文章目录
- 第7 章 TensorFlow基础
- 7.1TensorFlow简介
- 7.2TensorFlow的安装
- 7.3TensorFlow的发展
- 7.4TensorFlow的特点
- 7.5TensorFlow总体介绍
- 7.6TensorFlow编程示例
- 7.6.1 graph与session
- 7.6.2 Tensor
- 7.6.3 Variables
- 7.6.5 constant 、variable及 placeholder的异同
- 7.6.6 常用概念
- 7.6.7 实例:利用梯度下降--预测曲线
- 7.7 TensorFlow实现一个神经元
- 7.7.1 定义变量
- 7.7.2 定义一个神经元
- 7.7.3 TensorBoard可视化你的图
- 7.7.4训练神经元
- 7.7.5可视化训练过程
- 7.7.6小结
- 7.8TensorFlow常用函数
- 7.9TensorFlow的运行原理
- 7.10TensorFlow系统架构
第7 章 TensorFlow基础
7.1TensorFlow简介
TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统,采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即Tensor(张量),而Flow(流)意味着基于数据流图的计算,TensorFlow为张量从流图的一端流动到另一端计算过程。TensorFlow不只局限于神经网络,其数据流式图支持非常自由的算法表达,当然也可以轻松实现深度学习以外的机器学习算法。事实上,只要可以将计算表示成计算图的形式,就可以使用TensorFlow。
TensorFlow可被用于语音识别或图像识别等多项机器深度学习领域,TensorFlow一大亮点是支持异构设备分布式计算,它能够在各个平台上自动运行模型,从手机、单个CPU / GPU到成百上千GPU卡组成的分布式系统。
7.2TensorFlow的安装
安装TensorFlow,因本环境的python2.7采用anaconda来安装,故这里采用conda管理工具来安装TensorFlow,目前conda缺省安装版本为TensorFlow 1.3。
验证安装是否成功,可以通过导入tensorflow来检验。
启动ipython(或python)
7.3TensorFlow的发展
2015年11月9日谷歌开源了人工智能系统TensorFlow,同时成为2015年最受关注的开源项目之一。TensorFlow的开源大大降低了深度学习在各个行业中的应用难度。TensorFlow的近期里程碑事件主要有:
2016年04月:发布了分布式TensorFlow的0.8版本,把DeepMind模型迁移到TensorFlow;
2016年06月:TensorFlow v0.9发布,改进了移动设备的支持;
2016年11月:TensorFlow开源一周年;
2017年2月:TensorFlow v1.0发布,增加了Java、Go的API,以及专用的编译器和调试工具,同时TensorFlow 1.0引入了一个高级API,包含tf.layers,tf.metrics和tf.losses模块。还宣布增了一个新的tf.keras模块,它与另一个流行的高级神经网络库Keras完全兼容。
2017年4月:TensorFlow v1.1发布,为 Windows 添加 Java API 支,添加 tf.spectral 模块, Keras 2 API等;
2017年6月:TensorFlow v1.2发布,包括 API 的重要变化、contrib API的变化和Bug 修 复及其它改变等。
2017年7月:TensorFlow v1.3发布,tf.contrib.data.Dataset类、Tensorflow又在库中增加了 下列函数:DNNClassifier、DNNRegressor、LinearClassifer、LinearRegressor、 DNNLinearCombinedClassifier、DNNLinearCombinedRegressor。这些estimator 是tf.contrib.learn包的一部分。
2017年11月:TensorFlow v1.4发布,tf.keras、tf.data 现在是核心 TensorFlow API 的一部 分;添加 train_and_evaluate 用于简单的分布式 Estimator 处理。
7.4TensorFlow的特点
高度的灵活性
TensorFlow 采用数据流图,用于数值计算的开源软件库。只要计算能表示为一个数据 流图,你就可以使用Tensorflow。
真正的可移植性
Tensorflow 在CPU和GPU上运行,可以运行在台式机、服务器、云服务器、手机移动 设备、Docker容器里等等。
将科研和产品联系在一起
过去如果要将科研中的机器学习想法用到产品中,需要大量的代码重写工作。Tensorflow 将改变这一点。使用Tensorflow可以让应用型研究者将想法迅速运用到产品中,也可以 让学术性研究者更直接地彼此分享代码,产品团队则用Tensorflow来训练和使用计算模 型,并直接提供给在线用户,从而提高科研产出率。
自动求微分
基于梯度的机器学习算法会受益于Tensorflow自动求微分的能力。使用Tensorflow,只 需要定义预测模型的结构,将这个结构和目标函数(objective function)结合在一起,
并添加数据,Tensorflow将自动为你计算相关的微分导数。
多语言支持
Tensorflow 有一个合理的c++使用界面,也有一个易用的python使用界面来构建和执 行你的graphs。你可以直接写python/c++程序,也可以用交互式的Ipython界面来用 Tensorflow尝试这些想法,也可以使用Go,Java,Lua,Javascript,或者是R等语言。
