文章目录
第4章 TensorFlow数据处理
在机器学习、深度学习的实际项目中,由于数据都是真实数据,这些数据可能涉及多个来源地,存在大量不统一、不规范、缺失,甚至错误的数据,因此,在实际项目中,数据处理环节的挑战很大,往往占据大部分时间,且这个环节的输出质量直接影响模型的性能。
面对这个棘手问题,TensorFlow为我们提供了有效解决方法,这就是tf.data这个API。使用TensorFlow 2.0提供的tf.data可以有效进行数据预处理,同时通过构建数据流或数据管道,大大提高开发效率及数据质量。本章主要涉及如下内容:
♦ tf.data简介
♦ 构建Dataset的常用方法
♦ 如何生成自己的TFRecord数据
♦ 数据增强方法
4.1 tf.data简介
tf.data是TensorFlow提供的构建数据管道的一个工具,与PyTorch的utils.data类似。使用tf.data构建数据集(Dataset),可以使构建和管理数据管道更加方便。
tf.data API的结构如图4-1所示,最上边为Dataset基类,实例化为Iterator。TextLineDataset(处理文本)、TFRecordDataset(处理存储于硬盘的大量数据,不进行内存读取)、FixedLengthRecordDataset(二进制数据的处理)继承自Dataset,这几个类的方法大体一致,主要包括数据读取、元素变换、过滤,数据集拼接、交叉等。Iterator是Dataset中迭代方法的实例化,主要用于对数据进行访问。它有单次、可初始化、可重新初始化、可馈送等4种迭代方法,可实现对数据集中元素的快速迭代,供模型训练使用。因此,只要掌握Dataset以及Iterator的方法,即可清楚TensorFlow的数据读取方法。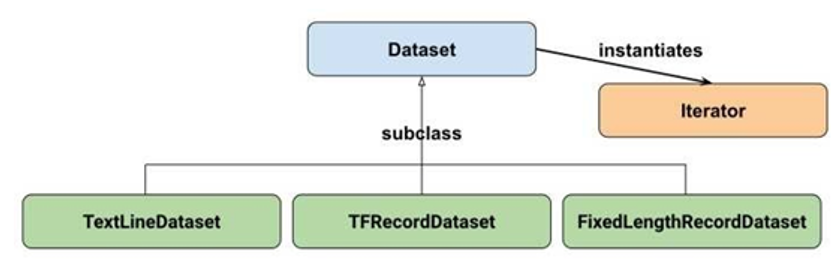
图4-1 tf.data API的架构图
接下来主要介绍Dataset的基本属性、创建方法,Iterator的使用等内容。
4.2 构建数据集的常用方法
tf.data.Dataset表示一串元素(element),其中每个元素包含一个或多个Tensor对象。例如:在一个图像流水线(pipeline)中,一个元素可以是单个训练样本,它们带有一个表示图像数据的张量和一个标签组成的数据对(pair)。有两种不同的方式构建一个数据集,具体如下。
直接从 Tensor 创建数据集(例如 Dataset.from_tensor_slices());当然 NumPy 也是可以的,TensorFlow 会自动将其转换为 Tensor。
通过对一个或多个 tf.data.Dataset 对象的变换(例如 Dataset.batch())来创建数据集。
这两类构建方法又可以进一步分为7种方法,如表4-1所示。
表4-1 构建数据集的常用方法
| 数据格式 | 读取方法 | 备注 |
| 从NumPy数组读取 | tf.data.Dataset.from_tensor_slices | 当数据较小时 |
| 从Python Generator读取 | tf.data.Dataset.from_generator | |
| 从文本数据读取 | tf.data.TextLineDataset | |
| 从CSV数据读取 | tf.data.experimental.CsvDataset | |
| 从 TFRecord data读取 | tf.data.TFRecordDataset | TFRecord 是TensorFlow中自带的,它是一种方便储存比较大的数据集的数据格式(二进制格式),当内存不足时,我们可以将数据集制作成TFRecord格式的再将其解压读取。 |
| 从二进制文件读取数据 | tf.data.FixedLengthRecordDataset | |
| 从文件集中读取数据 | tf.data.Dataset.list_files() |
1)直接从内存中读取(如NumPy数据),可使用tf.data.Dataset.from_tensor_slices()。
2)使用一个 Python 生成器 (Generator) 初始化,从生成器中读取数据可以使用tf.data.Dataset.from_generator()。
3)读取文本数据,可使用tf.data.TextLineDataset()。
4)读取cvs数据,可使用tf.data.experimental.make_csv_dataset()。
5)从TFrecords格式文件读取数据,可使用tf.data.TFRecordDataset()。
6)从二进制文件读取数据,可用tf.data.FixedLengthRecordDataset()。
