python-ai-02
年度归档:2020年
数据预处理在解决深度学习问题的过程中,往往需要花费大量的时间和精力。 数据处理的质量对训练神经网络来说十分重要,良好的数据处理不仅会加速模型训练, 更会提高模型性能。为解决这一问题,PyTorch提供了几个高效便捷的工具, 以便使用者进行数据处理或增强等操作,同时可通过并行化加速数据加载。
【说明】本文使用的cat-dog数据集,请到书《Python深度学习基于PyTorch》下载代码及数据部分下载。
数据集存放大致有以下两种方式:
(1)所有数据集放在一个目录下,文件名上附有标签名,数据集存放格式如下: root/cat_dog/cat.01.jpg
root/cat_dog/cat.02.jpg
........................
root/cat_dog/dog.01.jpg
root/cat_dog/dog.02.jpg
......................
(2)不同类别的数据集放在不同目录下,目录名就是标签,数据集存放格式如下:
root/ants/xxx.png
root/ants/xxy.jpeg
root/ants/xxz.png
................
root/bees/123.jpg
root/bees/nsdf3.png
root/bees/asd932_.png
..................
1.1 对第1种数据集的处理步骤
(1)生成包含各文件名的列表(List)
(2)定义Dataset的一个子类,该子类需要继承Dataset类,查看Dataset类的源码
(3)重写父类Dataset中的两个魔法方法: 一个是: __lent__(self),其功能是len(Dataset),返回Dataset的样本数。 另一个是__getitem__(self,index),其功能假设索引为i,使Dataset[i]返回第i个样本。
(4)使用torch.utils.data.DataLoader加载数据集Dataset.
1.2 实例详解
以下以cat-dog数据集为例,说明如何实现自定义数据集的加载。
1.2.1 数据集结构
所有数据集在cat-dog目录下:
.\cat_dog\cat.01.jpg
.\cat_dog\cat.02.jpg
.\cat_dog\cat.03.jpg
....................
.\cat_dog\dog.01.jpg
.\cat_dog\dog.02.jpg
....................
1.2.2 导入需要用到的模块
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from torch.utils.data import DataLoader,Dataset from skimage import io,transform import matplotlib.pyplot as plt import os import torch from torchvision import transforms, utils from PIL import Image import pandas as pd import numpy as np #过滤警告信息 import warnings warnings.filterwarnings("ignore") |
1.2.3定义加载自定义数据的类
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
class MyDataset(Dataset): #继承Dataset def __init__(self, path_dir, transform=None): #初始化一些属性 self.path_dir = path_dir #文件路径,如'.\data\cat-dog' self.transform = transform #对图形进行处理,如标准化、截取、转换等 self.images = os.listdir(self.path_dir)#把路径下的所有文件放在一个列表中 def __len__(self):#返回整个数据集的大小 return len(self.images) def __getitem__(self,index):#根据索引index返回图像及标签 image_index = self.images[index]#根据索引获取图像文件名称 img_path = os.path.join(self.path_dir, image_index)#获取图像的路径或目录 img = Image.open(img_path).convert('RGB')# 读取图像 # 根据目录名称获取图像标签(cat或dog) label = img_path.split('\\')[-1].split('.')[0] #把字符转换为数字cat-0,dog-1 label = 1 if 'dog' in label else 0 if self.transform is not None: img = self.transform(img) return img,label |
1.2.4 实例化类
|
1 2 3 |
dataset = MyDataset('.\data\cat-dog',transform=None) img, label = dataset[0] #将启动魔法方法__getitem__(0) print(type(img)) |
<class 'PIL.Image.Image'>
1.2.5 查看图像形状
|
1 2 3 |
i=1 for img, label in dataset: if i |
img的形状(500, 374),label的值0
img的形状(300, 280),label的值0
img的形状(489, 499),label的值0
img的形状(431, 410),label的值0
img的形状(300, 224),label的值0
从上面返回样本的形状来看:
(1)每张图片的大小不一样,如果需要取batch训练的神经网络来说很不友好。
(2)返回样本的数值较大,未归一化至[-1, 1]
为此需要对img进行转换,如何转换?只要使用torchvision中的transforms即可
1.2.6 对图像数据进行处理
这里使用torchvision中的transforms模块
|
1 2 3 4 5 6 7 |
from torchvision import transforms as T transform = T.Compose([ T.Resize(224), # 缩放图片(Image),保持长宽比不变,最短边为224像素 T.CenterCrop(224), # 从图片中间切出224*224的图片 T.ToTensor(), # 将图片(Image)转成Tensor,归一化至[0, 1] T.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5]) # 标准化至[-1, 1],规定均值和标准差 ]) |
1.2.7查看处理后的数据
|
1 2 3 4 5 |
dataset = MyDataset('.\data\cat-dog',transform=transform) for img, label in dataset: print("图像img的形状{},标签label的值{}".format(img.shape, label)) print("图像数据预处理后:\n",img) break |
图像img的形状torch.Size([3, 224, 224]),标签label的值0
图像数据预处理后:
tensor([[[ 0.9059, 0.9137, 0.9137, ..., 0.9451, 0.9451, 0.9451],
[ 0.9059, 0.9137, 0.9137, ..., 0.9451, 0.9451, 0.9451],
[ 0.9059, 0.9137, 0.9137, ..., 0.9529, 0.9529, 0.9529],
...,
[-0.4824, -0.5294, -0.5373, ..., -0.9216, -0.9294, -0.9451],
[-0.4980, -0.5529, -0.5608, ..., -0.9294, -0.9373, -0.9529],
[-0.4980, -0.5529, -0.5686, ..., -0.9529, -0.9608, -0.9608]],
[[ 0.5686, 0.5765, 0.5765, ..., 0.7961, 0.7882, 0.7882],
[ 0.5686, 0.5765, 0.5765, ..., 0.7961, 0.7882, 0.7882],
[ 0.5686, 0.5765, 0.5765, ..., 0.8039, 0.7961, 0.7961],
...,
[-0.6078, -0.6471, -0.6549, ..., -0.9137, -0.9216, -0.9373],
[-0.6157, -0.6706, -0.6784, ..., -0.9216, -0.9294, -0.9451],
[-0.6157, -0.6706, -0.6863, ..., -0.9451, -0.9529, -0.9529]],
[[-0.0510, -0.0431, -0.0431, ..., 0.2078, 0.2157, 0.2157],
[-0.0510, -0.0431, -0.0431, ..., 0.2078, 0.2157, 0.2157],
[-0.0510, -0.0431, -0.0431, ..., 0.2157, 0.2235, 0.2235],
...,
[-0.9529, -0.9843, -0.9922, ..., -0.9529, -0.9608, -0.9765],
[-0.9686, -0.9922, -1.0000, ..., -0.9608, -0.9686, -0.9843],
[-0.9686, -0.9922, -1.0000, ..., -0.9843, -0.9922, -0.9922]]])
由此可知,数据已标准化、规范化。
1.2.8对数据集进行批量加载
使用DataLoader模块,对数据集dataset进行批量加载
|
1 2 3 4 |
#使用DataLoader加载数据 dataloader = DataLoader(dataset,batch_size=4,shuffle=True) for batch_datas, batch_labels in dataloader: print(batch_datas.size(),batch_labels.size()) |
torch.Size([4, 3, 224, 224]) torch.Size([4])
torch.Size([4, 3, 224, 224]) torch.Size([4])
torch.Size([4, 3, 224, 224]) torch.Size([4])
torch.Size([4, 3, 224, 224]) torch.Size([4])
torch.Size([4, 3, 224, 224]) torch.Size([4])
torch.Size([4, 3, 224, 224]) torch.Size([4])
torch.Size([4, 3, 224, 224]) torch.Size([4])
torch.Size([4, 3, 224, 224]) torch.Size([4])
torch.Size([4, 3, 224, 224]) torch.Size([4])
torch.Size([4, 3, 224, 224]) torch.Size([4])
torch.Size([2, 3, 224, 224]) torch.Size([2])
1.2.9随机查看一个批次的图像
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import torchvision import matplotlib.pyplot as plt import numpy as np %matplotlib inline # 显示图像 def imshow(img): img = img / 2 + 0.5 # unnormalize npimg = img.numpy() plt.imshow(np.transpose(npimg, (1, 2, 0))) plt.show() # 随机获取部分训练数据 dataiter = iter(dataloader) images, labels = dataiter.next() # 显示图像 imshow(torchvision.utils.make_grid(images)) # 打印标签 print(' '.join('%s' % ["小狗" if labels[j].item()==1 else "小猫" for j in range(4)])) |

2 对第2种数据集的处理
处理这种情况比较简单,可分为2步:
(1)使用datasets.ImageFolder读取、处理图像。
(2)使用.data.DataLoader批量加载数据集,示例如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
import torch from torchvision import transforms, datasets data_transform = transforms.Compose([ transforms.RandomSizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) hymenoptera_dataset = datasets.ImageFolder(root='.\catdog\train', transform=data_transform) dataset_loader = torch.utils.data.DataLoader(hymenoptera_dataset, batch_size=4, shuffle=True,num_workers=4) |
6.1 概述
从2013 google推出最初的一种Word Embedding(即word2vec)后,其发展非常迅速,尤其近些年对Word Embedding的应用和拓展,取得了非常大的进步。
Embedding的起源,应该追溯到Word2Vec,Word2Vec是一种Word Embedding。由于Word Embedding克服了传统整数向量、One-Hot向量的耗资源、对语句表现能力差等不足,Word Embedding在最近几年发展和创新不断,从最初的Word Embedding,已发展成Sequence Embedding、catategorial data Embedding、Graph Embedding等等。应用也从当初的自然语言处理(NLP)到传统机器学习、自然语言处理、推荐系统、广告、搜索排序等领域,并大大提升了这些应用的性能。
Embedding尤其在NLP方面,近些年取得巨大进步。可以说是最近几年在NLP领域最大的突破就在Word Embedding方面。如将替换RNN\LSTM的Transformer或Transformer-XL,在很多下游复杂任务上已超越人类平均水平的BERT、XLNET模型等等。而这些算法或模型的应用开始在推荐、传统机器学习、视觉处理、NLP方面开始爆发!难怪有人说Embedding时代已来临!
以下我用图形这种简单明了的方式,简单介绍一下Embedding的历史及最近几年的突破性进展,希望能给大家进一步学习提供参考。
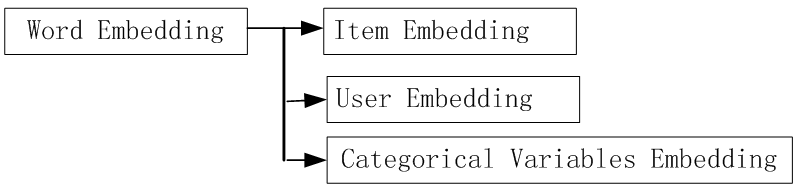
6.2Embedding在Entity领域的拓展
Entity Embedding是推荐系统、计算广告领域最近非常流行的做法,是从word2vec等一路发展而来的Embedding技术的最新延伸;
Entity Embedding中的Categorical Variable Embedding已成为贯通传统机器学习与深度学习的桥梁。
6.3 Embedding在NLP领域的最新进展
贪心学院2020-2-15至2020-2-22日5次公开课
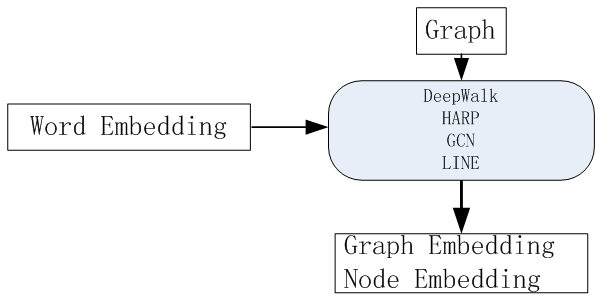
6.4 在Graph领域的拓展
Graph Embedding是推荐系统、计算广告领域最近非常流行的做法,是从word2vec等一路发展而来的Embedding技术的最新延伸;
Graph Embedding已经有很多大厂将Graph Embedding应用于实践后取得了非常不错的线上效果。
6.5 Embedding 应用到机器学习中
Embedding的起源和火爆都是在NLP中的,经典的word2vec都是在做word embedding这件事情,而真正首先在结构数据探索embedding的是在kaggle上的《Rossmann Store Sales》中的用简单特征工程取得第3名的解决方案(前两名为该领域的专业人士,采用了非常复杂的特征工程),作者在比赛完后为此方法整理一篇论文放在了arXiv,文章名:《Entity Embeddings of Categorical Variables》。
6.6Embedding在推荐领域的超级应用
1、[Item2Vec] Item2Vec-Neural Item Embedding for Collaborative Filtering (Microsoft 2016)
这篇论文是微软将word2vec应用于推荐领域的一篇实用性很强的文章。该文的方法简单易用,可以说极大拓展了word2vec的应用范围,使其从NLP领域直接扩展到推荐、广告、搜索等任何可以生成sequence的领域。
2、[Airbnb Embedding] Real-time Personalization using Embeddings for Search Ranking at Airbnb (Airbnb 2018)
Airbnb的这篇论文是KDD 2018的best paper,在工程领域的影响力很大,也已经有很多人对其进行了解读。简单来说,Airbnb对其用户和房源进行embedding之后,将其应用于搜索推荐系统,获得了实效性和准确度的较大提升。文中的重点在于embedding方法与业务模式的结合,可以说是一篇应用word2vec思想于公司业务的典范。
3、 [Airbnb Embedding] Real-time Personalization using Embeddings for Search Ranking at Airbnb (Airbnb 2018)
Airbnb的这篇论文是KDD 2018的best paper,在工程领域的影响力很大,也已经有很多人对其进行了解读。简单来说,Airbnb对其用户和房源进行embedding之后,将其应用于搜索推荐系统,获得了实效性和准确度的较大提升。文中的重点在于embedding方法与业务模式的结合,可以说是一篇应用word2vec思想于公司业务的典范。
4、[Alibaba Embedding] Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba (Alibaba 2018)
阿里巴巴在KDD 2018上发表的这篇论文是对Graph Embedding非常成功的应用。从中可以非常明显的看出从一个原型模型出发,在实践中逐渐改造,最终实现其工程目标的过程。这个原型模型就是上面提到的DeepWalk,阿里通过引入side information解决embedding问题非常棘手的冷启动问题,并针对不同side information进行了进一步的改造形成了最终的解决方案。
5、Behavior Sequence Transformer for E-commerce Recommendation in Alibaba(阿里2019)
近日,阿里巴巴搜索推荐事业部发布了一项新研究,首次使用强大的 Transformer 模型捕获用户行为序列的序列信号,供电子商务场景的推荐系统使用。该模型已经部署在淘宝线上,实验结果表明,与两个基准线对比,在线点击率(CTR)均有显著提高。
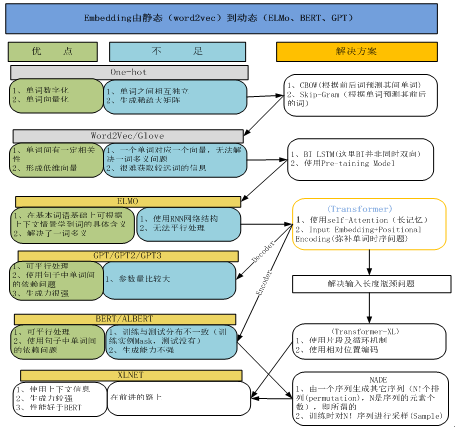
6.7 Embedding协助NLP极大提升性能
从简单的 Word2Vec,ELMo,GPT,BERT,XLNet到ALBERT, 这几乎是NLP过去10年最为颠覆性的成果。
1、BERT
BERT是一种基于Transformer Encoder来构建的一种模型,它整个的架构其实是基于DAE(Denoising Autoencoder)的,这部分在BERT文章里叫作Masked Lanauge Model(MLM)。MLM并不是严格意义上的语言模型,因为整个训练过程并不是利用语言模型方式来训练的。BERT随机把一些单词通过MASK标签来代替,并接着去预测被MASK的这个单词,过程其实就是DAE的过程。BERT有两种主要训练好的模型,分别是BERT-Small和BERT-Large, 其中BERT-Large使用了12层的Encoder结构。 整个的模型具有非常多的参数。
BERT在2018年提出,当时引起了爆炸式的反应,因为从效果上来讲刷新了非常多的记录,之后基本上开启了这个领域的飞速的发展。
2、XLNET
XLNet震惊了NLP领域,这种语言建模的新方法在20个NLP任务上的表现优于强大的BERT,并且在18个任务中获得了最先进的结果。
3、ALBERT
谷歌Lab近日发布了一个新的预训练模型"ALBERT"全面在SQuAD 2.0、GLUE、RACE等任务上超越了BERT、XLNet再次刷新了排行榜!ALBERT是一种轻量版本的BERT,利用更好的参数来训练模型,但是效果却反而得到了很大提升!ALBERT的核心思想是采用了两种减少模型参数的方法,比BERT占用的内存空间小很多,同时极大提升了训练速度,更重要的是效果上也有很大的提升!
