如果你对爬虫感兴趣,但没有相关基础,这个实例就比较适合你。本实例非常简单,特别适合入门。本实例主要步骤如下本实例爬取一个有关教学研究人员网站 WISE(http://www.wise.xmu.edu.cn/people/faculty),提取这个页面上所有老师的姓名和个人主页的链接,然后简单解析相关标签(tag),然后把解析出来的内容存放在文件和数据库中。
讲完这个实例后面还有一个更高级的爬虫实例,使用Scrapy架构爬取网站内容,这个架构分布式、平行处理等我们就无需做过多配置,系统自动为我们配置好。
接下来,我们还是从一个简单实例开始吧。
3.1下载网页
使用requests下载网页,它是第三方库
|
1 2 |
import requests r = requests.get('http://www.wise.xmu.edu.cn/people/faculty') |
把需要的网页内容提取出来:
|
1 |
html = r.content |
到这一步我们已经获取了网页的源代码。具体源 代码是什么样的呢?右键,点击“查看源文件”或者“查看源”就可以看到。
3.2 解析网页
从源代码里面找。找到的我们需要的信息如下:


解析使用bs4模块,该模块有最常用的几个BeautifulSoup对象的方法(method)。我们使用的这几个方法,主要是通过HTML的标签和标签里面的参数来定位,然后用特定方法(method)提取数据。
|
1 2 3 |
from bs4 import BeautifulSoup #创建BeautifulSoup对象 soup = BeautifulSoup(html,'html.parser') #html.parser是解析器 |
使用了BeautifulSoup对象的find方法。这个方法的意思是找到带有‘div’这个标签并且参数包含" class = 'people_list' "的HTML代码。如果有多个的话,find方法就取第一个。那么如果有多个呢?可以使用find_all,现在我们要取出所有的“a”标签里面的内容:
|
1 2 3 4 |
div_people_list = soup.find('div', attrs={'class': 'people_list'}) a_s = div_people_list.find_all('a', attrs={'target': '_blank'}) td_s=div_people_list.find_all('td') td_s[2].text.strip() |
显示结果
'助理教授'
这里我们使用find_all方法取出所有标签为“a”并且参数包含“ target = ‘_blank‘ ”的代码,返回一个列表。“a”标签里面的“href”参数是我们需要的老师个人主页的信息,而标签里面的文字是老师的姓名
|
1 2 3 4 |
for a in a_s: url = a['href'] name = a.get_text() print("%s,%s"%(name,url)) |
运行结果:
|
1 2 3 4 5 6 7 8 9 |
敖萌幪,/people/faculty/494d4f1c-0470-4f53-8b7c-d3594241876b.html Bowers, Roslyn,/people/faculty/d01fe119-7980-4238-a3ec-abb9b66ec706.html Brown, Katherine,/people/faculty/36c6b263-2cc2-4682-9975-02b75e6505f7.html 祝嘉良,/people/faculty/af02fab6-add2-46ca-8ef2-c4597584a952.html 邹至庄,/people/faculty/ad6c7108-0e44-4e48-9165-fcdeb4aeddc2.html |
3.3 拓展一
通过源码分析,可知教师的姓名,职位,邮箱等信息包含在td标签内,接下来我们解析源码并把解析结果保存到cvs文件中。具体步骤如下:
1、在td标签里,包含教师的姓名,职位,邮箱等信息
|
1 2 3 4 5 6 7 8 9 10 11 |
#a_s = div_people_list.find_all('a', attrs={'target': '_blank'}) td_s=div_people_list.find_all('td') tdlist=[] for i in range(1,len(td_s)): try: td_s[i]['colspan'] except Exception as e: tdlist.append(td_s[i].text.strip()) print(len(tdlist)) |
打印结果为
327
查看前几行数据
|
1 |
tdlist[:9] |
['敖萌幪',
'助理教授',
'mengmengao@xmu.edu.cn',
'Bowers, Roslyn',
'英语教师',
'bowers.roslyn@yahoo.com',
'Brown, Katherine',
'英语教师',
'kbrownanne@yahoo.com']
把数据保存到cvs文件中
|
1 2 3 4 5 6 7 8 |
tfile=open('lists.cvs', 'w', encoding='utf-8') tfile.truncate() for i in range(0,len(tdlist)): if (i+1)%3 ==0: tfile.write('"'+tdlist[i]+'"'+'\n') else: tfile.write('"'+tdlist[i]+'"'+',') tfile.close() |
3.4 拓展二
取出所以的td的内容,并按姓名,职位,邮箱格式写入数据库,采用mysql数据库,连接用pymysql,具体内容如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
import pymysql import csv import codecs def get_conn(): conn = pymysql.connect(host='slave02', port=3306, user='feigu', passwd='feigu', db='testdb', charset='utf8') return conn def CreateTable(): '''创建数据表tdlist''' db =get_conn() cur = db.cursor() create_sql = "create table if not exists tdlist(cust_name varchar(100) default null,cust_post varchar(100) default null,cust_email varchar(200) default null) ENGINE=MyISAM DEFAULT CHARSET=utf8" cur.execute(create_sql) db.commit() db.close() cur.close() print('数据表创建成功') def insert(cur, sql, args): cur.execute(sql, args) def read_csv_to_mysql(filename): with codecs.open(filename=filename, mode='r', encoding='utf-8') as f: CreateTable() reader = csv.reader(f) head = next(reader) conn = get_conn() cur = conn.cursor() sql = 'insert into tdlist values(%s,%s,%s)' for item in reader: if item[1] is None or item[1] == '': # item[1]作为唯一键,不能为null continue args = tuple(item) insert(cur, sql=sql, args=args) conn.commit() print("数据导入成功") cur.close() conn.close() if __name__ == '__main__': read_csv_to_mysql('lists.cvs') |
数据表创建成功
数据导入成功
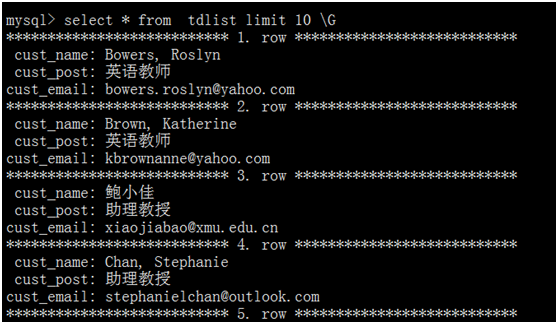
查看数据库部分记录:
本文参考:https://zhuanlan.zhihu.com/p/21377121
Pingback引用通告: Python与人工智能 – 飞谷云人工智能