7)从文件集中读取数据,可使用tf.data.Dataset.list_files()。
4.2.1 从内存中读取数据
从内存中读取数据的方法适用于数据较少,可直接存储于内存中的情况,其主要包括tf.data.Datasets.from_tensor_slices方法和tf.data.Datasets..from_generator(从生成器读取)方法。它从内存中读取数据,输入参数可以是NumPy的多维数组,也可以是TensorFlow的张量,还可以是Python的列表(list)、元祖以及字典等。
1.从NumPy中读取数据
如果输入数据为NumPy或tf.Tensor,可使用 Dataset.from_tensor_slices()读取。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import tensorflow as tf import numpy as np # 从NumPy数组构建数据集 dataset1 = tf.data.Dataset.from_tensor_slices(np.arange(10)) print(dataset1) # #从张量中读取数据 dataset2 = tf.data.Dataset.from_tensor_slices(tf.constant([1,2,3,4])) print(dataset2) # |
2. 从迭代器中读取数据
可以读取NumPy、张量数据,也可以读取迭代器中的数据。迭代器中的数据虽然也在内存中,但所耗的资源较小。在使用tf.data.Dataset.from_generator()方法构建数据集时,我们需要提供3个参数(generator、output_types、output_shapes),其中generator参数必须支持iter()协议,也就是generator需要具有迭代功能,推荐使用Python yield。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import numpy as np import tensorflow as tf #定义数据生成器函数 def data_generator(): dataset = np.array(range(5)) for d in dataset: yield d ds = tf.data.Dataset.from_generator(data_generator, (tf.int32), (tf.TensorShape([]))) #查看数据 for i in ds: print(i.numpy(),end=",") #运行结果:0,1,2,3,4 |
4.2.2 从文本中读取数据
内存数据一般较小,很多情况下,我们需要加载的数据保存在文本文件中,比如日志文件。tf.data.TextLineDataset可以帮助我们从文本文件中读取数据,源文件中(比如日志信息)的一行代表一个样本。 tf.data.TextLineDataset 的方法签名为:tf.data.TextLineDataset(filenames, compression_type=None, buffer_size=None, num_parallel_reads=None) ,其中:
• filenames :一系列将要读取的文本文件的路径+名字。
• compression_type :文件的压缩格式,tf.data.TextLineDataset可以从压缩文件中直接读取数据或者将数据写入压缩文件中以节省磁盘空间。它的默认值是None,表示不压缩。
• buffer_size :一次读取的字节数量,如果不指定,则将由TensorFlow根据一定策略选择。
• num_parallel_reads :如果有多个文件需要读取,用num_parallel_reads可以指定同时读取文件的数量。默认情况下按照文件顺序一个一个读取。
为了演示通过TextLineDataset读取数据的过程,这里以一个数据文件(test.txt)为例。
|
1 2 3 4 5 |
import tensorflow as tf ds_txt = tf.data.TextLineDataset(filenames = ["./data/test.txt"] ).skip(1) # 忽略掉第一行,第一行为标题 for line in ds_txt.take(2): print(line) |
运行结果如下:
tf.Tensor(b'Suzhou, JiangSu, 1', shape=(), dtype=string)
tf.Tensor(b'Wuxi, JiangSu, 0', shape=(), dtype=string)