性能最优化
如果你有一个32个CPU内核、4个GPU显卡的工作站,想要将你工作站的计算潜能 全发挥出来,由于Tensorflow 给予了线程、队列、异步操作等以最佳的支持,Tensorflow 让你可以将你手边硬件的计算潜能全部发挥出来。你可以自由地将Tensorflow图中的计 算元素分配到不同设备上,充分利用这些资源。
下表为TensorFlow的一些主要技术特征:

表7.1 TensorFlow的主要技术特征
7.5TensorFlow总体介绍
使用 TensorFlow, 你必须明白 TensorFlow:
使用图 (graph) 来表示计算任务。
在被称之为 会话 (Session) 的上下文 (context) 中执行图。
使用 tensor 表示数据。
通过 变量 (Variable) 维护状态。
使用 feed 和 fetch 可以为任意的操作(arbitrary operation)赋值或者从其中获取数据。
一个 TensorFlow 图描述了计算的过程。为了进行计算, 图必须在会话里被启动. 会话将图的 op 分发到诸如 CPU 或 GPU 之类的设备 上, 同时提供执行 op 的方法. 这些方法执行后, 将产生的 tensor 返回。在 Python 语言中, 返回的 tensor 是 numpy ndarray 对象; 在 C 和 C++ 语言中, 返回的 tensor 是tensorflow::Tensor 实例。
7.6TensorFlow编程示例
实际上编写tensorflow可以总结为两步:
(1)组装一个graph;
(2)使用session去执行graph中的operation。
因此我们从 graph 与 session 说起。
7.6.1 graph与session
(1)计算图
Tensorflow 是基于计算图的框架,因此理解 graph 与 session 显得尤为重要。不过在讲解 graph 与 session 之前首先介绍下什么是计算图。假设我们有这样一个需要计算的表达式。该表达式包括了两个加法与一个乘法,为了更好讲述引入中间变量c与d。由此该表达式可以表示为:
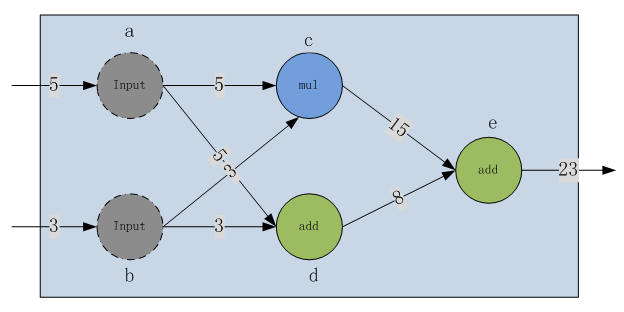
图 7.1 数据流图
当需要计算e时就需要计算c与d,而计算c就需要依赖输入值a与b,计算d需要依赖输入值a与b。这样就形成了依赖关系。这种有向无环图就叫做计算图,因为对于图中的每一个节点其微分都很容易得出,因此应用链式法则求得一个复杂的表达式的导数就成为可能,所以它会应用在类似tensorflow这种需要应用反向传播算法的框架中。
(2)概念说明
下面是 graph , session , operation , tensor 四个概念的简介。
1)Tensor:类型化的多维数组,图的边;边(edge)对应于向操作(operation)传入和从operation传出的实际数值,通常以箭头表示。
2)Operation:执行计算的单元,图的节点,节点(node)通常以圆圈、椭圆和方框等来表示,代表了对数据所做的运算或某种操作,在上图中,“add”、“mul”为运算节点。
3)Graph:一张有边与点的图,其表示了需要进行计算的任务;
4)Session:称之为会话的上下文,用于执行图。
Graph仅仅定义了所有 operation 与 tensor 流向,没有进行任何计算。而session根据 graph 的定义分配资源,计算 operation,得出结果。既然是图就会有点与边,在图计算中 operation 就是点而 tensor 就是边。Operation 可以是加减乘除等数学运算,也可以是各种各样的优化算法。每个 operation 都会有零个或多个输入,零个或多个输出。 tensor 就是其输入与输出,其可以表示一维二维多维向量或者常量。而且除了Variables指向的 tensor 外,所有的 tensor 在流入下一个节点后都不再保存。
(3)举例
下面首先定义一个数据流图(其实没有必要,tensorflow会默认定义一个),并做一些计算。
graph = tf.Graph()
with graph.as_default():
a = tf.Variable(3,name='input_a')
b = tf.Variable(5,name='input_b')
d = tf.add(a,b,name='add_d')
initialize = tf.global_variables_initializer()
这段代码,首先导入tensorflow,定义一个graph类,并在这张图上定义了foo与bar的两个变量,并给予初始值,最后对这个值求和,并初始化所有变量。其中,Variable是定义变量并赋予初值。让我们看下d。后面是输出,可以看到并没有输出实际的结果,由此可见在定义图的时候其实没有进行任何实际的计算。
运行结果为:ensor("add_d:0", shape=(), dtype=int32)
下面定义一个session,并进行真正的计算。
sess.run(initialize)
res = sess.run(d)
print(res)
运行结果为:8
这段代码中,定义了session,并在session中执行了真正的初始化,并且求得d的值并打印出来。可以看到,在session中产生了真正的计算,得出值为8。
7.6.2 Tensor
Tensorflow的张量(Tensor)有rank,shape,data types的概念,下面来分别讲解。
(1)rank
张量(Tensor)为n维矩阵,而Rank一般是指张量的维度,即0D(0维)张量称为标量;1D(1维)张量等价于向量;2D(2维)等价于矩阵;对于更高维数的张量,可称为N维张量或N阶张量。有了这一概念,便可以之前的示例数据流图进行修改,使其变为使用张量:
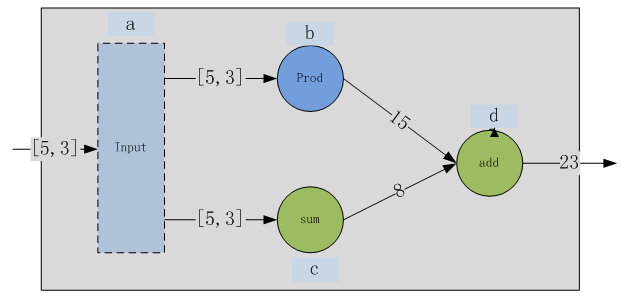
图 7.2 张量数据流图
按下列方式,修改之前的代码。将分离的节点a、b替换为统一的输入节点a,而a为1D张量。当然运算符需要调整,由add改为reduce_sum,具体如下:
c=tf.reduce_sum(a,name='sum_c')
(2)shape
Shape指tensor每个维度数据的个数,可以用python的list/tuple表示。下图表示了rank,shape的关系。
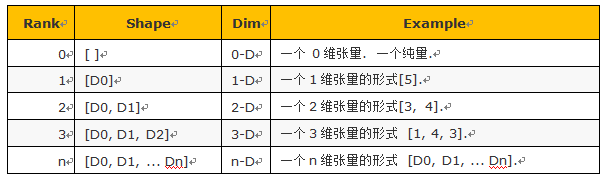
表7.2 Rank与shape的对应关系
(3)data type
Data type,是指单个数据的类型。常用DT_FLOAT,也就是32位的浮点数。下图表示了所有的types。
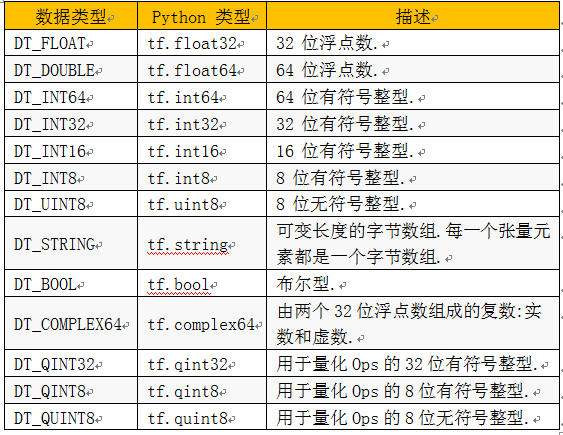
表7.3 数据类型
7.6.3 Variables
1)介绍
TensorFlow中的变量在使用前需要被初始化,在模型训练中或训练完成后可以保存或恢复这些变量值。下面介绍如何创建变量,初始化变量,保存变量,恢复变量以及共享变量。当训练模型时,需要使用Variables保存与更新参数。Variables会保存在内存当中,所有tensor一旦拥有Variables的指向就不会在session中丢失。其必须明确的初始化而且可以通过Saver保存到磁盘上。Variables可以通过Variables初始化。
biases = tf.Variable(tf.zeros([200]), name="biases")
其中,tf.random_normal是随机生成一个正态分布的tensor,其shape是第一个参数,stddev是其标准差。tf.zeros是生成一个全零的tensor。之后将这个tensor的值赋值给Variable。
以下我们通过一个实例来详细说明:
(1)创建模型的权重及偏置
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35), name="weights")
biases = tf.Variable(tf.zeros([200]), name="biases")
(2)初始化变量
实际在其初始化过程中做了很多的操作,比如初始化空间,赋初值(等价于tf.assign),并把Variable添加到graph中等操作。注意在计算前需要初始化所有的Variable。一般会在定义graph时定义global_variables_initializer,其会在session运算时初始化所有变量。
直接调用global_variables_initializer会初始化所有的Variable,如果仅想初始化部分Variable可以调用
init_op = tf.global_variables_initializer()
sess=tf.Session()
sess.run(init_op)
(3) 保存模型变量
保存模型由三个文件组成model.data,model.index,model.meta
saver.save(sess, './tmp/model/',global_step=100)
运行结果:
'./tmp/model/-100'
(4)恢复模型变量
#先加载 meta graph并恢复权重变量
saver.restore(sess,tf.train.latest_checkpoint('./tmp/model/'))
(5)查看恢复后的变量
运行结果:
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0................... 0.]
2) 共享模型变量
在复杂的深度学习模型中,存在大量的模型变量,并且期望能够一次性地初始化这些变量。TensorFlow提供了tf.variable_scope和tf.get_variable两个API,实现了共享模型变量。tf.get_variable(, , ):表示创建或返回指定名称的模型变量,其中name表示变量名称,shape表示变量的维度信息,initializer表示变量的初始化方法。tf.variable_scope():表示变量所在的命名空间,其中scope_name表示命名空间的名称。共享模型变量使用示例如下:
def conv_relu(input, kernel_shape, bias_shape):
# 创建变量"weights"
weights = tf.get_variable("weights", kernel_shape, initializer=tf.random_normal_initializer())
# 创建变量 "biases"
biases = tf.get_variable("biases", bias_shape, initializer=tf.constant_initializer(0.0))
conv = tf.nn.conv2d(input, weights, strides=[1, 1, 1, 1], padding='SAME')
return tf.nn.relu(conv + biases)
#定义卷积层,conv1和conv2为变量命名空间
with tf.variable_scope("conv1"):
# 创建变量 "conv1/weights", "conv1/biases".
relu1 = conv_relu(input_images, [5, 5, 32, 32], [32])
with tf.variable_scope("conv2"):