6.8 Embedding表示为何如此重要?
1、它体量小,但能量大(是维度较少,但为连续性数值的向量);
2、它能在循环中不断学习(学习中能学到很多数据中很多内在规则或特性),下图为在训练完之后,学到的一些特性。
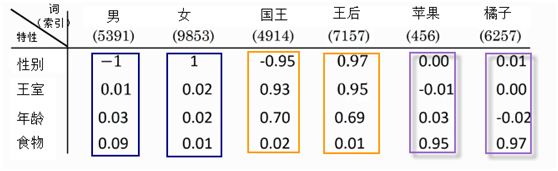
通过学习,如国王这个词,通过学习,能获取性能、王室等重要信息,而不仅仅是这个词的数字表示。
在《XGBoost与神经网络谁更牛?》文章,基于相同数据,对XGBoost和神经网络(NN)两种方法进行横行比较。XGBoost是属于Tree Model,只把分类特征进行数字化。对神经网络(NN)先把分类特征数值化,然后转换为One-hot。结果两个算法的测试结果(损失值)如下:
表3-1两种不同算法测试结果

《XGBoost与神经网络谁更牛?》基于相同数据集用不同算法进行比较,本章将从纵向进行比较,即基于相同数据集,相同算法(都是神经网络NN),但特征处理方式不同。一种是《XGBoost与神经网络谁更牛?》的方法,另外一种对分类特征采用Embedding方法,把分类特征转换为向量,并且这些向量的值会随着模型的迭代而自动更新。这两种方法比较的结果如表3-2所示:
表3-2 同一算法不同特征处理方式的测试结果

训练及测试数据没有打乱,其中测试数据是最新原数据的10%。
从表3-2可以看出,使用EE处理分类特征的方法性能远好于不使用EE的神经网络,使用EE有利于充分发挥NN的潜能,提升NN在实现传统机器学习任务的性能。
EE处理方法为何能大大提升模型的性能?使用EE处理特征有哪些优势,Embedding方法是否还适合于处理其它特征?如连续特征、时许特征、图(graph)特征等。这些问题后续将陆续进行说明。接下来我们将用Keras或TensorFlow的Embeding层处理分类特征。
3.1 Embedding简介
神经网络、深度学习的应用越来越广泛,从计算机视觉到自然语言处理和时间序列预测。在这些领域都取得不错成绩,有很多落地项目性能已超过人的平均水平。不但有较好的性能,特征工程方面更是实现了特征工程的自动化。
特征工程是传统机器学习的核心任务,模型性能如何很大程度取决特征工程处理方法,由此,要得到理想的特征工程往往需要很多业务和技术方面的技巧,因此有“特征工程是一门艺术”的说法,这也从一个侧面说明特征工程的门槛比较高,不利于普及和推广。不过这种情况,近些年正在改变。为了解决这一大瓶颈,人们开始使用神经网络或深度学习方法处理传统机器学习任务,特征工程方法使用Embedding 方法,把离散变量转变为较低维的向量,通过这种方式,我们可以将神经网络,深度学习用于更广泛的领域。
目前Embedding已广泛使用在自然语言处理(NLP)、结构化数据、图形数据等处理方面。在NLP 中常用的 Word Embedding ,对结构化数据使用 Entity Embedding,对图形数据采用Graph Embedding。这些内容后续我们将陆续介绍。这里先介绍如何用keras或TensorFlow实现分类特征的Embedding。
3.1.1 Keras.Embedding格式
keras的Embedding层格式如下:
|
1 |
keras.layers.Embedding(input_dim, output_dim, embeddings_initializer='uniform', embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None) |
Keras提供了一个嵌入层(Embedding layer),可用于处理文本数据、分类数据等的神经网络。它要求输入数据进行整数编码,以便每个单词或类别由唯一的整数表示。嵌入层使用随机权重初始化,并将学习所有数据集中词或类别的表示。这层只能作为模型的第1层。
【参数说明】
input_dim: int > 0。词汇表大小或类别总数, 即,最大整数索引(index) + 1。
output_dim: int >= 0。词向量的维度。
embeddings_initializer: embeddings 矩阵的初始化方法 (详见 https://keras.io/initializers/)。
embeddings_regularizer: embeddings matrix 的正则化方法
(详见https://keras.io/regularizers/)。
embeddings_constraint: embeddings matrix 的约束函数 (详见 https://keras.io/constraints/)。
mask_zero: 是否把 0 看作为一个应该被遮蔽的特殊的 "padding" 值。这对于可变长的循环神经网络层十分有用。 如果设定为 True,那么接下来的所有层都必须支持 masking,否则就会抛出异常。 如果 mask_zero 为 True,作为结果,索引 0 就不能被用于词汇表中 (input_dim 应该与 vocabulary + 1 大小相同)。
input_length: 输入序列的长度,当它是固定的时。 如果你需要连接 Flatten 和 Dense 层,则这个参数是必须的 (没有它,dense 层的输出尺寸就无法计算)。
输入尺寸
尺寸为 (batch_size, sequence_length) 的 2D 张量。
输出尺寸
尺寸为 (batch_size, sequence_length, output_dim) 的 3D 张量。
更多信息可参考官网:
https://keras.io/layers/embeddings/
https://keras.io/zh/layers/embeddings/(中文)
假设定义一个词汇量为200的嵌入层的整数编码单词,将词嵌入到32维的向量空间,每次输入50个单词的输入文档,那么对应的embedding可写成如下格式:
|
1 |
em=Embedding(200,32,input_length=50) |
为更好理解Keras的Embedding层的使用,下面列举几个具体实例。
(1)简单实例代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
model = Sequential() model.add(Embedding(1000, 64, input_length=10)) # 模型将输入一个大小为 (batch, input_length) 的整数矩阵。 # 输入中最大的整数(即词索引)不应该大于 999 (词汇表大小) #生成输入矩阵,batch=32,input_length=10 input_array = np.random.randint(1000, size=(32, 10)) #编译模型 model.compile('rmsprop', 'mse') #进行预测 output_array = model.predict(input_array) # 现在 model.output_shape == (None, 10, 64),其中 None 是 batch 的维度。 print(output_array.shape) ###(32, 10, 64) |
(2)用Embedding学习文本表示实例
假设有10个文本文档,每个文档都有一个学生提交的工作评论。每个文本文档被分类为正的“1”或负的“0”。这是一个简单的情感分析问题。用Keras的Embedding学习这10个文本的表示,具体实现代码如下;
#导入需要的模块
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
import numpy as np from tensorflow.keras.preprocessing.text import one_hot from tensorflow.keras.preprocessing.sequence import pad_sequences from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Embedding #定义一个文档,这个文档有10句语句 docs = ['Well done!', 'Good work', 'Great effort', 'nice work', 'Excellent!', 'Weak', 'Poor effort!', 'not good', 'poor work', 'Could have done better.'] #定义对应的类标签 labels = np.array([1,1,1,1,1,0,0,0,0,0]) vocab_size = 50 # 用one-hot函数将文本编码为大小为vocab_size的单词索引列表 encoded_docs = [one_hot(d, vocab_size) for d in docs] print("把文本转换为整数") print(encoded_docs) # 将序列填充到相同的长度(长度为4) max_length = 4 padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post') print("填充向量") print(padded_docs) #定义模型 model = Sequential() model.add(Embedding(vocab_size,8,input_length=max_length,name='word_embedding')) model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) #编译模型 model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc']) #查看模型结构 print("查看模型结构") print(model.summary()) #拟合模型 model.fit(padded_docs, labels, epochs=50, verbose=0) #评估模型 loss, accuracy = model.evaluate(padded_docs, labels, verbose=0) print("查看模型精度") print('Accuracy: %f' % (accuracy*100)) |
运行结果如下:
把文本转换为整数
[[49, 28], [33, 36], [21, 41], [18, 36], [32], [29], [18, 41], [30, 33], [18, 36], [43, 17, 28, 34]]
填充向量
[[49 28 0 0]
[33 36 0 0]
[21 41 0 0]
[18 36 0 0]
[32 0 0 0]
[29 0 0 0]
[18 41 0 0]
[30 33 0 0]
[18 36 0 0]
[43 17 28 34]]
查看模型结构
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_5 (Embedding) (None, 4, 8) 400
_________________________________________________________________
flatten_4 (Flatten) (None, 32) 0
_________________________________________________________________
dense_4 (Dense) (None, 1) 33
=================================================================
Total params: 433
Trainable params: 433
Non-trainable params: 0
_________________________________________________________________
None
查看模型精度
Accuracy: 89.999998
查看通过50次迭代后的Embedding矩阵。
|
1 2 |
model.get_layer('word_embedding').get_weights()[0].shape ##(50,8) model.get_layer('word_embedding').get_weights()[0][:3] #查看前3行 |
运行结果如下:
array([[ 0.03469506, 0.05556902, -0.06460979, 0.04944995, -0.04956526,
-0.01446372, -0.01657126, 0.04287368],
[ 0.04969586, -0.0284451 , -0.03200825, -0.00149088, 0.04212971,
-0.00741715, -0.02147427, -0.02345204],
[ 0.00152697, 0.04381416, 0.01856637, -0.00952369, 0.04007444,
0.00964203, -0.0313913 , -0.04820969]], dtype=float32)
3.1.2 Dense简介
|
1 |
keras.layers.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None) |
Dense就是常用的的全连接层,它实现以下操作:
|
1 |
output = activation(dot(input, kernel) + bias) |
其中 activation 是按逐个元素计算的激活函数,kernel 是由网络层创建的权值矩阵,以及 bias 是其创建的偏置向量 (只在 use_bias 为 True 时才有用)。
注意: 如果该层的输入的秩大于2,那么它首先被展平然后 再计算与 kernel 的点乘。
【参数说明】
units: 正整数,输出空间维度。
activation: 激活函数 (详见 activations)。 若不指定,则不使用激活函数 (即,「线性」激活: a(x) = x)。
use_bias: 布尔值,该层是否使用偏置向量。
kernel_initializer: kernel 权值矩阵的初始化器 (详见https://keras.io/zh/initializers/)。
bias_initializer: 偏置向量的初始化器 (详见https://keras.io/zh/initializers/).