实际上,csv文件也是一个文本文件,TextLineDataset也可以读取csv文件的数据,但是根据上面的例子我们知道,tf.data.TextLineDataset会将文件中的每一行数据读成一个张量,如果我们想保留csv文件中数据的结构(比如第一列代表了什么,第二列代表了什么),可以使用tf.data.experimental.make_csv_dataset函数。这里以泰坦尼克生存预测数据为例进行简单说明,第一行为标题。
|
1 2 3 4 5 6 7 8 9 10 |
import tensorflow as tf ds4 = tf.data.experimental.make_csv_dataset( file_pattern = ["./data/train.csv"], batch_size=2, na_value="", ignore_errors=True) for data in ds4.take(2): print(data) |
此外,可以指定在读取数据时只读取我们感兴趣的列,通过传入参数select_columns 来实现。
在train.csv文件中,survived列是标签数据。可以通过指定label_name来分离样本数据和标签数据。
4.2.3 读取TFrecord格式文件
TFRecord 是 TensorFlow 自带的一种数据格式,是一种二进制文件。它是TensorFlow 官方推荐的数据保存格式,其数据的存储、读取操作更加高效。具体来说,TFRecord的优势可概括为:
1)支持多种数据格式;
2)更好的利用内存,方便复制和移动;
3)将二进制数据和标签(label)存储在同一个文件中。
TFRecord 格式文件的存储形式会很合理地帮我们存储数据。TFRecord 内部使用了 Protocol Buffer 二进制数据编码方案,它只占用一个内存块,只需要一次性加载一个二进制文件的方式即可,简单,快速,尤其对大型训练数据很友好。当我们的训练数据量比较大的时候,TFRecord可以将数据分成多个 TFRecord 文件,以提高处理效率。
假设有一万张图像, TFRecord 可以将其保存成 5 个.tfrecords 文件(具体保存成几个文件,要看文件大小),这样我们在读取数据时,只需要进行5 次数据读取。如果把这一万张图像保存为NumPy格式数据,则需要进行10000次数据读取。
我们可以使用tf.data.TFRecordDataset类读取TFRecord文件。
|
1 2 3 4 5 6 7 8 |
import os input_path="./data/" ds = tf.data.TFRecordDataset([os.path.join(input_path, 'records')]) # 如果需要读取压缩文件,值需要指定compression_type # ds = tf.data.TFRecordDataset([os.path.join(output_dir, 'records')], compression_type='GZIP') print(ds) ## |
TFRecord格式非常高效,接下来我们将详细介绍如何把自己的数据转换为TFRecord格式的数据,以及转换的具体步骤等内容。
4.3 如何生成自己的TFRecord格式数据
上节我们介绍了TFRecord格式的一些优点,那么,如何把一般格式的数据,如图像、文本等格式数据,转换为TFRecord格式数据呢?这里通过介绍一个把有关小猫和小狗的jpg格式的图像转换为TFRecord文件,然后读取转换后的数据的例子,帮助你了解如何生成自己的TFRecord格式数据。
4.3.1 把数据转换为TFRecord格式的一般步骤
把非TFRecord格式数据转换为TFRecord格式数据的一般步骤,如图4-2所示。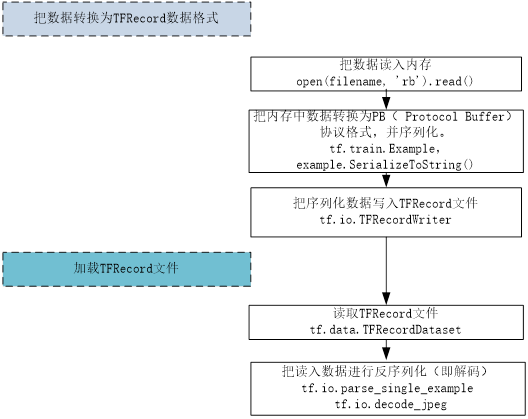
图4-2 转换成TFRecord格式的一般步骤
在数据转换过程中,Example是TFReocrd的核心,TFReocrd包含一系列Example,每个Example可以认为是一个样本。Example是Tensorflow的对象类型,可通过tf.train.example来使用。
Example含义: 如表4-2所示,假设有样本(x,y) :输入x 和 输出y一起叫作样本。这里每个x是六维向量,每个y是一维向量。
1)表征 (representation):x集合了代表个人的全部特征。其中特征 (feature):x中的某个维度:如学历,年龄,职业。是某人的一个特点。
2)标签 (label):y为输出。
表4-2 一个样本格式
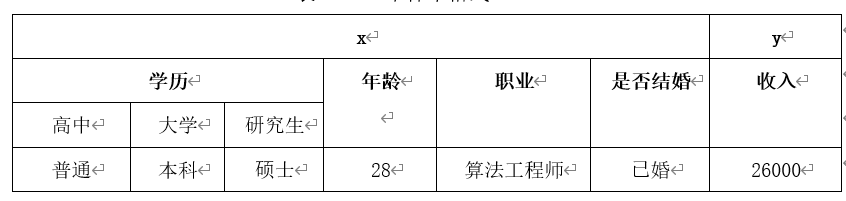