# 创建变量 "conv2/weights", "conv2/biases".
relu1 = conv_relu(relu1, [5, 5, 32, 32], [32])
3)Variables与constant的区别
值得注意的是Variables与constant的区别。Constant一般是常量,可以被赋值给Variables,constant保存在graph中,如果graph重复载入那么constant也会重复载入,其非常浪费资源,如非必要尽量不使用其保存大量数据。而Variables在每个session中都是单独保存的,甚至可以单独存在一个参数服务器上。可以通过代码观察到constant实际是保存在graph中,具体如下。
print(tf.get_default_graph().as_graph_def())
运行结果:
node {
name: "Const"
op: "Const"
attr {
key: "dtype"
value {
type: DT_FLOAT
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_FLOAT
tensor_shape {
}
float_val: 1.0
}
}
}
}
4)variables与get_variables的区别
(1)语法格式:
tf.Variable的参数列表为:
返回一个由initial_value创建的变量
tf.get_variable的参数列表为:
如果已存在参数定义相同的变量,就返回已存在的变量,否则创建由参数定义的新变量。
(2)使用tf.Variable时,如果检测到命名冲突,系统会自己处理。使用tf.get_variable()时,系统不会处理冲突,而会报错。
w_1 = tf.Variable(3,name="w_1")
w_2 = tf.Variable(1,name="w_1")
print( w_1.name)
print( w_2.name)
打印结果:
w_1:0
w_1_1:0
w_1 = tf.get_variable(name="w_1",initializer=1)
w_2 = tf.get_variable(name="w_1",initializer=2)
报错:
alueError Traceback (most recent call last)
in ()
2
3 w_1 = tf.get_variable(name="w_1",initializer=1)
----> 4 w_2 = tf.get_variable(name="w_1",initializer=2)
(3)两者的本质区别
tf.get_variable创建变量时,会进行变量检查,当设置为共享变量时(通过scope.reuse_variables()或tf.get_variable_scope().reuse_variables()),检查到第二个拥有相同名字的变量,就返回已创建的相同的变量;如果没有设置共享变量,则会报[ValueError: Variable varx alreadly exists, disallowed.]的错误。而tf.Variable()创建变量时,name属性值允许重复,检查到相同名字的变量时,由自动别名机制创建不同的变量。
tf.reset_default_graph()
with tf.variable_scope("scope1"):
w1 = tf.get_variable("w1", shape=[])
w2 = tf.Variable(0.0, name="w2")
with tf.variable_scope("scope1", reuse=True):
w1_p = tf.get_variable("w1", shape=[])
w2_p = tf.Variable(1.0, name="w2")
print(w1 is w1_p, w2 is w2_p)
print(w1_p,w2_p)
打印结果:
True False
<tf.Variable 'scope1/w1:0' shape=() dtype=float32_ref> <tf.Variable 'scope1_1/w2:0' shape=() dtype=float32_ref>
由此,不难明白官网上说的参数复用的真面目了。由于tf.Variable() 每次都在创建新对象,所有reuse=True 和它并没有什么关系。对于get_variable(),来说,如果已经创建的变量对象,就把那个对象返回,如果没有创建变量对象的话,就创建一个新的。
5)命名
另外一个值得注意的地方是尽量每一个变量都明确的命名,这样易于管理命令空间,而且在导入模型的时候不会造成不同模型之间的命名冲突,这样就可以在一张graph中容纳很多个模型。
6)Variables支持很多数学运算,具体可参考以下表格。
表7.4 常用运算
7.6.4 placeholders与feed_dict
当我们定义一张graph时,有时候并不知道需要计算的值,比如模型的输入数据,其只有在训练与预测时才会有值。这时就需要placeholder与feed_dict的帮助。
定义一个placeholder,可以使用tf.placeholder(dtype,shape=None,name=None)函数。
b = tf.constant(2,name='input_b')
d = tf.add(a,b,name='add_d')
with tf.Session() as sess:
print(sess.run(d))
在上面的代码中,会抛出错误(InvalidArgumentError (see above for traceback): You must feed a value for placeholder tensor 'input_a_1' with dtype int32 and shape [1]),因为计算d需要a的具体值,而在代码中并没有给出。这时候需要将实际值赋给a。最后一行修改如下:
其中最后的dict就是一个feed_dict,一般会使用python读入一些值后传入,当使用minbatch的情况下,每次输入的值都不同。
7.6.5 constant 、variable及 placeholder的异同
(1)constant
constant()是一个函数,作用是创建一个常量tensor,其格式为:
其中各参数说明如下:
value: 一个dtype类型(如果指定了)的常量值(列表)。要注意的是,要是value是一个列表的话,那么列表的长度不能够超过形状参数指定的大小(如果指定了)。要是列表长度小于指定的,那么多余的由列表的最后一个元素来填充。
dtype: 返回tensor的类型
shape: 返回的tensor形状。
name: tensor的名字
verify_shape: Boolean that enables verification of a shape of values。
示例:
#build graph
a=tf.constant(1.,name="a")
b=tf.constant(1.,shape=[2,2],name="b")
#construct session
sess=tf.Session()
#run in session
result_a=sess.run([a,b])
print("result_a:",result_a[0])
print("result_b:",result_a[1])
运行结果如下:
result_a: 1.0
result_b: [[ 1. 1.] [ 1. 1.]]