kernel_regularizer: 运用到 kernel 权值矩阵的正则化函数 (详见 https://keras.io/zh/regularizers/)。
bias_regularizer: 运用到偏置向的的正则化函数 (详见 https://keras.io/zh/regularizers/)。
activity_regularizer: 运用到层的输出的正则化函数 (它的 "activation")。 (详见 https://keras.io/zh/regularizers/)。
kernel_constraint: 运用到 kernel 权值矩阵的约束函数 (详见https://keras.io/zh/constraints/)。
bias_constraint: 运用到偏置向量的约束函数 (详见https://keras.io/zh/constraints/)。
输入尺寸
nD张量,尺寸: (batch_size, ..., input_dim)。 最常见的情况是一个尺寸为 (batch_size, input_dim) 的2D输入。
输出尺寸
nD张量,尺寸: (batch_size, ..., units)。 例如,对于尺寸为 (batch_size, input_dim)的2D输入, 输出的尺寸为 (batch_size, units)。
简单示例代码:
|
1 2 3 4 5 6 7 8 |
# 作为 Sequential 模型的第一层 model = Sequential() model.add(Dense(32, input_shape=(16,))) # 现在模型就会以尺寸为 (*, 16) 的数组作为输入, # 其输出数组的尺寸为 (*, 32) # 在第一层之后,就不再需要指定输入的尺寸了: model.add(Dense(32)) |
3.2 NN架构
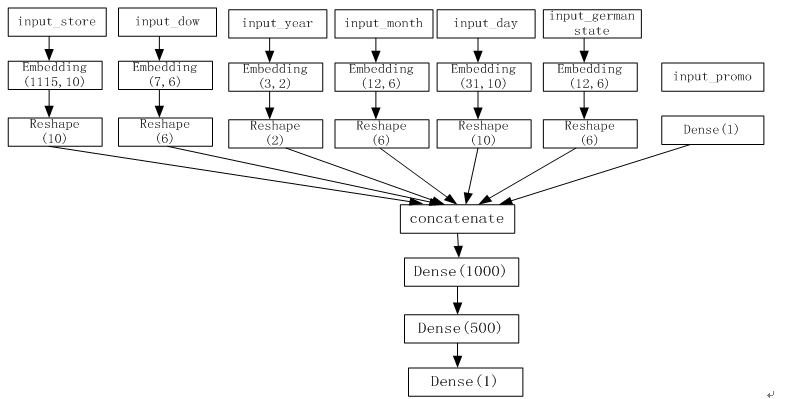
图3-1 NN架构图
从图3-1可知,NN共处理7个特征,其中promo特征因只有2个值(0或1),无需转换为Embedding向量,其它6个特征,根据类别数,分别做了Embedding处理。处理后合并这7个特征,再通过3个全连接层。
3.3 分类特征处理
基于第2章(《XGBoost与NN谁更牛?》)处理保存的feature_train_data.pickle文件,做如下处理:
3.3.1 数据预处理
(1)定义对特征进行Embedding处理函数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
#从训练结果读取各特征的embedding向量,并用这些向量作为输入值 def embed_features(X, saved_embeddings_fname): # f_embeddings = open("embeddings_shuffled.pickle", "rb") f_embeddings = open(saved_embeddings_fname, "rb") embeddings = pickle.load(f_embeddings) #因store_open,promo这两列(索引分别为0、3),至多只有两个值,没有进行embedding,故需排除在外 index_embedding_mapping = {1: 0, 2: 1, 4: 2, 5: 3, 6: 4, 7: 5} X_embedded = [] (num_records, num_features) = X.shape for record in X: embedded_features = [] for i, feat in enumerate(record): feat = int(feat) if i not in index_embedding_mapping.keys(): embedded_features += [feat] else: embedding_index = index_embedding_mapping[i] embedded_features += embeddings[embedding_index][feat].tolist() X_embedded.append(embedded_features) return numpy.array(X_embedded) #分别取出各特征,因第1列只有1个值,不用第1列(即索引为0的列) def split_features(X): X_list = [] #获取X第2列数据 store_index = X[..., [1]] X_list.append(store_index) #获取X第3列数据,以下类推 day_of_week = X[..., [2]] X_list.append(day_of_week) promo = X[..., [3]] X_list.append(promo) year = X[..., [4]] X_list.append(year) month = X[..., [5]] X_list.append(month) day = X[..., [6]] X_list.append(day) State = X[..., [7]] X_list.append(State) return X_list |
(2)导入模块
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import pickle import numpy numpy.random.seed(123) from tensorflow.keras.models import Sequential from tensorflow.keras.models import Model as KerasModel from tensorflow.keras.layers import Input, Dense, Activation, Reshape,Flatten from tensorflow.keras.layers import Concatenate from tensorflow.keras.layers import Embedding from tensorflow.keras.callbacks import ModelCheckpoint import sys sys.setrecursionlimit(10000) train_ratio = 0.9 shuffle_data = False one_hot_as_input = False embeddings_as_input = False save_embeddings = True saved_embeddings_fname = "embeddings.pickle" # set save_embeddings to True to create this file |
(3)读取数据
|
1 2 3 4 5 |
f = open('feature_train_data.pickle', 'rb') (X, y) = pickle.load(f) num_records = len(X) train_size = int(train_ratio * num_records) |
(4)生成训练、测试数据
|
1 2 3 4 |
X_train = X[:train_size] X_val = X[train_size:] y_train = y[:train_size] y_val = y[train_size:] |
(5)定义采样函数
|
1 2 3 4 5 |
def sample(X, y, n): '''random samples''' num_row = X.shape[0] indices = numpy.random.randint(num_row, size=n) return X[indices, :], y[indices] |
(6)采样生成训练数据
|
1 2 |
X_train, y_train = sample(X_train, y_train, 200000) # Simulate data sparsity print("Number of samples used for training: " + str(y_train.shape[0])) |
3.3.2 构建模型
(1)定义Model类
|
1 2 3 4 5 6 7 8 |
class Model(object): def evaluate(self, X_val, y_val): assert(min(y_val) > 0) guessed_sales = self.guess(X_val) relative_err = numpy.absolute((y_val - guessed_sales) / y_val) result = numpy.sum(relative_err) / len(y_val) return result |
(2)构建模型
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
class NN_with_EntityEmbedding(Model): def __init__(self, X_train, y_train, X_val, y_val): super().__init__() self.epochs = 10 self.checkpointer = ModelCheckpoint(filepath="best_model_weights.hdf5", verbose=1, save_best_only=True) self.max_log_y = max(numpy.max(numpy.log(y_train)), numpy.max(numpy.log(y_val))) self.__build_keras_model() self.fit(X_train, y_train, X_val, y_val) def preprocessing(self, X): X_list = split_features(X) return X_list def __build_keras_model(self): input_store = Input(shape=(1,)) output_store = Embedding(1115, 10, name='store_embedding')(input_store) output_store = Reshape(target_shape=(10,))(output_store) input_dow = Input(shape=(1,)) output_dow = Embedding(7, 6, name='dow_embedding')(input_dow) output_dow = Reshape(target_shape=(6,))(output_dow) #promo只有0、1两个值,无需进行Embedding input_promo = Input(shape=(1,)) output_promo = Dense(1)(input_promo) input_year = Input(shape=(1,)) output_year = Embedding(3, 2, name='year_embedding')(input_year) output_year = Reshape(target_shape=(2,))(output_year) input_month = Input(shape=(1,)) output_month = Embedding(12, 6, name='month_embedding')(input_month) output_month = Reshape(target_shape=(6,))(output_month) input_day = Input(shape=(1,)) output_day = Embedding(31, 10, name='day_embedding')(input_day) output_day = Reshape(target_shape=(10,))(output_day) input_germanstate = Input(shape=(1,)) output_germanstate = Embedding(12, 6, name='state_embedding')(input_germanstate) output_germanstate = Reshape(target_shape=(6,))(output_germanstate) input_model = [input_store, input_dow, input_promo, input_year, input_month, input_day, input_germanstate] output_embeddings = [output_store, output_dow, output_promo, output_year, output_month, output_day, output_germanstate] output_model = Concatenate()(output_embeddings) output_model = Dense(1000, kernel_initializer="uniform")(output_model) output_model = Activation('relu')(output_model) output_model = Dense(500, kernel_initializer="uniform")(output_model) output_model = Activation('relu')(output_model) output_model = Dense(1)(output_model) output_model = Activation('sigmoid')(output_model) self.model = KerasModel(inputs=input_model, outputs=output_model) self.model.compile(loss='mean_absolute_error', optimizer='adam') def _val_for_fit(self, val): val = numpy.log(val) / self.max_log_y return val def _val_for_pred(self, val): return numpy.exp(val * self.max_log_y) def fit(self, X_train, y_train, X_val, y_val): self.model.fit(self.preprocessing(X_train), self._val_for_fit(y_train), validation_data=(self.preprocessing(X_val), self._val_for_fit(y_val)), epochs=self.epochs, batch_size=128, # callbacks=[self.checkpointer], ) # self.model.load_weights('best_model_weights.hdf5') print("Result on validation data: ", self.evaluate(X_val, y_val)) def guess(self, features): features = self.preprocessing(features) result = self.model.predict(features).flatten() return self._val_for_pred(result) |
(3)训练模型
|
1 2 3 4 5 |
models = [] print("Fitting NN_with_EntityEmbedding...") for i in range(5): models.append(NN_with_EntityEmbedding(X_train, y_train, X_val, y_val)) |
运行部分结果
Fitting NN_with_EntityEmbedding...
Train on 200000 samples, validate on 84434 samples
Epoch 1/10
200000/200000 [==============================] - 37s 185us/sample - loss: 0.0140 - val_loss: 0.0113
Epoch 2/10
200000/200000 [==============================] - 33s 165us/sample - loss: 0.0093 - val_loss: 0.0110
Epoch 3/10
200000/200000 [==============================] - 34s 168us/sample - loss: 0.0085 - val_loss: 0.0104
Epoch 4/10
200000/200000 [==============================] - 35s 173us/sample - loss: 0.0079 - val_loss: 0.0107
Epoch 5/10
200000/200000 [==============================] - 37s 184us/sample - loss: 0.0076 - val_loss: 0.0100
Epoch 6/10
200000/200000 [==============================] - 38s 191us/sample - loss: 0.0074 - val_loss: 0.0095
Epoch 7/10
200000/200000 [==============================] - 31s 154us/sample - loss: 0.0072 - val_loss: 0.0097
Epoch 8/10
200000/200000 [==============================] - 33s 167us/sample - loss: 0.0071 - val_loss: 0.0091
Epoch 9/10
200000/200000 [==============================] - 36s 181us/sample - loss: 0.0069 - val_loss: 0.0090
Epoch 10/10
200000/200000 [==============================] - 40s 201us/sample - loss: 0.0068 - val_loss: 0.0089
Result on validation data: 0.09481584162850512
Train on 200000 samples, validate on 84434 samples
Epoch 1/10
200000/200000 [==============================] - 38s 191us/sample - loss: 0.0143 - val_loss: 0.0125
Epoch 2/10
200000/200000 [==============================] - 41s 206us/sample - loss: 0.0096 - val_loss: 0.0107
Epoch 3/10
200000/200000 [==============================] - 46s 232us/sample - loss: 0.0089 - val_loss: 0.0105
Epoch 4/10
200000/200000 [==============================] - 39s 197us/sample - loss: 0.0082 - val_loss: 0.0099
Epoch 5/10
200000/200000 [==============================] - 39s 197us/sample - loss: 0.0077 - val_loss: 0.0095
Epoch 6/10
200000/200000 [==============================] - 41s 207us/sample - loss: 0.0075 - val_loss: 0.0111
Epoch 7/10
200000/200000 [==============================] - 39s 193us/sample - loss: 0.0073 - val_loss: 0.0092
Epoch 8/10
200000/200000 [==============================] - 50s 248us/sample - loss: 0.0071 - val_loss: 0.0092
Epoch 9/10
200000/200000 [==============================] - 46s 228us/sample - loss: 0.0070 - val_loss: 0.0094
Epoch 10/10
200000/200000 [==============================] - 44s 221us/sample - loss: 0.0069 - val_loss: 0.0091
Result on validation data: 0.09585602861091462
3.3.3 验证模型
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#求多个模型的集成精度 def evaluate_models(models, X, y): assert(min(y) > 0) guessed_sales = numpy.array([model.guess(X) for model in models]) mean_sales = guessed_sales.mean(axis=0) relative_err = numpy.absolute((y - mean_sales) / y) result = numpy.sum(relative_err) / len(y) return result print("Evaluate combined models...") print("Training error...") r_train = evaluate_models(models, X_train, y_train) print(r_train) print("Validation error...") r_val = evaluate_models(models, X_val, y_val) print(r_val) |
运行结果如下:
Evaluate combined models...
Training error...
0.06760082089742254
Validation error...
0.09348419043167332
3.4 可视化Entity Embedding
把特征转换为Entity Embedding之后,可以利用t-SNE进行可视化,如对store特征的Embedding降维后进行可视化,从可视化结果揭示出一些重要信息,彼此相似的类别比较接近。
3.4.1 保存Embedding
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#保存各特征的embedding值 if save_embeddings: model = models[3].model store_embedding = model.get_layer('store_embedding').get_weights()[0] dow_embedding = model.get_layer('dow_embedding').get_weights()[0] year_embedding = model.get_layer('year_embedding').get_weights()[0] month_embedding = model.get_layer('month_embedding').get_weights()[0] day_embedding = model.get_layer('day_embedding').get_weights()[0] german_states_embedding = model.get_layer('state_embedding').get_weights()[0] with open(saved_embeddings_fname, 'wb') as f: pickle.dump([store_embedding, dow_embedding, year_embedding, month_embedding, day_embedding, german_states_embedding], f, -1) |
3.4.2 可视化Embedding特征
(1)导入模块
|
1 2 3 4 5 6 7 8 9 10 |
import pickle from sklearn import manifold import matplotlib.pyplot as plt import numpy as np %matplotlib inline #屏蔽警告信息 import warnings warnings.filterwarnings('ignore') |
(2)读取保存的embedding文件
|
1 2 3 |
with open("embeddings.pickle", 'rb') as f: [store_embedding, dow_embedding, year_embedding, month_embedding, day_embedding, german_states_embedding] = pickle.load(f) |
(3)定义对应各州的名称
|
1 |
states_names = ["柏林","巴登•符腾堡","拜仁","下萨克森","黑森","汉堡","北莱茵•威斯特法伦州","莱茵兰•普法尔茨州","石勒苏益格荷尔斯泰因州","萨克森州","萨克森安哈尔特州","图林根州"] |
(4)可视化german_states_embedding
|
1 2 3 4 5 6 7 8 9 |
plt.rcParams['font.sans-serif']=['SimHei'] ##显示中文 plt.rcParams['axes.unicode_minus']=False ##防止坐标轴上的-号变为方块 tsne = manifold.TSNE(init='pca', random_state=0, method='exact') Y = tsne.fit_transform(german_states_embedding) plt.figure(figsize=(8,8)) plt.scatter(-Y[:, 0], -Y[:, 1]) for i, txt in enumerate(states_names): plt.annotate(txt, (-Y[i, 0],-Y[i, 1]), xytext = (-20, 8), textcoords = 'offset points') plt.savefig('state_embedding.pdf') |
可视化结果如下:

图3-2 可视化german_states_embedding
从图3-2 可知,德国的原属于东德的几个州:萨克森州、萨克森安哈尔特州、图林根州彼此比较接近。其它各州也有类似属性,这就是Embedding通过多次迭代,从数据中学习到一些规则。
XGBoost是Kaggle上的比赛神器,近些年在kaggle或天池比赛上时常能斩获大奖,不过这样的历史正在改变!最近几年神经网络的优势开始从非结构数据向结构数据延伸,而且在一些Kaggle比赛中取得非常不错的成绩。
XGBoost很牛,不过更牛的应该是NN! 这章我们通过一个实例来说明,本实例基于相同数据,使用XGBoost和神经网络(NN)对类别数据转换为数字。XGBoost是属于Tree Model,故是否使用One-hot影响不大(通过测试,确实如此,相反,如果转换为one-hot将大大增加内存开销),所以使用xgboost的数据转换为数字后,没有再转换为one-hot编码。对神经网络(NN)而言,是否把数据转换为One-hot,影响比较大,所以使用NN的模型数据已转换为One-hot。
两种算法测试结果为表2-1。

训练及测试数据没有打乱,其中测试数据是最新原数据的10%。
2.1 XGBoost简介
2.1.1概述
XGBoost的全称是eXtreme Gradient Boosting,由很多CART(Classification And Regression Tree)树集成,其中CART是对分类决策树和回归决策树的总称。
分类决策树一般使用信息增益、信息增益率、基尼系数来选择特征的依据。CART回归树是假设树为二叉树,通过不断将特征进行分裂。比如当前树结点是基于第j个特征值进行分裂的,设该特征值小于s的样本划分为左子树,大于s的样本划分为右子树。因此,当我们为了求解最优的切分特征j和最优的切分点s,就转化为求解这么一个目标函数。
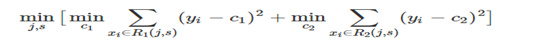
只要遍历所有特征的的所有切分点,就能找到最优的切分特征和切分点。最终得到一棵回归树。
2.1.2 主要原理
XGBoost本质上还是一个GBDT(Gradient Boosting Decision Tree),但为力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted。GBDT的原理就是所有弱分类器的结果相加等于预测值,然后下一个弱分类器去拟合误差函数对预测值的梯度(或残差)(这个梯度/残差就是预测值与真实值之间的误差)。一个弱分类器如何去拟合误差函数残差?
