3 神经网络语言模型
n-gram语言模型简单明了,解释性较好,但有几个较大缺陷:
1、维度灾难,随着n值越大,单词组合数指数级增长,由此带来相关联合或条件概率大量为0;
2、因n一般不能超过3或4,这影响模型利用单词更多邻居信息;
3、n-gram使用单词组合的频度作为计算基础,这需要提前计算,且无法泛化到相似语句或相似单词的情况。
接下来将介绍的神经网络语言模型(NNLM),可有效避免n-gram的这些不足,NNLM使用哪些方法或技术来解决这些问题的呢?请看下节内容。
3.1 神经网络语言模型
Yoshua Bengio团队在2003年在论文《A Neural Probabilistic Language Model》中提出神经网络语言模型(NNLM),可以说是后续神经网络语言模型的鼻祖,其创新点有以下几点,这些亮点也是它避免n-gram模型不足的重要方法。
1、使用词嵌入(word Embedding)代替单词索引;
2、使用神经网络计算概率
当然,这个NNLM还有很多不足,其中整个模型因使用softmax,tanh等激活函数,在面对较大的语料库时(如词汇量在几万、几百万、甚至更多)计时效率很低,而且模型有点繁琐不够简练,后续我们将介绍一些改进模型。
3.1.1 神经网络语言模型(NNLM)
Yoshua Bengio团队提出的这个NNLM的架构图1-2所示。
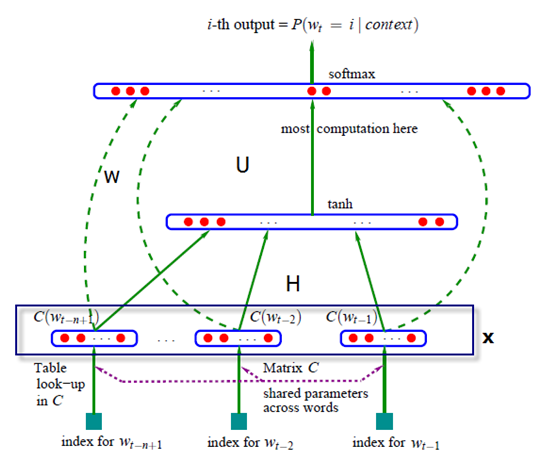
图1-2 神经网络架构
假设该模型训练的语料库的词汇量为|V|,语料库中每个单词w_i转换成词向量的大小维度为m。把每个单词w_i转换为词嵌入的矩阵为C,其形状为|V|xm。其过程如图1-3所示。

图1-3 通过矩阵C把词索引转换为词嵌入
整个网络架构用表达式表示:
y=b+Wx+U tanh(d+Hx)
其中Wx表示输入层与输出层有直接联系(图1-2中的虚线部分),如果不要这个链接,直接设置W为0即可,b是输出层的偏置向量,d是隐层的偏置向量,里面的x即是单词到特征向量的映射,计算如下:
x=(C(w_(t-1) ),C(w_(t-2) ),⋯,C(w_(t-n+1)))
其中C是一个矩阵,其形状为|V|xm
假设隐层的神经元个数为h,那么整个模型的参数可以细化为θ = (b, d, W, U, H, C)。下面各参数含义及形状:
b是词向量x到输出层的偏移量,维度为|V|
W是词向量x到输出层的权重矩阵,维度为|V|x(n−1)m
d是隐含层的偏移量,维度为h
H是输入x到隐含层的权重矩阵,形状为hx(n-1)m
U是隐含层到输出层的权重矩阵,形状为|V|xh
网络的第一层(输入层)是将C(w_(t-1) ),C(w_(t-2) ),⋯,C(w_(t-n+1))这已知的n-1和单词的词向量首尾相连拼接起来,形成(n-1)m的向量x。
网络的第二层(隐藏层)直接用d+Hx计算得到,d是一个偏置项。之后,用tanh作为激活函数。
网络的第三层(输出层)一共有|V|个节点,最后使用softmax函数将输出值y归一化成概率。
最后,用随机梯度下降法把这个模型优化出来就可以了。
3.1.2 NNLM的PyTorch实现
这样用一个简单实例,实现3.1.1节的计算过程。
1、导入需要的库或模块
|
1 2 3 4 |
import torch import torch.nn as nn import torch.optim as optim import jieba |
2、定义语料库及预处理函数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#定义一个简单语料库 sentences = [ "我喜欢苹果", "我爱运动", "我讨厌老鼠"] #预处理语料库,得到批量数据 def make_batch(sentences): input_batch = [] target_batch = [] for sen in sentences: word = list(jieba.cut(sen)) #对每句话进行中文分词 input = [word_dict[n] for n in word[:-1]] # 创建(1至n-1) 作为输入,这里实际上就是取前两个词。 target = word_dict[word[-1]] # 这里把每句的最后一个词作为目标, input_batch.append(input) target_batch.append(target) return input_batch, target_batch |