要存储表4-2中的数据,通常我们把输入表征x与标签y分开进行保存。假设有100个样本,把所有输入存储在100x6的numpy矩阵中,把标签存储在100x1的向量中。
Example协议块格式如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
message Example { Features features = 1; }; message Features { map<string, Feature> feature = 1; }; message Feature { one of kind { BytesList bytes_list = 1; FloatList float_list = 2; Int64List int64_list = 3; } }; |
以TFRecord方式存储,输入和标签将以字典方式存放在一起,具体格式如图4-3所示。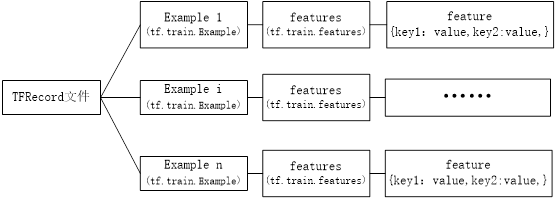
图4-3 TFRecord文件的存储格式
4.3.2 加载TFRecord文件流程
生成TFRecord文件后,我们可以通过tf.data来生成一个迭代器,设置每次调用都返回一个大小为batch_size的batch。可以通过TensorFlow的两个重要的函数读取TFRecord文件,如图4-4所示,分别是读取器(Reader)tf.data.TFRecordDataset和解码器(Decoder)tf.io.parse_single_example。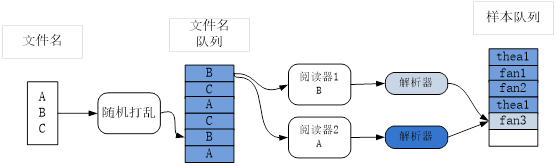
图4-4 加载TFRecord文件流程
4.3.3 代码实现
生成TFRecord格式数据的完整过程为:
• 先把源数据(可以是文本、图像、音频、Embedding等,这里是小猫、小狗的图像)导入内存(如NumPy);
• 把内存数据转换为TFRecord格式数据;
• 读取TFRecord数据。
1)导入模块及数据。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import tensorflow as tf import os data_dir = "./data/cat-dog" train_cat_dir = data_dir + '/train/cats/' train_dog_dir = data_dir + "/train/dogs/" train_tfrecord_file = data_dir + "/train/train.tfrecords" test_cat_dir = data_dir + "/test/cats/" test_dog_dir = data_dir + "/test/dogs/" test_tfrecord_file = data_dir + "/test/test.tfrecords" train_cat_filenames = [train_cat_dir + filename for filename in os.listdir(train_cat_dir)] train_dog_filenames = [train_dog_dir + filename for filename in os.listdir(train_dog_dir)] train_filenames = train_cat_filenames + train_dog_filenames train_labels = [0]*len(train_cat_filenames) + [1]*len(train_dog_filenames) test_cat_filenames = [test_cat_dir + filename for filename in os.listdir(test_cat_dir)] test_dog_filenames = [test_dog_dir + filename for filename in os.listdir(test_dog_dir)] test_filenames = test_cat_filenames + test_dog_filenames test_labels = [0]*len(test_cat_filenames) + [1]*len(test_dog_filenames) |
2)把数据转换为TFRecord格式。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
