columns=['name','age','addr'],index=['a','b','c','d']) d3 |
10.4.2 获取数据
获取DataFrame结构中数据可以采用obj[]操作、obj.iloc[]、obj.loc[]等命令。
(1)使用obj[]来获取列或行
|
1 2 3 4 5 6 |
d3[['name']] #选取某一列 d3[['name','age']] ##选择多列 d3['a':'c'] ##选择行 d3[1:3] ##选择行(利用位置索引) d3[d3['age']>40] ###使用过滤条件 |
(2)使用obj.loc[] 或obj.iloc[]获取行或列数据。
loc通过行标签获取行数据,iloc通过行号获取行数据。
loc 在index的标签上进行索引,范围包括start和end.
iloc 在index的位置上进行索引,不包括end.
这两者的主要区别可参考如下示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import pandas as pd data = [[1,2,3],[4,5,6],[7,8,9]] index = ['a','b','c'] columns=['c1','c2','c3'] df = pd.DataFrame(data=data, index=index, columns=columns) ###########loc的使用############ df.loc[['a','b']] #通过行标签获取行数据 df.loc[['a'],['c1','c3']] #通过行标签、列名称获取行列数据 df.loc[['a','b'],['c1','c3']] #通过行标签、列名称获取行列数据 #########iloc的使用############### df.iloc[1] #通过行号获取行数据 df.iloc[0:2] #通过行号获取行数据,不包括索引2的值 df.iloc[1:,1] ##通过行号、列行获取行、列数据 df.iloc[1:,[1,2]] ##通过行号、列行获取行、列数据 df.iloc[1:,1:3] ##通过行号、列行获取行、列数据 |
【说明】
除使用iloc及loc外,早期版本还有ix格式。pandas0.20.0及以上版本,ix已经丢弃,请尽量使用loc和iloc;
10.4.3 修改数据
我们可以像操作数据库表一样操作DataFrame,删除数据、插入数据、修改字段名、索引名、修改数据等,以下通过一些实例来说明。
|
1 2 3 |
data={'name':['zhanghua','liuting','gaofei','hedong'],'age':[40,45,50,46],'addr':['jianxi','pudong','beijing','xian']} d3=DataFrame(data,columns=['name','age','addr'],index=['a','b','c','d']) d3 |

图10-3 数据结构
|
1 2 3 4 5 6 7 8 9 10 11 12 |
d3.drop('d',axis=0) ###删除行,如果欲删除列,使axis=1即可 d3 ###从副本中删除,原数据没有被删除 d3.drop('addr',axis=1) ###删除第addr列 ###添加一行,注意需要ignore_index=True,否则会报错 d3.append({'name':'wangkuan','age':38,'addr':'henan'},ignore_index=True) d3 ###原数据未变 ###添加一行,并创建一个新DataFrame d4=d3.append({'name':'wangkuan','age':38,'addr':'henan'},ignore_index=True) d4.index=['a','b','c','d','e'] ###修改d4的索引 d4.loc['e','age']=39 ###修改索引为e列名为age的值 |
10.4.4 汇总统计
Pandas有一组常用的统计方法,可以根据不同轴方向进行统计,当然也可按不同的列或行进行统计,非常方便。
常用的统计方法有:
表10-1 Pandas统计方法
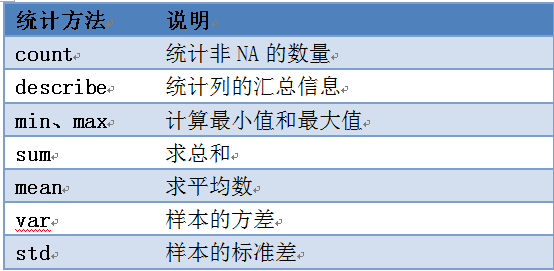
以下通过实例来说明这些方法的使用
(1)把csv数据导入pandas
|
1 2 3 4 5 6 7 8 9 10 11 |
from pandas import DataFrame import numpy as np import pandas as pd inputfile = r'C:\Users\lenovo\data\stud_score.csv' data = pd.read_csv(inputfile,encoding='gbk') #其他参数, ###header=None 表示无标题,此时缺省列名为整数;如果设为0,表示第0行为标题 ###names,encoding,skiprows等 #读取excel文件,可用 read_excel df=DataFrame(data) df.head(3) ###显示前3行 |