(2)variable
通过Variable()构造一个变量(variable),创建一个新的变量,初始值为initial_value构造函数需要初始值,初始值为initial_value,初始值可以是一个任何类型任何形状的Tensor。初始值的形状和类型决定了这个变量的形状和类型。构造之后,这个变量的形状和类型就固定了,他的值可以通过assign()函数来改变。如果你想要在之后改变变量的形状,你就需要assign()函数同时变量的validate_shape=False。和任何的Tensor一样,通过Variable()创造的变量能够作为图中其他操作的输入使用。
创建variable 后,其值会一直保存到程序运行结束,而一般的tensor张量在tensorflow运行过程中只是在计算图中流过,并不会保存下来。
因此varibale主要用来保存tensorflow构建的一些结构中的参数,这些参数才不会随着运算的消失而消失,才能最终得到一个模型。
比如神经网络中的权重和bias等,在训练过后,总是希望这些参数能够保存下来,而不是直接就消失了,所以这个时候要用到Variable。
注意,所有和varible有关的操作在计算的时候都要使用session会话来控制,包括计算,打印等等。
其具体格式为:
各参数说明:
initial_value: 一个Tensor类型或者是能够转化为Tensor的python对象类型。它是这个变量的初始值。这个初始值必须指定形状信息,不然后面的参数validate_shape需要设置为false。当然也能够传入一个无参数可调用并且返回制定初始值的对象,在这种情况下,dtype必须指定。
trainable: 如果为True(默认也为Ture),这个变量就会被添加到图的集合GraphKeys.TRAINABLE_VARIABLES.中去 ,这个collection被作为优化器类的默认列表。
collections:图的collection 键列表,新的变量被添加到这些collection中去。默认是[GraphKeys.GLOBAL_VARIABLES].
validate_shape: 如果是False的话,就允许变量能够被一个形状未知的值初始化,默认是True,表示必须知道形状。
caching_device: 可选,描述设备的字符串,表示哪个设备用来为读取缓存。默认是变量的device,
name: 可选,变量的名称
variable_def: VariableDef protocol buffer. If not None, recreates the Variable object with its contents. variable_def and the other arguments are mutually exclusive.
dtype: 如果被设置,初始化的值就会按照这里的类型来定。
expected_shape: TensorShape类型.要是设置了,那么初始的值会是这种形状
import_scope: Optional string. Name scope to add to the Variable. Only used when initializing from protocol buffer.
示例:
import tensorflow as tf
#create a Variable
w=tf.Variable(initial_value=[[1,2],[3,4]],dtype=tf.float32)
x=tf.Variable(initial_value=[[1,1],[1,1]],dtype=tf.float32)
x=x.assign(x*2)
print(x)
y=tf.matmul(w,x)
z=tf.sigmoid(y)
print(z)
init=tf.global_variables_initializer()
with tf.Session() as session:
session.run(init)
z=session.run(z)
print(z)
运行结果:
Tensor("Assign_1:0", shape=(2, 2), dtype=float32_ref)
Tensor("Sigmoid_2:0", shape=(2, 2), dtype=float32)
[[ 0.99752742 0.99752742]
[ 0.99999917 0.99999917]]
(3)placeholder
placeholder的作用可以理解为占个位置,我并不知道这里将会是什么值,但是知道类型和形状等等一些信息,先把这些信息填进去占个位置,然后以后用feed的方式来把这些数据“填”进去。返回的就是一个用来用来处理feeding一个值的tensor。
那么feed的时候一般就会在你之后session的run()方法中用到feed_dict这个参数了。这个参数的内容就是你要“喂”给那个placeholder的内容。
它是tensorflow中又一保存数据的利器,它在使用的时候和前面的variable不同的是在session运行阶段,需要给placeholder提供数据,利用feed_dict的字典结构给placeholdr变量“喂数据”。
其一般格式:
参数说明:
dtype: 将要被fed的元素类型
shape:(可选) 将要被fed的tensor的形状,要是不指定的话,你能够fed进任何形状的tensor。
name:(可选)这个操作的名字
示例:
|
1 2 3 4 5 6 7 8 9 10 |
x = tf.placeholder(tf.float32, shape=(2, 3)) y=tf.reshape(x,[3,2]) z= tf.matmul(x, y) print(z) with tf.Session() as sess: #print(sess.run(y)) #不注释将报错,因没有给y输入具体数据. rand_array_x = np.random.rand(2, 3) rand_array_y = np.random.rand(3, 2) print(sess.run(z, feed_dict={x: rand_array_x,y: rand_array_y})) #这句成功 |
运行结果:
Tensor("MatMul_9:0", shape=(2, 2), dtype=float32)
[[ 0.2707203 0.68843865]
[ 0.42275223 0.73435611]]
7.6.6 常用概念
从上例我们可以看到TensorFlow有不少概念,这些概念或名称有些我们在其它系统中看到或使用过,但在TensorFlow架构中,其用途很多不一样,现把主要的一些概念总结如下,便于大家参考。
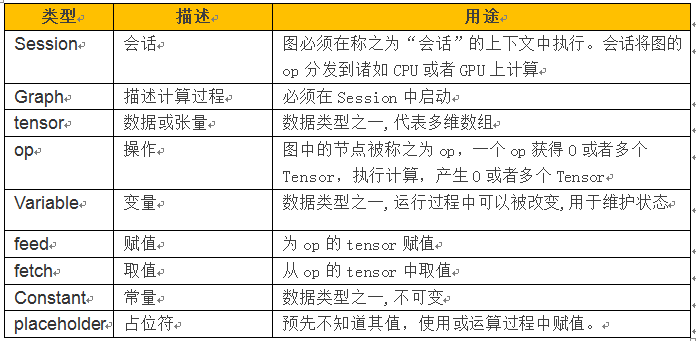
表 7.5 TensorFlow常用概念
7.6.7 实例:利用梯度下降--预测曲线