3、构建模型
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Model class NNLM(nn.Module): def __init__(self): super(NNLM, self).__init__() self.C = nn.Embedding(n_class, m) self.H = nn.Linear(n_step * m, n_hidden, bias=False) self.d = nn.Parameter(torch.ones(n_hidden)) self.U = nn.Linear(n_hidden, n_class, bias=False) self.W = nn.Linear(n_step * m, n_class, bias=False) self.b = nn.Parameter(torch.ones(n_class)) def forward(self, X): X = self.C(X) # X : [batch_size, n_step, n_class] X = X.view(-1, n_step * m) # [batch_size, n_step * n_class],对应x tanh = torch.tanh(self.d + self.H(X)) # [batch_size, n_hidden] output = self.b + self.W(X) + self.U(tanh) # [batch_size, n_class],对应y return output |
4、训练模型
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
if __name__ == '__main__': n_step = 2 # 对应n-gram中n-1值 n_hidden = 2 #对应隐含层的节点数h m = 2 #对应于m的值 words_list=[] for sen in sentences: a=list(jieba.cut(sen)) words_list.extend(a) words_list=list(set(words_list)) word_dict = {w: i for i, w in enumerate(words_list)} number_dict = {i: w for i, w in enumerate(words_list)} n_class = len(word_dict) # 语料库中词汇量,相当与|V| model = NNLM() criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) input_batch, target_batch = make_batch(sentences) input_batch = torch.LongTensor(input_batch) target_batch = torch.LongTensor(target_batch) # Training for epoch in range(5000): optimizer.zero_grad() output = model(input_batch) # output : [batch_size, n_class], target_batch : [batch_size] loss = criterion(output, target_batch) if (epoch + 1) % 1000 == 0: print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss)) loss.backward() optimizer.step() #print(model.H.weight) #查看H训练后的权重 # 预测 predict = model(input_batch).data.max(1, keepdim=True)[1] # 测试 print([sen.split()[:2] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()]) |