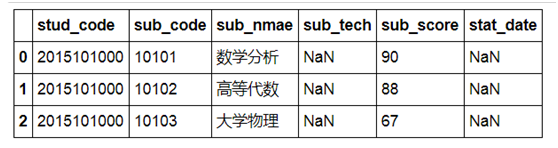
(2)查看df的统计信息
|
1 2 3 4 5 |
df.count() #统计非NaN行数 df['sub_score'].describe() ##汇总学生各科成绩 df['sub_score'].std() ##求学生成绩的标准差 df['sub_score'].var() ##求学生成绩的方差 |
【说明】
var:表示方差: σ^2=∑▒〖(X-μ)〗^2/N (10.1)
即各项-均值的平方求和后再除以N 。
std:表示标准差,是var的平方根。
10.4.5选择部分列
这里选择学生代码、课程代码、课程名称、程程成绩,注册日期等字段
|
1 2 3 4 |
#根据列的索引来选择 df.iloc[:,[0,1,2,4,5]] #或根据列名称来选择 df1=df.loc[:,['stud_code','sub_code','sub_name','sub_score','stat_date']] |
10.4.6删除重复数据
如果有重复数据(对df1的所有列),则删除最后一条记录。
|
1 |
df1.drop_duplicates(keep='last') |
10.4.7补充缺省值
(1)用指定值补充NaN值
这里要求把stat_date的缺省值(NaN)改为'2018-09-01'
|
1 2 |
df2=df1.fillna({'stat_date':'2018-11-05'}) df2.head(3) |
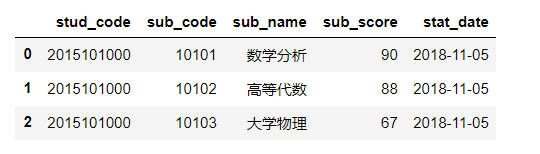
(2)可视化,并在图形上标准数据
|
1 2 3 |
df21=df2.loc[:,['sub_name','sub_score']].head(5) df22=pd.pivot_table(df21, index='sub_name', values='sub_score') df22 |
结果为:

导入一些库及支持中文的库
|
1 2 3 4 5 6 7 |
import pandas as pd from pandas import DataFrame import matplotlib.pyplot as plt import matplotlib from matplotlib.font_manager import FontProperties font = FontProperties(fname=r"c:\windows\fonts\simkai.ttf", size=14) %matplotlib inline |
画图
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
plt.figure(figsize=(10,6)) #设置x轴柱子的个数 x=np.arange(5)+1 #设置y轴的数值,需将numbers列的数据先转化为数列,再转化为矩阵格式 y=np.array(list(df22['sub_score'])) xticks1=list(df22.index) #构造不同课程类目的数列 #画出柱状图 plt.bar(x,y,width = 0.35,align='center',color = 'b',alpha=0.8) #设置x轴的刻度,将构建的xticks代入,同时由于课程类目文字较多,在一块会比较拥挤和重叠,因此设置字体和对齐方式 plt.xticks(x,xticks1,size='small',rotation=30,fontproperties=font) #x、y轴标签与图形标题 plt.xlabel('课程主题类别',fontproperties=font) plt.ylabel('sub_score') plt.title('不同课程的成绩',fontproperties=font) #设置数字标签 for a,b in zip(x,y): plt.text(a, b+0.05, '%.0f' % b, ha='center', va= 'bottom',fontsize=14) #设置y轴的范围 plt.ylim(0,100) plt.show() |
运行结果
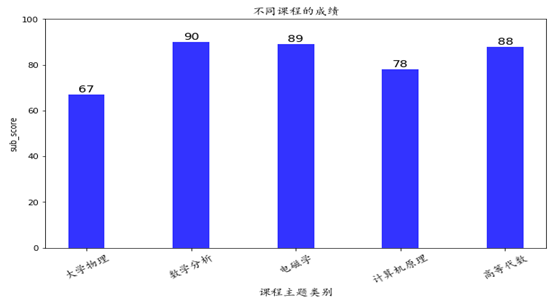
图10-4 可视化结果
10.4.8从MySQL中获取数据
(1)从MySQL数据库中获取学生基本信息表
Python连接MySQL数据库是通过pymysql这个桥梁,这个Python的第三方库,需要安装,安装命令如下:
|
1 |
pip install pymysql |
以下是从数据库获取学习具体代码:
|
1 2 3 4 5 6 7 8 |
import numpy as np import pandas as pd from pandas import DataFrame import pymysql conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='feigu', db='feigudb', charset='gbk') #学生代码直接从数据库读取为字符型,而df2中学生代码为整数型,故需要进行类型转换 df_info= pd.read_sql('select cast(stud_code as signed) as stud_code,stud_name from stud_info', conn) |