根据函数生成数据,利用梯度下降法,画一条模拟曲线,逼近原数据的分布。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt %matplotlib inline LR = 0.1 REAL_PARAMS = [1.2, 2.5] INIT_PARAMS = [2, 4.5] x = np.linspace(-1, 1, 200, dtype=np.float32) # x data y_fun = lambda a, b: np.sin(b*np.cos(a*x)) tf_y_fun = lambda a, b: tf.sin(b*tf.cos(a*x)) noise = np.random.randn(200)/10 y = y_fun(*REAL_PARAMS) + noise # 实际值 # tensorflow graph #定义a、b变量,并初始化 a=tf.Variable(2.0,dtype=tf.float32) b=tf.Variable(4.5,dtype=tf.float32) pred = tf_y_fun(a, b) #预测值 mse = tf.reduce_mean(tf.square(y-pred)) train_op = tf.train.GradientDescentOptimizer(LR).minimize(mse) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for t in range(400): a_, b_, mse_ = sess.run([a, b, mse]) result, _ = sess.run([pred, train_op]) #训练模型 # 可视化结果: print('a=', a_, 'b=', b_) plt.figure(1) plt.scatter(x, y, c='b') # plot data plt.plot(x, result, 'r-', lw=2) # plot line fitting |
运行结果:
a= 1.16647 b= 2.48966

7.7 TensorFlow实现一个神经元
【环境说明】TensorFlow1.3,Python3.6,Jupyter
7.7.1 定义变量
import tensorflow as tf
#定义一个图
graph = tf.get_default_graph()
#定义一个常数
input_value = tf.constant(1.0)
我们来看一下input_value的结果,就会发现这个是一个无维度的32位浮点张量:就是一个数字
input_value
<tf.Tensor 'Const:0' shape=() dtype=float32>
这个结果并没有说明这个数字是多少?不像Python变量一样,定义后立即可以看到其值,对于TensorFlow定义的这个常数,为了执行input_value这句话,并给出这个数字的值,我们需要创造一个“会话”(session)。让图里的计算在其中执行并明确地要执行input_value并给出结果(会话会默认地去找那个默认图)
sess.run(input_value)
运行结果为:1
“执行”一个常量可能会让人觉得有点怪。但是这与在Python里执行一个表达式类似。这就是TensorFlow管理它自己的对象空间(计算图)和它自己的执行方式。
7.7.2 定义一个神经元
接下来我们定义一个神经元,让该神经元学习一个简单1到0的函数,即输入为1,输出为0这样一个函数。假设我们有一个训练集,输入为1,输出为0.8(正确输出是0)。
假设我们要预测的函数为:y=w*x,其中w为权重,x为输入,y为输出或预测值。他们间的关系如下图所示:

图7.3 单个神经元
现在已经有了一个会话,其中有一个简单的图。下面让我们构建仅有一个参数的神经元,或者叫权重。通常即使是简单的神经元也都会有偏置项和非一致的启动函数或激活函数,但这里我们先不管这些。
神经元的权重不应该是常量,我们会期望这个值能改变,从而学习训练数据里的输入和输出。这里我们定义权重是一个TensorFlow的变量,并给它一个初值0.8。
#让权重与输入相乘,得到输出
output_value = weight * input_value
怎么才能看到乘积是多少?我们必须“运行”这个output_value运算。但是这个运算依赖于一个变量:权重。我们告诉TensorFlow这个权重的初始值是0.8,但在这个会话里,这个值还没有被设置。tf.global_variables_initializer()函数生成了一个运算,来初始化所有的变量(我们的情况是只有一个变量)。随后我们就可以运行这个运算了。
sess.run(init)
tf.global_variables_initializer()的结果会包括现在图里所有变量的初始化器。所以如果你后续加入了新的变量,你就需要再次使用tf.global_variables_initializer()。一个旧的init是不会包括新的变量的。
现在我们已经准备好运行output_value运算了。
运算结果为:0.80000001
0.8 * 1.0是一个32位的浮点数,而32位浮点数一般不会是0.8。0.80000001是系统可以获得的一个近似值。
7.7.3 TensorBoard可视化你的图
到目前为止,我们的图是很简单的,但是能看到她的图形表现形式也是很好的。我们用TensorBoard来生成这个图形。TensorBoard读取存在每个运算里面的名字字段,这和Python里的变量名是很不一样的。我们可以使用这些TensorFlow的名字,并转成更方便的Python变量名。这里tf.multiply和我前面使用*来做乘运算是等价的,但这个操作可以让我们设置运算的名字。
w = tf.Variable(0.8, name='weight')
y = tf.multiply(w, x, name='output')
TensorBoard是通过查看一个TensorFlow会话创建的输出的目录来工作的。我们可以先用一个summary.FileWriter来写这个输出。如果我们只是创建一个图的输出,它就将图写出来。
构建summary.FileWriter的第一个参数是一个输出目录的名字。如果此目录不存在,则在构建summary.FileWriter时会被建出来。
现在我们可以通过命令行来启动TensorBoard了。
TensorBoard会运行一个本地的Web应用,端口6006(6006是goog这个次倒过的对应)。在你本机的浏览器里登陆IP:6006/#graphs,你就可以看到在TensorFlow里面创建的图,类似于图7.4

图7.4 在TensorBoard里可视化的一个最简单的TensorFlow的神经元
7.7.4训练神经元
我们已经有了一个神经元,但如何才能让它学习?假定我们让输入为1,而正确的输出应该是0。也就是说我们有了一个仅有一条记录且记录只有一个特征(值为1)和一个结果(值为0)的训练数据集。我们现在希望这个神经元能学习这个1->0的函数。
目前的这个系统是输入1而输出0.8。但不是我们想要的。我们需要一个方法来测量系统误差是多少。我们把对误差的测量称为“损失”,并把损失最小化设定为系统的目标。损失是可以为负值的,而对负值进行最小化是毫无意思的。所以我们用实际输出和期望输出之差的平方来作为损失的测量值。
