第1章 机器学习简介
大数据、人工智能是目前大家谈论比较多的话题,它们的应用也越来越广泛、与我们的生活关系也越来越密切,影响也越来越深远,其中很多已进入寻常百姓家,如无人机、网约车、自动导航、智能家电、电商推荐、人机对话机器人等等。
大数据是人工智能的基础,而使大数据转变为知识或生产力,离不开机器学习(Machine Learning),可以说机器学习是人工智能的核心,是使机器具有类似人的智能的根本途径。
本章主要介绍机器有关概念、与大数据、人工智能间的关系、机器学习常用架构及算法等,具体如下:
- 机器学习的定义
- 大数据与机器学习
- 机器学习与、人工智能及深度学习
- 机器学习的基本任务
- 如何选择合适算法
- Spark在机器学习方面的优势
1.1机器学习的定义
机器学习是什么?是否有统一或标准定义?目前好像没有,即使在机器学习的专业人士,也好像没有一个被广泛认可的定义。在维基百科上对机器学习有以下几种定义:
“机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。
“机器学习是对能通过经验自动改进的计算机算法的研究”。
“机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。”
一种经常引用的英文定义是:A computer program is said to learn from experience (E) with respect to some class of tasks( T) and performance(P) measure , if its performance at tasks in T, as measured by P, improves with experience E。
可以看出机器学习强调三个关键词:算法、经验、性能,其处理过程如下图所示。 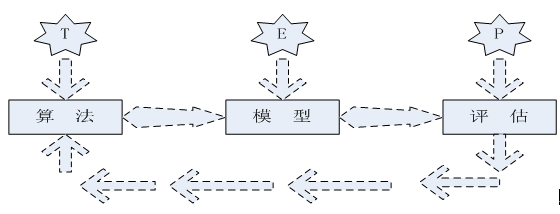
图1.1 机器学习处理流程
图1.1表明机器学习是使数据通过算法构建出模型,然后对模型性能进行评估,评估后的指标,如果达到要求就用这个模型测试新数据,如果达不到要求就要调整算法重新建立模型,再次进行评估,如此循环往复,最终获得满意结果。
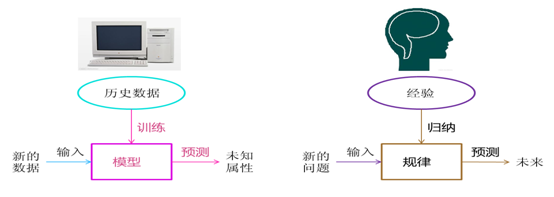
1.2大数据与机器学习
我们已进入大数据时代,产生数据的能力空前高涨,如互联网、移动网、物联网、成千上万的传感器、穿戴设备、GPS等等,存储数据、处理数据等能力也得到了几何级数的提升,如Hadoop、Spark技术为我们存储、处理大数据提供有效方法。
数据就是信息、就是依据,其背后隐含了大量不易被我们感官识别的信息、知识、规律等等,如何揭示这些信息、规则、趋势,正成为当下给企业带来高回报的热点。其中数据是重要考量,在某个方面来说,数据比算法重要,数据犹如经验。
1.3 机器学习、人工智能及深度学习
人工智能和机器学习这两个科技术语如今已经广为流传,已成为当下的热词,
然而,他们间有何区别?又有哪些相同或相似的地方?虽然人工智能和机器学习高度相关,但却并不尽相同。
人工智能是计算机科学的一个分支,目的是开发一种拥有智能行为的机器,目前
很多大公司都在努力开发这种机器学习技术。他们都在努力让电脑学会人类的行为模式,
以便推动很多人眼中的下一场技术革命——让机器像人类一样“思考”。
过去10年,机器学习已经为我们带来了无人驾驶汽车、实用的语音识别、有效的网络搜索等等。接下来人工智能将如何改变我们的生活?在哪些领域最先发力?我们拭目以待。
对很多机器学习来说,特征提取不是一件简单的事情。在一些复杂问题上,
要想通过人工的方式设计有效的特征集合,往往要花费很多的时间和精力。
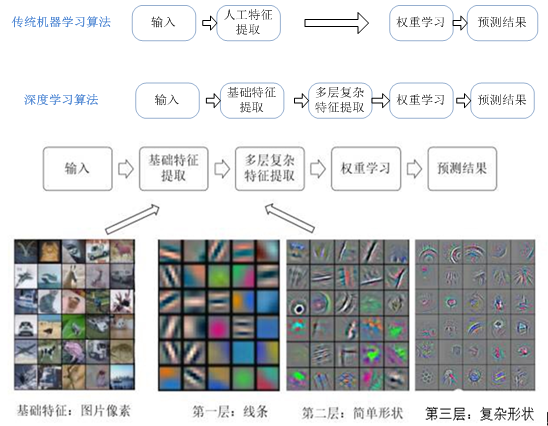
图1.2 机器学习与深度学习流程对比
深度学习解决的核心问题之一就是自动地将简单的特征组合成更加复杂的特征,并利用这些组合特征解决问题。深度学习是机器学习的一个分支,它除了可以学习特征和任务之间的关联以外,还能自动从简单特征中提取更加复杂的特征。图1.2 中展示了深度学习和传统机器学习在流程上的差异。如图1.2 所示,深度学习算法可以从数据中学习更加复杂的特征表达,使得最后一步权重学习变得更加简单且有效。
前面我们分别介绍了机器学习、人工智能及深度学习,它们间的关系如何?
