文章目录
一、目标检测的目的和挑战
1、目标检测的目的
目标检测的目的是什么?主要就是:
(1)确定目标对象所在位置及大小;
(2)确定目标对象的类别
第1点是属于检测,第2点识别,重点是检测,目标图像检测后识别与一般图像识别一样。如何检测目标对象?我们可以通过以下图像更形象地进行说明。为简便起见,我们假设图像中只有1个目标对象(或少数几个目标对象),对这个图像进行检测的目标就是,
用矩形框界定目标对象,如下图所示。

图1 目标检测示意图
把要检测的目标用矩阵图框定,然后对框定的目标进行分类,这就是目标检测的主要目标。框定目标并识别目标两个任务中,框定目标是关键。如何框定目标呢?
我们从简单的情况开始,然后,再考虑更复杂的情况。
假设图像中只有一个目标,如图1的左图。这种情况,我们凭直觉最先想到的或许就是使用一个矩形框窗口,从左到右移动,如图2所示。

图2 用一个框进行自左向右移动示意图
这是一种非常理想情况,使用的框大小正好能框,这些候选框确定后,就可以针对每个框使用分类模型计算各框为猫的概率或得分,如图3所示。看哪个框的得分最高就选择哪个框,从图3 可知,中间这个框内容对象为猫的概率最大,故选择这个框(如图1左图所示)。框确定意味着这个框的左上点的坐标(x,y)及这个框的高(h)和宽(w)也确定了。

图3 不同框中对象的概率或得分示意图
当然这是一种非常简单的情况,实际情况往往要复杂的多,挑战更大。
2、目标检测的主要挑战
目标检测的主要挑战可归纳如下:
目标对象位置不定
目标对象有不同大小和形状
对象有多种,同一种也可能有多个
存在遮掩、光照等问题
如何既准又快的完成这些任务
如图13-1 右图所示。对这种情况,当然我们可以使用不同大小的窗口,然后采用移动的方法,这种产生候选框的方法理论上是可行的,但因此而产生的的框将很大,而且这种方法不管图像中有几个对象,都需要如此操作,效率非常低。
为解决这一问题,人们研究了很多方法,目前还在不断更新迭代中。以下我们简介几种典型方法。
二、生成候选框的常用方法
1、选择性搜索方法(SS)
选择性搜索方法(Selective Search,简称SS)如何对图像进行划分呢?它不是通过大小网格的方式,而且通过图像中的纹理、边缘、颜色等信息对图像进行自底向上的分割,然后对分割区域进行不同尺度的合并,每个生成的区域即一个候选区框,如图4所示。这种方法基于传统特征,速度较慢。

图4 使用SS算法生成候选框的示意图
SS算法基本思想为:
(1)首先通过基于图的图像分割方法(Image Segmentation)将图像分割成很多很多的小块;
(2)使用贪心策略,基于相似度(如颜色相似度、尺寸相似度、纹理相似度等)合并一些区域。
2、RPN算法
SS采用传统特征提取方法,而且非常耗时。是否有更有效方法呢?Faster R-CNN算法中提出一种基于神经网络的生成候选框方法,那就是RPN。
RPN(Region Proposal Networks)层用于生成候选框,并利用softmax判断候选框是前景还是背景,从中选取前景候选框(因为物体一般在前景中),并利用bounding box regression调整候选框的位置,从而得到特征子图,称为proposals。
RPN的工作原理:
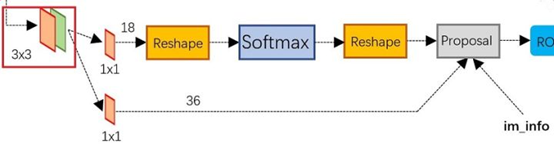
上图展示了RPN网络的具体结构。
首先,经过一次3x3的卷积操作,最后得到了一个channel数目是256的特征图,尺寸和公共特征图相同,我们假设是256 x(H x W)。
然后,经过2条支线:
(1)上面一条支线通过softmax来分类anchors获得前景foreground和背景background(检测目标是foreground),
(2)下面一条支线用于计算anchors的边框偏移量,以获得精确的proposals。
最后的proposal层则负责综合foreground anchors和偏移量获取proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。
这里涉及一个重要概念anchor:简单地说,RPN依靠一个在共享特征图上滑动的窗口,为每个位置生成9种预先设置好长宽比与面积的目标框(即anchor)。这9种初始anchor包含三种面积(128×128,256×256,512×512),每种面积又包含三种长宽比(1:1,1:2,2:1)。示意图如下图所示:
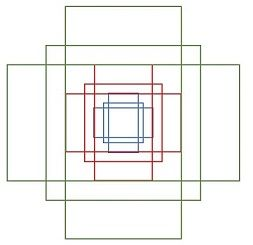
由于共享特征图的大小约为40×60,所以RPN生成的初始anchor的总数约为20000个(40×60×9)。其实RPN最终就是在原图尺度上,设置了密密麻麻的候选anchor。进而去判断anchor到底是前景还是背景,意思就是判断这个anchor到底有没有覆盖目标,以及为属于前景的anchor进行第一次坐标修正。如何实现坐标修正?具体可参考第三部分的边框回归(Bounding Box Regression)。
3、anchor概述
RPN的目标是代替Selective Search实现候选框的提取,目标检测的实质是对候选框的回归,而网络不可能自动生成任意大小的候选框,因此Anchor的主要意义就在于根据feature map在原图片上划分出很多大小、宽高比不相同的矩形框,RPN会对这些框进行一个粗略的分类(如是否存在目标对象)和回归,选取一些微调过的包含前景的正类别框以及包含背景的负类别框,送入之后的网络结构参与训练。
Anchor的产生过程:
(1)base_size=16 这个参数代表的是网络特征提取过程中图片缩小的倍数,和网络结构有关,ZFNet的缩小倍数为16,表明了最终feature map上一个像素可以映射到原图上16 x 16区域的大小。
(2)ratios=[0.5,1,2] 这个参数指的是要将16x16的区域,按照1:2,1:1,2:1三种比例进行变换,如下图所示:

(3)scales=2**np.arange(3, 6) 这个参数是要将输入区域的宽和高进行8,16,32三种倍数的放大,如16x16的区域变成(16x8)x(16x8)=128x128的区域,(16x16)x(16x16)=256x256的区域,(16x32)x(16x32)=512x512的区域,如下图所示:
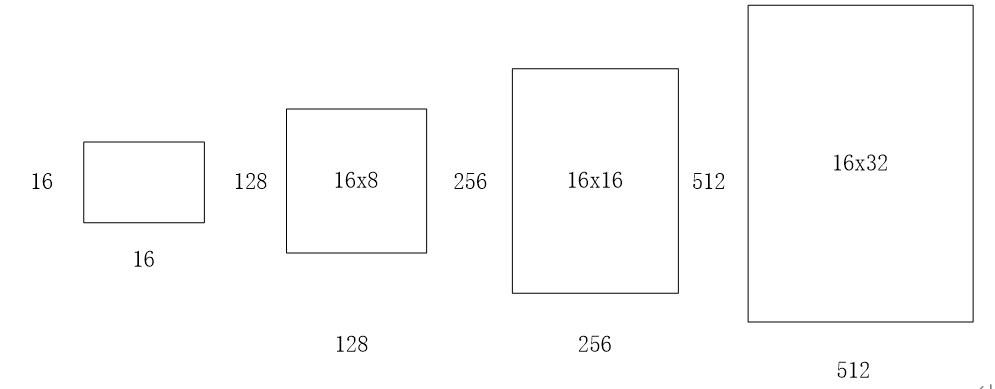
通过以上三个参数,针对于feature map上的任意一个像素点,首先映射到原图片上一个 16 x 16 的区域,然后以这个区域的中心点作为变换中心,将其变为三种宽高比的区域,再分别对这三种区域的面积扩大8,16,32倍,最终一个像素点对应到了原图的9个不同的矩形框,这些框就叫做Anchor,如下图:
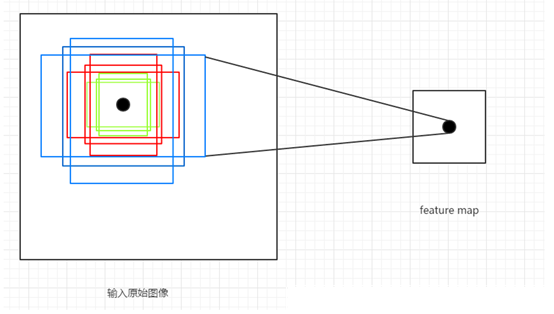
注意: 将不完全在图像内部(初始化的anchor的4个坐标点超出图像边界)的anchor都过滤掉,一般过滤后只会有原来1/3左右的anchor。如果不将这部分anchor过滤,则会使训练过程难以收敛。
Anchor是目标检测中的一个重要概念,通常是人为设计的一组框,作为分类(classification)和框回归(bounding box regression)的基准框。
无论是单阶段(single-stage)检测器还是两阶段(two-stage)检测器,都广泛地使用了anchor。例如,
两阶段检测器的第一阶段通常采用 RPN 生成 proposal,是对anchor进行分类和回归的过程,即 anchor -> proposal -> detection bbox;
大部分单阶段检测器是直接对 anchor 进行分类和回归,也就是 anchor -> detection bbox。
常见的生成 anchor 的方式是滑窗(sliding window),也就是首先定义k个特定尺度(scale)和长宽比(aspect ratio)的 anchor,
然后在全图上以一定的步长滑动。这种方式在 Faster R-CNN,YOLO v2+、SSD,RetinaNet 等经典检测方法中被广泛使用。
三、优化候选框
1、交并比(IOU)
通过SS或RPN等方法,最后每类选出的候选框(Region Proposal)比较多,在这些候选框中如何选出质量较好的框?人们想到使用IOU这个度量值。IOU(Intersection Over Union)指标来计算候选框和目标实际标注边界框的重合度。假如我们要计算两个矩形框A和B的IOU,就是它们的交集与并集之比,如下图所示:

矩形框A、B的一个重合度IOU计算公式为:
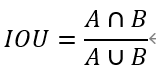
2、非极大值抑制(NMS,Non Maximum Suppression)
通过SS或RPN等方法产生的大量的候选框,这些矩形框有很多是指向同一目标(如下图所示),因此就存在大量冗余的候选。如何减少这些冗余框?NMS就是一个有效方法。

非极大值抑制(Non-Maximum Suppression,以下简称NMS算法)的思想是搜索局部极大值,抑制非极大值元素。就像上图片一样,定位一个车辆,SS或RPN算法对每个目标(如上图中汽车)生成一堆的方框,过滤哪些多余的矩形框,找到那个最佳的矩形框。
非极大值抑制的基本思路为:
先假设有6个候选框,根据分类器类别分类概率做排序,如下图所示:

从小到大分别属于车辆的概率分别为A、B、C、D、E、F。
(1)从最大概率矩形框(即面积最大的框)F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D(因为超过阈值,说明D与F或者B与F,已经有很大部分是重叠的,那我们保留面积最大的F即可,其余小面积的B,D就是多余的,用F完全可以表示一个物体了,所以保留F丢掉B,D);并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
(4)一直重复这个过程,找到所有曾经被保留下来的矩形框。
3、边框回归(Bounding Box Regression)
(1)边框回归的主要目的
通过SS或RPN等算法生成的大量候选框,虽然有一部分可以通过NMS等方法过滤一些多余框,但仍然还会存在很多质量不高的框图。如下图所示。

其中红色矩形框(内部这个框)的质量不高(红色的矩形框定位不准(IoU<0.5), 说明这个矩形框没有正确检测出飞机)。需要通过边框回归进行修改。此外,训练时作为有监督学习,也需要通过边框回归使预测框,通过迭代不断向目标框(Ground Truth)靠近。
(2)边框回归的主要原理
下图所示,红色的框A代表生成的候选框(即positive Anchors),绿色的框G代表目标框(Ground Truth),接下来需要基于A和G,找到一种映射关系得到一个预测框G’通过迭代使G’不断接近目标框G。这个过程用数学符合可表示为:,


(3)如何找到这个对应关系F?
如何通过变换F实现从上图中的矩形框A变为矩形框G’呢? 比较简单的思路就是: 平移+放缩,具体实现步骤如下:

以认为d_\astA(这里*表示x,y,w,h)变换是一种线性变换, 如此就可以用线性回归来建模对矩形框进行微调。线性回归就是给定输入的特征向量X, 学习一组参数W, 使得经过线性回归后的值跟真实值 G(Ground Truth)非常接近. 即G≈WX 。 那么 anchor Bounding-box 中的输入以及输出分别是什么呢?