loss = (y - y_)**2
对此,现有的图还不能做什么事情。所以我们需要一个优化器。这里我们使用梯度下降优化器来基于损失值的导数去更新权重。这个优化器采用一个学习率来调整每一步更新的大小。这里我们设为0.025。
这个优化器很聪明。它自动地运行,并在整个网络里恰当地设定梯度,完成后向的学习过程。让我们看看我们的简单例子里的梯度是什么样子的。
那么compute_gradients可能会返回(None,v),即部分变量没有对应的梯度,在下一步的时候NoneType会导致错误。因此,需要将有梯度的变量提取出来,记为grads_vars。
之后,对grads_vars再一次计算梯度,得到了gradient。
sess.run(tf.global_variables_initializer())
sess.run(gradient)
运行结果为:[(1.6, 0.80000001)]
为什么梯度值是1.6?我们的损失函数是错误的平方,因此它的导数就是这个错误乘2。现在系统的输出是0.8而不是0,所以这个错误就是0.8,乘2就是1.6。优化器是对的!
对于更复杂的系统,TensorFlow可以自动地计算并应用这些梯度值。
让我们运用这个梯度来完成反向传播。
sess.run(optim.apply_gradients(grads_and_vars))
sess.run(w)
运行结果为:0.75999999,约为0.76
现在权重减少了0.04,这是因为优化器减去了梯度乘以学习比例(1.6*0.025)。权重向着正确的方向在变化。
其实我们不必像这样调用优化器。我们可以形成一个运算,自动地计算和使用梯度:train_step。
for i in range(100):
sess.run(train_step)
sess.run(y)
运算结果为:0.0047364226
通过100次运行训练步骤后,权重和输出值已经非常接近0了。这个神经元已经学会了!
7.7.5可视化训练过程
在TensorBoard里显示训练过程的分析,你可能对训练过程中发生了什么感兴趣,比如我们想知道每次训练步骤后,系统都是怎么去预测输出的。为此,我们可以在训练循环里面打印输出值。
for i in range(100):
print('before step {}, y is {}'.format(i, sess.run(y)))
sess.run(train_step)
运行结果:
before step 0, y is 0.800000011920929
before step 1, y is 0.7599999904632568
before step 2, y is 0.722000002861023
before step 3, y is 0.6858999729156494
....................................................................
before step 95, y is 0.006121140904724598
before step 96, y is 0.005815084092319012
before step 97, y is 0.005524329841136932
before step 98, y is 0.005248113535344601
before step 99, y is 0.004985707812011242
这种方法可行,但是有些问题。看懂一串数字是比较难的,能用一个图来展示就好了。仅仅就这一个需要观察的值,就有很多输出要看。而且我们希望能观察多个值。如果能用一个一致统一的方法来记录所有值就好了。
幸运的是,上面我们用来可视化图的工具也有我们需要的这个功能。
我们通过加入能总结图自己状态的运算来提交给计算图。这里我们会创建一个运算,它能报告y的当前值,即神经元的输出。
当你运行一个总结运算,它会返回给一个protocal buffer文本的字符串。用summary.FileWriter可以把这个字符串写入一个日志目录。
sess.run(tf.global_variables_initializer())
for i in range(100):
summary_str = sess.run(summary_y)
summary_writer.add_summary(summary_str, i)
sess.run(train_step)
在运行命令 tensorboard --logdir="./log/simple_stats"后,你就可以在IP:6006里面看到一个可交互的图形(如图7.5所示)。
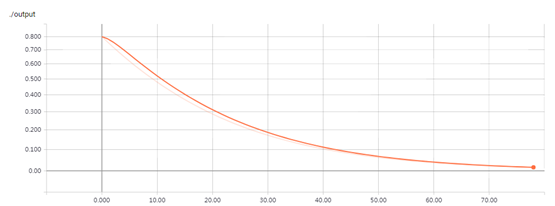
图7.5 TensorBoard里的可视化图,显示了一个神经元的输出和训练循环次数的关系。
7.7.6小结
下面是代码的完全版。它相当的小。但每个小部分都显示了有用且可理解的TensorflowFlow的功能。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import tensorflow as tf x = tf.constant(1.0, name='input') w = tf.Variable(0.8, name='weight') y = tf.multiply(w, x, name='output') y_ = tf.constant(0.0, name='correct_value') loss = tf.pow(y - y_, 2, name='loss') train_step = tf.train.GradientDescentOptimizer(0.025).minimize(loss) for value in [x, w, y, y_, loss]: tf.summary.scalar(value.op.name, value) summaries = tf.summary.merge_all() sess = tf.Session() summary_writer = tf.summary.FileWriter('./log/simple_stats', sess.graph) sess.run(tf.global_variables_initializer()) for i in range(100): summary_str = sess.run(summaries) summary_writer.add_summary(summary_str, i) sess.run(train_step) |
我们这里所演示的例子甚至比非常简单。能看到这样具体的例子可以帮助理解,还可以从简单的砖头开始使用并扩展构建更为复杂的系统。
如果你想继续实践TensorFlow,可以从构建更有趣的神经元开始,或许可以使用不同的激活函数。你也可以用更有趣的数据来训练。继续添加更多的神经元,或者更多的层级。你可以查看更复杂的预制的模型,或学习TensorFlow的教程与如何使用它手册。去学吧!