def encoder(filenames, labels, tfrecord_file): with tf.io.TFRecordWriter(tfrecord_file) as writer: for filename, label in zip(filenames, labels): image = open(filename, 'rb').read() # 建立feature字典,这里特征image,label都以向量方式存储 feature = { 'image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image])), 'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[label])) } # 通过字典创建example,example对象对label和image数据进行封装 example = tf.train.Example(features=tf.train.Features(feature=feature)) # 将example序列化并写入字典 writer.write(example.SerializeToString()) encoder(train_filenames, train_labels, train_tfrecord_file) encoder(test_filenames, test_labels, test_tfrecord_file) |
构建Example时,这个tf.train.Feature()函数可以接收3种数据,具体如下。
• bytes_list: 可以存储string 和byte两种数据类型。
• float_list: 可以存储float(float32)与double(float64) 两种数据类型。
• int64_list: 可以存储bool、 enum、int32、uint32、int64、uint64。
对于只有一个值的数据(比如label)可以用float_list或int64_list,而像图像、视频、Embedding这种列表型的数据,通常转化为bytes格式储存。
3)从TFRecord读取数据。这里使用 tf.data.TFRecordDataset类来读取TFRecord文件。TFRecordDataset 对于标准化输入数据和优化性能十分有用。可以使用tf.io.parse_single_example函数对每个样本进行解析(tf.io.parse_example用于对批量样本进行解析)。 注意,这里的 feature_description 是必需的,因为数据集使用计算图方式执行,需要这些描述来构建它们的形状和类型签名。
可以使用 tf.data.Dataset.map 方法将函数应用于数据集的每个元素。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
def decoder(tfrecord_file, is_train_dataset=None): #构建数据集 dataset = tf.data.TFRecordDataset(tfrecord_file) #说明特征的描述属性,用于解码每个样本 feature_discription = { 'image': tf.io.FixedLenFeature([], tf.string), 'label': tf.io.FixedLenFeature([], tf.int64) } def _parse_example(example_string): # 解码每一个样本 #将文件读入到队列中 feature_dic = tf.io.parse_single_example(example_string, feature_discription) feature_dic['image'] = tf.io.decode_jpeg(feature_dic['image']) #对图像进行resize feature_dic['image'] = tf.image.resize(feature_dic['image'], [256, 256])/255.0 #tf.image.random_flip_up_down(image).shape return feature_dic['image'], feature_dic['label'] batch_size = 4 if is_train_dataset is not None: #tf.data.experimental.AUTOTUNE#根据计算机性能进行运算速度的调整 dataset = dataset.map(_parse_example).shuffle(buffer_size=2000).batch(batch_size).prefetch(tf.data.experimental.AUTOTUNE) else: dataset = dataset.map(_parse_example) dataset = dataset.batch(batch_size) return dataset train_data = decoder(train_tfrecord_file, 1) test_data = decoder(test_tfrecord_file) |