(2)查看df_info前3行数据
|
1 |
df_info.head(3) |
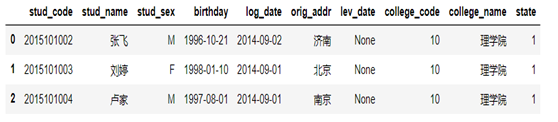
(3)选择前两个字段
|
1 |
df_info1=df_info.iloc[:,[0,1]] |
(4)df2 与df_info1 根据字段stud_code 进行内关联
|
1 2 |
df3=pd.merge(df_info1,df2,on='stud_code',how='inner') df3.head(3) |
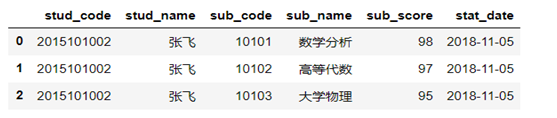
(5)对df3 根据字段stud_code,sub_code进行分组,并求平均每个同学各科的平均成绩。
|
1 2 |
df4=df3.groupby(['stud_name','sub_name'],as_index=False).mean() df4.head(3) |
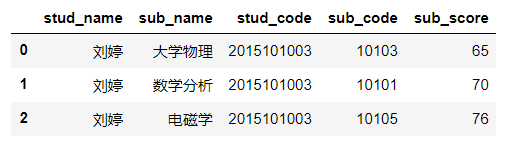
【备注】
如果需要合计各同学的成绩,可用如下语句。
|
1 |
df3.groupby(['stud_name'],as_index=False).sum().head(3) |

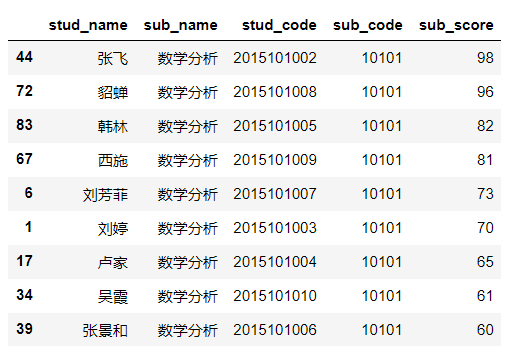
(6)选择数学分析课程,并根据成绩进行降序。
|
1 |
df4[df4['sub_code'].isin(['10101'])].sort_values(by='sub_score', ascending=False) |
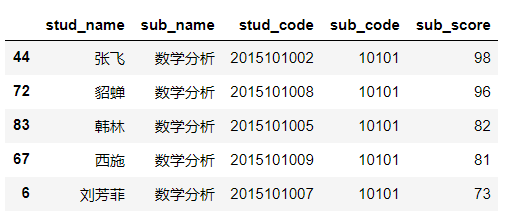
(7)取前5名
|
1 2 |
df_top5=df4[df4['sub_code'].isin(['10101'])].sort_values(by='sub_score', ascending=False).head(5) df_top5 |
注:DataFrame数据结构的函数或方法有很多,大家可以通过df.[Tab键]方式查看,具体命令的使用方法,如df.count(),可以在Ipython命令行下输入:?df.count() 查看具体使用,退出帮助界面,按q即可。
10.4.9把pandas数据写入excel
把pandas数据写入excel中的sheet中
|
1 2 3 4 5 |
with pd.ExcelWriter(r'C:\Users\lenovo\test1107.xlsx') as writer: df2.to_excel(writer,sheet_name='df2',index=False) #不保存序列号 df1.to_excel(writer,sheet_name='学生成绩') #同时保持序列号 writer.save() df2.to_csv("test1107.csv",index=False,sep=',') #把pandas数据写人csv文件 |
10.4.10 应用函数及映射
我们知道数据库中有很多函数可用作用于表中元素,DataFrame也可将函数(内置或自定义)应用到各列或行上,而且非常方便和简洁,具体可用通过DataFrame的apply,使或applymap或map,也可以作用到元素级。以下通过实例说明具体使用。
|
1 2 |
d1=DataFrame(np.arange(12).reshape((3,4)),index=['a','b','c'],columns=['a1','a2','a3','a4']) d1 |
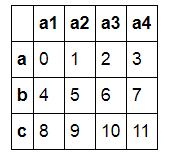
|
1 2 3 |
d1.apply(lambda x:x.max()-x.min(),axis=0) ###列级处理 d1.applymap(lambda x:x*2) ###处理每个元素 d1.iloc[1].map(lambda x:x*2) ###处理每行数据 |
10.4.11 时间序列
pandas最基本的时间序列类型就是以时间戳(时间点)(通常以python字符串或datetime对象表示)为索引的Series:
|
1 2 3 |
dates = ['2017-06-20','2017-06-21','2017-06-22','2017-06-23','2017-06-24'] ts = pd.Series(np.random.randn(5),index = pd.to_datetime(dates)) ts |
索引为日期的DataFrame数据的索引、选取以及子集构造
|
1 2 3 4 5 6 7 |
ts.index #传入可以被解析成日期的字符串 ts['2017-06-21'] #传入年或年月 ts['2017-06'] #时间范围进行切片 ts['2017-06-20':'2017-06-22'] |
10.4.12 数据离散化
如何离散化连续性数据?在一般开发语言中,可以通过控制语句来实现,但如果分类较多时,这种方法不但繁琐,效率也比较低。在Pandas中是否有更好方法?如果有,又该如何实现呢?