参考:https://www.oreilly.com/learning/hello-tensorflow
7.8TensorFlow常用函数
TensorFlow函数有很多,有不同类别的,如数据类型转换、变量定义、激活函数、卷积函数等等,这里我们选择一些常用或本章后续用到的一些函数,供大家参考。

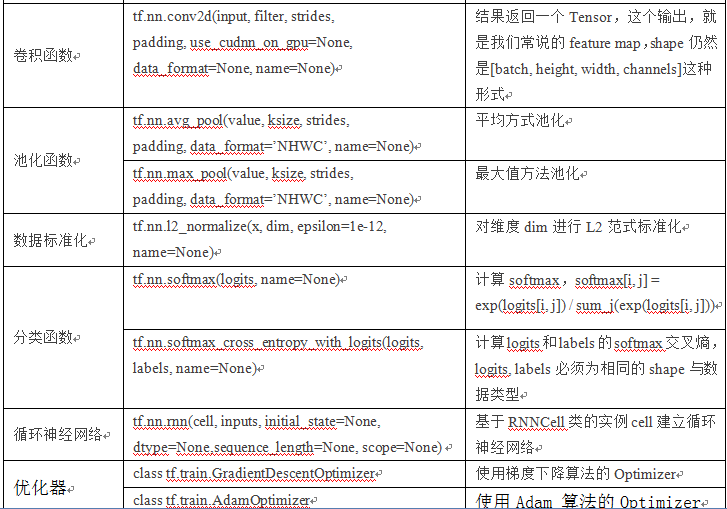
表7.6 TensorFlow常用函数
7.9TensorFlow的运行原理
TensorFlow有一个重要组件client,即客户端,此外,还有master、worker,这些有点类似Spark的结构。它通过Session的接口与master及多个worker相连,其中每一个worker可以与多个硬件设备(device)相连,比如CPU或GPU,并负责管理这些硬件。而master则负责管理所有worker按流程执行计算图。
TensorFlow有单机模式和分布式模式两种实现,其中单机指client、master、worker全部在一台机器上的同一个进程中;分布式的版本允许client、master、worker在不同机器的不同进程中,同时由集群调度系统统一管理各项任务。下图(图7.6)所示为单机版和分布式版本的实现原理图。
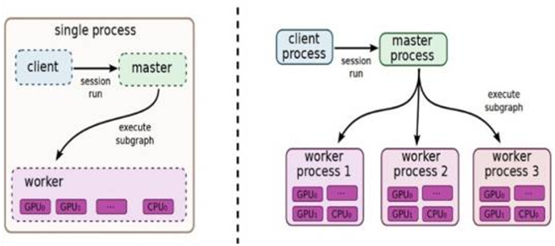
图7.6 TensorFlow 单机版本和分布式运行原理
7.10TensorFlow系统架构
图7.7 是TensorFlow的系统架构,从底向上分为设备管理和通信层、数据操作层、图计算层、API接口层、应用层。其中设备管理和通信层、数据操作层、图计算层是TensorFlow的核心层。
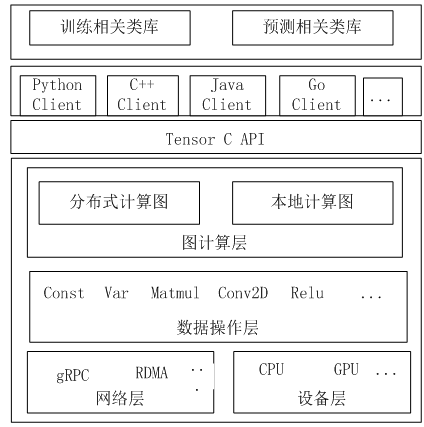
图7.7 TensorFlow 系统架构
底层设备通信层负责网络通信和设备管理
设备管理可以实现TensorFlow设备异构的特性,支持CPU、GPU、Mobile等不同设备。 网络通信依赖gRPC通信协议实现不同设备间的数据传输和更新。
第二层为数据操作层实现
这些OP以Tensor为处理对象,依赖网络通信和设备内存分配,实现了各种Tensor操 作或计算。OP不仅包含MatMul等计算操作,还包含Queue等非计算操作。
第三层是图计算层(Graph),包含本地计算流图和分布式计算流图的实现
Graph模块包含Graph的创建、编译、优化和执行等部分,Graph中每个节点都是OP 类型表示。
第四层是API接口层
Tensor C API是对TensorFlow功能模块的接口封装,便于其他语言平台调用。
第四层以上是应用层
不同编程语言在应用层通过API接口层调用TensorFlow核心功能实现相关应用。
这样的博客让人禁不住一天来几次!
这样精彩的博客越来越少咯!
谢谢您的鼓励
一言不发岂能证明我来过了?!
谢谢!欢迎常来看看
Pingback引用通告: Python与人工智能 – 飞谷云人工智能