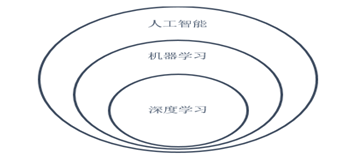
图1.3 人工智能、机器学习与深度学习间的关系
人工智能、机器学习和深度学习是非常相关的几个领域。图1.3说明了它们之间大致关系。人工智能是一类非常广泛的问题,机器学习是解决这类问题的一个重要手段,深度学习则是机器学习的一个分支。在很多人工智能问题上,深度学习的方法突破了传统机器学习方法的瓶颈,推动了人工智能领域的快速发展。
1.4 机器学习的基本任务
机器学习基于数据,并以此获取新知识、新技能。它的任务有很多,分类是其基本任务之一,分类就是将新数据划分到合适的类别中。分类一般用于目标特征为类别型,如果目标特征为连续型,我们往往采用回归方法,回归对新进行预测,回归是机器学习中使用非常广泛的方法之一。
分类和回归,都是先根据标签值或目标值建立模型或规则,然后利用这些带有目标值的数据形成的模型或规则,对新数据进行识别或预测。这两种方法都属于监督学习。与监督学习相对是无监督学习,无监督学习不指定目标值或预先无法知道目标值,它可以将把相似或相近的数据划分到相同的组里,聚类就是解决这一类问题的方法之一。
除了监督学习、无监督学习这两种最常见的方法外,还有半监督学习、强化学习等方法,这里我们就不展开了,下图形为这些基本任务间的关系。
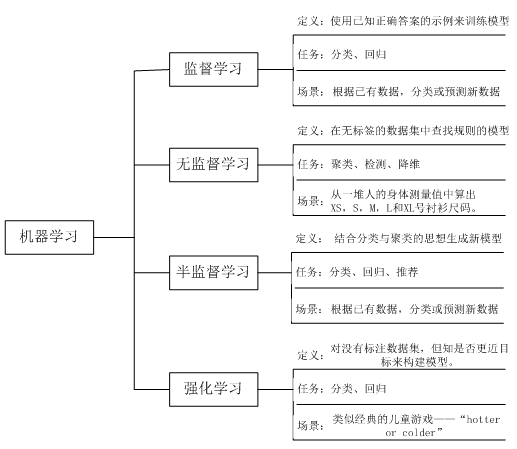
图1.4 机器学习基本任务
1.5 如何选择合适算法
在讲如何选择机器学习算法之前,我们先简单介绍一下机器常用方法,重点介绍算法核心思想、优缺点及模式图示等方面的内容,具体可参考下图:
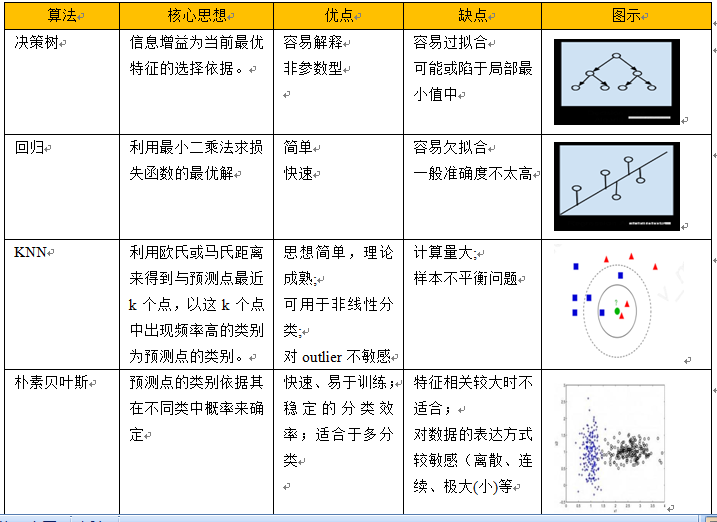
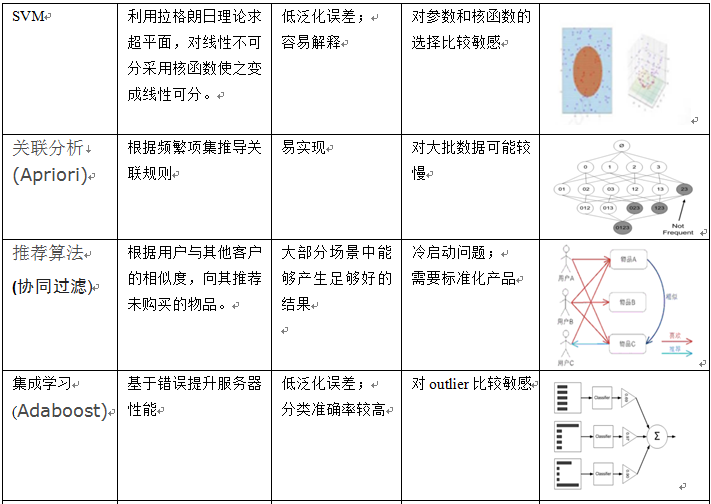
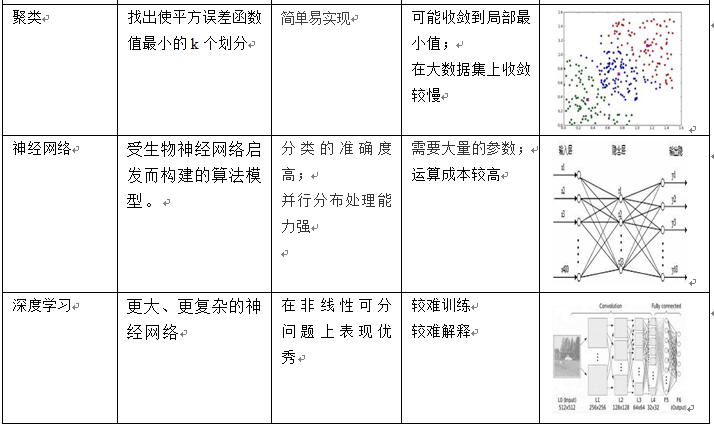 当我们接到一个数据分析或挖掘的任务或需求时,如果希望用机器学习来处理,首要任务是根据任务或需求选择合适算法,选择哪种算法较合适?分析的一般步骤为:
当我们接到一个数据分析或挖掘的任务或需求时,如果希望用机器学习来处理,首要任务是根据任务或需求选择合适算法,选择哪种算法较合适?分析的一般步骤为: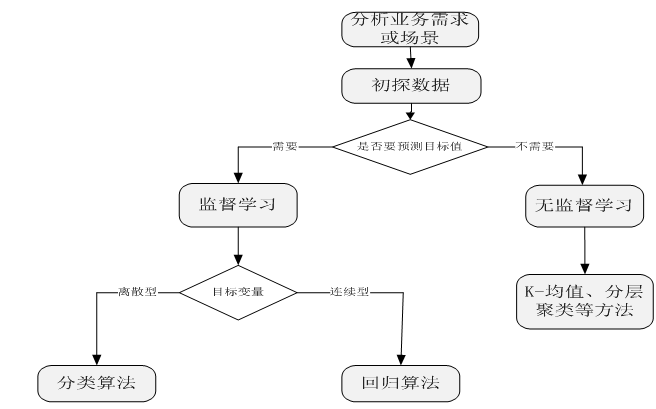
图1.5 选择算法的一般步骤
充分了解数据及其特性,有助于我们更有效地选择机器学习算法。采用以上步骤在一定程度上可以缩小算法的选择范围,使我们少走些弯路,但在具体选择哪种算法方面,一般并不存在最好的算法或者可以给出最好结果的算法,在实际做项目的过程中,这个过程往往需要多次尝试,有时还要尝试不同算法。不过先用一种简单熟悉的方法,然后,在这个基础上不断优化,时常能收获意想不到的效果。