pandas有现成方法,如cut或qcut等,不需要编写代码,至于如何使用还是通过实例来说明。
|
1 2 3 4 5 |
import numpy as np import pandas as pd from pandas import DataFrame df9=DataFrame({'age':[21,25,30,32,36,40,45,50],'type':['1','2','1','2','1','1','2','2']},columns=['age','type']) df9 |
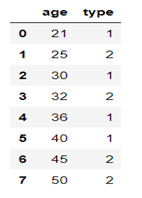
现在需要对age字段进行离散化, 划分为(20,30],(30,40],(40,50].
|
1 2 3 4 5 |
level=[20,30,40,50] ##划分为(20,30],(30,40],(40,50] groups=['A','B','C'] ##对应标签为A,B,C df9['age_t']=pd.cut(df9['age'],level,labels=groups) ##新增字段为age_t df10=df9[['age','age_t','type']] df10 |
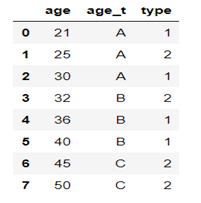
10.4.13 交叉表
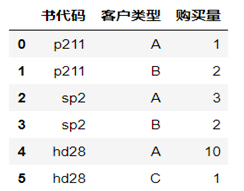
我们平常看到的数据格式大多像数据库中的表,如购买图书的基本信息:
表10-2 客户购买图书信息
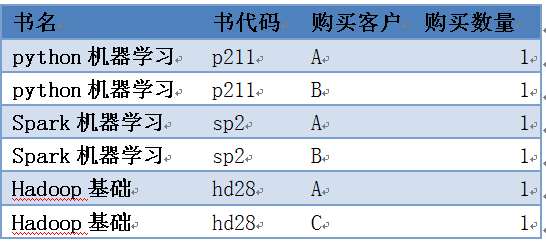
这样的数据比较规范,比较适合于一般的统计分析。但如果我们想查看客户购买各种书的统计信息,就需要把以上数据转换为如下格式:
表10-3 客户购买图书的对应关系
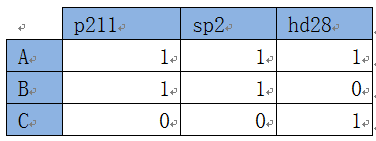
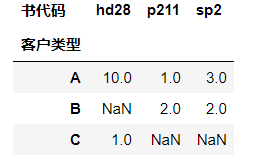
我们观察一下不难发现,把表10-3中书代码列旋转为行就得到表2数据。如何实现行列的互换呢?编码能实现,但比较麻烦,还好,pandas提供了现成的方法或函数,如stack、unstack、pivot_table函数等。以下以pivot_table为例说明具体实现。
|
1 2 3 4 5 |
import numpy as np import pandas as pd from pandas import DataFrame df=DataFrame({'书代码':['p211','p211','sp2','sp2','hd28','hd28'],'客户类型':['A','B','A','B','A','C'],'购买量':[1,2,3,2,10,1]},columns=['书代码','客户类型','购买量']) df |
实现行列互换,把书代码列转换为行或索引
|
1 |
pd.pivot_table(df,values='购买量',index='客户类型',columns='书代码') |
|
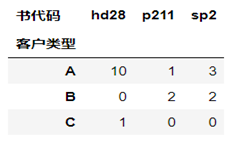
1 2 |
####转换后,出现一些NaN值或空值,我们可以把NaN修改为0 pd.pivot_table(df,values='购买量',index='客户类型',columns='书代码',fill_value=0) |
10.5 后续思考
(1)生成一个类似下例的DataFrame,C,D两列为随机数,可以与下表中数据不一致。

(2)求第(1)题的DataFrame中,C列的平均值,最大值。
(3)从第(1)题的dataframe中得到如下结果:

10.6 小结
本章介绍了Pandas的两个数据类型:Series和DataFrame。Series 是一种一维的数据类型,其中的每个元素都有各自的标签。DataFrame 是一个二维的、表格型的数据结构。Pandas 的Dataframe可以储存许多不同类型的数据,并且每个轴都有标签,可以把它当作一个Series 的字典。Pandas在数据清理、数据处理、数据可视化等方面有比较明显优势。