5、运行结果
Epoch: 1000 cost = 0.113229
Epoch: 2000 cost = 0.015353
Epoch: 3000 cost = 0.004546
Epoch: 4000 cost = 0.001836
Epoch: 5000 cost = 0.000853
[['我喜欢苹果'], ['我爱运动'], ['我讨厌老鼠']] -> ['苹果', '运动', '老鼠']
3.1.3词嵌入特征
在NNLM语言模型中,通过神经网络的线性/非线性转换以及激活函数(例如softmax)得到似然条件概率值。同时因为保存了隐层的系数矩阵,因此可以得到每个文本序列以及每个词的词嵌入(Word Embedding)。词嵌入一般通过神经网络能学习语料库中的一些特性或知识, 如捕获词之间的多种相似性。图1-4为在某语料库上训练得到的一个简单词嵌入矩阵,从这个特征我们可以看出,有些词是相近的,如男与女,国王与王后,苹果与橘子等,这些相似性是从语料库学习得到。如何从语料库中学习这些特征或知识?人们研究出多种有效方法,其中最著名的就是Word2vec。
另外我们可以把词嵌入这些特性,通过迁移方法,应用到下游项目中。
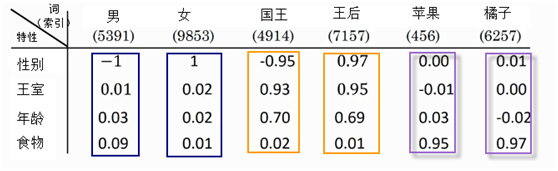
图1-4 词嵌入特征示意图
与从语料库中学习词嵌入类似,在视觉处理领域中,也是通过学习图像,把图像特征转换为编码,整个过程如下图1-5所示。只不过在视觉处理中我们一般不把学到的向量为词嵌入,而往往称之为编码。
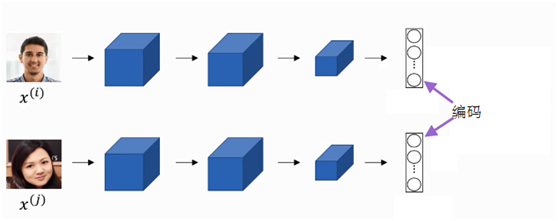
图1-5 把图像转换为编码示意图
3.1.4 word2vec简介
词嵌入(word Embedding)最早由 Hinton 于 1986 年提出的,可以克服独热表示的缺点。解决词汇与位置无关问题,可以通过计算向量之间的距离(欧式距离、余弦距离等)来体现词与词的相似性。其基本想法是直接用一个普通的向量表示一个词,此向量为:
[0.792, -0.177, -0.107, 0.109, -0.542, ...],常见维度50或100。用这种方式表示的向量,“麦克”和“话筒”的距离会远远小于“麦克”和“天气”的距离。
词嵌入表示的优点是解决了词汇与位置无关问题,不足是学习过程相对复杂且受训练语料的影响很大。训练这种向量表示的方法较多,常见的有LSA、PLSA、LDA、Word2Vec等,其中Word2Vec是Google在2013年开源的一个工具,Word2Vec是一款用于词向量计算的工具,同时也是一套生成词向量的算法方案。Word2Vec算法的背后是一个浅层神经网络,其网络深度仅为3层,所以,严格说Word2Vec并非深度学习范畴。但其生成的词向量在很多任务中都可以作为深度学习算法的输入,因此,在一定程度上可以说Word2Vec技术是深度学习在NLP领域的基础。训练Word2Vec主要有以下两种模型来训练得到:
1、CBOW模型
CBOW模型包含三层,输入层、映射层和输出层。其架构如图1-6。CBOW模型中的w(t)为目标词,在已知它的上下文w(t-2),w(t-1),w(t+1),w(t+2)的前提下预测词w(t)出现的概率,即:p(w/context(w))。 目标函数为:
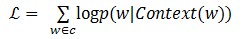

图1-6 CBOW模型
CBOW模型训练其实就是根据某个词前后若干词来预测该词,这其实可以看成是多分类。最朴素的想法就是直接使用softmax来分别计算每个词对应的归一化的概率。但对于动辄十几万词汇量的场景中使用softmax计算量太大,于是需要用一种二分类组合形式的hierarchical softmax,即输出层为一棵二叉树。
2、Skip-gram模型
Skip-gram模型同样包含三层,输入层,映射层和输出层。其架构如图1-7。Skip-Gram模型中的w(t)为输入词,在已知词w(t)的前提下预测词w(t)的上下文w(t-2),w(t-1),w(t+1),w(t+2),条件概率写为:p(context(w)/w)。目标函数为:
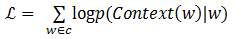
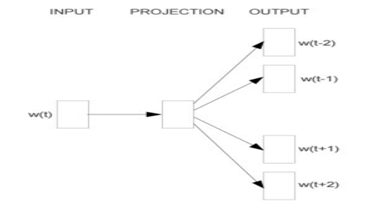
图1-7 Skip-gram模型