1.6机器学习常用术语
为更好说明机器学习中一些常用术语,我们以一个预测天气的示例来说明,通过具体数据来介绍一些概念,可能比单纯定义来得更具体一些。
假如我们有一组天气数据,是来自全世界不同国家和地区的每日天气,内容包括最高温度、最低温度、平均湿度、风速之类的相关数据,例如数据的一部分是这样的:
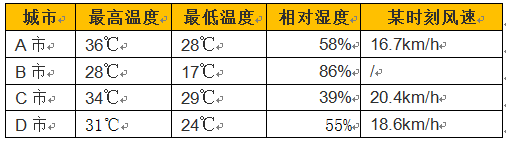
在这组数据中,我们将称A市、B市、C市、D市等以及温度、湿度等情况的总和称为数据集(data set)。表格中的每一行,也就是某城市和它的对应的情况被称为一个样本(sample/instance)。表格中的每一列,例如最高温度、最低温度,被称为特征(feature/attribute),而每一列中的具体数值,例如36℃ 、28℃,被称为属性值(attribute value)。数据中也可能会有缺失数据(missing data),例如B市的某时刻风速,我们会将它视作缺失数据。
如果我们想预测城市的天气,例如是晴朗还是阴雨天,这些数据是不够的,除了特征以外,我们还需要每个城市的具体天气情况,也就是通常语境下的结果。在机器学习中,它会被称为标签(label),用于标记数据。值得注意的是,数据集中不一定包含标签信息,而这种区别会引起方法上的差别。我们可以给上述示例加上一组标签:
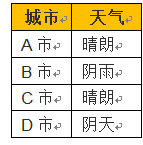
在机器学习中,数据集又可以分为三类:训练集(Training Set )、测试集(Testing Set)和交叉验证集(Cross-Validation Set)。 顾名思义,训练集在机器学习的过程中,用来训练我们模型的部分;而测试集用评估、测试模型泛化能力的部分;交叉验证集它是用来调整模型具体参数的数据集。
根据数据有没有标签,我们可以把机器学习分类为监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)和强化学习(Reinforcement Learning)。
监督学习是学习给定标签的数据集,比如说有一组气候数据,给出他们的详细资料,将它们作为判断或预测天气是晴天还是阴雨等标签的依据,然后预测明天是否会下雨,就是一种典型的监督学习。监督学习中也有不同的分类,如果我们训练的结果是阴雨、晴天之类离散的类型,则称为分类(Classification),如果只有两种类型的话可以进一步称为二分类(Binary Classification);如果我们训练的结果是下雨的概率为0.87之类连续的数字,则称为回归(Regression)。