4)可视化读取的数据。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import matplotlib.pyplot as plt %matplotlib inline #查看数据集中样本的具体信息 i=1 for image,lable in train_data: plt.subplot(1,2,i) plt.imshow(image[0].numpy()) i+=1 if i==3: break plt.show() |
解码TFRecord数据的示意图如图4-5所示。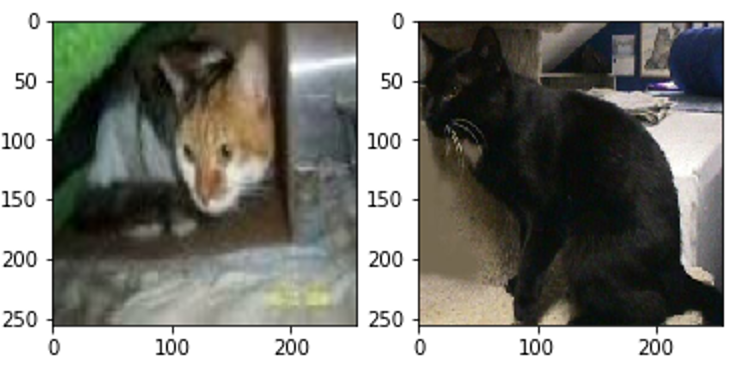
图4-5 解码TFRecord数据的示意图
4.4 数据增强方法
在训练模型时,我们采用的图像数据越多,建立有效、准确的模型的概率就越大。如果没有理想的海量数据,我们应该怎么办呢?此时我们可以采取数据增强方法来增加数据集的大小以及多样性。数据增强(Data Augmentation)是指对图像进行随机的旋转、裁剪、随机改变图像的亮度和对比度以及对数据进行标准化(数据的均值为0,方差为1)等一系列操作。
如图4-6所示,我们可以通过不同的数据增强方法制作出6张标签相同(都是狗)的图,从而增加我们学习的样本。
图4-6通过TensorFlow数据增强方法得到不同状态的图像
4.4.1 常用的数据增强方法
常见的数据增强方法可以分为几何空间变换方法以及像素颜色变换方法两大类。几何空间变换包括对图像进行翻转、剪切、缩放等,像素颜色变换包括增加噪声、进行颜色扰动、锐化、浮雕、模糊等。
在TensorFlow中,我们可以结合使用数据增强方法与数据流水线,通常有以下两种方式:
1)利用TensorFlow的预处理方法定义数据增强函数然后通过Sequential类加以应用;
2)利用tf.image的内置方法手动创建数据增强路由。
相比较而言,第一种方式更加简单,第二种方式相对复杂,但是更加灵活。接下来,我们以第二种方式为例进行演示,顺便探索tf.image为我们提供了哪些便利的函数。我们可以通过dir(tf.image)查看它的内置方法。
之前我们提到,图像的左右翻转可以使用tf.image.flip_left_right或者tf.image.random_flip_left_right来实现,而图像的上下翻转可以使用tf.image.flip_up_down或者tf.image.random_flip_up_down实现。更多的图像转换方法,可以查阅API文档。
下面我们用一个完整的例子来演示如何在Tensorflow流水线中配合使用tf.image来进行数据增强。首先我们定义一个函数来读取图像数据。
1)定义导入数据函数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import tensorflow as tf import matplotlib.pyplot as plt %matplotlib inline def load_images(imagePath): # 从传入的路径中读取图像,并且转换数据成浮点数类型 image = tf.io.read_file(imagePath) image = tf.image.decode_jpeg(image, channels=3) image = tf.image.convert_image_dtype(image, dtype=tf.float32) image = tf.image.resize(image, (156, 156)) # 获得图像名称作为标签 label = tf.strings.split(imagePath, ".")[-2] # 返回图像数据以及标签 return (image, label) |