举一个非常简单的例子,比如我今年30岁了,但计算机或者模型GBDT并不知道我今年多少岁,那GBDT咋办呢?
(1)它会在第一个弱分类器(或第一棵树中)随便用一个年龄比如20岁来拟合,然后发现误差有10岁;
(2)在第二棵树中,用6岁去拟合剩下的损失,发现差距还有4岁;
(3)在第三棵树中用3岁拟合剩下的差距,发现差距只有1岁了;
(4)在第四课树中用1岁拟合剩下的残差,完美。
最终,四棵树的结论加起来,就是真实年龄30岁。实际工程中GBDT是计算负梯度,用负梯度近似残差。
注意,为何GBDT可以用用负梯度近似残差呢?
回归任务下,GBDT 在每一轮的迭代时对每个样本都会有一个预测值,此时的损失函数为均方差损失函数,表达式如下:
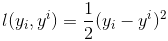
那此时的负梯度是这样计算的,具体表达式如下:
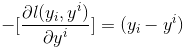
所以,当损失函数选用均方损失函数是时,每一次拟合的值就是(真实值 - 当前模型预测的值),即残差。此时的变量是,即“当前预测模型的值”,也就是对它求负梯度。
更多详细内容可参考:https://blog.csdn.net/v_july_v/article/details/81410574
2.1.3 主要优点
(1)目标表达式:
XGBoost优化了GBDT的目标函数。一方面,在GBDT的基础上加入了正则项,包括叶子节点的个数和每个叶子节点输出的L2模的平方和,正则项可以控制树的复杂度,让模型倾向于学习简单的模型,防止过拟合;另外,XGBoost还支持线性分类器,传统的GBDT是以CART算法作为基学习器。
(2)使用Shrinkage:
对每棵树的预测结果采用了shrinkage,相当于学习率,降低模型对单颗树的依赖,提升模型的泛化能力。
(3)采用列采样:
XGBoost借助了随机森林的优点,采用了列采样,进一步防止过拟合,加速训练过程,而传统的GBDT则没有列采样。
(4)优化方法:
XGBoost对损失函数的展开采用了一阶梯度和二阶梯度,而传统的GBDT只采用了一阶梯度。
(5)增益计算:
对分裂依据进行了优化。不同于CART算法,XGBoost采用了新的基于一阶导数和二阶导数的统计信息作为树的结构分数,采用分列前的结构与分裂后的结构得分的增益作为分裂依据,选择增益最大的特征值作为分裂点,替代了回归树的误差平方和。
(6)最佳增益节点查找:
XGBoost在寻找最佳分离点的方式上采用了近似算法,基于权重的分位数划分方式(权重为二阶梯度)。主要是对特征取值进行分桶,然后基于桶的值计算增益。
(7)预排序。
在寻找最佳增益节点时,将所有数据放入内存进行计算,得到预排序结果,然后在计算分裂增益的时候直接调用。
(8)缺失值处理
对于特征的值有缺失的样本,Xgboost可以自动学习出他的分裂方向。Xgboost内置处理缺失值的规则。
(9)支持并行。
众所周知,Boosting算法是顺序处理的,也是说Boosting不是一种串行的结构吗?怎么并行的?注意XGBoost的并行不是tree粒度的并行。XGBoost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含)。XGBoost的并行式在特征粒度上的,也就是说每一颗树的构造都依赖于前一颗树。
2.1.4 XGBoost的模型参数
XGBoost使用字典的方式存储参数,主要参数有如下这些:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
params = { 'booster':'gbtree', 'objective':'multi:softmax', # 多分类问题 'num_class':10, # 类别数,与multi softmax并用 'gamma':0.1, # 用于控制是否后剪枝的参数,越大越保守,一般0.1 0.2的样子 'max_depth':12, # 构建树的深度,越大越容易过拟合 'lambda':2, # 控制模型复杂度的权重值的L2 正则化项参数,参数越大,模型越不容 易过拟合 'subsample':0.7, # 随机采样训练样本 'colsample_bytree':3,# 这个参数默认为1,是每个叶子里面h的和至少是多少 # 对于正负样本不均衡时的0-1分类而言,假设h在0.01附近, #min_child_weight为1意味着叶子节点中最少需要包含100个样本。 #这个参数非常影响结果,控制叶子节点中二阶导的和的最小值,该 #参数值越小,越容易过拟合。 'silent':0, # 设置成1 则没有运行信息输入,最好是设置成0 'eta':0.007, # 如同学习率 'seed':1000, 'nthread':7, #CPU线程数 #'eval_metric':'auc' } |
安装XGBoost建议使用conda命令。如:conda install py-xgboost=0.90
2.2 NN简介
使用的神经网络结构如下图所示
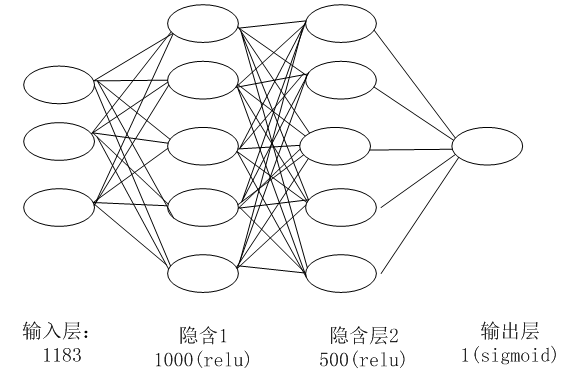
图2-1 神经网络结构
本实例使用的神经网络结构比较简单,共4层,除输入、输出层外,中间是两个全连接层。输入层1183个节点,这个正好是特征转换为one-hot后的元素个数,第1个隐含层的节点是1000,激活函数为relu,第2个隐含层的节点数为500,激活函数为relu,输出层1个节点,激活函数为sigmoid。
2.3 数据集简介
这里使用德国Rossmann超市2013、2014、2015三年的销售数据,具体数据文件包括:
train.csv-包括销售在内的历史数据
test.csv-测试数据(不包括销售)
store.csv-有关商店的补充信息
这些数据可从这里下载:https://www.kaggle.com/c/rossmann-store-sales/data
1、train.csv-包括销售在内的历史数据,共有9列,每列的含义如下:
date(日期):代表存储期
DayOfWeek(星期几):7表示周日,6表示周六以此类推
store(商店):每个商店的唯一ID
sale(销售):特定日期的营业额(这是您的预期)
customer(客户):特定日期的客户数量
open(开):为对存储是否被打开的指示:0 =关闭,1 =开
promo(促销):表示商店当天是否在进行促销
StateHoliday(州假日):通常,除州外,所有商店都在州法定假日关闭。请注意,所有学校在公共假日和周末都关闭。a =公共假期,b =复活节假期,c =圣诞节,0 =无
SchoolHoliday(学校假日):指示(商店,日期)是否受到公立学校关闭的影响
(1)导入数据
|
1 2 3 4 5 |
import pandas as pd import numpy as np store = pd.read_csv(r".\data\rossmann\store.csv") train = pd.read_csv(r".\data\rossmann\train.csv",index_col = "Date",parse_dates = ['Date'],low_memory=False) test = pd.read_csv(r".\data\rossmann\test.csv",index_col = "Date",parse_dates = ['Date'],low_memory=False) |
(2)查看前5行数据。

(3)查看是否有空值
|
1 2 |
#查看是否有空值 train.isnull().sum() |
Store 0
DayOfWeek 0
Sales 0
Customers 0
Open 0
Promo 0
StateHoliday 0
SchoolHoliday 0
dtype: int64
(4)查看各特征的不同值
|
1 2 3 4 |
#查看各字段的不同值 train['Year'] = train.index.year print("共有几年的数据:",train['Year'].unique()) print("共有几种促销方法:",train['Promo'].unique()) |
共有几年的数据: [2015 2014 2013]
共有几种促销方法: [1 0]
2、store.csv数据集简介
StoreType- 区分4种不同的商店模型:a,b,c,d
Assortment分类 -描述分类级别:a =基本,b =额外,c =扩展
CompetitionDistance-距离最近的竞争对手商店的距离(以米为单位)
CompetitionOpenSince [Month / Year] -给出最近的竞争对手开放的大概年份和月份。
Promo促销 -表示商店当天是否在进行促销
Promo2 -Promo2是某些商店的连续和连续促销:0 =商店不参与,1 =商店正在参与
Promo2Since [年/周] -描述商店开始参与Promo2的年份和日历周。
PromoInterval-描述启动Promo2的连续间隔,并指定重新开始促销的月份。例如,“ Feb,May,Aug,Nov”表示该商店的每一轮始于该年任何一年的2月,5月,8月,11月

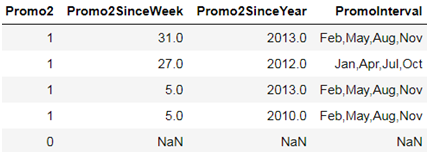
2.4使用Xgboost算法实例
2.4.1 读取数据
(1)导入模块
|
1 2 3 4 5 6 |
import pickle import csv #屏蔽警告信息 import warnings warnings.filterwarnings('ignore') |
(2)定义数据预处理函数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
#把csv文件转换为字典 def csv2dicts(csvfile): data = [] keys = [] for row_index, row in enumerate(csvfile): #把第一行标题打印出来 if row_index == 0: keys = row print(row) continue # if row_index % 10000 == 0: # print(row_index) data.append({key: value for key, value in zip(keys, row)}) return data #如果值为空,则用'0'填充 def set_nan_as_string(data, replace_str='0'): for i, x in enumerate(data): for key, value in x.items(): if value == '': x[key] = replace_str data[i] = x |
(3)读取数据
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
train_data = "train.csv" store_data = "store.csv" store_states = 'store_states.csv' #读取数据 with open(train_data) as csvfile: data = csv.reader(csvfile, delimiter=',') with open('train_data.pickle', 'wb') as f: data = csv2dicts(data) #头尾倒过来 data = data[::-1] #序列化,把数据保存到文件中 pickle.dump(data, f, -1) print(data[:3]) |
2.4.2 预处理数据
(1)导入模块
|
1 2 3 4 5 6 |
import pickle from datetime import datetime from sklearn import preprocessing import numpy as np import random random.seed(42) |
(2)读取处理后的文件
|
1 2 3 4 5 |
with open('train_data.pickle', 'rb') as f: train_data = pickle.load(f) num_records = len(train_data) with open('store_data.pickle', 'rb') as f: store_data = pickle.load(f) |
(3)定义预处理store数据函数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
#对时间特征进行拆分和转换,是是否促销promo等特征转换为整数 def feature_list(record): dt = datetime.strptime(record['Date'], '%Y-%m-%d') store_index = int(record['Store']) year = dt.year month = dt.month day = dt.day day_of_week = int(record['DayOfWeek']) try: store_open = int(record['Open']) except: store_open = 1 promo = int(record['Promo']) #同时返回state对应的简称 return [store_open, store_index, day_of_week, promo, year, month, day, store_data[store_index - 1]['State'] ] |
(4)生成训练数据
|
1 2 3 4 5 6 7 8 9 10 11 |
train_data_X = [] train_data_y = [] for record in train_data: if record['Sales'] != '0' and record['Open'] != '': fl = feature_list(record) train_data_X.append(fl) train_data_y.append(int(record['Sales'])) print("Number of train datapoints: ", len(train_data_y)) print(min(train_data_y), max(train_data_y)) |
2.4.3 保存预处理数据
(1)把各类别特征转换为整数,并保存为pickle文件
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
full_X = train_data_X full_X = np.array(full_X) train_data_X = np.array(train_data_X) les = [] #对每列进行处理,先把类别转换为数值,然后转换为独热编码 for i in range(train_data_X.shape[1]): le = preprocessing.LabelEncoder() le.fit(full_X[:, i]) les.append(le) train_data_X[:, i] = le.transform(train_data_X[:, i]) with open('les.pickle', 'wb') as f: pickle.dump(les, f, -1) train_data_X = train_data_X.astype(int) train_data_y = np.array(train_data_y) #保存数据到feature_train_data.pickle文件 with open('feature_train_data.pickle', 'wb') as f: pickle.dump((train_data_X, train_data_y), f, -1) print(train_data_X[0], train_data_y[0]) |
2.4.4 采样生成训练与测试数据
(1)读取数据
|
1 2 3 4 5 6 |
train_ratio = 0.9 f = open('feature_train_data.pickle', 'rb') (X, y) = pickle.load(f) num_records = len(X) train_size = int(train_ratio * num_records) |
(2)生成训练与测试集
|
1 2 3 4 |
X_train = X[:train_size] X_val = X[train_size:] y_train = y[:train_size] y_val = y[train_size:] |
(3)定义采样函数
|
1 2 3 4 5 |
def sample(X, y, n): '''random samples''' num_row = X.shape[0] indices = numpy.random.randint(num_row, size=n) return X[indices, :], y[indices] |
(4)采样数据
|
1 2 |
X_train, y_train = sample(X_train, y_train, 200000) # Simulate data sparsity print("Number of samples used for training: " + str(y_train.shape[0])) |
2.4.5 构建模型
(1)导入模块
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import tensorflow as tf import numpy numpy.random.seed(123) from sklearn import linear_model from sklearn.ensemble import RandomForestRegressor from sklearn.svm import SVR from sklearn.preprocessing import StandardScaler import xgboost as xgb from sklearn import neighbors from sklearn.preprocessing import Normalizer from tensorflow.keras.models import Sequential from tensorflow.keras.models import Model as KerasModel from tensorflow.keras.layers import Input, Dense, Activation, Reshape,Flatten from tensorflow.keras.layers import Concatenate from tensorflow.keras.layers import Embedding from tensorflow.keras.callbacks import ModelCheckpoint |
(2)构建xgboost模型
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