无监督学习是学习没有标签的数据集,比如在分析大量语句之后,训练出一个模型将较为接近的词分为一类,而后可以根据一个新的词在句子中的用法(和其他信息)将这个词分入某一类中。其中比较微妙的地方在于,这种问题下使用聚类(Clustering)(方法)所获得的簇(Cluster)(结果),有时候是无法人为地观察出其特征的,但是在得到聚类后,可能会对数据集有新的启发。
强化学习是构建一个系统,在与环境交互的过程中提高系统的性能。环境的当前状态信息中通常包含一个反馈信号,这个反馈值不是一个确定的类标或连续类型的值,而是通过反馈函数产生的对当前系统行为的评价。通过探索性的试错或者借助精心设计的激励系统使得正向反馈最大化。象棋或围棋对弈就是一个常见的强化学习例子。下图为强化学习系统原理示意图:
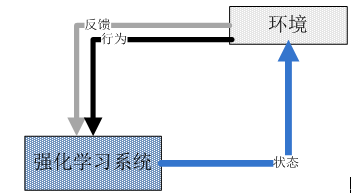
对模型性能的评估,或对其泛化能力的评估,往往是一项重要内容。对分类问题我们通常利用准确率、ROC曲线等指标进行评估;对回归类模型,我们通常均方误差(MSE)、均方根误差(RMSE)等指标来确定模型的精确性。
但值得注意的是,模型并不是误差越小就一定越好,因为如果仅仅基于误差,我们可能会得到一个过拟合(Overfitting)的模型;但是如果不考虑误差,我们可能会得到一个欠拟合(Underfitting)的模型,用图像来说的话大致可以这样理解:
如果模型十分简单,往往会欠拟合,对于训练数据和测试数据的误差都会很大;但如果模型太过于复杂,往往会过拟合,那么训练数据的误差可能相当小,但是测试数据的误差会增大。所以需要“驰张有度”,找到最好的那个平衡点。
如果出现过拟合或欠拟合,有哪些解决方法呢?
1、对于欠拟合,一般可考虑提高数据质量、规范特征、增加新特征或训练数据量等方法;采用交叉验证及网格搜索参数等方法调优超参数(不是通过算法本身学习出来的参数,如迭代步数、树高度、步长等);采用其它算法如集成算法等等。
2、对于过拟合问题,可以考虑引入正则化,正则化指修改算法,使其降低泛化误差(而非降低训练误差);对于维数较大的情况,采用PCA降维也是选项之一。
在模型训练过程中,泛化误差不会随着模型复杂度趋于0,相反它一般呈现U型曲线,但训练误差一般训练复杂度增强而变小,直至趋于0。具体关系我们可以参考下图:
聚类问题的标准一般基于距离:簇内距离(Intra-cluster Distance)和簇间距离(Inter-cluster Distance)。根据常识而言,簇内距离是越小越好,也就是簇内的元素越相似越好;而簇间距离越大越好,也就是说簇间(不同簇)元素越不相同越好。
Pingback引用通告: 大数据、人工智能快速入门 – 飞谷云人工智能
Pingback引用通告: Python与人工智能 – 飞谷云人工智能