(4)边框回归为何只能微调?
要使用线性回归,要求anchor A与G相乘较小,否则这些变换将可能变成复杂的非线性变换。
(5)边框回归主要应用
在RPN生成Proposal的过程中,最后输出时也使用边框回归使预测框不断向目标框逼近。
(6)改进空间
YOLO v2提出一种直接预测位置坐标的方法。之前的坐标回归实际上回归的不是坐标点,而是需要对预测结果做一个变换才能得到坐标点,这种方法在充分利用目的对象的位置信息方面效率打了较大折扣,为更好利用目标对象的位置信息,YOLO v2采用目标对象的中心坐标及左上角的方法,具体可参考下图:
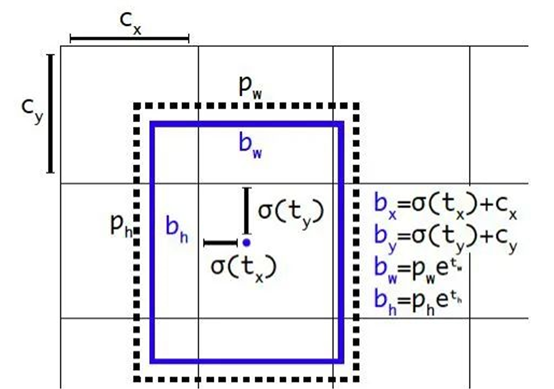
其中p_w,P_h为anchor box的宽和高,t_x,\ t_y,t_w,t_h为预测边界框的坐标值,σ是sigmoid函数。C_x,C_y为是当前网格左上角到图像左上角的距离,需要将网格大小归一化,即令一个网格的宽=1,高=1。
四、模型优化
1、SPP Net
SPP-Net 是何恺明、孙健等人的作品。SPP-Net 的主要创新点就是SPP,即Spatial pyramid pooling,空间金字塔池化。该方案解决了R-CNN 中每个region proposal 都要过一次CNN 的缺点,从而提升了效率,并且避免了为了适应CNN 的输入尺寸而图像缩放导致的目标形状失真的问题。我们通常看到的RoI pooling是SPP-net的一种变换版本。
2、FPN
FPN 全称Feature Pyramid Network,其主要思路是通过特征层面(即feature map)的转换,生成语义和低层信息都很丰富的特征金字塔,用于预测
如图所示,(a) 表示的是图像金字塔(image pyramid),即对图像进行放缩,不同的尺度分别进行预测。这种方法在目标检测里较为常用,但是速度较慢,因为每次需要对不同尺度的图像分别过一次CNN 进行训练。(b)表示的是单一feature map 的预测。由于图像金字塔速度太慢,索性直接只采用最后一层输出进行预测,但这样做同时也丢失了很多信息。(c) 表示的是各个scale 的feature map 分别进行预测,但是各个层次之间(不同scale)没有交互。SSD 模型中就是采用了这种策略,将不同尺度的bbox 分配到代表不同scale 的feature map上。(d) 即为这里要将的FPN 网络,即特征金字塔。这种方式通过将所有scale 的feature map 进行打通和结合,兼顾了速度和准确率。
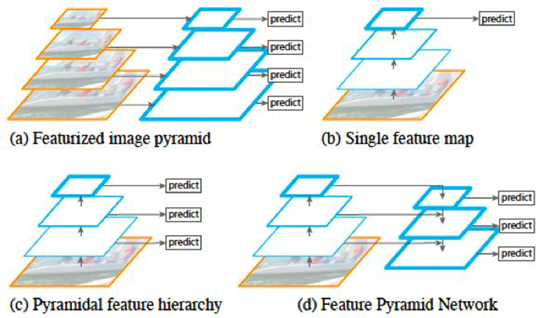
如何进行横向连接和融合?如下。把高层特征做2倍上采样,然后将其和对应的前一层特征结合,注意前一层特征经过 1*1 的卷积改变维度使得可以用加法进行融合。值得一提的是,这只是其中一种融合方式,当然也可以做通道上的 concat
FPN 在每两层之间为一个buiding block,结构如下:

FPN 的block 结构分为两个部分,一个自顶向下通路(top-down pathway),另一个是侧边通路(lateral pathway)。所谓自顶向下通路,具体指的是上一个小尺寸的feature map(语义更高层)做2 倍上采样,并连接到下一层。而侧边通路则指的是下面的feature map(高分辨率低语义)先利用一个1×1 的卷积核进行通道压缩,然后和上面下来的采样后结果进行合并。合并方式为逐元素相加(element-wise addition)。合并之后的结果在通过一个3×3 的卷积核进行处理,得到该scale 下的feature map。
FPN 并不是一个目标检测框架,它的这种结构可以融入到其他的目标检测框架中,去提升检测器的性能。截至现在,FPN 已经可以说成为目标检测框架中必备的结构了。