class Model(object): def evaluate(self, X_val, y_val): assert(min(y_val) > 0) guessed_sales = self.guess(X_val) relative_err = numpy.absolute((y_val - guessed_sales) / y_val) result = numpy.sum(relative_err) / len(y_val) return result class XGBoost(Model): def __init__(self, X_train, y_train, X_val, y_val): super().__init__() dtrain = xgb.DMatrix(X_train, label=numpy.log(y_train)) evallist = [(dtrain, 'train')] param = {'nthread': -1, 'max_depth': 7, 'eta': 0.02, 'silent': 1, 'objective': 'reg:linear', 'colsample_bytree': 0.7, 'subsample': 0.7} num_round = 3000 self.bst = xgb.train(param, dtrain, num_round, evallist) print("Result on validation data: ", self.evaluate(X_val, y_val)) def guess(self, feature): dtest = xgb.DMatrix(feature) return numpy.exp(self.bst.predict(dtest)) |
2.4.6 训练模型
|
1 2 3 |
models = [] print("Fitting XGBoost...") models.append(XGBoost(X_train, y_train, X_val, y_val)) |
运行结果如下:
[2980] train-rmse:0.148366
[2981] train-rmse:0.148347
[2982] train-rmse:0.148314
[2983] train-rmse:0.148277
[2984] train-rmse:0.148238
[2985] train-rmse:0.148221
[2986] train-rmse:0.148218
[2987] train-rmse:0.148187
[2988] train-rmse:0.148182
[2989] train-rmse:0.148155
[2990] train-rmse:0.148113
[2991] train-rmse:0.148113
[2992] train-rmse:0.148067
[2993] train-rmse:0.148066
[2994] train-rmse:0.148064
[2995] train-rmse:0.148062
[2996] train-rmse:0.148048
[2997] train-rmse:0.148046
[2998] train-rmse:0.148046
[2999] train-rmse:0.148041
Result on validation data: 0.14628885960491078
2.5 使用NN算法实例
2.5.1 预处理数据
导入数据、对数据进行预处理,这些与2.4小节中的2.4.1、2.4.2一样,接下来对个特征先转换为数字,然后转换为one-hot编码,并保存。
(1)把数据转换为one-hot编码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
encoded_x = None full_X = train_data_X full_X = np.array(full_X) train_data_X = np.array(train_data_X) for i in range(train_data_X.shape[1]): label_encoder = preprocessing.LabelEncoder() feature = label_encoder.fit_transform(train_data_X[:,i]) feature = feature.reshape(train_data_X.shape[0], 1) onehot_encoder = preprocessing.OneHotEncoder(sparse=False) feature = onehot_encoder.fit_transform(feature) if encoded_x is None: encoded_x = feature else: encoded_x = np.concatenate((encoded_x,feature),axis=1) print("X shape: : ", encoded_x.shape) |
(2)保存数据
|
1 2 3 4 5 6 7 |
train_data_X =encoded_x.astype(int) train_data_y = np.array(train_data_y) #保存数据到feature_train_data.pickle文件 with open('feature_train_data.pickle', 'wb') as f: pickle.dump((train_data_X, train_data_y), f, -1) print(train_data_X[0], train_data_y[0]) |
2.5.2 生成训练数据
(1)读取数据
|
1 2 3 4 5 6 |
train_ratio = 0.9 f = open('feature_train_data.pickle', 'rb') (X, y) = pickle.load(f) num_records = len(X) train_size = int(train_ratio * num_records) |
(2)生成训练数据
|
1 2 3 4 |
X_train = X[:train_size] X_val = X[train_size:] y_train = y[:train_size] y_val = y[train_size:] |
(3)定义采样函数
|
1 2 3 4 5 |
def sample(X, y, n): '''random samples''' num_row = X.shape[0] indices = numpy.random.randint(num_row, size=n) return X[indices, :], y[indices] |
(4)通过采样生成训练数据
|
1 2 |
X_train, y_train = sample(X_train, y_train, 200000) # Simulate data sparsity print("Number of samples used for training: " + str(y_train.shape[0])) |
2.5.3 构建神经网络模型
(1)导入模块
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import tensorflow as tf import numpy numpy.random.seed(123) from sklearn import linear_model from sklearn.ensemble import RandomForestRegressor from sklearn.svm import SVR from sklearn.preprocessing import StandardScaler import xgboost as xgb from sklearn import neighbors from sklearn.preprocessing import Normalizer from tensorflow.keras.models import Sequential from tensorflow.keras.models import Model as KerasModel from tensorflow.keras.layers import Input, Dense, Activation, Reshape,Flatten from tensorflow.keras.layers import Concatenate from tensorflow.keras.layers import Embedding from tensorflow.keras.callbacks import ModelCheckpoint |
(2)定义Model类
|
1 2 3 4 5 6 7 8 |
class Model(object): def evaluate(self, X_val, y_val): assert(min(y_val) > 0) guessed_sales = self.guess(X_val) relative_err = numpy.absolute((y_val - guessed_sales) / y_val) result = numpy.sum(relative_err) / len(y_val) return result |
(3)构建神经网络
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
class NN(Model): def __init__(self, X_train, y_train, X_val, y_val): super().__init__() self.epochs = 10 self.checkpointer = ModelCheckpoint(filepath="best_model_weights.hdf5", verbose=1, save_best_only=True) self.max_log_y = max(numpy.max(numpy.log(y_train)), numpy.max(numpy.log(y_val))) self.__build_keras_model() self.fit(X_train, y_train, X_val, y_val) def __build_keras_model(self): self.model = Sequential() self.model.add(Dense(1000, kernel_initializer="uniform", input_dim=1183)) #self.model.add(Dense(1000, kernel_initializer="uniform", input_dim=8)) self.model.add(Activation('relu')) self.model.add(Dense(500, kernel_initializer="uniform")) self.model.add(Activation('relu')) self.model.add(Dense(1)) self.model.add(Activation('sigmoid')) self.model.compile(loss='mean_absolute_error', optimizer='adam') def _val_for_fit(self, val): val = numpy.log(val) / self.max_log_y return val def _val_for_pred(self, val): return numpy.exp(val * self.max_log_y) def fit(self, X_train, y_train, X_val, y_val): self.model.fit(X_train, self._val_for_fit(y_train), validation_data=(X_val, self._val_for_fit(y_val)), epochs=self.epochs, batch_size=128, # callbacks=[self.checkpointer], ) # self.model.load_weights('best_model_weights.hdf5') print("Result on validation data: ", self.evaluate(X_val, y_val)) def guess(self, features): result = self.model.predict(features).flatten() return self._val_for_pred(result) |
2.5.4 训练模型
|
1 2 3 4 |
models = [] print("Fitting NN...") for i in range(1): models.append(NN(X_train, y_train, X_val, y_val)) |
运行结果:
Fitting NN...
Train on 200000 samples, validate on 84434 samples
Epoch 1/10
200000/200000 [==============================] - 12s 60us/sample - loss: 0.0121 - val_loss: 0.0142
Epoch 2/10
200000/200000 [==============================] - 11s 54us/sample - loss: 0.0080 - val_loss: 0.0104
Epoch 3/10
200000/200000 [==============================] - 11s 53us/sample - loss: 0.0071 - val_loss: 0.0100
Epoch 4/10
200000/200000 [==============================] - 11s 54us/sample - loss: 0.0064 - val_loss: 0.0099
Epoch 5/10
200000/200000 [==============================] - 11s 54us/sample - loss: 0.0059 - val_loss: 0.0098
Epoch 6/10
200000/200000 [==============================] - 11s 54us/sample - loss: 0.0055 - val_loss: 0.0103
Epoch 7/10
200000/200000 [==============================] - 11s 55us/sample - loss: 0.0051 - val_loss: 0.0100
Epoch 8/10
200000/200000 [==============================] - 11s 54us/sample - loss: 0.0047 - val_loss: 0.0099
Epoch 9/10
200000/200000 [==============================] - 11s 53us/sample - loss: 0.0045 - val_loss: 0.0102
Epoch 10/10
200000/200000 [==============================] - 11s 54us/sample - loss: 0.0042 - val_loss: 0.0100
Result on validation data: 0.10825838109273625
接下来将用更多实例,从多个角度比较NN与传统ML的比较,带EE(Entity Embedding)的NN与不带NN的比较,带EE的传统ML与不带EE的传统ML,以及EE在ML的顶级应用(如推荐算法、预测等问题上的使用)。
EE就像一座桥梁,把结构化数据与NN(或深度学习算法)连接在一起,大大发挥了NN在处理结构化数据方面的潜能(即NN强大的学习能力),深度学习将彻底改变传统机器学习。
1 分类特征传统处理方法
分类(Categorical)特征常被称为离散特征、分类特征,数据类型通常是object类型,而机器学习模型通常只能处理数值数据,所以需要对Categorical数据转换成Numeric特征。
Categorical特征又有两类,我们需要理解它们的具体含义并进行对应的转换。
(1)有序(Ordinal)类型:
这种类型的Categorical存在着自然的顺序结构,如果你对Ordinal 类型数据进行排序的话,可以是增序或者降序,比如在衣服型号这个特征中具体的值可能有:S、M、L、XL等衣服尺码,其中S:(Small)表示小 ,M(Middle)表示中 ,L(Large)表示大,XL(extra large)表示加大尺码,它们之间有XL>L>M>S的大小关系。
(2)常规(Nominal)类型或无序类型:
这种是常规的Categorical类型,不能对Nominal类型数据进行排序,这类特征无谁大谁小之分。比如颜色特征可能的值有:red、yellow、blue、black等,我们不能说red>yellow>blue>black。
对于Ordinal和Nominal类型数据有不同的方法将它们转换成数字。
1.1 处理有序类型
对于Ordinal类型数据可以使用OrdinalEncoder、LabelEncoder进行编码处理,功能相同,都将每一个类别的特征转换成一个新的整数(0到类别数n-1之间)。例如S、M、L、XL等衣服尺码这四个类别进行OrdinalEncoder(或LabelEncoder)处理后会映射成0、1、2、3,这样数据间的自然大小关系也会保留下来。以下数据集data_set共有4列,这4列从左到右分别表示型号、颜色、性别、标签。其中型号为有序类别,其它都是常规类别。这些都是字符,现在利用sklearn中预处理模块preprocessing,把型号转换为数字,具体代码如下:
(1)导入数据
|
1 2 3 4 5 6 |
from sklearn.preprocessing import OrdinalEncoder,LabelEncoder,OneHotEncoder import numpy as np import numpy as np data_set=np.array([['L','red','Female','yes'],['M','red','Male','no'],['M','yellow','Female','yes'],['XL','blue','Male','no']]) |
data_set的结果如下
array([['L', 'red', 'Female', 'yes'],
['M', 'red', 'Male', 'no'],
['M', 'yellow', 'Female', 'yes'],
['XL', 'blue', 'Male', 'no']], dtype='<U6')
(2)进行转换
|
1 2 3 4 5 6 |
x1 = data_set[:,0] #获取第1列数据 x1=x1.reshape(-1,1) #转换为2D,transform传递的X一定要是2D的,即 #(samples,features) oe = OrdinalEncoder() #实例化 ord=oe.fit(x1) #导入数据 oe.transform(x1) #转换后的数据为:array([[0],[1],[1],[]2]) oe.categories_ #属性.categories_查看类别特征究竟有多少类别 |
1.2 处理常规类型
1.1节用OrdinalEncoder、OrdinalEncoder把分类变量型号转换为数字,同样可以把颜色、性别、标签等这些属于常规类型的特征转换为整数(0到类别数n-1之间)。具体代码如下:
1.2.1 把标签转换为数字
使用LabelEncoder把标签特征转换为数字。
|
1 2 3 4 5 |
y = data_set[:,-1] #获取最后一列数据 le = LabelEncoder() #实例化 le.fit_transform(y) #也可以直接fit_transform一步到位 le.classes_ #属性.classes_查看标签中究竟有多少类别['no', 'yes'] label #查看获取的结果label[1, 0, 1, 0] |
1.2.2 把颜色、性别转换为数字
|
1 2 3 4 |
x2 = data_set[:,1:-1] #获取第2、3列数据 oe = OrdinalEncoder() #实例化 ord=oe.fit_transform(x2) #导入数据并进行转换 print(ord) |
运行结果如下:
[[1. 0.]
[1. 1.]
[2. 0.]
[0. 1.]]