2)可视化数据增强效果。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 对图像进行上下左右随机的翻转以及调整明亮度,最后旋转图像 imagePath = "./data/dog.jpg" images,labels=load_images(imagePath) fig = plt.gcf() fig.set_size_inches(20, 30) images = tf.image.random_flip_left_right(images) ax_raw1 = plt.subplot(1, 4, 1) ax_raw1.imshow(images) images = tf.image.random_flip_up_down(images) ax_raw2 = plt.subplot(1, 4, 2) ax_raw2.imshow(images) images = tf.image.random_brightness(images, 1) ax_raw3 = plt.subplot(1, 4, 3) ax_raw3.imshow(images) images = tf.image.rot90(images, 1) ax_raw3 = plt.subplot(1, 4, 4) ax_raw3.imshow(images) |
运行结果如图4-7所示。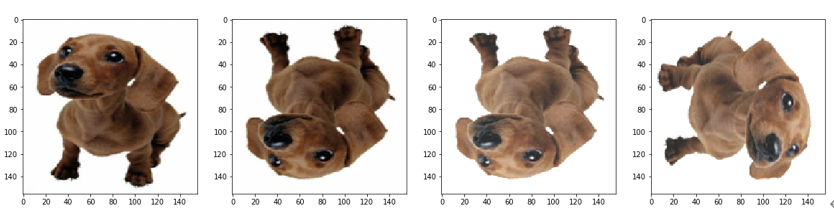
图4-7 通过数据增强方法得到不同位置的图像
3)定义数据增强函数。
|
1 2 3 4 5 6 7 8 9 |
def augment_using_ops(images, labels): # 对图像进行上下左右随机的翻转,调整明亮度最后旋转90度 images = tf.image.random_flip_left_right(images) images = tf.image.random_flip_up_down(images) images = tf.image.random_brightness(images, 1) images = tf.image.rot90(images, 1) # 返回图像和标签 return (images, labels) |
4.4.2 创建数据处理流水线
在把数据应用于深度学习模型训练时,我们往往需要对数据进行各种预处理以满足模型输入参数的需要。tf.data提供了一系列有用的API来帮我们进行数据转换,比较常用的数据转换方法列举如下。
• map: 将(自定义或者TensorFlow定义)转换函数应用到数据集的每一个元素。
• filter:选择数据集中符合条件的一系列元素。
• shuffle: 对数据按照顺序打乱。
• repeat: 将数据集中的数据重复N次,如果没有指定N,重复无限次。
• take: 采样,取从开始起的N个元素。
• batch: 构建批次,每次放一个批次。
具体实现如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
BATCH_SIZE = 8 AUTOTUNE = tf.data.experimental.AUTOTUNE # 输入图像的路径 imagePaths = ["./data/dog.jpg"] # 创建数据输入流水线 ds = tf.data.Dataset.from_tensor_slices(imagePaths) ds = ds.shuffle(len(imagePaths), seed=42).map(load_images,num_parallel_calls=AUTOTUNE).cache().batch(BATCH_SIZE) ds = ds.map(augment_using_ops, num_parallel_calls=AUTOTUNE).prefetch(AUTOTUNE) #放到生成器里,便于单独取出数据 batch = next(iter(ds)) |
为了更加直观地显示出数据增强的效果,我们用matplotlib画出我们做过数据转换后的图像,具体实现如下:
|
1 2 3 4 5 6 7 8 9 |
fig = plt.figure() (image, label) = (batch[0][0], batch[1][0]) ax = plt.subplot() plt.imshow(image.numpy()) print(label.numpy().decode("UTF-8")) plt.title(label.numpy().decode("UTF-8")) plt.axis("off") plt.tight_layout() plt.show() |
经过处理后的图像如图4-8所示。

图4-8 经过处理后的图像
4.5 小结
数据预处理、数据增强等方法是机器学习和深度学习中经常用到的方法,我们在使用这些方法时也会遇到一定的挑战,尤其对于一些不规范的数据,数据预处理显得尤为重要。而数据增强方法是扩充数据量、丰富数据多样性的有效方法。对数据预处理、数据增强,TensorFlow都提供了很多内置方法。