在表示颜色这一列中,我们使用[0,1,2]代表了三个不同的颜色,然而这种转换是正确的吗?[0,1,2]这三个数字在算法看来,是连续且可以计算的,这三个数字相互不等,有大小,甚至有着可以相加相乘的联系。所以算法会把颜色,性别这样的常规分类特征,都误会成是有序特征这样的分类特征,把本来互相平等、独立的颜色特征误认为有大小的区分,如blue>yellow>red,blue的重要性是yellow颜色的2倍,这显然是不合理的。因此,我们把分类转换成数字的时候,忽略了数字中自带的数学性质,所以给算法传达了一些不准确的信息,而这会影响我们的建模。如何解决这个问题?
对于Nominal类型数据可以使用OneHotEncoder进行编码处理,尽量向算法传达最准确的信息。
1.2.3 使用OneHotEncoder方法
对于常规类别特征采用独热编码(One-Hot)方式处理,可以保证特征的基本属性,向算法专递最准确的信息。one-hot如何做到这点的呢?首先我们来了解一下one-hot编码的原理。
独热编码会为每个离散值创建一个哑特征(dummy feature)。什么是哑特征呢?举例来说,对于‘颜色’这一特征中的‘blue’,我们将其编码为[blue=1,yellow=0,red=0],同理,对于‘yellow’,我们将其编码为[blue=0,yellow=1,red=0],特点就是向量只有一个1,其余均为0,故称之为one-hot。即把颜色特征转换成如下表示:
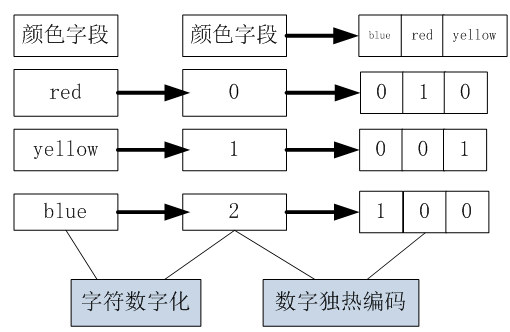
图1-1 one-hot编码示意图
从图1-1可知,独热编码进行了如下转换:
①把字符类型转换为数字类型。
②把一个字段(颜色字段)变成3个字段(字段个数为颜色的类别总数)
③对新创建的3个字段,颜色对应位置的值置为1,其它2列位置的都是0。
这么做的目的是为了保证每一个离散取值的“无序性、公平性、彼此正交性”。
下面我们用代码实现颜色和性别字段的one-hot转换。
(1)把字符转换为数字
|
1 2 3 4 |
x2 = data_set[:,1:-1] #获取第2、3列数据 oe=OrdinalEncoder() #实例化 x2=oe.fit_transform(x2) #先把字符转换为数字型 print(x2) |
打印结果如下:
[[1. 0.]
[1. 1.]
[2. 0.]
[0. 1.]]
(2)把数字转换为独热编码
|
1 2 3 |
oh = OneHotEncoder(categories='auto') #实例化 x3=oh.fit_transform(x2).toarray() #导入数据并进行转换 print(x3) |
打印结果如下:
[[0. 1. 0. 1. 0.]
[0. 1. 0. 0. 1.]
[0. 0. 1. 1. 0.]
[1. 0. 0. 0. 1.]]
前3列为颜色,后2列为性别。
【说明】OneHotEncoder是sklearn方法,pandas有一个对于方法,即get_dummies,它可直接把字符转换为oneHot编码。具体使用可参考如下博客:
https://blog.csdn.net/maymay_/article/details/80198468
对于Nominal类型数据可以使用独热编码(OneHotEncoder)有其合理的一面,但也有很多不足,如当遇到大数据,一个特征的类别很多几百,甚至几千或更多,而且这样的特征还有很多,如此一来,把这些特征转换成one-hot编码后,特征数将非常巨大!此外,这种方法只是简单把类别数据转换成0或1,无法准确反应这些特征内容隐含的一些规则或这些类别的分布信息,如一个表示地址的特征,可能包括北京、上海、杭州、美国纽约、华盛顿、洛杉矶,东京、大阪等等,这些属性具有一定分布特性,北京、上海、杭州之间的距离较近,而上海与纽约之间的距离应该比较远,诸如此类问题,one-hot是无法表示的。
是否有更有好、更有效的处理方法呢?有,就是接下来将介绍的Learned Embedding方法。
2 使用Embendding方法处理分类特征
2.1传统处理方法的不足
(1)无法真是反应特征的含义
如果仅仅把分类特征转换为数字,可能将无序变成有序,有序的变成可运算(如把M,X,XL转变为0、1、2,那么1+1=2,即X+X=XL,这显然不合逻辑)。
(2)容易导致维度暴增
如果把分类特征转换为one-hot编码,虽然可以使常规分类特征表现更公平、独立,但极易导致维度暴增。如比如阿里上的商品维度就至少是千万量级的,而且这样的商品很多,如果采用one-hot编码,则维度马上变成亿级以上。如果处理语言,词汇量更是几千、几万。除了维度暴增,还导致矩阵的极端稀疏,而太过稀疏数据不利于在机器学习或深度学习中提升性能或增强其泛化能力的。
(3)无法揭示特征内部的规则
很多商品、地址、词汇分类特征,其内容往往包含很多规则,如商品之间的层次关系、地址之间的依赖关系、词汇之间的相似性等,无法通过简单数字化来表达。
2.2 Embedding方法简介
近几年,从计算机视觉到自然语言处理再到时间序列预测,神经网络、深度学习的应用越来越广泛。在深度学习的应用过程中,Embedding 这样一种将离散变量转变为连续向量的方式为传统机器学习、神经网络在各方面的应用带来了极大的扩展。该技术目前主要有两种应用,NLP 中常用的Word Embedding以及用于类别数据的Entity Embedding。
简单来说,Embedding就是用一个低维的向量表示一个事物,可以是一个词、一个类别特征(如商品,电影、物品等)或时间序列特征等。这个Embedding向量通过学习可更准确的表示对应特征的内在含义,使距离相近的向量对应的物体有相近的含义,如图1-2所示
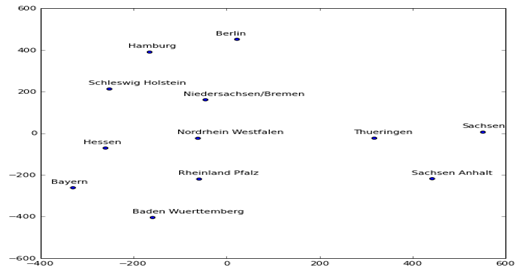
图1-2 可视化销售地址的Embedding
图1-2 是一个有关销售地址的Embedding图形,这是通过神经网络不断学习,得到有关销售地址的Embedding向量,具体代码实现方法后续将介绍。
Embedding往往放在神经网络的第一层,Embedding层可以训练过程不断更新,可以学习到对应特征的内在关系,含Embedding的网络结构可参考图1-3,所以Embedding有时又称为Learned Embedding。一个模型学习到的learned Embedding,也可以被其他模型重用。
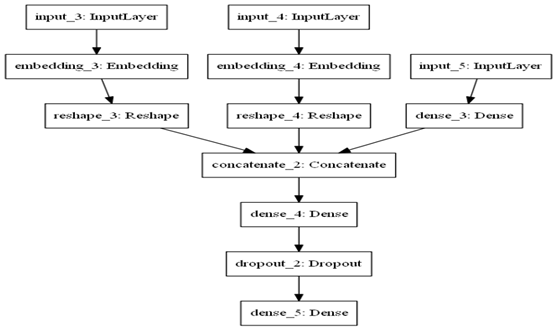
图1-3 含Embedding层的神经网络结构图
图1-3把两个分类特征(input_3,input_4)转换为Embedding后,与连续性输入特征(input_5)合并在一起,然后,连接全连接层等。在训练过程中,Embedding向量不断更新。
Embedding的灵感来自Word2Vec,但与Word2Vec有些不同,Word2Vec是google于2013年开源的一个计算词向量的工具。
目前各大深度学习平台都提供了Embedding层:
PyTorch1+的Embedding层是:
torch.nn.Embedding(m,n),
TensorFlow2+的Embedding层为:
tf.layers.Embedding(vocab_size, embedding_dim, input_length=maxlen),
keras的是:
keras.layers.Embedding(input_dim, output_dim, embeddings_initializer='uniform', embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None)
2.3 Embedding的拓展
近些年Embedding发展很快,可以说很多内容都可表示为Embedding,从最初的word2vec到类别特征可以表示为Embedding(又成为Entity Embedding),时间序列数据可以表示Sequnce Embedding,目前推荐系统经常使用的Item Embedding和User Embedding,和目前的研究热点之一的Graph Embedding等等。可以说万物都可Embedding,目前Embedding已成为深度学习的基本操作。
2.4 Embedding方法的巨大威力
(1)Embedding在各种比赛中取得名列前茅
在结构化数据上运用神经网络时,Entiry Embedding表现的很好。 例如,在Kaggle竞赛”预测出租车的距离问题”上获得第1名的解决方案,就是使用Entiry Embedding来处理每次乘坐的分类元数据(Alexandre de Brébisson,2015)。 同样,预测Rossmann药店销售任务的获得第3名的解决方案使用了比前两个方案更简单的方法: 使用简单的前馈神经网络, 再加上类别变量的Entity Embedding。它包括超过1000个类别的变量,如商店ID(Guo&Berkahn,2016),作者把比赛结果汇总在一篇论文中(Entity Embeddings of Categorical Variables),在论文作者使用Embedding对传统机器学习与神经网络进行纵向和横行的比较,结果如表1-1。
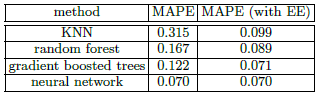
表1-1的结果对原打乱,然后取10%的测试数据。
从表1-1可以看出,如果不使用EE(Entity Embedding),神经网络的性能优于传统机器学习,如果使用EE,效果就更加明显。

表1-2 不打乱原数据,从最新的数据中取10%作为测试数据。
(2)Embedding是现代推荐系统中重要部分
微软的 Deep Crossing、Google 的 Wide&Deep 、YouTube深度学习推荐系统、阿里 DIN(2018 年)、华为 DeepFM系统、美团的推荐系统等等都把Embedding作为其重要组件。图1-4 为Google Wide&Deep(2016 年)的架构图。

图1-4 Google Wide&Deep架构图
3、小试牛刀:使用Embedding处理类别特征
本实例使用breast-cancer1数据集(下载),共有10列,其中前9列为分类特征,最后1列为标签,共有285行数据。
主要步骤如下:
(1)导入需要的模块
(2)定义导入数据的函数
首先,数据中含?的项替换为nan值,然后删除含nan的行。然后把前9列放入X,最后1列放入y
(3)先把类别特征数字化,然后在转换为长度都为10的Embedding向量
(4)合并这些Embedding向量
(5)构建模型,模型结构如1-5所示。
模型结构图1-5所示
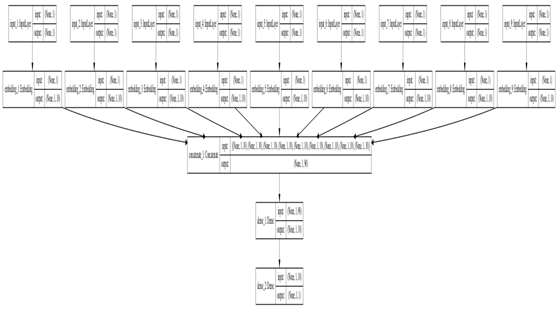
图1-5
(6)训练及评估模型
通过一般分类特征处理方法及使用传统机器学习该数据集能获得74%左右的精度,这里得到77%左右的精度。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 |
from numpy import unique from pandas import read_csv import numpy as np from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from tensorflow.keras.models import Model from tensorflow.keras.layers import Input from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Embedding from tensorflow.keras.layers import concatenate from tensorflow.keras.utils import plot_model #屏蔽警告信息 import warnings warnings.filterwarnings('ignore') # 定义导入数据函数 def load_dataset(filename): # load the dataset as a pandas DataFrame data = read_csv(filename, header=None) #删除含值为?的行 data = data.replace(to_replace='?',value=np.nan) data = data.dropna(how = 'any') # retrieve numpy array dataset = data.values # split into input (X) and output (y) variables X = dataset[:, :-1] y = dataset[:,-1] # format all fields as string X = X.astype(str) # 把标签数据转换为2D数据 y = y.reshape((len(y), 1)) return X, y # 先把各特征转换为数字 def prepare_inputs(X_train, X_test): X_train_enc, X_test_enc = list(), list() # label encode each column for i in range(X_train.shape[1]): le = LabelEncoder() le.fit(X_train[:, i]) # encode train_enc = le.transform(X_train[:, i]) test_enc = le.transform(X_test[:, i]) # store X_train_enc.append(train_enc) X_test_enc.append(test_enc) return X_train_enc, X_test_enc # 把标签列转换为数字 def prepare_targets(y_train, y_test): le = LabelEncoder() le.fit(y_train) y_train_enc = le.transform(y_train) y_test_enc = le.transform(y_test) return y_train_enc, y_test_enc # 加载数据 X, y = load_dataset(r'D:\python-script\py\data\breast-cancer1.csv') # 划分数据 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # prepare input data X_train_enc, X_test_enc = prepare_inputs(X_train, X_test) # prepare output data y_train_enc, y_test_enc = prepare_targets(y_train, y_test) # make output 3d y_train_enc = y_train_enc.reshape((len(y_train_enc), 1, 1)) y_test_enc = y_test_enc.reshape((len(y_test_enc), 1, 1)) # 把特征转换为长度为10的向量 in_layers = list() em_layers = list() for i in range(len(X_train_enc)): # calculate the number of unique inputs n_labels = len(unique(X_train_enc[i])) # define input layer in_layer = Input(shape=(1,)) # define embedding layer em_layer = Embedding(n_labels, 10)(in_layer) # store layers in_layers.append(in_layer) em_layers.append(em_layer) # 合并所用embedding向量 merge = concatenate(em_layers) dense = Dense(10, activation='relu', kernel_initializer='he_normal')(merge) output = Dense(1, activation='sigmoid')(dense) model = Model(inputs=in_layers, outputs=output) # compile the keras model model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 把模型保存到磁盘 plot_model(model, show_shapes=True, to_file='embeddings.png') # fit the keras model on the dataset model.fit(X_train_enc, y_train_enc, epochs=20, batch_size=16, verbose=2) # 评估模型 _, accuracy = model.evaluate(X_test_enc, y_test_enc, verbose=0) print('Accuracy: %.2f' % (accuracy*100)) |
运行结果如下:
Epoch 15/20
184/184 - 0s - loss: 0.4477 - accuracy: 0.7989
Epoch 16/20
184/184 - 0s - loss: 0.4399 - accuracy: 0.8152
Epoch 17/20
184/184 - 0s - loss: 0.4351 - accuracy: 0.8152
Epoch 18/20
184/184 - 0s - loss: 0.4305 - accuracy: 0.8043
Epoch 19/20
184/184 - 0s - loss: 0.4250 - accuracy: 0.8043
Epoch 20/20
184/184 - 0s - loss: 0.4212 - accuracy: 0.8043
Accuracy: 77.17
欢迎加入本书的在线答疑及交流群!加入QQ:799038260 或扫以下二维码
本书代码及数据下载
提取码:lyl0
目 录
第一部分 Embedding基础部分
第1章 万物皆可Embedding
第2章 获取Embedding的几种方法
第3 章 计算机视觉处理
第4章 文本及序列处理
第5章 注意力机制
第6章 从Word Embedding到ELMO
第7章 从ELMo到BERT和GPT
1.GPT可视化
2.GPT-3简介
3.ChatGPT简介
第8章 BERT几种典型改进方法
第9章 推荐系统
第二部分 Embedding应用实例
第10 章 用Embedding表现分类特征
第11 章 用Embedding提升机器学习性能
第12 章 用Transformer实现英文翻译中文
第13 章 Embedding在推荐系统中的应用
第14章 用BERT实现中文语句分类
第15章 用GPT2生成文本
第16章 Embedding技术总结
我这次TensorFlow的升级之路,可以用一句话来概括:“山重水复疑无路,柳暗花明又一村”
1.1环境分析
1、目标:升级到TensorFlow-GPU 2.0
2、原有环境:
Python3.6,TensorFlow-GPU 1.6,ubuntu16.04,GPU驱动为NVIDIA-SMI 387.26
3、“硬核”:
①如果要升级到TensorFlow-gpu 2.0,cuda 应该是10.+,而10.+,根据下表1-1可知,GPU的Driver Version应该>=410+,但我目前的Driver Version 387.26。
②TensorFlow支持Python3.7
4、在安装TensorFlow-gpu 2.0之前需要做的事情
①升级GPU Driver Version>=410(最关键)
②安装Python3.7
③安装cuda 10
④安装TensorFlow-gpu 2.0
1.2参考资料
以下这些参考资料在安装过程中可能需要。
1、如何查找GPU型号与Driver version之间的关系?
安装新的支持cuda10+的驱动,具体安装驱动程序,可登录:
https://www.nvidia.com/Download/Find.aspx?lang=en-us 得到图1-1界面,输入对于GPU型号获取对于驱动程序。
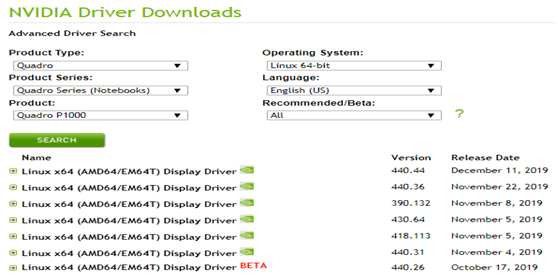
图1-1 GPU型号及产品系列兼容的Driver版本
2、安装GPU驱动有哪些常用方法?
安装GPU驱动有一些3种方法,前2种操作比较简单,第3种NVIDIA推荐的手动安装方法,定制比较高,但比较繁琐。
①使用标准Ubuntu仓库进行自动化安装
②使用PPA仓库进行自动化安装
③使用官方的NVIDIA驱动进行手动安装
3、如何查看当前内核?
安装过程中,可能会出现/boot目录空间问题,这些需要通过一些方法保证/boot空间,方法有删除一些非当前使用的内核或扩充/boot空间等方法。
①查看内核列表
|
1 |
sudo dpkg --get-selections |grep linux-image |
②查看当前使用的内核
|
1 |
uname -r |
③删除内核方法
|
1 |
sudo apt-get remove linux-image-***-generic |
1.3 安装的准备工作
1、查看显卡基本信息
通过命令nvidia-smi 查看显卡基本信息:
NVIDIA-SMI 387.26 Driver Version: 387.26
2、nvidia 驱动和cuda runtime 版本对应关系
查看nvidia官网:
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
表1-1 CUDA与其兼容的Driver版本
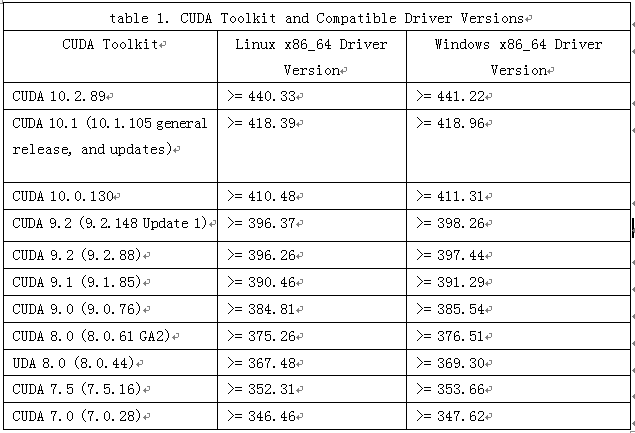
从上表可知,因我目前的GPU驱动版本为:Driver Version: 387.26,无法安装cudnn10+
需要升级GPU驱动。
1.4 升级GPU驱动
Ubuntu 社区建立了一个命名为 Graphics Drivers PPA 的全新 PPA,专门为 Ubuntu 用户提供最新版本的各种驱动程序,如Nvidia 驱动。因此我采用通过 PPA 为 Ubuntu 安装 Nvidia 驱动程序,即使用PPA仓库进行自动化安装。
1、卸载系统里的Nvidia低版本显卡驱动
|
1 |
sudo apt-get purge nvidia* |
2、把显卡驱动加入PPA
|
1 |
sudo add-apt-repository ppa:graphics-drivers |
3、更新apt-get
|
1 |
sudo apt-get update |
4、查找显卡驱动最新的版本号
|
1 |
sudo apt-get update |
返回如下信息

5、采用apt-get命令在终端安装GPU驱动
|
1 |
sudo apt-get install nvidia-418 nvidia-settings nvidia-prime |
6、重启系统并验证
(1)重启系统
|
1 |
sudo reboot |
(2)查看安装情况
在终端输入以下命令行
|
1 |
lsmod | grep nvidia |
如果没有输出,则安装失败。成功安装会有如下类似信息。
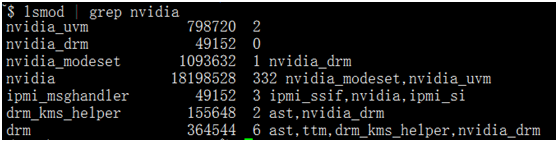
(3)查看Ubuntu自带的nouveau驱动是否运行
|
1 |
lsmod | grep nvidia |
如果终端没有内容输出,则显卡驱动的安装成功!
(4)使用nvidia-smi查看GPU驱动是否正常
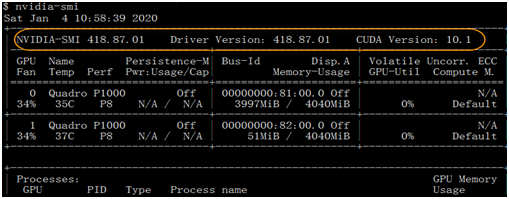
至此,GPU驱动已成功安装,驱动版本为418,接下来就可安装TensorFlow、Pytorch等最新版本了!
1.5安装Python3.7
1、安装python3.7
因TensorFlow-GPU 2.0支持python3.7,故需删除python3.6,安装python3.7
(1)使用rm -rf 命令删除目录:anaconda3
|
1 |
rm -rf anaconda3 |
(2)到anaconda官网下载最新的最新的anaconda3版本
登录:https://www.anaconda.com/distribution/
得到如下界面:
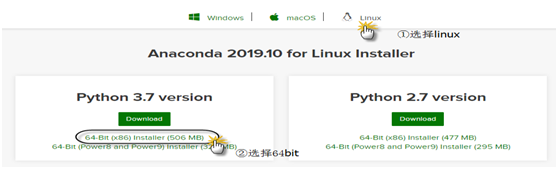
图1-2 下载anaconda界面
下载很快,506MB,5分钟左右就下载完成。
得到sh程序包:Anaconda3-2019.10-Linux-x86_64.sh
(3)安装python3.7
在命令行执行如下命令:
|
1 |
bash Anaconda3-2019.10-Linux-x86_64.sh |
安装过程中,会有几个问题,一般回答yes即可:
第一个问题:
Do you accept the license terms? [yes|no]
选择yes
第二个问题:
Anaconda3 will now be installed into this location:
~/anaconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
按回车ENTER即可
第三个问题:
Do you wish the installer to initialize Anaconda3
by running conda init? [yes|no]
选择yes将把Python安装目录,自动写入.bashrc文件
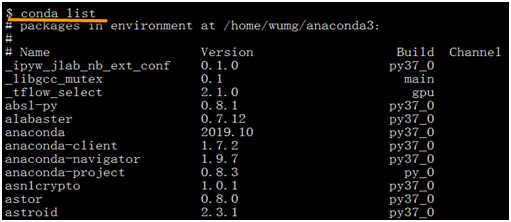
(4)使用命令conda list查看已安装的一些版本
1.6安装TensorFlow-GPU 2.0
如果使用conda安装TensorFlow-gpu 2.0,可用一个命令搞定,如果用pip安装需要3步。
1.6.1 用conda安装
使用conda安装tensorflow-gpu时,它会自动下载依赖项,比如最重要的cuda和cudnn等,其中cuda将自动安装10版本。
①先查看能安装的TensorFlow包
|
1 |
conda search tensorflw |
②安装TensorFlow-GPU 2.0
|
1 |
conda install tensorflow-gpu=2.0.0 |
1.6.2用pip安装
①先安装cudatoolkit
|
1 |
pip install cudatoolkit==10.0 |
②安装cudnn
|
1 |
pip install cudnn |
③安装TensorFlow-gpu 2.0
|
1 |
pip install tensorflow-gpu==2.0.0 |
【说明】
①如果使用conda环境(如果只有一个Python版本,也可不使用conda环境),创建环境时,采用conda create -n tf2 python=3.7,而不是之前版本的source create *。激活环境也是用conda activate tf2 。
②如果卸载需先卸载cudnn,然后再卸载cudatoolkit
1.7 Jupyter notebook的配置
可参考《Python深度学习基于TensorFlow》的8.3小节。
1.8 安装验证
1、验证tensorflow安装是否成功
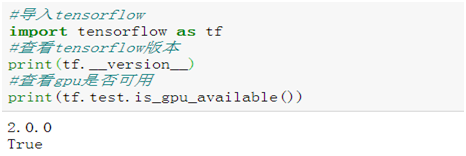
说明tensorflow-gpu安装成功,而且gpu使用正常。
1.9 TensorFlow一般方式处理实例
1.9、1.10小节,都基于以MNIST数据集,数据预处理相同,模型也相同。1.9节采用keras的一般模型训练方法,1.10节采用分布式处理方法,比较两种方式的处理逻辑、性能及所用时间等指标。
1.9.1导入需要的库
|
1 2 3 4 5 6 7 8 9 10 |
import os import sys import time import tensorflow as tf from matplotlib import pyplot as plt %matplotlib inline from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Dropout, Flatten from tensorflow.keras.layers import Conv2D, MaxPooling2D |
1.9.2导入数据
|
1 2 3 4 |
#在Keras地自带数据集中导入所需的MNIST模块 from tensorflow.keras.datasets import mnist #加载数据到Keras (x_train, y_train), (x_test, y_test) = mnist.load_data() |
1.9.3数据预处理
(1)转换为4维数组
|
1 2 |
x_train = x_train.reshape(60000, 28, 28, 1) x_test = x_test.reshape(10000, 28, 28, 1) |
(2)获取通道信息
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 定义输入图像数据的行列信息 img_rows, img_cols = 28, 28 #导入backend模块,使用函数image_data_format()获取通道位置信息 from tensorflow.keras import backend as K if K.image_data_format() == 'channels_first': x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols) x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols) input_shape = (1, img_rows, img_cols) else: x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1) x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1) input_shape = (img_rows, img_cols, 1) |
(3)对数据进行缩放
|
1 2 3 4 |
x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 |
(4)把标签数据转换为二值数据格式或one-hot格式
|
1 2 3 4 |
# 使用keras自带工具将标签数据转换成二值数据格式,以方便模型训练 import tensorflow.keras.utils as utils y_train =utils.to_categorical(y_train, 10) y_test = utils.to_categorical(y_test, 10) |
1.9.4构建模型
|
1 2 3 4 5 6 7 8 9 10 11 |
model = Sequential()#初始化序贯模型 model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28,28,1)))#二维卷积层 model.add(MaxPooling2D(pool_size=(2, 2)))#最大池化层 model.add(Conv2D(64, (3, 3), activation='relu'))#二维卷积层 model.add(MaxPooling2D(pool_size=(2, 2)))#最大池化层 model.add(Flatten())#Flatten层,把tensor转换成一维形式 model.add(Dense(64, activation='relu'))#定义全连接层 model.add(Dense(10, activation='softmax'))#定义输出层 model.summary()#查看模型结构 |
模型结构如下。

1.9.5编译模型
|
1 2 3 4 5 |
import tensorflow.keras as keras model.compile(loss=keras.losses.categorical_crossentropy, #optimizer=keras.optimizers.Adadelta(), optimizer=keras.optimizers.Adam(), metrics=['accuracy']) |
1.9.6训练模型
|
1 2 3 4 5 |
model.fit(x_train, y_train, batch_size=128, epochs=12, verbose=1, validation_data=(x_test, y_test)) |
运行结果如下。
Epoch 9/12
60000/60000 [==============================] - 5s 81us/sample - loss: 0.0133 - accuracy: 0.9958 - val_loss: 0.0259 - val_accuracy: 0.9915
Epoch 10/12
60000/60000 [==============================] - 5s 79us/sample - loss: 0.0101 - accuracy: 0.9969 - val_loss: 0.0264 - val_accuracy: 0.9916
Epoch 11/12
60000/60000 [==============================] - 5s 81us/sample - loss: 0.0083 - accuracy: 0.9973 - val_loss: 0.0338 - val_accuracy: 0.9892
Epoch 12/12
60000/60000 [==============================] - 5s 80us/sample - loss: 0.0082 - accuracy: 0.9973 - val_loss: 0.0308 - val_accuracy: 0.9910
1.9.7 GPU的使用情况
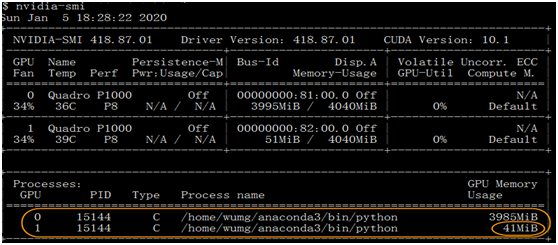
一般情况下,实际上只有一个GPU在使用,另一个几乎没有运行。
1.10 TensorFlow分布式处理实例
1.10.1概述
TensorFlow 2.0 开始支持更优的多 GPU 与分布式训练。Tensorflow的分布策略目前主要有四个Strategy:
MirroredStrategy
CentralStorageStrategy
MultiWorkerMirroredStrategy
ParameterServerStrategy
这里主要介绍第1种策略,即镜像策略(MirroredStrategy)。TensorFlow 2.0 在多 GPU 训练上是否更好了呢?是的,镜像策略用于单机多卡数据并行同步更新的情况,在每个GPU上保存一份模型副本,模型中的每个变量都镜像在所有副本中。这些变量一起形成一个名为MirroredVariable的概念变量。通过apply相同的更新,这些变量保持彼此同步。
镜像策略用了高效的All-reduce算法来实现设备之间变量的传递更新。默认情况下,它使用NVIDIA NCCL作为all-reduce实现。用户还可以在官方提供的其他几个选项之间进行选择。如图1-3所示。
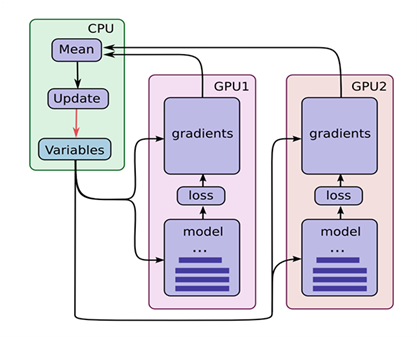
图1-3 TensorFlow使用多GPU示意图
(1)假设你的机器上有2个GPU。
(2)在单机单GPU的训练中,数据是一个batch一个batch的训练。 在单机多GPU中,数据一次处理2个batch(假设是2个GPU训练), 每个GPU处理一个batch的数据计算。
(3)变量,或者说参数,保存在CPU上。
(4)刚开始的时候数据由CPU分发给2个GPU, 在GPU上完成了计算,得到每个batch要更新的梯度。
(5)然后在CPU上收集完了2个GPU上的要更新的梯度, 计算一下平均梯度,然后更新参数。
(6)然后继续循环这个过程。
1.10.2创建一个分发变量和图形的镜像策略
|
1 2 3 4 |
strategy = tf.distribute.MirroredStrategy() print ('Number of devices: {}'.format(strategy.num_replicas_in_sync)) #训练脚本就会自动进行分布式训练。如果你只想用主机上的部分GPU训练 #strategy = tf.distribute.MirroredStrategy(devices=["/gpu:0", "/gpu:1"]) |
1.10.3定义批处理等变量
|
1 2 3 4 |
BUFFER_SIZE = len(x_train) BATCH_SIZE_PER_REPLICA = 64 GLOBAL_BATCH_SIZE = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync EPOCHS = 12 |
1.10.4创建数据集并进行分发
|
1 2 3 4 5 |
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(BUFFER_SIZE).batch(GLOBAL_BATCH_SIZE) test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(GLOBAL_BATCH_SIZE) train_dist_dataset = strategy.experimental_distribute_dataset(train_dataset) test_dist_dataset = strategy.experimental_distribute_dataset(test_dataset) |
1.10.5创建模型
|
1 2 3 4 5 6 7 8 9 10 11 12 |
def create_model(): model = tf.keras.Sequential([ tf.keras.layers.Conv2D(32, 3, activation='relu',input_shape=(28,28,1)), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(64, 3, activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Flatten(), tf.keras.layers.Dense(64, activation='relu'), tf.keras.layers.Dense(10, activation='softmax') ]) return model |
1.10.6创建存储检查点
|
1 2 3 |
# 创建检查点目录以存储检查点。 checkpoint_dir = './training_checkpoints' checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt") |
1.10.7定义损失函数
|
1 2 3 4 5 6 7 8 |
with strategy.scope(): # 将减少设置为“无”,以便我们可以在之后进行这个减少并除以全局批量大小。 loss_object = tf.keras.losses.CategoricalCrossentropy( reduction=tf.keras.losses.Reduction.NONE) # 或者使用 loss_fn = tf.keras.losses.sparse_categorical_crossentropy def compute_loss(labels, predictions): per_example_loss = loss_object(labels, predictions) return tf.nn.compute_average_loss(per_example_loss, global_batch_size=GLOBAL_BATCH_SIZE) |
1.10.8定义性能衡量指标
如损失和准确性
|
1 2 3 4 5 6 7 8 9 |
ith strategy.scope(): test_loss = tf.keras.metrics.Mean(name='test_loss') #train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy( train_accuracy = tf.keras.metrics.CategoricalAccuracy( name='train_accuracy') #test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy( test_accuracy = tf.keras.metrics.CategoricalAccuracy( name='test_accuracy') |
1.10.9训练模型
(1)定义优化器、计算损失值
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 必须在`strategy.scope`下创建模型和优化器。 with strategy.scope(): model = create_model() optimizer = tf.keras.optimizers.Adam() checkpoint = tf.train.Checkpoint(optimizer=optimizer, model=model) with strategy.scope(): def train_step(inputs): images, labels = inputs with tf.GradientTape() as tape: predictions = model(images, training=True) loss = compute_loss(labels, predictions) gradients = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(gradients, model.trainable_variables)) train_accuracy.update_state(labels, predictions) return loss def test_step(inputs): images, labels = inputs predictions = model(images, training=False) t_loss = loss_object(labels, predictions) test_loss.update_state(t_loss) test_accuracy.update_state(labels, predictions) |
(2)训练模型
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
with strategy.scope(): # `experimental_run_v2`将复制提供的计算并使用分布式输入运行它。 @tf.function def distributed_train_step(dataset_inputs): per_replica_losses = strategy.experimental_run_v2(train_step, args=(dataset_inputs,)) return strategy.reduce(tf.distribute.ReduceOp.SUM, per_replica_losses, axis=None) @tf.function def distributed_test_step(dataset_inputs): return strategy.experimental_run_v2(test_step, args=(dataset_inputs,)) for epoch in range(EPOCHS): # 训练循环 total_loss = 0.0 num_batches = 0 for x in train_dist_dataset: total_loss += distributed_train_step(x) num_batches += 1 train_loss = total_loss / num_batches # 测试循环 for x in test_dist_dataset: distributed_test_step(x) if epoch % 2 == 0: checkpoint.save(checkpoint_prefix) template = ("Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, " "Test Accuracy: {}") print (template.format(epoch+1, train_loss, train_accuracy.result()*100, test_loss.result(), test_accuracy.result()*100)) |
运行结果如下。
Epoch 9, Loss: 1.0668369213817641e-05, Accuracy: 99.91753387451172, Test Loss: 0.041710007935762405, Test Accuracy: 99.09666442871094
Epoch 10, Loss: 0.006528814323246479, Accuracy: 99.90166473388672, Test Loss: 0.04140192270278931, Test Accuracy: 99.10091400146484
Epoch 11, Loss: 0.001252010464668274, Accuracy: 99.90159606933594, Test Loss: 0.04158545285463333, Test Accuracy: 99.10043334960938
Epoch 12, Loss: 0.0014430719893425703, Accuracy: 99.90159606933594, Test Loss: 0.041613057255744934, Test Accuracy: 99.09874725341797
1.10.10 GPU使用情况
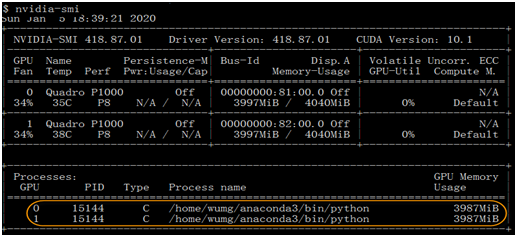
由此可知,采用分布式方式,两个GPU都得到充分使用。
1.11 建议使用conda安装TensorFlow
https://zhuanlan.zhihu.com/p/46599887
使用 TensorFlow 开展机器学习工作的朋友,应该有不少是通过 pip 下载的 TensorFlow。但是近日机器学习专家 Michael Nguyen 大声疾呼:“为了性能起见,别再用 pip 下载 TensorFlow了!”,他强力建议的理由基于以下两点:
1、更快的CPU性能Conda TensorFlow 包利用了用于深度神经网络或 1.9.0 版本以上的 MKL-DNN 网络的英特尔 Math Kernel Library(MKL),这个库能让性能大幅提升。如下图所示:
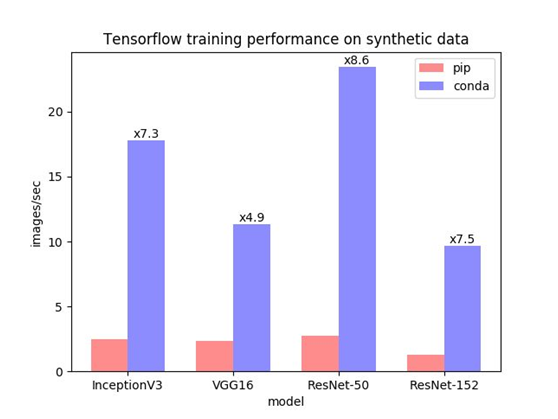
可以看到,相比 pip 安装,使用 Conda 安装后的性能足足提升了 8 倍。这对于仍然经常使用 CPU 训练的人来说,无疑帮助很大。我(Michael Nguyen——译者注)自己平时在把代码放到 GPU 驱动的机器之前,会先使用 CPU 机器跑一遍,使用 Conda 安装 TensorFlow 能大幅加快迭代速度。
MKL 库不仅能加快 TensorFlow 包的运行速度,也能提升其它一些广泛使用的程序库的速度,比如 Numpy、NumpyExr、Scikit-Learn。
2、简化 GPU 版的安装
Conda 安装会自动安装 CUDA 和 GPU 支持所需的 CuDNN 库,但 pip 安装需要你手动完成。大家都比较喜欢一步到位的吧,特别是下载很多个库的时候。
【说明】有些软件或版本使用conda安装可能找不到,这时需要使用pip安装,使用pip可以安装一些较新版本。
1.12 安装PyTorch
1、登录PyTorch官网
https://pytorch.org/
2、选择安装配置
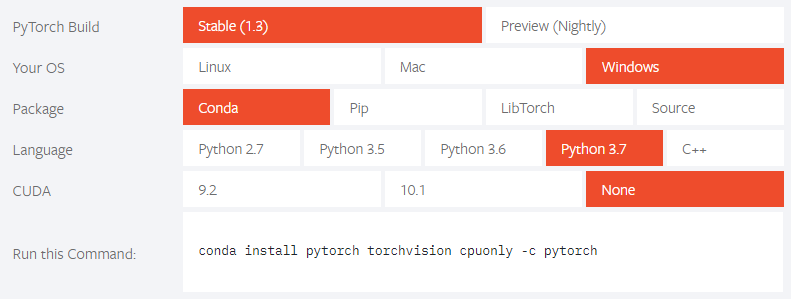
3、用conda安装
复制执行语句到命令行,进行执行,如安装cpu版的PyTorch
|
1 |
conda install pytorch torchvision cpuonly -c pytorch |
如果这种方式无法执行,或下载很慢,可把-c pytorch去掉, -c参数指明了下载pytorch的通道,优先级比清华镜像更高
使用指定的源(如清华源)可以采用如下命令,这样安装速度应该快很多。
【说明】如果在windows下安装pytorch出现对xx路径没有权重问题时,在进入cmd时,右键选择用管理员身份安装,如图所示:
|
1 2 |
#安装cpu版本 conda install pytorch torchvision cpuonly |
安装gpu conda 1010版本
|
1 2 |
#安装gpu版本 conda install pytorch torchvision cudatoolkit=10.1 |
4、使用pip安装
|
1 2 3 4 |
#安装GPU最新版本 pip install torch torchvision #安装CPU版本 pip install torch==1.4.0+cpu torchvision==0.5.0+cpu -f https://download.pytorch.org/whl/torch_stable.html |
5、验证安装是否成功
|
1 2 3 |
import torch print(torch.__version__) print(torch.cuda.is_available()) #查看GPU是否可用 |
1.13 修改安装源
我们用pip或conda安装软件时,很慢甚至时常报连接失败等问题,出现这些情况,一般是下载的源是国外的网站。可以修改安装源来大大加速下载速度及其稳定性,以下介绍几种利用清华源的方法。
1、修改conda安装源
在用户当前目录下,创建.condarc文件,然后把以下内容放入该文件即可。
|
1 2 3 4 5 6 |
channels: - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ - https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ - defaults show_channel_urls: true |
【说明】windows环境也是如此,如果没有.condarc文件,就创建。
2、修改pip安装源
为了和conda保持一致,选择还是清华的镜像源。步骤如下:
(1)修改 ~/.pip/pip.conf 文件。
|
1 |
vi ~/.pip/pip.conf |
【说明】如果是windows环境,在用户当前目录下,修改pip\pip.ini文件
没有就创建。
(2)添加源
|
1 2 3 4 |
[global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple [install] trusted-host = pypi.tuna.tsinghua.edu.cn |